
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
随着人机交互、虚拟现实等相关领域的发展,人体姿态识别已经成为热门研究课题。由于人体属于非刚性模型,具有时变性的特点,导致识别的准确性和鲁棒性不理想。本文基于KinectV2体感摄像头采集的骨骼信息,结合人体角度和距离特征,提出了一种基于单样本学习的模型匹配方法。首先,通过对采集的骨骼信息进行特征提取,计算关节点向量夹角和关节点的位移并设定阈值,其次待测姿态与模板姿态进行匹配计算,满足阈值限定范围则识别成功。实验结果表明,该方法能够实时的检测和识别阈值限定范围内定义的人体姿态,提高了识别的准确性和鲁棒性。
 Abstract:
Abstract:With the development of human-computer interaction, virtual reality, and other related fields, human posture recognition has become a hot research topic. Since the human body belongs to a non-rigid model and has time-varying characteristics, the accuracy and robustness of recognition are not ideal. Based on the KinectV2 somatosensory camera to collect skeletal information, this paper proposes a one-shot learning model matching method based on human body angle and distance characteristics. First, feature extraction is performed on the collected bone information, and the joint point vector angle and joint point displacement are calculated and a threshold is set. Secondly, the pose to be measured is matched with the template pose, and the recognition is successful if the threshold limit is met. Experimental results show that the method can detect and recognize human poses within the defined threshold in real-time, which improves the accuracy and robustness of recognition.
-
Key words:
- pose model /
- skeleton data /
- one-shot learning /
- model matching /
- KinectV2
-

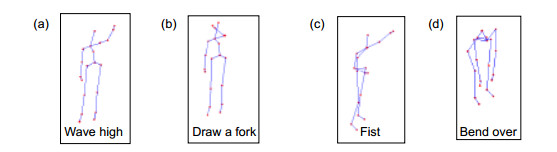
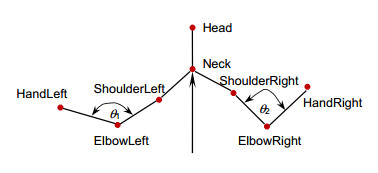
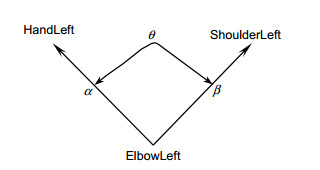
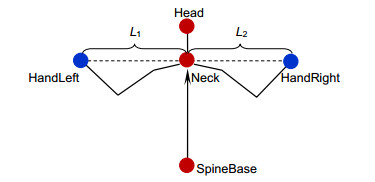
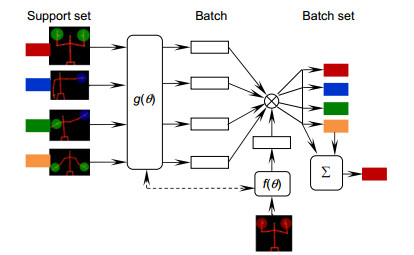
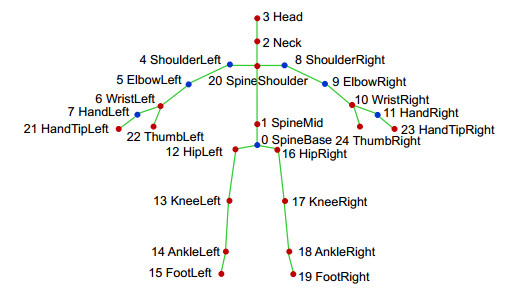
Overview: With the development of human-computer interaction, virtual reality, and other related fields, human pose recognition has become a hot research topic. Since the human body belongs to a non-rigid model and has time-varying characteristics, the accuracy and robustness of recognition are not ideal. Based on the KinectV2 somatosensory camera to collect skeletal information, this paper proposes a one-shot learning model matching method based on human body angle and distance characteristics. KinectV2 somatosensory camera can capture color images, depth images, and skeletal images. This article combines color images and skeletal images to extract and recognize human poses, thereby making the recognition more accurate, real-time, and robust. Through the feature extraction of the obtained bone information, the feature vector is constructed using the vector in mathematical thought, that is, the endpoint of the joint point minus the joint point of the starting point. The joint angle in this article uses the elbow joint as the fulcrum, shoulder joint, and the hand joint is constructed as the end-point. In this way, multiple types of poses can be combined, and the attitude sample library can be expanded. The joint point vector angle and the joint point displacement are calculated, and the threshold is set. The angle features and distance features are selected to make the feature points more prominent. The posture is easy to identify in complex situations. The final posture to be measured is matched with the template posture. The idea of matching calculation is to calculate the real-time posture characteristics, and compare the calculation results with the set type data and thresholds successfully. The significance of the model matching method using one-shot learning small sample learning is that small sample learning does not require a large number of samples and only a small number of samples for training. The advantages of a small number of samples are as follow: 1) The pose features can be accurately located during training; 2) Irrelevant data is discarded; 3) The calculation amount is reduced; 4) The recognition speed and accuracy are improved in the attitude matching process; 5) The anti-interference ability is stronger. The design of this paper is applied to option selection. Gesture recognition replaces the physical device and makes a defined gesture to complete the selection of options. Experimental results show that the method can detect and recognize human poses within the defined threshold in real-time, which improves the accuracy and robustness of recognition.
-

-

图 8 角度特征姿态识别结果示意图
Figure 8. Schematic diagram of recognition results of angular features
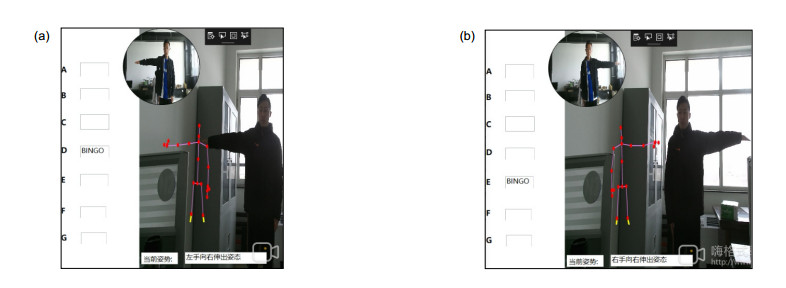
图 9 距离特征姿态识别结果示意图
Figure 9. Schematic diagram of distance feature pose recognition results
表 1 七种姿态识别结果
Table 1. Recognition results of seven gestures
Poses Experiments Recognition error Recognition rate/% A 50 0 100.00 B 50 0 100.00 C 50 1 98.00 D 50 0 100.00 E 50 1 98.00 F 50 2 96.00 G 50 2 96.00  下载: 导出CSV
下载: 导出CSV
表 2 七种算法识别率对比
Table 2. Comparison of recognition rates of seven algorithms
Algorithm type Algorithm 1 Algorithm 2 Algorithm 3 Algorithm 4 Algorithm 5 Algorithm 6 Text algorithm Average recognition rate/% 97.30 90.78 98.14 97.80 96.16 93.07 98.29 Average recognition time/ms 42 58 47 34 44 52 32
下载: 导出CSV
-
[1] Henry P, Krainin M, Herbst E, et al. RGB-D mapping: using Kinect-style depth cameras for dense 3D modeling of indoor environments[J]. Int J Rob Res, 2012, 31(5): 647-663. doi: 10.1177/0278364911434148
[2] 黄国范, 李亚. 人体动作姿态识别综述[J]. 电脑知识与技术, 2013, 12(1): 133-135. https://www.cnki.com.cn/Article/CJFDTOTAL-DNZS201301045.htm
Huang G F, Li Y. A survey of human action and pose recognition[J]. Comput Knowl Technol, 2013, 12(1): 133-135. https://www.cnki.com.cn/Article/CJFDTOTAL-DNZS201301045.htm
[3] Shotton J, Sharp T, Kipman A, et al. Real-time human pose recognition in parts from single depth images[J]. Commun ACM, 2013, 56(1): 116-124. doi: 10.1145/2398356.2398381
[4] 严利民, 杜斌, 郭强, 等. 基于局部扫描法对倾斜指势的识别[J]. 光电工程, 2016, 43(12): 147-153. doi: 10.3969/j.issn.1003-501X.2016.12.023
Yan L M, Du B, Guo Q, et al. Recognize the tilt fingertips by partial scan algorithm[J]. Opto-Electron Eng, 2016, 43(12): 147-153. doi: 10.3969/j.issn.1003-501X.2016.12.023
[5] 李红波, 丁林建, 吴渝, 等. 基于Kinect骨骼数据的静态三维手势识别[J]. 计算机应用与软件, 2015, 14(9): 161-165. doi: 10.3969/j.issn.1000-386x.2015.09.039
Li H P, Ding L J, Wu Y, et al. Static three-dimensional gesture recognition based on Kinect skeleton data[J]. Comput Appl Softw, 2015, 14(9): 161-165. doi: 10.3969/j.issn.1000-386x.2015.09.039
[6] Cao Z, Simon T, Wei S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]//Conference on Computer Vision and Pattern Recognition(CVPR), 2017: 7291-7299.
[7] Pfitscher M, Welfer D, Evaristo José Do Nascimento, et al. Article Users Activity Gesture Recognition on Kinect Sensor Using Convolutional Neural Networks and FastDTW for Controlling Movements of a Mobile Robot[J]. Inteligencia Artificial Revista Iberoamericana de Inteligencia Artificial, 2019, 22(63): 121-134. http://www.researchgate.net/publication/332227318_Article_Users_Activity_Gesture_Recognition_on_Kinect_Sensor_Using_Convolutional_Neural_Networks_and_FastDTW_for_Controlling_Movements_of_a_Mobile_Robot/download
[8] 赵海勇. 基于视频流的运动人体行为识别研究[D]. 西安: 西安电子科技大学, 2011.
Zhao H Y. Research of human action recognition based on video stream[D]. Xi'an: Xidian University, 2011.
[9] Xu W Y, Wu M Q, Zhao M, et al. Human action recognition using multilevel depth motion maps[J]. IEEE Access, 2019, 7: 41811-41822. doi: 10.1109/ACCESS.2019.2907720
[10] Vinyals O, Blundell C, Lillicrap T, et al. Matching networks for one shot learning[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016: 3637-3645.
[11] 朱大勇, 郭星, 吴建国. 基于Kinect三维骨骼节点的动作识别方法[J]. 计算机工程与应用, 2018, 54(20): 152-158. doi: 10.3778/j.issn.1002-8331.1706-0285
Zhu D Y, Guo X, Wu J G. Action recognition method using Kinect 3D skeleton data[J]. Comput Eng Appl, 2018, 54(20): 152-158. doi: 10.3778/j.issn.1002-8331.1706-0285
[12] 蔡兴泉, 涂宇欣, 余雨婕, 等. 基于少量关键序列帧的人体姿态识别方法[J]. 图学学报, 2019, 40(3): 532-538. https://www.cnki.com.cn/Article/CJFDTOTAL-GCTX201903017.htm
Cai X Q, Tu Y X, Yu Y J, et al. Human posture recognition method based on few key frames sequence[J]. J Graph, 2019, 40(3): 532-538. https://www.cnki.com.cn/Article/CJFDTOTAL-GCTX201903017.htm
[13] 钱银中, 沈一帆. 姿态特征与深度特征在图像动作识别中的混合应用[J]. 自动化学报, 2019, 45(3): 626-636. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201903016.htm
Qian Y Z, Shen Y F. Hybrid of pose feature and depth feature for action recognition in static image[J]. Acta Autom Sin, 2019, 45(3): 626-636. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201903016.htm
[14] Monir S, Rubya S, Ferdous H S. Rotation and scale invariant posture recognition using Microsoft Kinect skeletal tracking feature[C]//2012 12th International Conference on Intelligent Systems Design and Applications (ISDA), 2012: 829-842.
[15] 郭同欢, 陈姚节, 林玲. 基于姿态角的双Kinect数据融合技术及应用[J]. 科学技术与工程, 2019, 19(29): 172-178. doi: 10.3969/j.issn.1671-1815.2019.29.028
Guo T H, Chen Y J, Lin L. Gesture recognition based on the gesture angle of dual Kinect[J]. Sci Technol Eng, 2019, 19(29): 172-178. doi: 10.3969/j.issn.1671-1815.2019.29.028
[16] Wang P, Liu L Q, Shen C H, et al. Multi-attention network for one shot learning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 2721-2729.
[17] Yang Y, Saleemi I, Shah M. Discovering motion primitives for unsupervised grouping and one-shot learning of human actions, gestures, and expressions[J]. IEEE Trans Pattern Anal Mach Intell, 2013, 35(7): 1635-1648. doi: 10.1109/TPAMI.2012.253
[18] Sundermeyer M, Alkhouli T, Wuebker J, et al. Translation modeling with bidirectional recurrent neural networks[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014: 14-25.
[19] Cheng X L, He M Y, Duan W J. Machine vision based physical fitness measurement with human posture recognition and skeletal data smoothing[C]//2017 International Conference on Orange Technologies (ICOT), 2017: 323-342.
[20] Li Q M, Lin W X, Li J. Human activity recognition using dynamic representation and matching of skeleton feature sequences from RGB-D images[J]. Signal Process Image Commun, 2018, 68: 265-272. doi: 10.1016/j.image.2018.06.013
[21] Zhang Z Q, Liu Y N, Li A, et al. A novel method for user-defined human posture recognition using Kinect[C]//2014 7th International Congress on Image and Signal Processing, 2014: 724-739.
[22] Sagayam K M, Hemanth D J. Hand posture and gesture recognition techniques for virtual reality applications: a survey[J]. Virtual Real, 2017, 21(2): 91-107. doi: 10.1007/s10055-016-0301-0
[23] Stephenson R M, Chai R, Eager D. Isometric finger pose recognition with sparse channel SpatioTemporal EMG imaging[J]. Annu Int Conf IEEE Eng Med Biol Soc, 2018, 2018: 5232-5235. http://www.ncbi.nlm.nih.gov/pubmed/30441518
[24] Vishwakarma D K, Singh T. A visual cognizance based multi-resolution descriptor for human action recognition using key pose[J]. AEU-Int J Electron Commun, 2019, 107: 157-169. doi: 10.1016/j.aeue.2019.05.023
[25] Liu X X, Feng X Y, Pan S J, et al. Skeleton tracking based on Kinect camera and the application in virtual reality system[C]//Proceedings of the 4th International Conference on Virtual Reality, 2018: 21-25.
[26] Bulbul M F, Islam S, Ail H. 3D human action analysis and recognition through GLAC descriptor on 2D motion and static posture images[J]. Multimed Tools Appl, 2019, 78(15): 21085-21111. doi: 10.1007/s11042-019-7365-2
[27] Agahian S, Negin F, Köse C. An efficient human action recognition framework with pose-based spatiotemporal features[J]. Eng Sci Technol, 2020, 23(1): 196-203. http://www.sciencedirect.com/science/article/pii/S2215098618312345
-

 点击扫一扫
点击扫一扫
图(9)
表(2)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


