
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
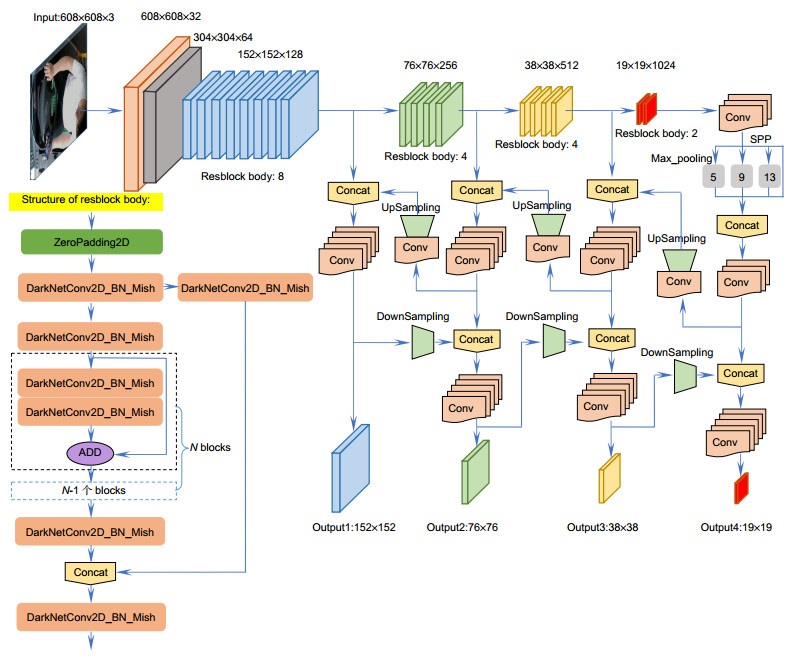
小目标物体实时检测一直是图像处理领域中的难点。本文基于深度学习的目标检测算法,提出了一种端到端的神经网络,用于复杂驾驶场景下的手机小目标检测。首先,通过改进YOLOv4算法,设计了一个端到端的小目标检测网络(OMPDNet)来提取图片特征;其次,基于K-means算法设计了一个聚类中心更加贴切数据样本分布的聚类算法K-means-Precise,用以生成适应于小目标数据的先验框(anchor),从而提升网络模型的效率;最后,采用监督与弱监督方式构建了自己的数据集,并在数据集中加入负样本用于训练。在复杂的驾驶场景实验中,本文提出的OMPDNet算法不仅可以有效地完成驾驶员行车时使用手机的检测任务,而且对小目标检测在准确率和实时性上较当今流行算法都有一定的优势。

Abstract
Real-time detection of small objects is always a difficult problem in image processing. Based on the target detection algorithm of deep learning, this paper proposed an end-to-end neural network for mobile phone small target detection in complex driving scenarios. Firstly, an end-to-end small target detection network (OMPDNet) was designed to extract image features by improving the YOLOv4 algorithm. Secondly, based on the K-means algorithm, a K-means-Precise clustering algorithm of more appropriate data samples distribution in the clustering center was designed, which was used to generate prior frames suitable for small target data, so as to improve the efficiency of the network model. Finally, we constructed our own data set with supervision and weak supervision, and added negative samples to the data set for training. In the complex driving scene experiments, the OMPDNet algorithm proposed in this paper can not only effectively complete the detection task of using mobile phone while driving, but also has certain advantages over the current popular algorithms in accuracy and real-time for small target detection.
-
Overview

Overview: Real-time detection of small objects is always a difficult problem in the field of image processing. It has the characteristics of low resolution and difficult detection, which often leads to missed detection and false detection. In this paper, based on the deep learning target detection algorithm, an end-to-end neural network is proposed for small target detection like mobile phone in complex driving scenes. Firstly, in order to maintain a high accuracy rate and ensure real-time performance, this paper improves the YOLOv4 algorithm and designs an end-to-end small target detection network (OMPDNet) to extract image features. Secondly, setting an appropriate size of Anchor is conducive to improving the convergence speed and accuracy of the model. Meanwhile, based on K-means, this paper presents a clustering algorithm K-means-Precise, which is more suitable for the distribution of sample data. It is used to generate anchors suitable for small target data, so as to improve the efficiency of the network model. Finally, a data set (OMPD Dataset) is made by using supervision and weak supervision method to make up for the lack of public data set in specific driving scenes. It is composed of shooting videos from the in-car monitoring camera, a small number of public data sets and internet pictures. And more, in order to solve the problem of imbalance between positive and negative samples, negative samples are added to the data set for training in the paper. The experimental results on OMPD Dataset show that K-means-Precise can slightly improve the accuracy of the model. But importantly, it converges five cycles ahead of time. The overall detection of the network model is evaluated by the accuracy rate, recall rate and average accuracy rate, which are 89.7%, 96.1% and 89.4% respectively, and the speed reaches 72.4 frames per second. It shows that in the complex driving scene experiments, the OMPDNet proposed in this paper can not only effectively complete the detection task of drivers using mobile phones while driving, but also has certain advantages in accuracy and real-time performance of small target detection compared with current popular algorithms. Especially, in the practical engineering application, real-time is more important, which can recognize the behavior while driver playing mobile phone to reduce the occurrence of traffic accidents, and be benefit to the traffic management department. Our proposed method is not only suitable for mobile phone detection, but also can be extended to small target detection problems in the field of deep learning. In the future work, we will continue to improve the algorithm and generalize its performance.
-

-
Input: dataset {x1, x2, …, xN}, number of clusters k, variance threshold λ Output : clusters q{xi}∈{1, 2, …, k} Initialize centroids {c1, c2, …, ck} Repeat Repeat for i=1, 2, …, N do q{xi}∈←argminj |xi-cj| end for for j=1, 2, …, k do cj←mean|xi|q{xi}=j| end for Until centroids do not change for m=1, 2, …, k do calculate q{xi} mean mi and variance σi if σi > λ then remove the sample end if end for {x1, x2, …, xN}←{x1, x2, …, xN'} N←N' Until dataset and centroids do not change  下载: 导出CSV
下载: 导出CSV
表 1 K-means-Precise的实验结果
Table 1. Experimental results of K-means-Precise
Method P/% R/% mAP/% Convergence time OMPDNet 84.5 94.2 82.4 64 epoch OMPDNet+K-means-Precise 85.7 94.3 83.2 59 epoch
下载: 导出CSV
表 2 负样本训练的实验结果
Table 2. Experimental results of negative sample training
Method P/% R/% mAP/% OMPDNet 84.5 94.2 82.4 OMPDNet+negative sample training 89.2 94.1 86.3
下载: 导出CSV
表 3 五种算法的性能比较
Table 3. Performance comparisons of five algorithms
Method P/% R/% mAP/% Speed/(f/s) Faster R-CNN 85.4 83.5 78.6 23.2 SSD 78.6 75.9 75.8 44.5 YOLOv3 82.3 79.4 80.1 52.4 YOLOv4 89.8 84.2 83.6 56.8 Ours 89.7 96.1 89.4 72.4
下载: 导出CSV
-
参考文献
[1] Rodríguez-Ascariz J M, Boquete L, Cantos J, et al. Automatic system for detecting driver use of mobile phones[J]. Transp Res C Emergi Technol, 2011, 19(4): 673-681. doi: 10.1016/j.trc.2010.12.002.
[2] Leem S K, Khan F, Cho S H. Vital sign monitoring and mobile phone usage detection using IR-UWB radar for intended use in car crash prevention[J]. Sensors (Basel), 2017, 17(6): 1240. doi: 10.3390/s17061240.
[3] Berri R A, Silva A G, Parpinelli R S, et al. A pattern recognition system for detecting use of mobile phones while driving[C]//Proceedings of the 9th International Conference on Computer Vision Theory and Applications, 2014: 411-418. doi: 10.5220/0004684504110418.
[4] Cortes C, Vapnik V. Support-vector networks[J]. Mach Learn, 1995, 20(3): 273-297.
[5] Xiong Q F, Lin J, Wei Y, et al. A deep learning approach to driver distraction detection of using mobile phone[C]//2019 IEEE Vehicle Power and Propulsion Conference, 2019: 1-5. doi: 10.1109/VPPC46532.2019.8952474.
[6] Shi X P, Shan S G, Kan M N, et al. Real-time rotation-invariant face detection with progressive calibration networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 2295-2303.
[7] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal speed and accuracy of object detection[Z]. arXiv: 2004.10934, 2020.
[8] Bishop C. Pattern Recognition and Machine Learning[M]. New York: Springer-Verlag, 2006.
[9] Fukushima K. Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position[J]. Biol Cybern, 1980, 36(4): 193-202. doi: 10.1007/BF00344251
[10] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proc IEEE, 1998, 86(11): 2278-2324. doi: 10.1109/5.726791.
[11] Krizhevsky A, Sutskever I, Hinton G. ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems, 2012.
[12] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]//ICLR, 2015.
[13] Howard A G, Zhu M L, Chen B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications[Z]. arXiv: 1704.04861, 2017.
[14] Szegedy C, Liu W, Jia Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015: 1-9.
[15] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[16] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2001. doi: 10.1109/CVPR.2001.990517.
[17] Viola P, Jones M J. Robust real-time face detection[J]. Int J Comput Vis, 2004, 57(2): 137-154. doi: 10.1023/B:VISI.0000013087.49260.fb
[18] Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005: 886-893.
[19] Felzenszwalb P F, Girshick R B, McAllester D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Trans Pattern Anal Mach Intell, 2010, 32(9): 1627-1645. doi: 10.1109/TPAMI.2009.167.
[20] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
[21] He K M, Zhang X Y, Ren S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans Pattern Anal Mach Intell, 2015, 37(9): 1904-1916. doi: 10.1109/TPAMI.2015.2389824
[22] Girshick R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision, 2015: 1440-1448.
[23] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91-99.
[24] Dai J F, Li Y, He K M, et al. R-FCN: Object detection via region-based fully convolutional networks[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016: 379-387.
[25] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[26] Redmon J, Farhadi A. Yolo9000: Better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 6517-6525.
[27] Redmon J, Farhadi A. YOLOv3: An incremental improvement[Z]. arXiv: 1804.02767, 2018.
[28] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//European Conference on Computer Vision, 2016: 21-37.
[29] 金瑶, 张锐, 尹东. 城市道路视频中小像素目标检测[J]. 光电工程, 2019, 46(9): 190053. doi: 10.12086/oee.2019.190053
Jin Y, Zhang R, Yin D. Object detection for small pixel in urban roads videos[J]. Opto-Electron Eng, 2019, 46(9): 190053. doi: 10.12086/oee.2019.190053
[30] Hu P, Ramanan D. Finding tiny faces[Z]. arXiv: 1612.04402, 2016.
[31] Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020: 1571-1580.
[32] Liu S, Qi L, Qin H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8759-8768.
[33] Duan K W, Bai S, Xie L X, et al. CenterNet: keypoint triplets for object detection[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 6569-6578.
[34] Zhang H Y, Cisse M, Dauphin Y N, et al. mixup: beyond empirical risk minimization[Z]. arXiv: 1710.09412, 2017.
-
访问统计



 点击扫一扫
点击扫一扫

图(7)
表(4)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


