
 E-mail Alert
E-mail Alert RSS
RSS
Remote-sensing images reconstruction based on adaptive dual-domain attention network
-
摘要
随着卷积神经网络(convolutional neural networks, CNN)和 Transformer 模型的快速发展,它们在遥感图像超分辨率(remote-sensing image super-resolution, RSISR)重建任务中取得了显著进展。然而,现有方法在处理不同尺度物体特征时表现不足,同时未能充分挖掘通道与空间维度间的隐性关联,限制了重建性能的进一步提升。针对上述问题,本文提出了一种自适应双域注意力网络(adaptive dual-domain attention network, ADAN)。该网络通过融合通道域与空间域的自注意力信息,增强了特征提取能力;设计的多尺度前馈网络(multi-scale feed-forward network, MSFFN)能够捕捉丰富的多尺度特征;结合新颖的门控卷积模块,进一步提升了局部特征表达能力。基于 U 型结构的网络骨干设计,实现了高效的多层次特征融合。在多个公开遥感数据集上的实验结果表明,所提出的 ADAN 方法在定量指标(如 PSNR 和 SSIM)以及视觉质量方面均显著优于现有的先进算法,充分验证了其有效性与先进性,为遥感图像超分辨率重建提供了新的研究思路和技术路径。
-
关键词:
- 双域注意力 /
- Transformer /
- 注意力机制 /
- 遥感图像 /
- 超分辨率
Abstract
With the rapid development of convolutional neural networks (CNNs) and Transformer models, significant progress has been made in remote sensing image super-resolution (RSSR) reconstruction tasks. However, existing methods have limitations in effectively handling multi-scale object features and fail to fully explore the implicit correlations between channel and spatial dimensions, thus restricting further improvements in reconstruction performance. To address these issues, this paper proposes an adaptive dual-domain attention network (ADAN). The network integrates self-attention information from both channel and spatial domains to enhance feature extraction capabilities. A multi-scale feed-forward network (MSFFN) is designed to capture rich multi-scale features. At the same time, an innovative gated convolutional module is introduced to further enhance the representation of local features. The network adopts a U-shaped backbone structure, enabling efficient multi-level feature fusion. Experimental results on multiple publicly available remote sensing datasets show that the proposed ADAN method significantly outperforms state-of-the-art approaches in terms of quantitative metrics (e.g., PSNR and SSIM) and visual quality. These results validate the effectiveness and superiority of ADAN, providing novel insights and technical approaches for remote sensing image super-resolution reconstruction.
-
Key words:
- dual-domain attention /
- transformer /
- attention mechanism /
- remote sensing images /
- super-resolution
-
Overview
Overview: With the rapid development of convolutional neural networks (CNNs) and Transformer models, significant progress has been made in the task of remote sensing image super-resolution reconstruction (RSISR). However, existing methods have limitations in handling features of objects at different scales and fail to fully exploit the implicit relationships between channel and spatial dimensions, which restricts further improvement in reconstruction performance. To address these issues, an adaptive dual-domain attention network (ADAN) is proposed, aiming to enhance feature extraction capabilities by integrating self-attention information from both channel and spatial domains. Additionally, it combines multi-scale feature mining and local feature representation to improve the performance of remote sensing image super-resolution reconstruction.
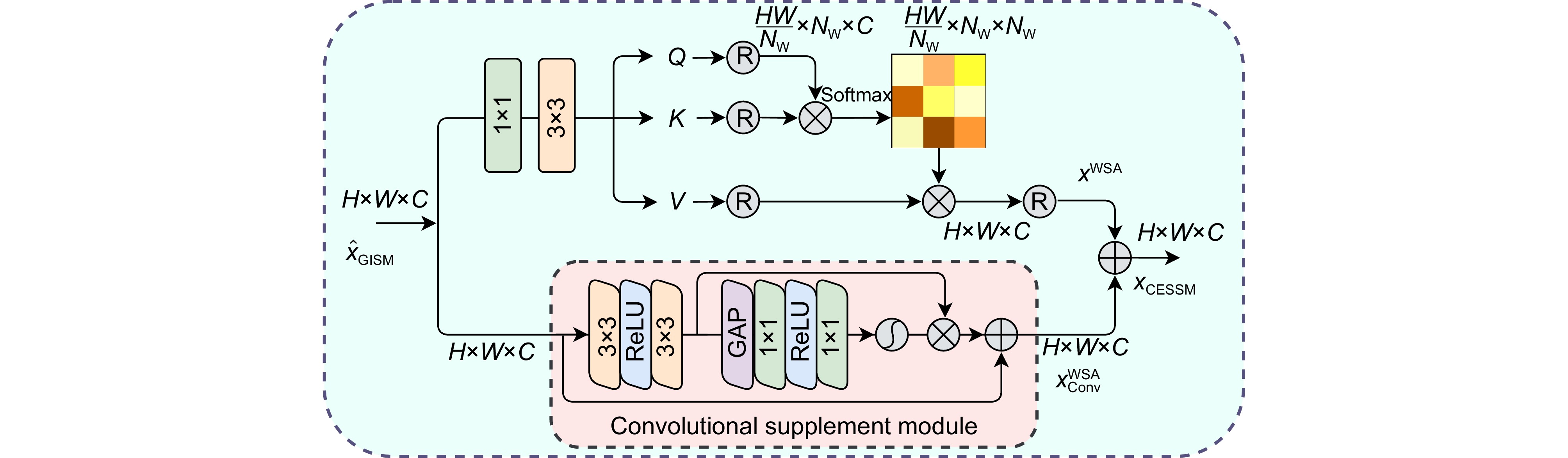
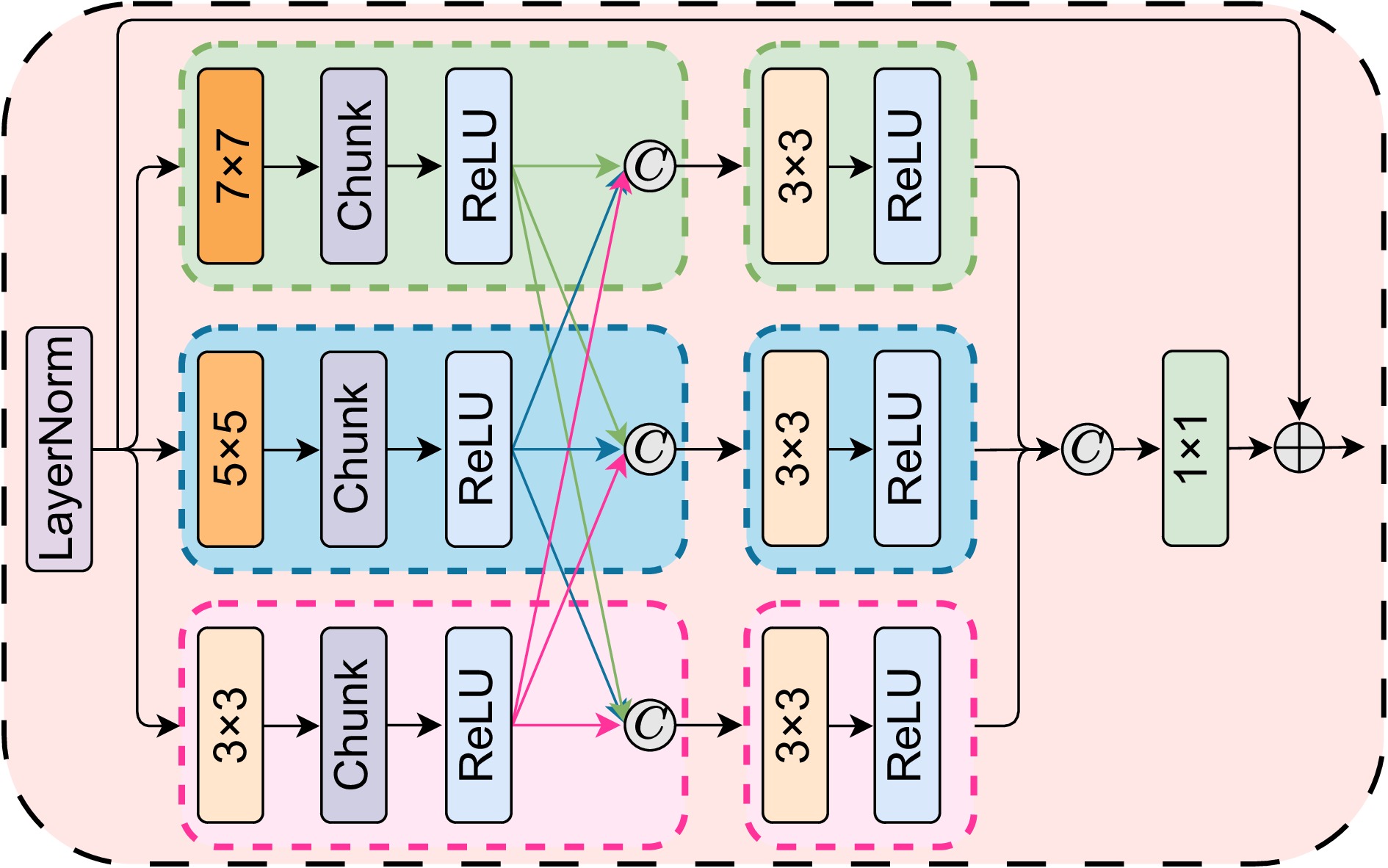
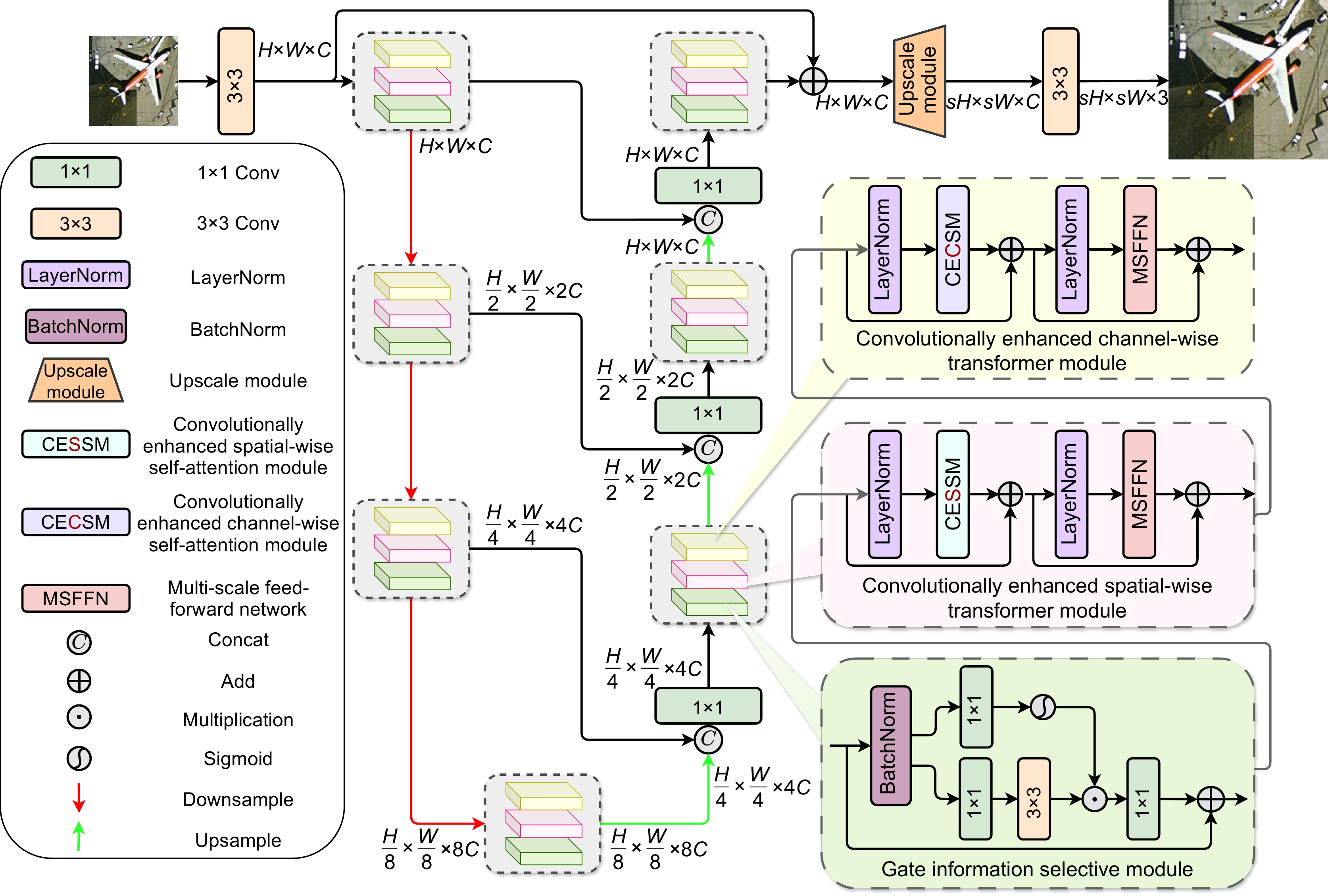
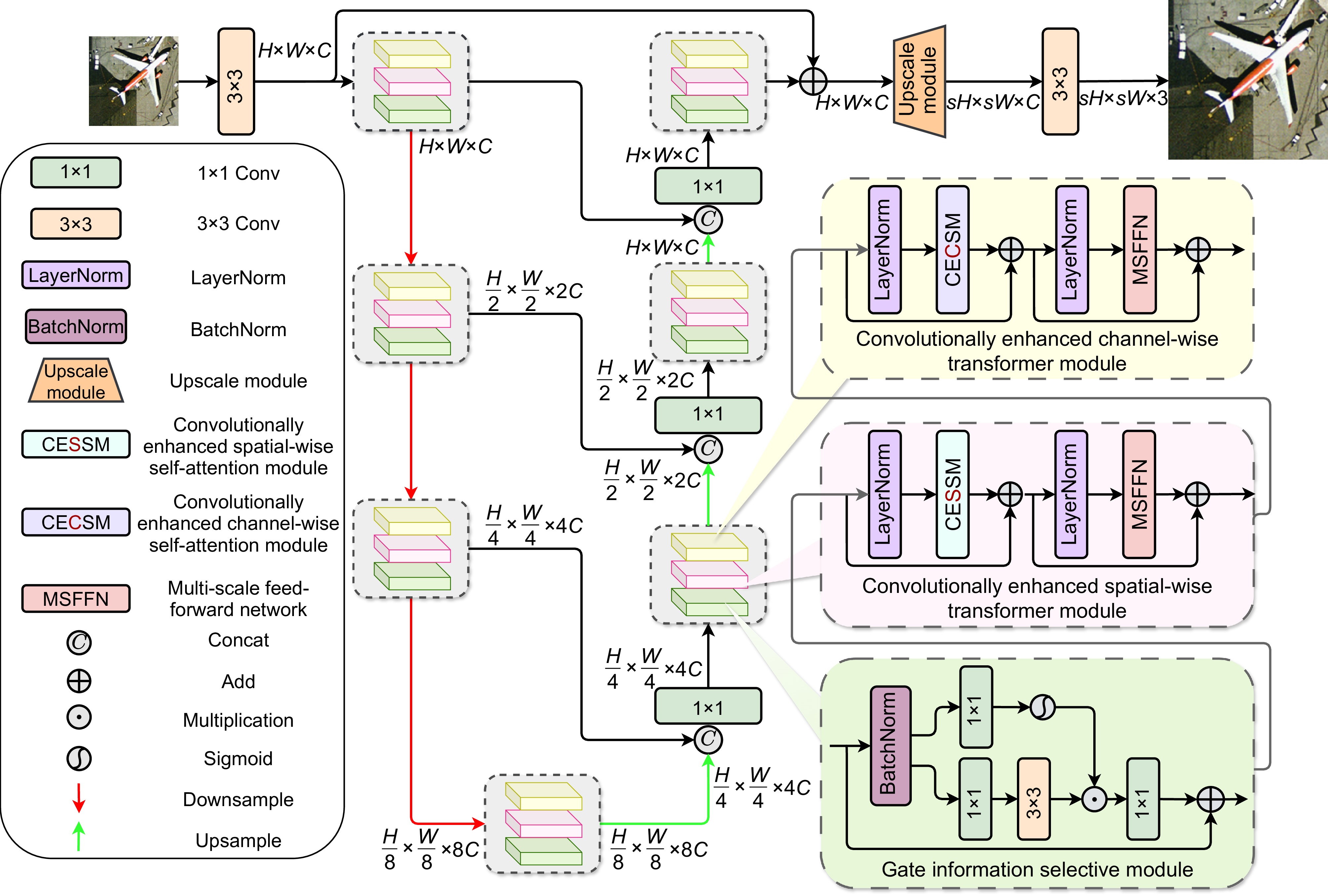
The research aims to address the shortcomings of existing methods in multi-scale feature extraction and insufficient exploration of channel-spatial relationships in remote sensing image super-resolution tasks. To this end, the ADAN network designs a multi-scale feed-forward network (MSFFN) to capture rich multi-scale features and incorporates a novel gate information selective module (GISM) to enhance local feature representation. Furthermore, the network adopts a U-shaped architecture to achieve efficient multi-level feature fusion. Specifically, ADAN introduces a convolutionally enhanced spatial-wise transformer module (CESTM) and a convolutionally enhanced channel-wise transformer module (CECTM) to extract channel and spatial features in parallel, comprehensively exploring the interactions and dependencies between features.
Experimental results demonstrate that ADAN significantly outperforms state-of-the-art algorithms on multiple public remote sensing datasets in terms of quantitative metrics (e.g., PSNR and SSIM) and visual quality, validating its effectiveness and superiority. The main contributions are as follows: 1) Proposing a novel method, ADAN, tailored for remote sensing image super-resolution tasks; 2) Designing parallel channel and spatial feature extraction modules along with a gated convolution module to comprehensively explore features across channel, spatial, and convolutional dimensions; 3) Introducing a multi-scale feed-forward network (MSFFN) to effectively explore potential scale relationships and enhance global representation capabilities; 4) Experimentally validating the superior performance of ADAN in remote sensing image super-resolution reconstruction. This research provides new insights and technical pathways for remote sensing image super-resolution reconstruction.
-

-
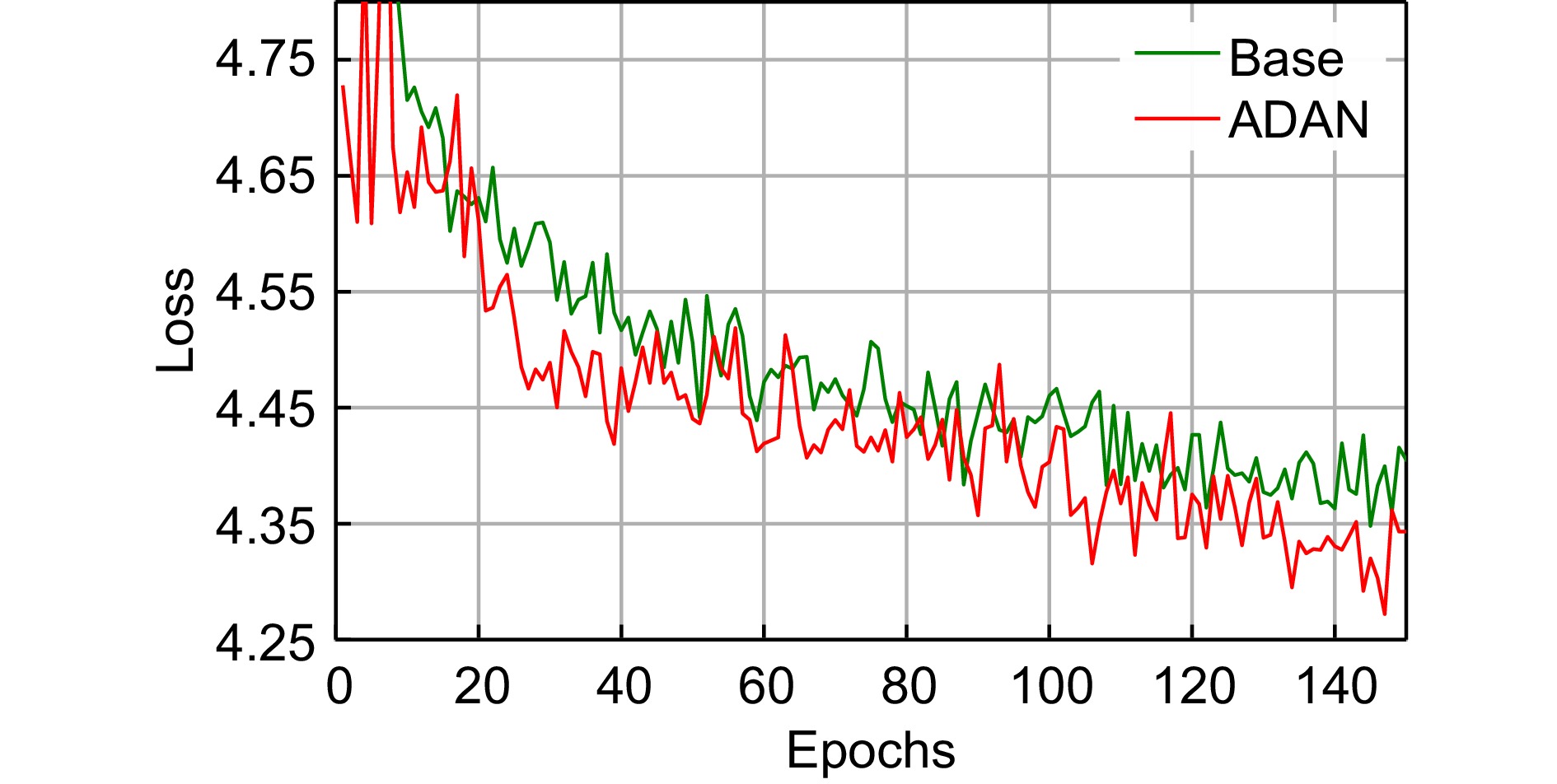
图 5 放大因子为×2时UCMerced Landuse的损失函数分析结果
Figure 5. Loss function analysis results on UCMerced LandUse with upscale factor of ×2

图 6 放大因子为×2时UCMerced Landuse的 PSNR分析结果
Figure 6. PSNR analysis results on UCMerced LandUse with upscale factor of ×2

图 7 放大因子为×2时UCMerced Landuse的视觉比较结果
Figure 7. Visual comparison on UCMerced Landuse with an upscaling factor of ×2

图 8 放大因子为×3时UCMerced Landuse的视觉比较结果
Figure 8. Visual comparison on UCMerced Landuse with an upscaling factor of ×3

图 9 放大因子为×4时UCMerced Landuse的视觉比较结果
Figure 9. Visual comparison on UCMerced Landuse with an upscaling factor of ×4

图 10 放大因子为$ \times 2 $ 时对 UCMerced Landuse 进行残差对比
Figure 10. Residual comparison on UCMerced Landuse with an upscaling factor of ×2
表 1 在UCMerced LandUse 数据集(×2、×3和×4)上的 PSNR/SSIM 结果
Table 1. PSNR/SSIM results on the UCMerced LandUse dataset (×2, ×3, and ×4)
Scale PSNR/SSIM Bicubic SRCNN FSRCNN VDSR LGCNet DCM HSENet TransENet Ours 2 30.76/0.8789 32.84/0.9152 33.18/0.9196 33.38/0.9220 33.48/0.9235 33.65/0.9274 34.22/0.9327 35.43/0.9355 35.62/0.9717 3 27.46/0.7631 28.66/0.8038 29.09/0.8167 29.28/0.8232 29.28/0.8238 29.52/0.8349 30.00/0.8420 31.03/0.8526 31.10/0.8811 4 25.65/0.6725 26.78/0.7219 26.93/0.7267 26.85/0.7317 27.02/0.7333 27.22/0.7528 27.73/0.7623 28.74/0.7694 28.84/0.8003  下载: 导出CSV
下载: 导出CSV
表 2 在AID数据集(×2、×3和×4)上的 PSNR/SSIM 结果
Table 2. PSNR/SSIM results on the AID dataset (×2, ×3, and ×4)
Scale PSNR/SSIM Bicubic SRCNN FSRCNN VDSR LGCNet DCM HSENet TransENet Ours 2 32.39/0.8906 34.49/0.9286 34.73/0.9331 35.05/0.9346 34.80/0.9320 35.21/0.9366 35.24/0.9368 35.28/0.9374 36.93/0.9617 3 29.08/0.7863 30.55/0.8372 30.98/0.8401 31.15/0.8522 30.73/0.8417 31.31/0.8561 31.39/0.8572 31.45/0.8595 32.96/0.8889 4 27.30/0.7036 28.40/0.7561 28.77/0.7729 28.99/0.7753 28.61/0.7626 29.17/0.7824 29.21/0.7850 29.38/0.7909 29.99/0.8177
下载: 导出CSV
表 3 AID 数据集中放大因子为×4时每个类别的平均 PSNR
Table 3. Average PSNR for each category with an upscaling factor of ×4 on the AID dataset
Class PSNR/dB Bicubic SRCNN LGCNet VDSR DCM HSENet TransENet Ours Airport 27.03 28.17 28.39 28.82 28.99 29.03 29.23 29.31 Bareland 34.88 35.63 35.78 35.98 36.17 36.21 36.20 36.42 Baseball field 29.06 30.51 30.75 31.18 31.36 31.23 31.59 31.28 Beach 31.07 31.92 32.08 32.29 32.45 32.76 32.55 33.51 Bridge 28.98 30.41 30.67 31.19 31.39 31.30 31.63 30.83 Center 25.26 26.59 26.92 27.48 27.72 27.84 28.03 27.44 Church 22.15 23.41 23.68 24.12 24.29 24.39 24.51 24.62 Commercial 25.83 27.05 27.24 27.62 27.78 27.99 27.97 28.39 Dense residential 23.05 24.13 24.33 24.70 24.87 24.44 25.13 24.62 Desert 38.49 38.84 39.06 39.13 39.27 39.37 39.31 38.99 Farmland 32.30 33.48 33.77 34.20 34.42 33.90 34.58 34.19 Forest 27.39 28.15 28.20 28.36 28.47 38.31 28.56 28.37 Industrial 24.75 26.00 26.24 26.72 26.92 26.99 27.21 27.30 Meadow 32.06 32.57 32.65 32.77 32.88 32.74 32.94 33.30 Medium residential 26.09 27.37 27.63 28.06 28.25 28.11 28.45 26.94 Mountain 28.04 28.90 28.97 29.11 29.18 29.26 29.28 28.89 Park 26.23 27.25 27.37 27.69 27.82 28.23 28.01 28.11 Parking 22.33 24.01 24.40 25.21 25.74 26.17 26.40 26.01 Playground 27.27 28.72 29.04 29.62 29.92 31.18 30.30 32.00 Pond 28.94 29.85 30.00 30.26 30.39 30.40 30.53 30.33 Port 24.69 25.82 26.02 26.43 26.62 26.92 26.91 27.47 Railway station 26.31 27.55 27.76 28.19 28.38 28.47 28.61 28.42 Resort 25.98 27.12 27.32 27.71 27.88 27.99 28.08 27.66 River 29.61 30.48 30.60 30.82 30.91 30.88 31.00 30.28 School 24.91 26.13 26.34 26.78 26.94 27.51 27.22 27.52 Sparse residential 25.41 26.16 26.27 26.46 26.53 26.44 26.43 26.58 Square 26.75 28.13 28.39 28.91 29.13 29.05 29.39 28.79 Stadium 24.81 26.10 26.37 26.88 27.10 27.28 27.41 28.01 Storage tanks 24.18 25.27 25.48 25.86 26.00 26.07 26.20 26.80 Viaduct 25.86 27.03 27.26 27.74 27.93 28.12 28.21 28.01 AVG 27.30 28.40 28.61 28.99 29.17 29.21 29.38 29.99
下载: 导出CSV
表 4 LPIPS 在尺度为×2、×3和×4时的 UCMerced LandUse 数据集上的结果
Table 4. LPIPS results on the UCMerced LandUse dataset with scaling factors of ×2, ×3, and ×4
Scale LPIPS Bicubic SRCNN FSRCNN VDSR LGCNet DCM HSENet TransENet Ours 2 0.0721 0.0444 0.0471 0.0287 0.0293 0.0284 0.0266 0.0279 0.0256 3 0.1281 0.0945 0.1062 0.0801 0.0752 0.0698 0.0654 0.0649 0.0641 4 0.1650 0.1260 0.1395 0.1102 0.1093 0.1046 0.1081 0.1030 0.1022
下载: 导出CSV
表 5 模块结构的消融结果
Table 5. Ablation results of module structures
Model GISM CESSM CECSM PSNR/dB SSIM Model 0 × × × 36.81 0.9609 Model 1 √ × × 36.86 0.9613 Model 2 √ √ × 36.90 0.9615 Model 3 (ours) √ √ √ 36.93 0.9617
下载: 导出CSV
表 6 多尺度前馈神经网络(MSFFN)消融结果
Table 6. Ablation results of the multi-scale feedforward neural network (MSFFN)
Method Params/M FLOPs/G PSNR/dB $ 3\times 3 $ 1.98 126 36.91 $ 5\times 5 $ 2.08 140 36.88 $ 7\times 7 $ 2.35 157 36.90 MSFFN (ours) 2.13 147 36.93
下载: 导出CSV
表 7 多尺度前馈神经网络(MSFFN)与其他代表性前馈神经网络的对比分析
Table 7. Comparison analysis of the multi-scale feedforward neural network (MSFFN) with other representative feedforward neural networks
Method Param/M FLOPs/G PSNR/dB MLP 1.96 120 36.85 Conv-FFN 2.02 131 36.88 GDFN 2.09 142 36.89 MSFFN (ours) 2.13 147 36.93
下载: 导出CSV
表 8 ADAN与其他代表性CNN-Transformer架构的对比分析
Table 8. Comparison analysis of ADAN with other representative CNN-Transformer architectures
Method PSNR/dB SSIM TransENet 35.43 0.9355 Spatial dimension Transformer 35.52 0.9521 Frequency dimension Transformer 35.56 0.9602 ADAN(ours) 35.62 0.9719
下载: 导出CSV
表 9 模型复杂性分析
Table 9. Model complexity analysis
Method Param/M Flops/G PSNR/dB LGCNet 0.193 7.11 33.48 DCM 2.180 7.32 33.65 HSENet 5.400 10.80 34.22 TransENet 37.800 9.32 35.43 ADAN(ours) 4.120 7.16 35.62
下载: 导出CSV
-
参考文献
[1] 陈明惠, 芦焱琦, 杨文逸, 等. OCT图像多教师知识蒸馏超分辨率重建[J]. 光电工程, 2024, 51(7): 240114. doi: 10.12086/oee.2024.240114
Chen M H, Lu Y Q, Yang W Y, et al. Super-resolution reconstruction of retinal OCT image using multi-teacher knowledge distillation network[J]. Opto-Electron Eng, 2024, 51(7): 240114. doi: 10.12086/oee.2024.240114
[2] 肖振久, 张杰浩, 林渤翰. 特征协同与细粒度感知的遥感图像小目标检测[J]. 光电工程, 2024, 51(6): 240066. doi: 10.12086/oee.2024.240066
Xiao Z J, Zhang J H, Lin B H. Feature coordination and fine-grained perception of small targets in remote sensing images[J]. Opto-Electron Eng, 2024, 51(6): 240066. doi: 10.12086/oee.2024.240066
[3] Wu L S, Fang L Y, Yue J, et al. Deep bilateral filtering network for point-supervised semantic segmentation in remote sensing images[J]. IEEE Trans Image Process, 2022, 31: 7419−7434. doi: 10.1109/TIP.2022.3222904
[4] Yang J Q, Du B, Xu Y H, et al. Can spectral information work while extracting spatial distribution?—An online spectral information compensation network for HSI classification[J]. IEEE Trans Image Process, 2023, 32: 2360−2373. doi: 10.1109/TIP.2023.3244414
[5] Sitaula C, Kc S, Aryal J. Enhanced multi-level features for very high resolution remote sensing scene classification[J]. Neural Comput Appl, 2024, 36(13): 7071−7083. doi: 10.1007/s00521-024-09446-y
[6] Zhang C, Lam K M, Liu T S, et al. Structured adversarial self-supervised learning for robust object detection in remote sensing images[J]. IEEE Trans Geosci Remote Sens, 2024, 62: 5613720. doi: 10.1109/TGRS.2024.3375398
[7] 禹文奇, 程塨, 王美君, 等. MAR20: 遥感图像军用飞机目标识别数据集[J]. 遥感学报, 2023, 27(12): 2688−2696. doi: 10.11834/jrs.20222139
Yu W Q, Cheng G, Wang M J, et al. MAR20: a benchmark for military aircraft recognition in remote sensing images[J]. Natl Remote Sens Bull, 2023, 27(12): 2688−2696. doi: 10.11834/jrs.20222139
[8] 张文雪, 罗一涵, 刘雅卿, 等. 基于主动位移成像的图像超分辨率重建[J]. 光电工程, 2024, 51(1): 230290. doi: 10.12086/oee.2024.230290
Zhang W X, Luo Y H, Liu Y Q, et al. Image super-resolution reconstruction based on active displacement imaging[J]. Opto-Electron Eng, 2024, 51(1): 230290. doi: 10.12086/oee.2024.230290
[9] 程德强, 马祥, 寇旗旗, 等. 基于多路特征校准的轻量级图像超分辨率重建算法[J]. 计算机辅助设计与图形学学报, 2025, 36(12): 241211 doi: 10.3724/SP.J.1089.2024-00306
Cheng D Q, Ma X, Kou Q Q, et al. Lightweight image super-resolution reconstruction algorithm based on multi-path feature calibration[J]. J Comput-Aided Des Comput Graph, 2025, 36(12): 241211 doi: 10.3724/SP.J.1089.2024-00306
[10] Dong C, Loy C C, He K M, et al. Learning a deep convolutional network for image super-resolution[C]//Proceedings of the 13th European Conference on Computer Vision, 2014: 184‒199. https://doi.org/10.1007/978-3-319-10593-2_13.
[11] Mei Y Q, Fan Y C, Zhou Y Q. Image super-resolution with non-local sparse attention[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 3517–3526. https://doi.org/10.1109/CVPR46437.2021.00352.
[12] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1646–1654. https://doi.org/10.1109/CVPR.2016.182.
[13] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 6000–6010.
[14] Chen X Y, Wang X T, Zhou J T, et al. Activating more pixels in image super-resolution Transformer[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 22367–22377. https://doi.org/10.1109/CVPR52729.2023.02142.
[15] Yang F Z, Yang H, Fu J L, et al. Learning texture Transformer network for image super-resolution[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 5791–5800. https://doi.org/10.1109/CVPR42600.2020.00583.
[16] Lu Z S, Li J C, Liu H, et al. Transformer for single image super-resolution[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2022: 457–466. https://doi.org/10.1109/CVPRW56347.2022.00061.
[17] Liang J Y, Cao J Z, Sun G L, et al. SwinIR: image restoration using Swin Transformer[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision Workshops, 2021: 1833–1844. https://doi.org/10.1109/ICCVW54120.2021.00210.
[18] Zhang X D, Zeng H, Guo S, et al. Efficient long-range attention network for image super-resolution[C]//Proceedings of the 17th European Conference on Computer Vision, 2022: 649–667. https://doi.org/10.1007/978-3-031-19790-1_39.
[19] 王志浩, 钱沄涛. 基于Swin Transformer的双流遥感图像时空融合超分辨率重建[J]. 计算机工程, 2024, 50(9): 33−45. doi: 10.19678/j.issn.1000-3428.0068296
Wang Z H, Qian Y T. Super-resolution reconstruction of spatiotemporal fusion for dual-stream remote sensing images based on Swin Transformer[J]. Comput Eng, 2024, 50(9): 33−45. doi: 10.19678/j.issn.1000-3428.0068296
[20] Lei S, Shi Z W, Zou Z X. Super-resolution for remote sensing images via local–global combined network[J]. IEEE Geosci Remote Sens Lett, 2017, 14(8): 1243−1247. doi: 10.1109/LGRS.2017.2704122
[21] Jiang K, Wang Z Y, Yi P, et al. Deep distillation recursive network for remote sensing imagery super-resolution[J]. Remote Sens, 2018, 10(11): 1700. doi: 10.3390/rs10111700
[22] Jiang K, Wang Z Y, Yi P, et al. Edge-enhanced GAN for remote sensing image superresolution[J]. IEEE Trans Geosci Remote Sens, 2019, 57(8): 5799−5812. doi: 10.1109/TGRS.2019.2902431
[23] Jiang K, Wang Z Y, Yi P, et al. Hierarchical dense recursive network for image super-resolution[J]. Pattern Recognit, 2020, 107: 107475. doi: 10.1016/j.patcog.2020.107475
[24] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90.
[25] Lim B, Son S, Kim H, et al. Enhanced deep residual networks for single image super-resolution[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017: 136–144. https://doi.org/10.1109/CVPRW.2017.151.
[26] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proceedings of the 32nd International Conference on Machine Learning, 2015: 448–456.
[27] Dong C, Loy C C, He K M, et al. Image super-resolution using deep convolutional networks[J]. IEEE Trans Pattern Anal Mach Intell, 2016, 38(2): 295−307. doi: 10.1109/TPAMI.2015.2439281
[28] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[29] Niu B, Wen W L, Ren W Q, et al. Single image super-resolution via a holistic attention network[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 191–207. https://doi.org/10.1007/978-3-030-58610-2_12.
[30] Zhang Y L, Li K P, Li K, et al. Image super-resolution using very deep residual channel attention networks[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 286–301. https://doi.org/10.1007/978-3-030-01234-2_18.
[31] Lei S, Shi Z W. Hybrid-scale self-similarity exploitation for remote sensing image super-resolution[J]. IEEE Trans Geosci Remote Sens, 2022, 60: 5401410. doi: 10.1109/TGRS.2021.3069889
[32] Zhang W D, Zhao W Y, Li J, et al. CVANet: cascaded visual attention network for single image super-resolution[J]. Neural Netw, 2024, 170: 622−634. doi: 10.1016/j.neunet.2023.11.049
[33] 祝冰艳, 陈志华, 盛斌. 基于感知增强Swin Transformer的遥感图像检测[J]. 计算机工程, 2024, 50(1): 216−223. doi: 10.19678/j.issn.1000-3428.0066941
Zhu B Y, Chen Z H, Sheng B. Remote sensing image detection based on perceptually enhanced Swin Transformer[J]. Comput Eng, 2024, 50(1): 216−223. doi: 10.19678/j.issn.1000-3428.0066941
[34] 张艳月, 张宝华, 赵云飞, 等. 基于双通道深度密集特征融合的遥感影像分类[J]. 激光技术, 2021, 45(1): 73−79. doi: 10.7510/jgjs.issn.1001-3806.2021.01
Zhang Y Y, Zhang B H, Zhao Y F, et al. Remote sensing image classification based on dual-channel deep dense feature fusion[J]. Laser Technol, 2021, 45(1): 73−79. doi: 10.7510/jgjs.issn.1001-3806.2021.01
[35] Salvetti F, Mazzia V, Khaliq A, et al. Multi-image super resolution of remotely sensed images using residual attention deep neural networks[J]. Remote Sens, 2020, 12(14): 2207. doi: 10.3390/rs12142207
[36] Dong X Y, Sun X, Jia X P, et al. Remote sensing image super-resolution using novel dense-sampling networks[J]. IEEE Trans Geosci Remote Sens, 2021, 59(2): 1618−1633. doi: 10.1109/TGRS.2020.2994253
[37] Xiao Y, Yuan Q Q, Jiang K, et al. TTST: a top-k token selective transformer for remote sensing image super-resolution[J]. IEEE Trans Image Process, 2024, 33: 738−752. doi: 10.1109/TIP.2023.3349004
[38] Liu H X, Dai Z H, So D R, et al. Pay attention to MLPs[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021: 704.
[39] Dauphin Y N, Fan A, Auli M, et al. Language modeling with gated convolutional networks[C]//Proceedings of the 34th International Conference on Machine Learning, 2017: 933–941.
[40] Song Y D, He Z Q, Qian H, et al. Vision transformers for single image Dehazing[J]. IEEE Trans Image Process, 2023, 32: 1927−1941. doi: 10.1109/TIP.2023.3256763
[41] Ba J L, Kiros J R, Hinton G E. Layer normalization[Z]. arXiv: 1607.06450, 2016. https://doi.org/10.48550/arXiv.1607.06450.
[42] Yang Y, Newsam S. Bag-of-visual-words and spatial extensions for land-use classification[C]//Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, 2010: 270–279. https://doi.org/10.1145/1869790.1869829.
[43] Xia G S, Hu J W, Hu F, et al. AID: a benchmark data set for performance evaluation of aerial scene classification[J]. IEEE Trans Geosci Remote Sens, 2017, 55(7): 3965−3981. doi: 10.1109/TGRS.2017.2685945
[44] Lei S, Shi Z W, Mo W J. Transformer-based multistage enhancement for remote sensing image super-resolution[J]. IEEE Trans Geosci Remote Sens, 2022, 60: 5615611. doi: 10.1109/TGRS.2021.3136190
[45] Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans Image Process, 2004, 13(4): 600−612. doi: 10.1109/TIP.2003.819861
[46] Zhang R, Isola P, Efros A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 586–595. https://doi.org/10.1109/CVPR.2018.00068.
[47] Kingma D P, Ba J. Adam: a method for stochastic optimization[Z]. arXiv: 1412.6980, 2014. https://doi.org/10.48550/arXiv.1412.6980.
[48] Dong C, Loy C C, Tang X O. Accelerating the super-resolution convolutional neural network[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 391‒407. https://doi.org/10.1007/978-3-319-46475-6_25.
[49] Haut J M, Paoletti M E, Fernández-Beltran R, et al. Remote sensing single-image superresolution based on a deep compendium model[J]. IEEE Geosci Remote Sens Lett, 2019, 16(9): 1432−1436. doi: 10.1109/LGRS.2019.2899576
-
访问统计

 点击扫一扫
点击扫一扫
图(11)
表(9)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


