
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
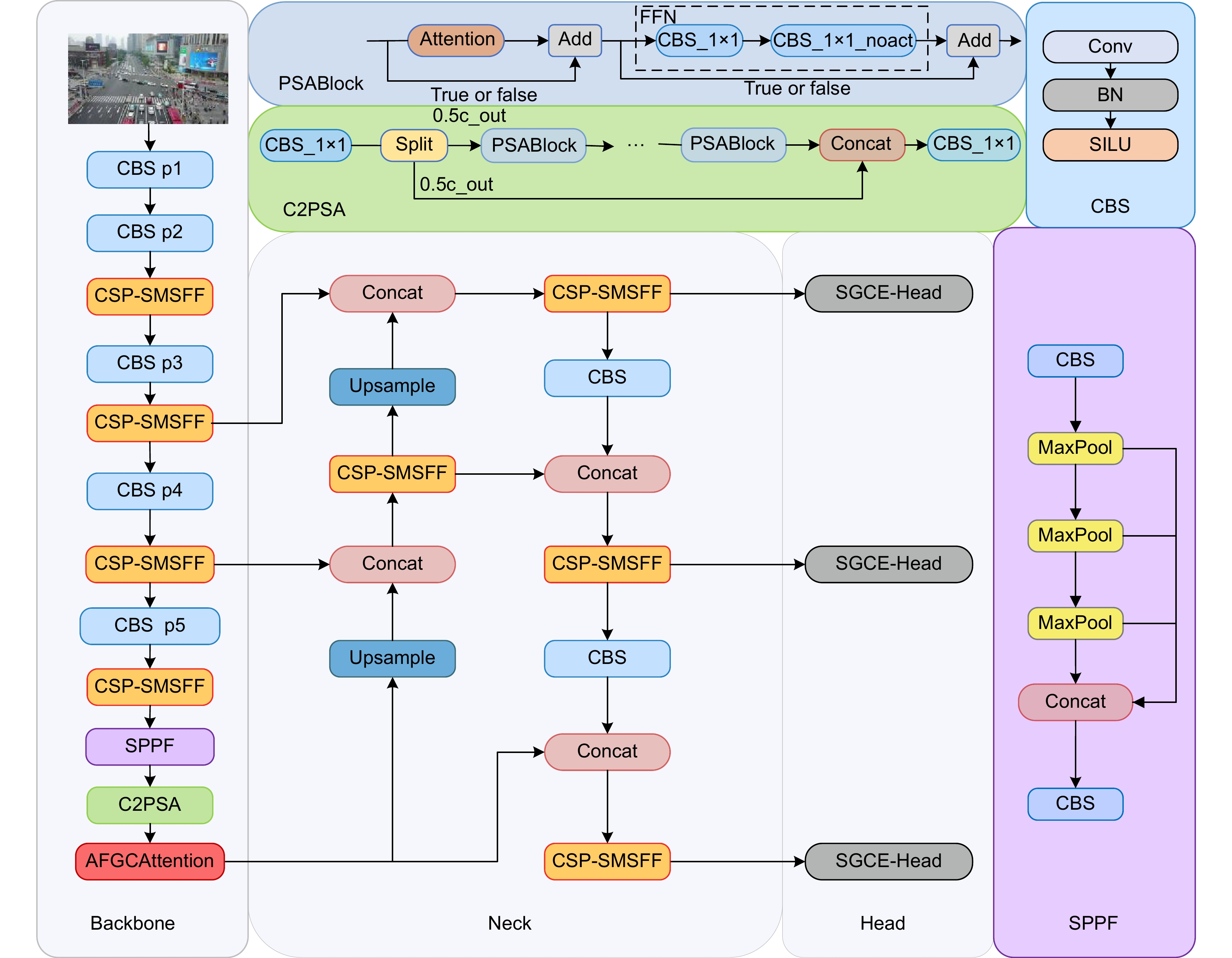
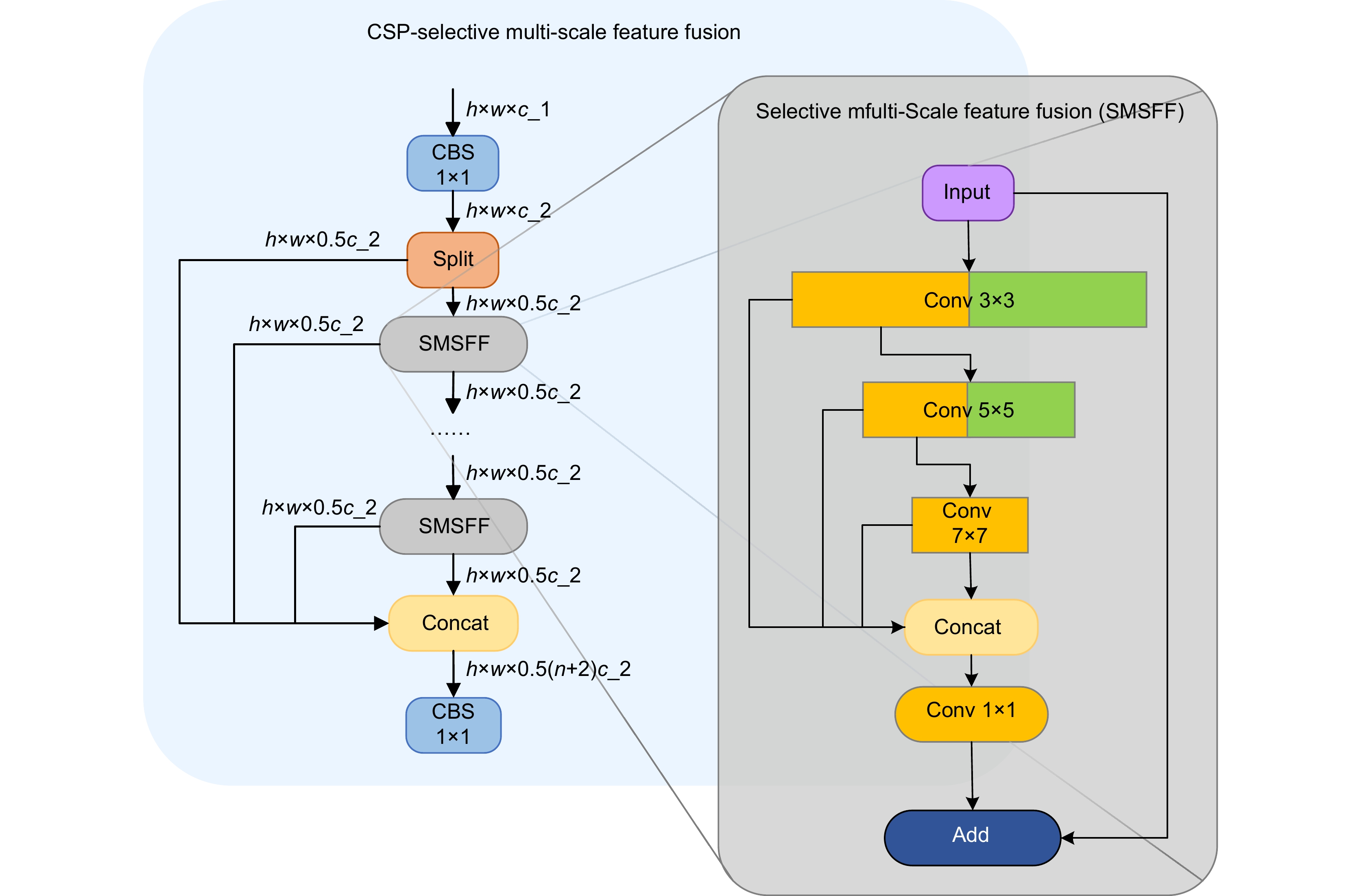
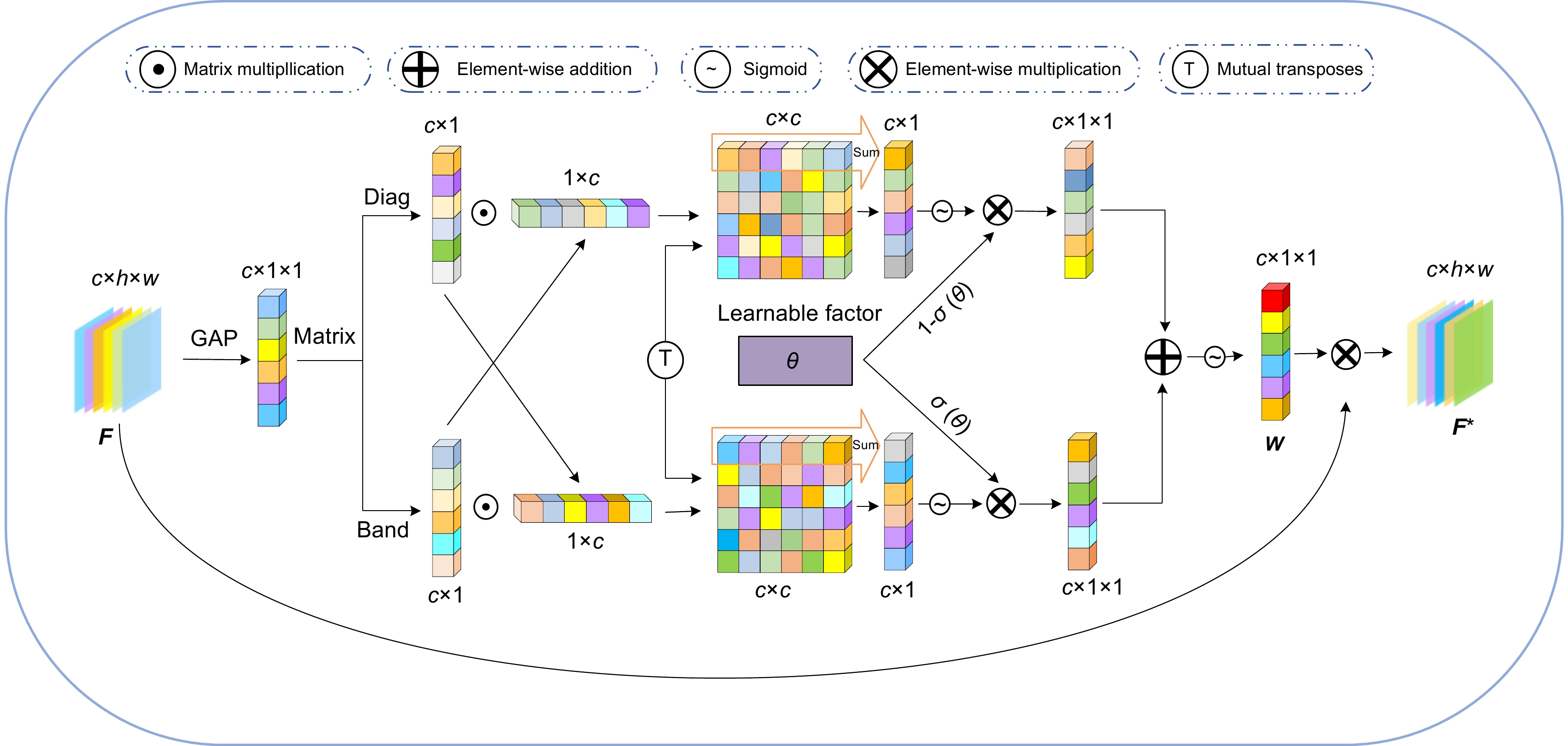
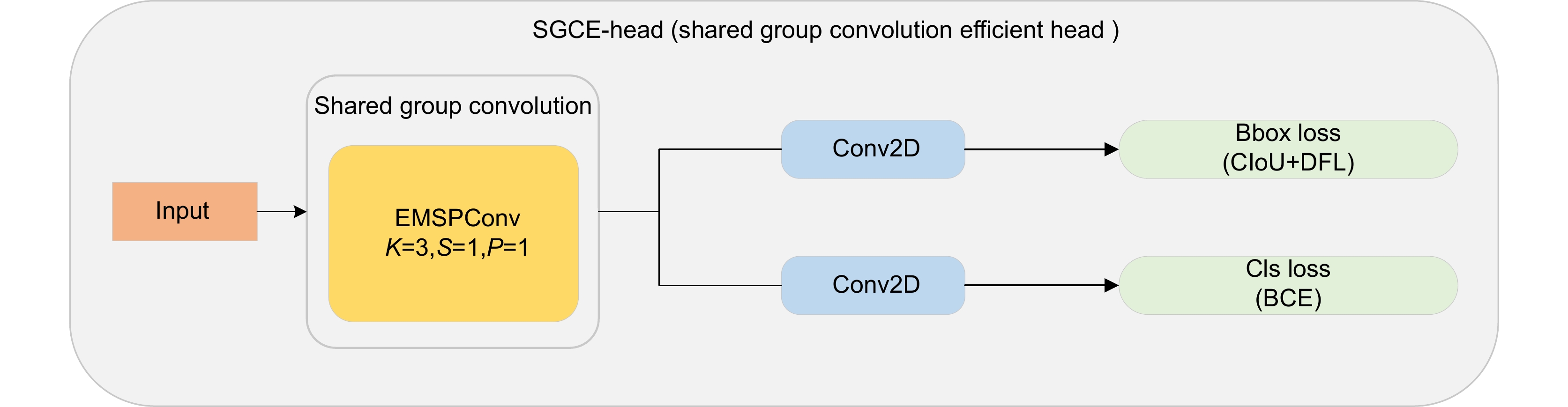
针对无人机图像中背景复杂、光线多变、目标遮挡及尺度不一导致的漏检、误检问题,提出一种多层次精细化无人机图像目标检测算法。首先,结合多尺度特征提取与特征融合增强策略,设计CSP-SMSFF (cross stage partial selective multi-scale feature fusion)模块,该模块通过递增卷积核与通道融合,精确捕获多尺度目标特征。其次,引入AFGCAttention (adaptive fine-grained channel attention)机制,通过动态调优机制优化通道特征表达,增强算法对多尺度重要样本特征的感知力与判别力及细粒度映射信息的保留能力,抑制背景噪声,改善漏检情况。而后,设计SGCE-Head (shared group convolution efficient head)检测头,利用EMSPConv (efficient multi-scale convolution)卷积实现对空间通道维度中全局重要特征与局部细节信息的精准捕获,增强对多尺度特征的定位与识别能力,改善误检问题。最后,提出Inner-Powerful-IoUv2损失函数,通过动态梯度加权与分层IoU优化,平衡不同质量样本的定位权重,增强模型对模糊目标的检测能力。采用数据集VisDrone2019和VisDrone2021进行实验,结果表明,该方法mAP@0.5数值达到了47.5%和45.3%,较基线模型分别提升5.7%和4.7%,优于对比算法。
-
关键词:
- 无人机图像 /
- 目标检测 /
- 多尺度特征提取与融合 /
- 自适应细粒度通道注意力 /
- EMSPConv
Abstract
To address the challenges of missed detection and false detection caused by complex backgrounds, varying illumination, target occlusion, and scale diversity in UAV images, this paper proposes a multi-level refined object detection algorithm for UAV imagery. First, a CSP-SMSFF (cross-stage partial selective multi-scale feature fusion) module is designed by integrating multi-scale feature extraction and feature fusion enhancement strategies. This module employs incremental convolutional kernels and channel-wise fusion to precisely capture multi-scale target features. Second, an AFGCAttention (adaptive fine-grained channel attention) mechanism is introduced, which optimizes channel feature representations through a dynamic fine-tuning mechanism. This enhances the algorithm’s sensitivity to critical multi-scale sample features, improves discriminative capability, preserves fine-grained mapping information, and suppresses background noise to mitigate missed detection. Third, a SGCE-Head (shared group convolution efficient head) detection head is developed, leveraging EMSPConv (efficient multi-scale convolution) to achieve precise capture of global salient features and local details in spatial-channel dimensions, thereby enhancing localization and recognition of multi-scale features and reducing false positives. Finally, the Inner-Powerful-IoUv2 loss function is proposed, which balances localization weights for samples of varying quality through dynamic gradient weighting and hierarchical IoU optimization, thereby strengthening the model’s capability to detect ambiguous targets. Experimental results on the VisDrone2019 and VisDrone2021 datasets benchmark demonstrate that the proposed method achieves 47.5% and 45.3% in mAP@0.5 under two evaluation settings, surpassing baseline models by 5.7% and 4.7%, respectively, and outperforming existing comparative algorithms.
-
Overview
Overview: In UAV (unmanned aerial vehicle) image target detection, challenges such as complex backgrounds, variable lighting conditions, target occlusion, and scale variations often lead to missed and false detections. To address these challenges and enhance both detection accuracy and robustness, we propose a multi-level fine-grained object detection algorithm for UAV images. This algorithm integrates several novel components and mechanisms aimed at improving feature representation across different scales, suppressing background noise, and accelerating model convergence, thus significantly optimizing detection performance. First, we introduce a cross-stage partial selective multi-scale feature fusion (CSP-SMSFF) module. This module combines multi-scale feature extraction and feature fusion enhancement strategies. By incrementally increasing convolution kernels and channel fusion, it accurately captures multi-scale target features. The CSP-SMSFF module effectively enhances the algorithm’s ability to handle targets of various sizes, which improves detection accuracy across different target scales, ensuring that small and large targets are both detected with high precision. Next, we incorporate the adaptive fine-grained channel attention (AFGCAttention) mechanism. This mechanism optimizes channel feature representations via dynamic tuning, improving the algorithm’s ability to perceive and discriminate important multi-scale sample features. It is particularly effective in handling complex backgrounds and occlusions, where the ability to retain fine-grained mapping information while suppressing background noise is crucial. This dynamic adjustment significantly reduces missed detections, especially for small and edge targets, thereby improving overall detection accuracy. Subsequently, we design the shared group convolution efficient (SGCE-Head) detection head, which utilizes efficient multi-scale convolution (EMSPConv) to capture both global important features and local fine details in the spatial-channel dimension. By improving the ability to locate and recognize multi-scale features, SGCE-Head addresses false detection issues and ensures that the algorithm distinguishes targets from backgrounds effectively, leading to more accurate and reliable results. Finally, we propose the Inner-Powerful-IoUv2 loss function. This function optimizes medium-quality anchor boxes and balances gradient strength for high and low IoU (intersection over union) samples. It enhances target localization accuracy and increases region attention, accelerating model convergence. The use of this loss function allows the model to achieve higher detection accuracy in a shorter amount of time, improving both its practical utility and efficiency. Experimental results on the VisDrone2019 and VisDrone2021 datasets demonstrate the effectiveness of our proposed method. Specifically, the algorithm achieves mAP@0.5 values of 47.5% and 45.3%, representing improvements of 5.7% and 4.7% over the baseline model. These results show that our algorithm not only outperforms existing state-of-the-art methods in terms of detection accuracy but also offers good versatility and real-time performance, making it suitable for a variety of application scenarios. In conclusion, the algorithm presented in this paper, by innovatively combining the CSP-SMSFF module, AFGCAttention mechanism, SGCE-Head detection head, and Inner-Powerful-IoUv2 loss function, provides a comprehensive solution to the core challenges of UAV image target detection. It significantly enhances detection accuracy, robustness, and real-time performance. This approach effectively addresses issues such as complex backgrounds, lighting variations, occlusion, and scale changes, while demonstrating strong versatility and achieving impressive results in practical applications.
-

-

图 1 无人机图像检测中的典型挑战示意图。(a)复杂背景;(b)光照突变;(c)目标遮挡;(d)尺度不一
Figure 1. Schematic illustration of typical challenges in UAV image detection. (a) Complex background; (b) Sudden change in illumination;(c) Target occlusion; (d) Inconsistent scales
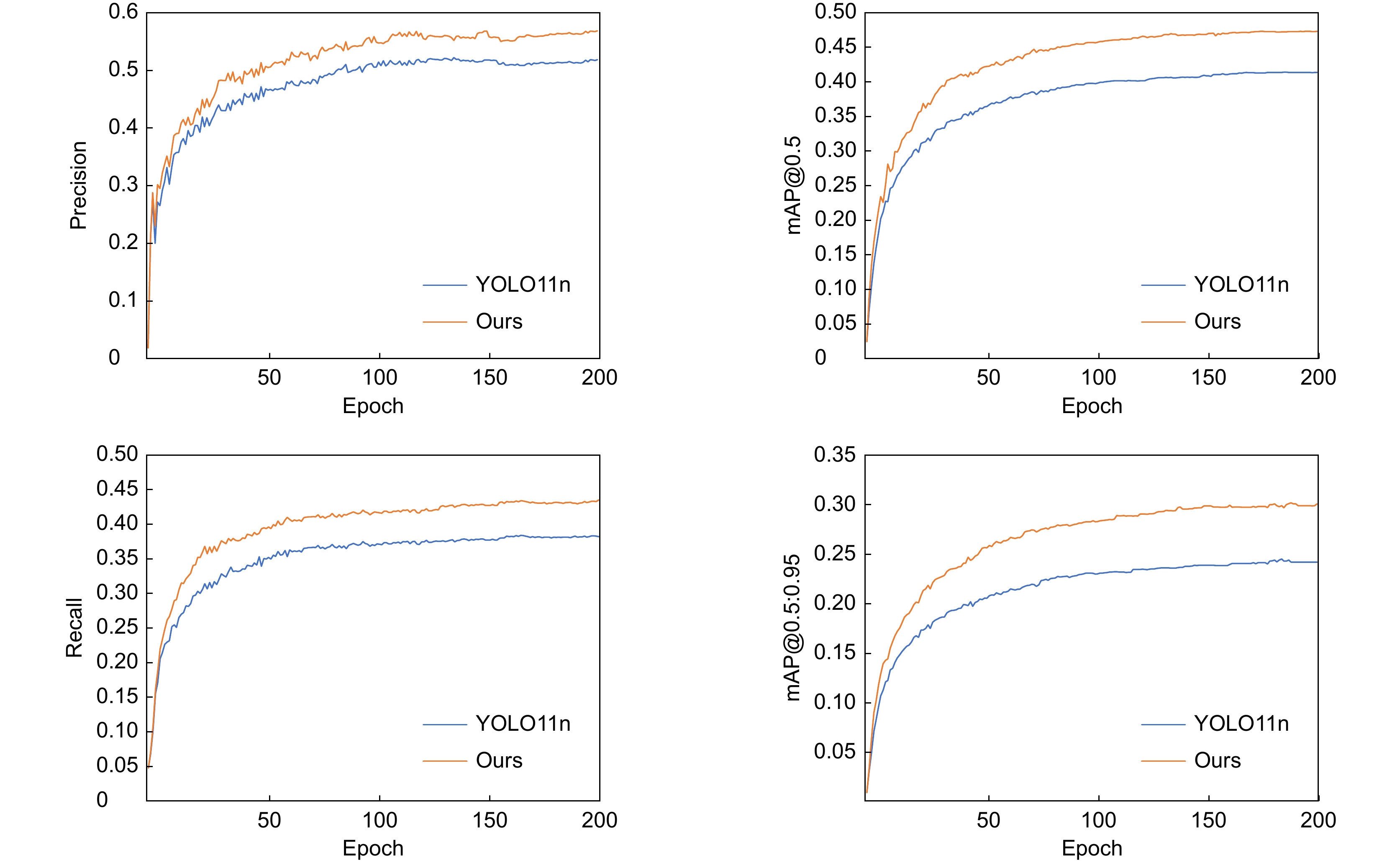
图 8 YOLO11n与改进模型各评价指标对比图
Figure 8. Comparison of evaluation metrics between YOLO11n and the improved model

图 9 在数据集VisDrone2019上的可视化效果对比
Figure 9. Comparison of visualization effects on dataset VisDrone2019

图 10 在数据集VisDrone2021上的可视化效果对比
Figure 10. Comparison of visualization effects on dataset VisDrone2021
表 1 各卷积核组合的数值对比
Table 1. Comparison of values for different convolution kernel combinations
Convolution kernel combination mAP@0.5/% mAP@0.5∶0.95/% Parameters/106 GFLOPs 2×2, 4×4, 6×6 41.5 22.0 2.8 3.9 3×3, 5×5, 7×7 45.2 26.5 3.5 5.8 3×3, 5×5, 8×8 46.5 27.8 4.7 6.5  下载: 导出CSV
下载: 导出CSV
表 2 实验环境
Table 2. Experimental environment
Environment Model Operating system Ubuntu 18.04 CPU Xeon(R) Gold 6430 GPU RTX 2080 Ti (11 GB) Programming language Python 3.10.0 CUDA 12.4
下载: 导出CSV
表 3 训练参数
Table 3. Training parameters
Parameter Setting Training epochs 200 Batch size 64 Input image size 640×640 Initial learning rate 0.01
下载: 导出CSV
表 4 所提算法在VisDrone2019数据集上的消融实验结果
Table 4. Ablation experiment results of the proposed algorithm on the VisDrone2019 dataset
Model Precision/% Recall/% mAP@0.5/% mAP@0.5∶0.95/% Parameters/106 GFLOPs YOLO11n 51.5 38.3 41.8 24.1 2.5 4.3 + CSP-SMSFF 52.7 40.2 45.2 26.5 3.5 5.8 + AFGCAttention 55.2 38.9 45.8 27.1 2.6 5.4 + SGCE-Head 51.3 37.5 42.3 25.4 2.3 4.5 +IPIoUv2 51.4 38.6 41.9 25.0 2.5 4.3 + CSP-SMSFF + AFGCAttention 56.2 41.6 46.8 28.2 3.6 7.0 + CSP-SMSFF + AFGCAttention + SGCE-Head 56.7 42.8 47.4 29.7 3.3 7.3 + CSP-SMSFF + AFGCAttention + SGCE-Head + IPIoUv2 56.8 43.5 47.5 30.0 3.3 7.3
下载: 导出CSV
表 5 不同模型在VisDrone2019数据集上的对比
Table 5. Comparison of different models on the VisDrone2019 dataset
Model Precision/% Recall/% mAP@0.5/% mAP@0.5∶0.95/% FPS RetinaNet 35.5 21.9 20.3 12.5 26 Faster R-CNN 48.0 35.1 35.0 21.9 23 Deformmable-DETR 52.4 45.0 44.4 28.3 69 BDAD-YOLO 45.6 35.7 36.1 20.7 122 YOLOv10n 47.7 36.0 37.0 21.2 146 SSG-YOLOv7 48.6 37.1 42.6 24.6 98 YOLOv8 50.5 38.5 45.4 27.4 63 Ours 56.8 43.5 47.5 30.0 145
下载: 导出CSV
表 6 不同模型在数据集VisDrone2021上的对比
Table 6. Comparison of different models on VisDrone2021 dataset
Model Precision/% Recall/% mAP@0.5/% mAP@0.5∶0.95/% FPS RetinaNet 31.5 18.9 15.3 10.5 21 Faster R-CNN 46.1 33.6 32.3 18.8 20 Deformable-DETR 51.5 42.1 42.0 22.4 62 BDAD-YOLO 43.2 33.6 34.3 17.8 112 YOLOv10n 45.4 36.1 36.4 18.7 140 SSG-YOLOv7 47.9 37.6 40.7 22.2 96 YOLOv8 49.4 40.1 43.6 24.7 60 Ours 53.2 41.8 45.3 26.4 140
下载: 导出CSV
-
参考文献
[1] 陈旭, 彭冬亮, 谷雨. 基于改进YOLOv5s的无人机图像实时目标检测[J]. 光电工程, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
Chen X, Peng D L, Gu Y. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electron Eng, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
[2] Xiong X R, He M T, Li T Y, et al. Adaptive feature fusion and improved attention mechanism-based small object detection for UAV target tracking[J]. IEEE Internet Things J, 2024, 11(12): 21239−21249. doi: 10.1109/JIOT.2024.3367415
[3] 马梁, 苟于涛, 雷涛, 等. 基于多尺度特征融合的遥感图像小目标检测[J]. 光电工程, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363
Ma L, Gou Y T, Lei T, et al. Small object detection based on multi-scale feature fusion using remote sensing images[J]. Opto-Electron Eng, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363
[4] Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), 2005: 886–893. https://doi.org/10.1109/CVPR.2005.177.
[5] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031
[6] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), 2017: 2980–2988. https://doi.org/10.1109/ICCV.2017.322.
[7] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 779–788. https://doi.org/10.1109/CVPR.2016.91.
[8] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 6517–6525. https://doi.org/10.1109/CVPR.2017.690.
[9] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: optimal speed and accuracy of object detection[Z]. arXiv: 2004.10934, 2020. https://doi.org/10.48550/arXiv.2004.10934.
[10] Ge Z, Liu S T, Wang F, et al. YOLOX: exceeding YOLO series in 2021[Z]. arXiv: 2107.08430, 2021. https://doi.org/10.48550/arXiv.2107.08430.
[11] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//14th European Conference on Computer Vision, 2016: 21–37. https://doi.org/10.1007/978-3-319-46448-0_2.
[12] Misbah M, Orakazi F A, Tanveer L, et al. TF-BiFPN improves YOLOv5: enhancing small-scale multiclass drone detection in dark[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(2): 5354-5361. https://ieeexplore.ieee.org/document/10684481.
[13] Yu C, Shin Y. MCG-RTDETR: multi-convolution and context-guided network with cascaded group attention for object detection in unmanned aerial vehicle imagery[J]. Remote Sensing, 2024, 16(17): 3169 doi: 10.3390/rs16173169
[14] Kang M, Ting C M, Ting F F, et al. BGF-YOLO: enhanced YOLOv8 with multiscale attentional feature fusion for brain tumor detection[C]//Medical Image Computing and Computer Assisted Intervention – MICCAI 2024, 2024, 15008: 35–45. https://doi.org/10.1007/978-3-031-72111-3_4.
[15] 黄毅, 周纯, 刘欣军, 等. 基于YOLOv10的无人机复杂背景下多尺度检测模型[J/OL]. 光通信研究, 2024: 1–8[2024-11-26]. http://kns.cnki.net/kcms/detail/42.1266.TN.20240822.1307.002.html.
Huang Y, Zhou C, Liu X J, et al. Multiscale detection model for complex backgrounds in UAV Images based on YOLOv10[J/OL]. Study Opt Commun, 2024: 1–8. [2024-11-26]. http://kns.cnki.net/kcms/detail/42.1266.TN.20240822.1307.002.html.
[16] 谌海云, 肖章勇, 郭勇, 等. 基于改进YOLOv8s的无人机航拍目标检测算法[J]. 电光与控制, 2024, 31(12): 55−63. doi: 10.3969/j.issn.1671-637X.2024.12.009
Chen H Y, Xiao Z Y, Guo Y, et al. A UAV aerial target detection algorithm based on improved YOLOv8s[J]. Electron Opt Control, 2024, 31(12): 55−63. doi: 10.3969/j.issn.1671-637X.2024.12.009
[17] 赵青, 察豪, 牟伟琦, 等. 一种基于改进YOLOv7的无人机多目标光学检测方法[J]. 电讯技术, 2024, 64(8): 1213−1218. doi: 10.20079/j.issn.1001-893x.230704002
Zhao Q, Cha H, Mu W Q, et al. A multi-target optical detection method for UAV based on improved YOLOv7[J]. Telecommun Eng, 2024, 64(8): 1213−1218. doi: 10.20079/j.issn.1001-893x.230704002
[18] 李姝, 李思远, 刘国庆. 基于YOLOv8无人机航拍图像的小目标检测算法研究[J]. 小型微型计算机系统, 2024, 45(9): 2165−2174. doi: 10.20009/j.cnki.21-1106/TP.2024-0329
Li S, Li S Y, Liu G Q. Research on small target detection algorithm based on YOLOv8 UAV aerial images[J]. J Chin Comput Syst, 2024, 45(9): 2165−2174. doi: 10.20009/j.cnki.21-1106/TP.2024-0329
[19] Yaseen M. What is YOLOv8: an in-depth exploration of the internal features of the next-generation object detector[Z]. arXiv: 2408.15857, 2024. https://doi.org/10.48550/arXiv.2408.15857.
[20] 张润梅, 肖钰霏, 贾振楠, 等. 改进YOLOv7的无人机视角下复杂环境目标检测算法[J]. 光电工程, 2024, 51(5): 240051. doi: 10.12086/oee.2024.240051
Zhang R M, Xiao Y F, Jia Z N, et al. Improved YOLOv7 algorithm for target detection in complex environments from UAV perspective[J]. Opto-Electron Eng, 2024, 51(5): 240051. doi: 10.12086/oee.2024.240051
[21] 赵继达, 甄国涌, 储成群. 基于YOLOv8的无人机图像目标检测算法[J]. 计算机工程, 2024, 50(4): 113−120. doi: 10.19678/j.issn.1000-3428.0068268
Zhao J D, Zhen G Y, Chu C Q. Unmanned aerial vehicle image target detection algorithm based on YOLOv8[J]. Comput Eng, 2024, 50(4): 113−120. doi: 10.19678/j.issn.1000-3428.0068268
[22] 孟鹏帅, 王峰, 翟伟光, 等. 基于YOLO-DSBE的无人机对地目标检测[J]. 航空兵器, 2025, 32(2): 94−103. doi: 10.12132/ISSN.1673-5048.2024.0064
Meng P S, Wang F, Zhai W G, et al. UAV-to-ground target detection based on YOLO-DSBE[J]. Aero Weaponry, 2025, 32(2): 94−103. doi: 10.12132/ISSN.1673-5048.2024.0064
[23] Khanam R, Hussain M. YOLOv11: an overview of the key architectural enhancements[Z]. arXiv: 2410.17725, 2024. https://doi.org/10.48550/arXiv.2410.17725.
[24] Jegham N, Koh C Y, Abdelatti M, et al. Evaluating the evolution of YOLO (you only look once) models: a comprehensive benchmark study of YOLO11 and its predecessors[Z]. arXiv: 2411.00201, 2024. https://doi.org/10.48550/arXiv.2411.00201.
[25] Liu G L, Reda F A, Shih K J, et al. Image inpainting for irregular holes using partial convolutions[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 85–105. https://doi.org/10.1007/978-3-030-01252-6_6.
[26] Sun H, Wen Y, Feng H J, et al. Unsupervised bidirectional contrastive reconstruction and adaptive fine-grained channel attention networks for image Dehazing[J]. Neural Networks, 2024, 176: 106314. doi: 10.1016/j.neunet.2024.106314
[27] Wang C Y, Mark Liao H Y, Wu Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020: 1571–1580. https://doi.org/10.1109/CVPRW50498.2020.00203.
[28] Han K, Wang Y H, Tian Q, et al. GhostNet: More features from cheap operations[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 1577–1586. https://doi.org/10.1109/CVPR42600.2020.00165.
[29] Zheng P, Hu Y F, Chen Y H. Application of enhancing YOLOv8 algorithm using FasterNet structure in human pose estimation[C]//Proceedings of the 9th International Conference on Computer and Communication Systems (ICCCS), 2024: 207–212. https://doi.org/10.1109/ICCCS61882.2024.10603101.
[30] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[31] Wen G H, Li M, Luo Y H, et al. The improved YOLOv8 algorithm based on EMSPConv and SPE-head modules[J]. Multimed Tools Appl, 2024, 83(5): 2957−2972. doi: 10.1007/s11042-023-17957-4
[32] Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 5987–5995. doi: 10.1109/CVPR.2017.634.
[33] Zheng Z H, Wang P, Liu W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, 2020: 12993–13000. https://doi.org/10.1609/aaai.v34i07.6999.
[34] Zhang H, Xu C, Zhang S J. Inner-IoU: more effective intersection over union loss with auxiliary bounding box[Z]. arXiv: 2311.02877, 2023. https://doi.org/10.48550/arXiv.2311.02877.
[35] Liu C, Wang K G, Li Q, et al. Powerful-IoU: more straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism[J]. Neural Networks, 2024, 170: 276−284. doi: 10.1016/j.neunet.2023.11.041
[36] Du D W, Zhu P F, Wen L Y, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop, 2019: 213–226. https://doi.org/10.1109/ICCVW.2019.00030.
[37] Cao Y R, He Z J, Wang L J, et al. VisDrone-DET2021: the vision meets drone object detection challenge results[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, 2021: 2847–2854. https://doi.org/10.1109/ICCVW54120.2021.00319.
[38] Wang Y Y, Wang C, Zhang H, et al. Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery[J]. Remote Sens, 2019, 11(5): 531. doi: 10.3390/rs11050531
[39] Zhu X Z, Su W J, Lu L W, et al. Deformable DETR: deformable transformers for end-to-end object detection[C]//9th International Conference on Learning Representations, 2021.
[40] 孙佳宇, 徐民俊, 张俊鹏, 等. 优化改进YOLOv8无人机视角下目标检测算法[J]. 计算机工程与应用, 2025, 61(1): 109−120. doi: 10.3778/j.issn.1002-8331.2405-0030
Sun J Y, Xu M J, Zhang J P, et al. Optimized and improved YOLOv8 target detection algorithm from UAV perspective[J]. Comput Eng Appl, 2025, 61(1): 109−120. doi: 10.3778/j.issn.1002-8331.2405-0030
[41] Wang A, Chen H, Liu L H, et al. YOLOv10: real-time end-to-end object detection[C]//Proceedings of the 38th International Conference on Neural Information Processing Systems, 2024.
-
访问统计



 点击扫一扫
点击扫一扫
图(11)
表(6)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


