
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
针对基于边界框检测的单阶段YOLACT算法缺少对感兴趣区域进行定位提取,且两个边界框存在相互重叠而难以区分的问题,基于改进的YOLACTR算法,提出一种无锚框实例分割方法,将掩码生成解耦成特征学习和卷积核学习,利用特征聚合网络生成掩码特征,将位置信息添加到特征图,采用多层Transformer和双向注意力来获得动态卷积核。实验结果表明,该方法在MS COCO公共数据集的掩码精度(AP)达到35.2%,相对于YOLACT算法,掩码精度提升25.7%,小目标检测精度提升37.1%,中等目标检测精度提升25.8%,大目标检测精度提升21.9%。相较YOLACT、Mask R-CNN、SOLO等方法,所提算法在分割精度和边缘细节保留方面均具有明显优势,特别在重叠物体的分割和小目标检测中表现更为出色,有效解决传统方法在实例边界重叠区域的错误分割问题。
-
关键词:
- YOLACT /
- 无锚框实例分割 /
- 动态卷积 /
- Transformer
Abstract
Aiming at the problem that the single-stage YOLACT algorithm based on bounding box detection lacks the location and extraction of the region of interest, and the issue that two bounding boxes overlap and are difficult to distinguish, this paper proposes an anchor-free instance segmentation method based on the improved YOLACTR algorithm. The mask generation is decoupled into feature learning and convolution kernel learning, and the feature aggregation network is used to generate mask features. By adding position information to the feature map, multi-layer transformer and two-way attention are used to obtain dynamic convolution kernels. The experimental results show that this method achieves a mask accuracy (AP) of 35.2% on the MS COCO public dataset. Compared with the YOLACT algorithm, this method improves the mask accuracy by 25.7%, the small target detection accuracy by 37.1%, the medium target detection accuracy by 25.8%, and the large target detection accuracy by 21.9%. Compared with YOLACT, Mask R-CNN, SOLO, and other methods, our algorithm shows significant advantages in segmentation accuracy and edge detail preservation, especially excelling in overlapping object segmentation and small target detection, effectively solving the problem of incorrect segmentation in instance boundary overlap regions that traditional methods face.
-
Key words:
- YOLACT /
- anchor-free instance segmentation /
- dynamic convolution /
- Transformer
-
Overview
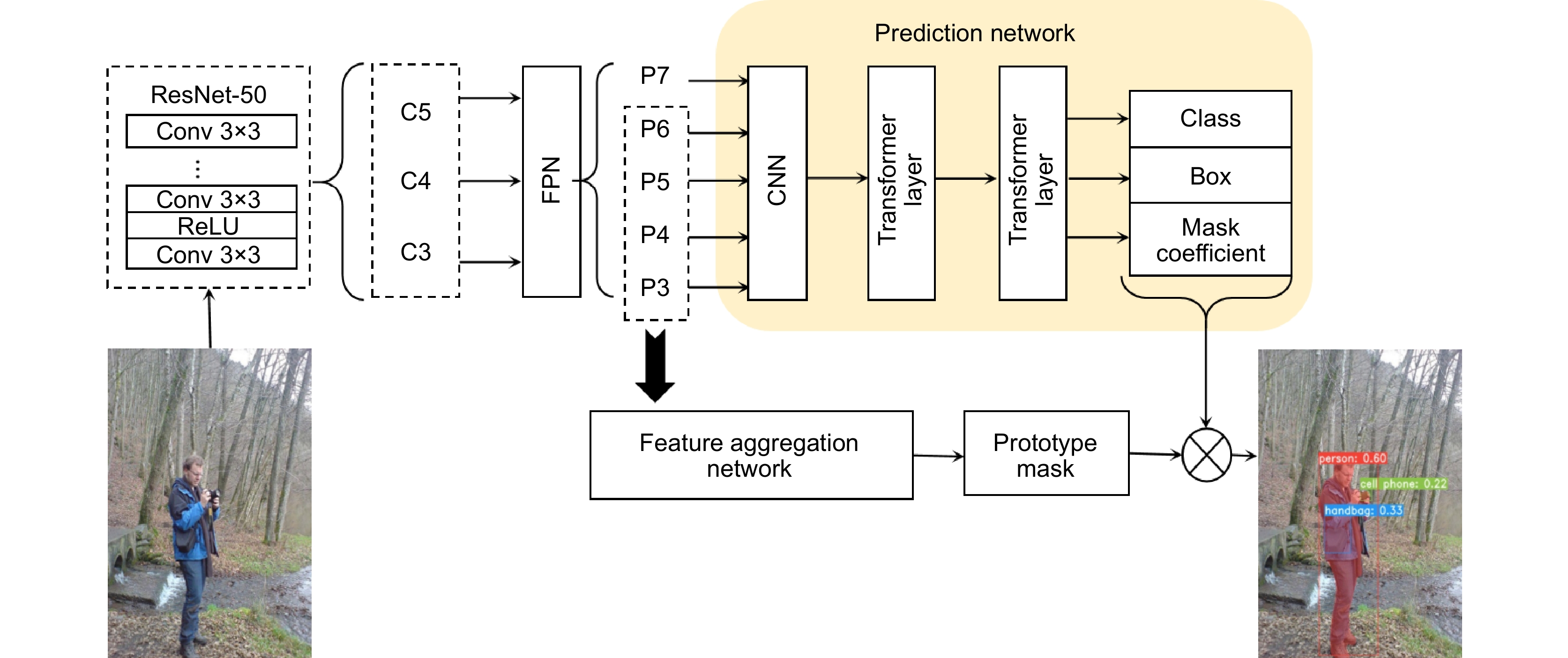
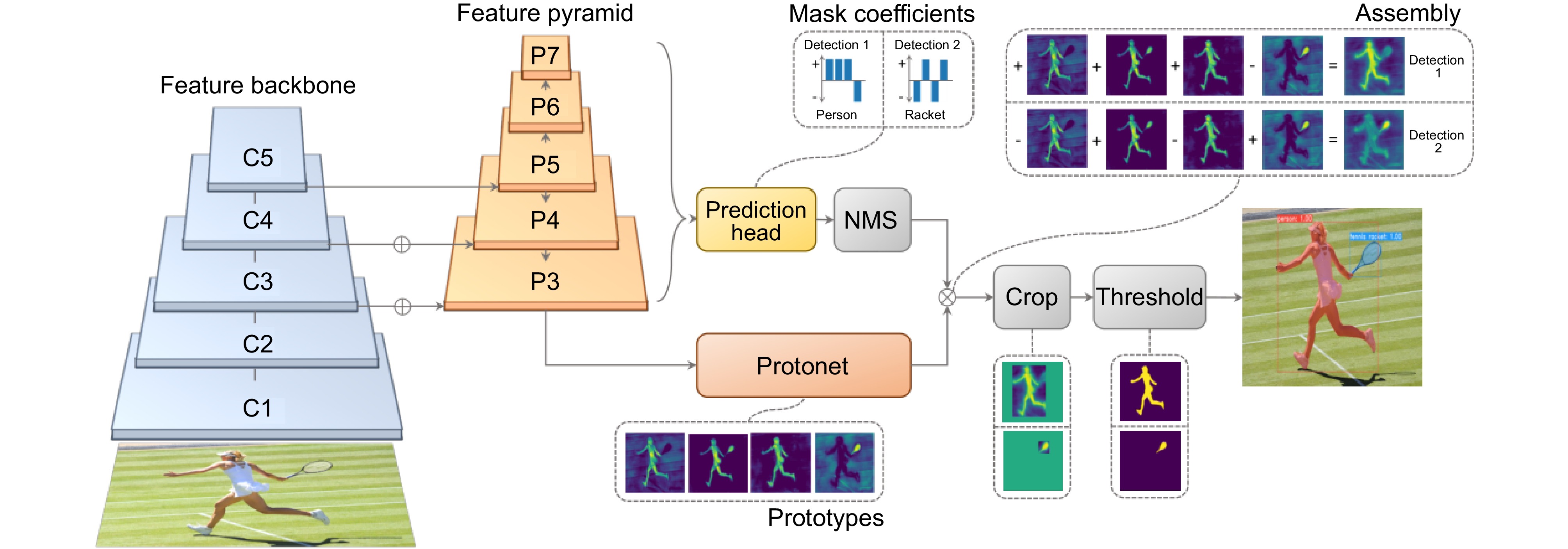
Overview: This paper proposes an anchor-free instance segmentation algorithm based on YOLACTR to address the limitations of the single-stage YOLACT algorithm in instance segmentation tasks. Traditional YOLACT algorithms rely on bounding box detection, suffering from precise localization of regions of interest and facing difficulties in distinguishing overlapping instances, which constrains detection accuracy. This research decouples the mask generation process into parallel tasks of feature learning and convolution kernel learning, abandoning traditional bounding box detection methods and adopting a more natural mask representation approach.
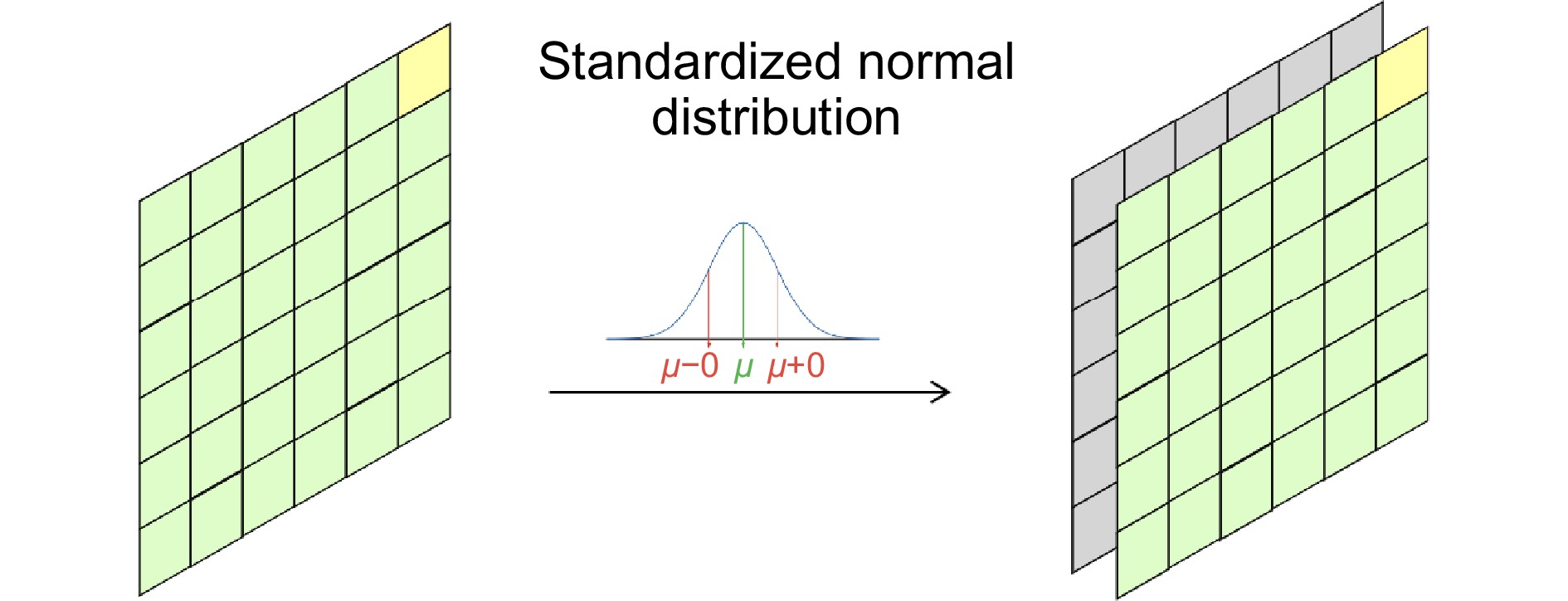
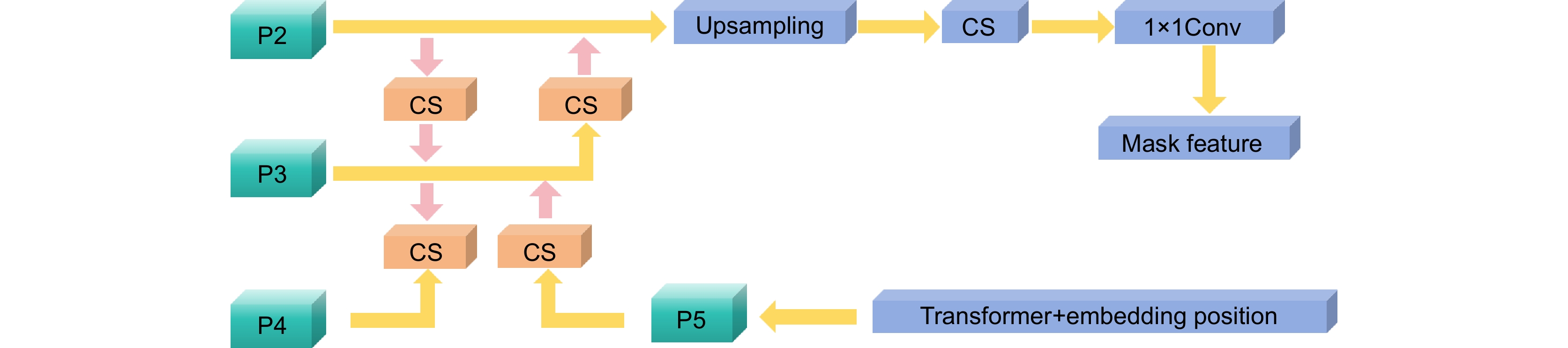
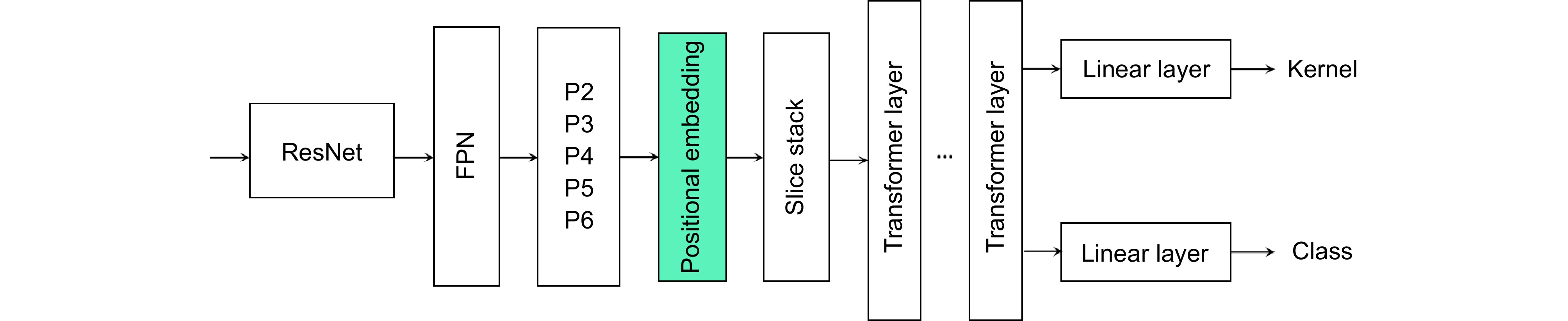
In the algorithmic implementation, random positional embedding techniques are employed to enhance the position sensitivity of feature maps, utilizing a six-layer Transformer structure to process spatial information, simultaneously generating dynamic convolution kernels and category information. The feature aggregation network integrates bottom-layer features from the feature pyramid and high-level features from the prediction network, optimizing feature expression capabilities through channel-spatial (CS) attention modules. For the loss function design, the research implements a combination of focal loss for classification tasks and dice loss for mask generation.
The network architecture consists of four primary components: a multi-scale feature generation network utilizing ResNet and feature pyramid networks; A mask generation network combining transformer with feature aggregation; A prediction network incorporating positional information to generate dynamic convolution kernels; Auxiliary network structures to enhance overall performance. This design allows for more effective handling of spatial relationships and instance boundaries compared to traditional anchor-based approaches.
Experimental results on the MS COCO dataset demonstrate that this method achieves a mask accuracy (AP) of 35.2%, representing a 25.7% improvement over the YOLACT algorithm. Specifically, the detection accuracy for small targets is improved by 37.1%, for medium targets by 25.8%, and for large target by 21.9%. When compared to algorithms such as Mask R-CNN, YOLACTR, and SOLO, this method shows advantages in segmentation accuracy and edge detail preservation. It performs exceptionally well in handling overlapping objects and small target detection, effectively addressing the segmentation issues in instance boundary overlap regions faced by traditional methods.
This paper effectively overcomes the limitations of traditional bounding box methods by decoupling the mask generation process and introducing anchor-free design, achieving balanced performance in instance segmentation tasks across different scales of objects, particularly improving small target detection capability and boundary differentiation of overlapping objects.
-

-
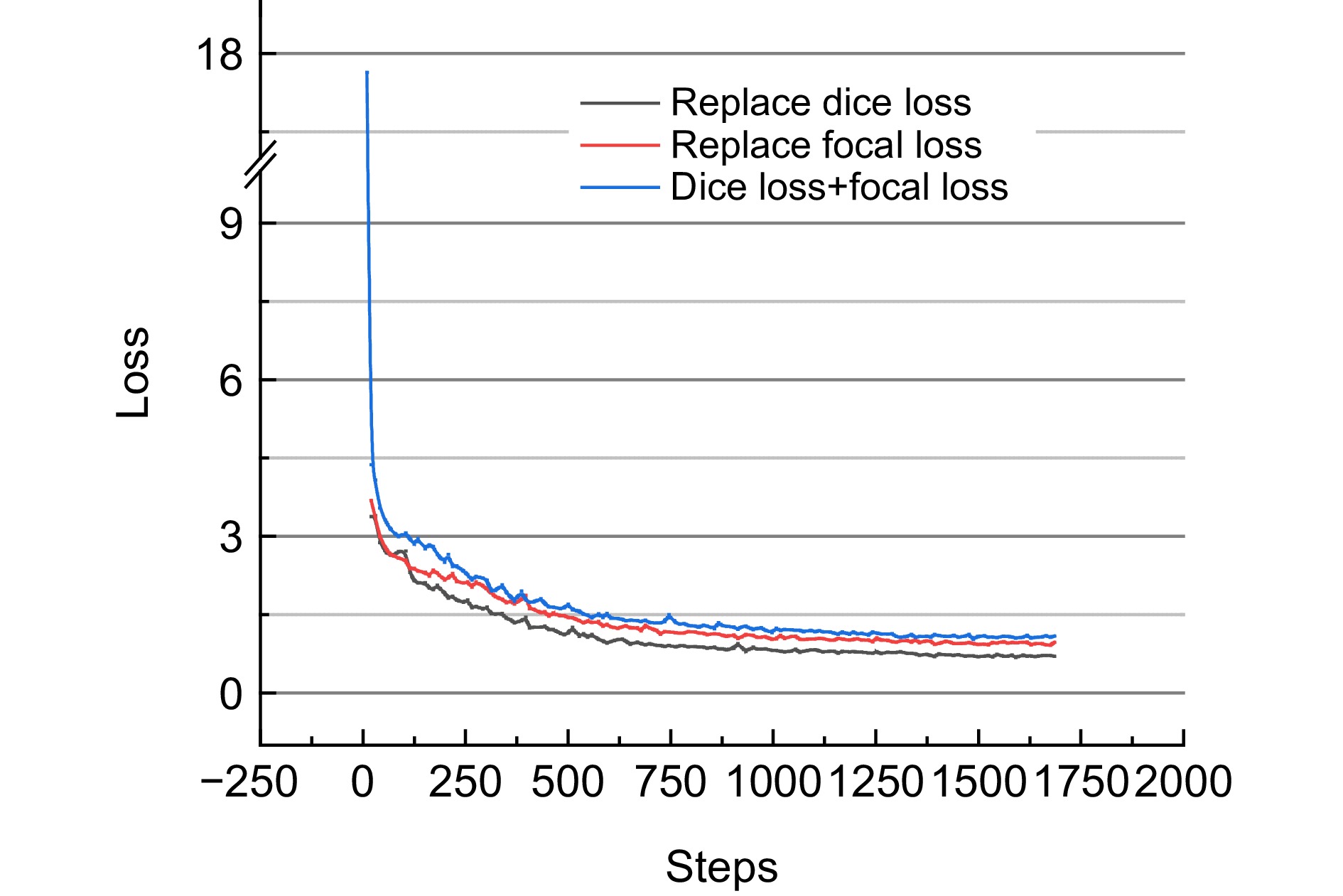
图 9 不同损失函数配置下的损失变化曲线
Figure 9. Loss variation curves under different loss function configurations
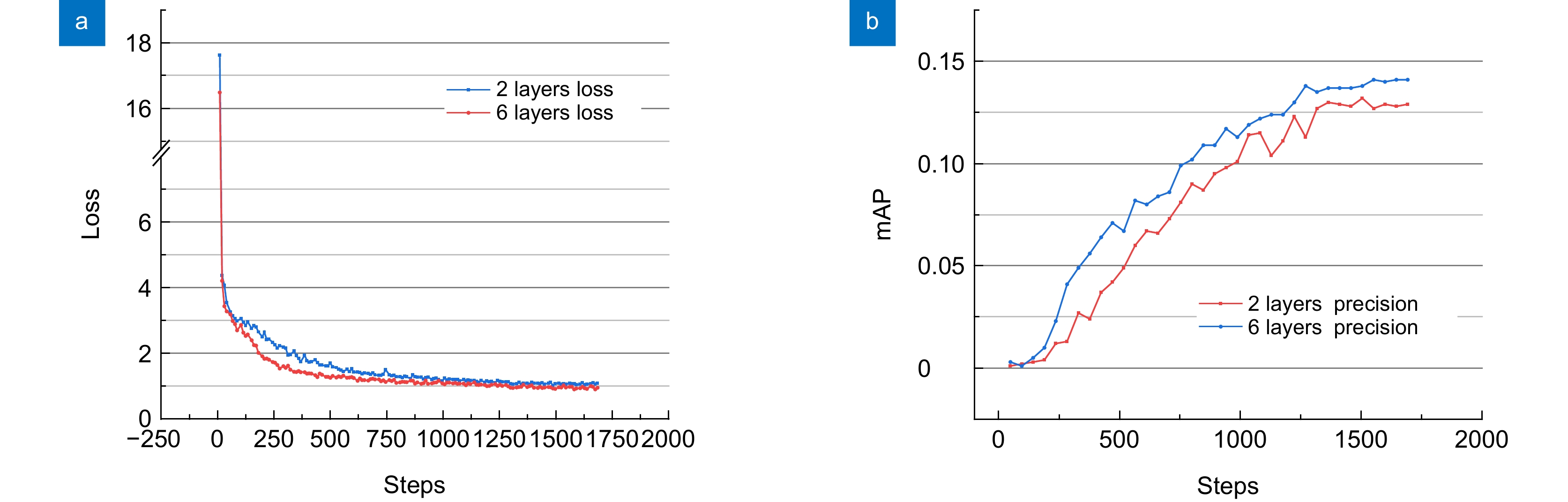
图 10 2层和6层Transformer模型的不同曲线。(a)损失变化曲线;(b)精度变化曲线
Figure 10. Different curves for 2- and 6-layer Transformer models. (a) Loss variation curves; (b)Accuracy variation curves
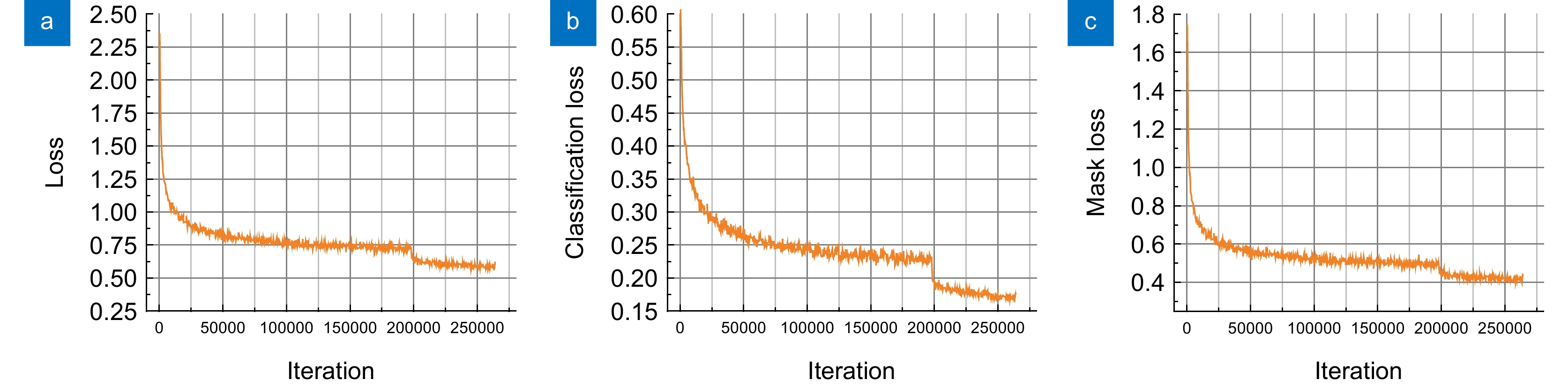
图 11 训练过程中各损失下降示意图。(a)总损失曲线;(b)分类损失曲线;(c)掩码损失曲线
Figure 11. Schematic diagrams of the decline of each loss during the training process. (a) Total loss curve; (b) Classification loss curve; (c) Mask loss curve
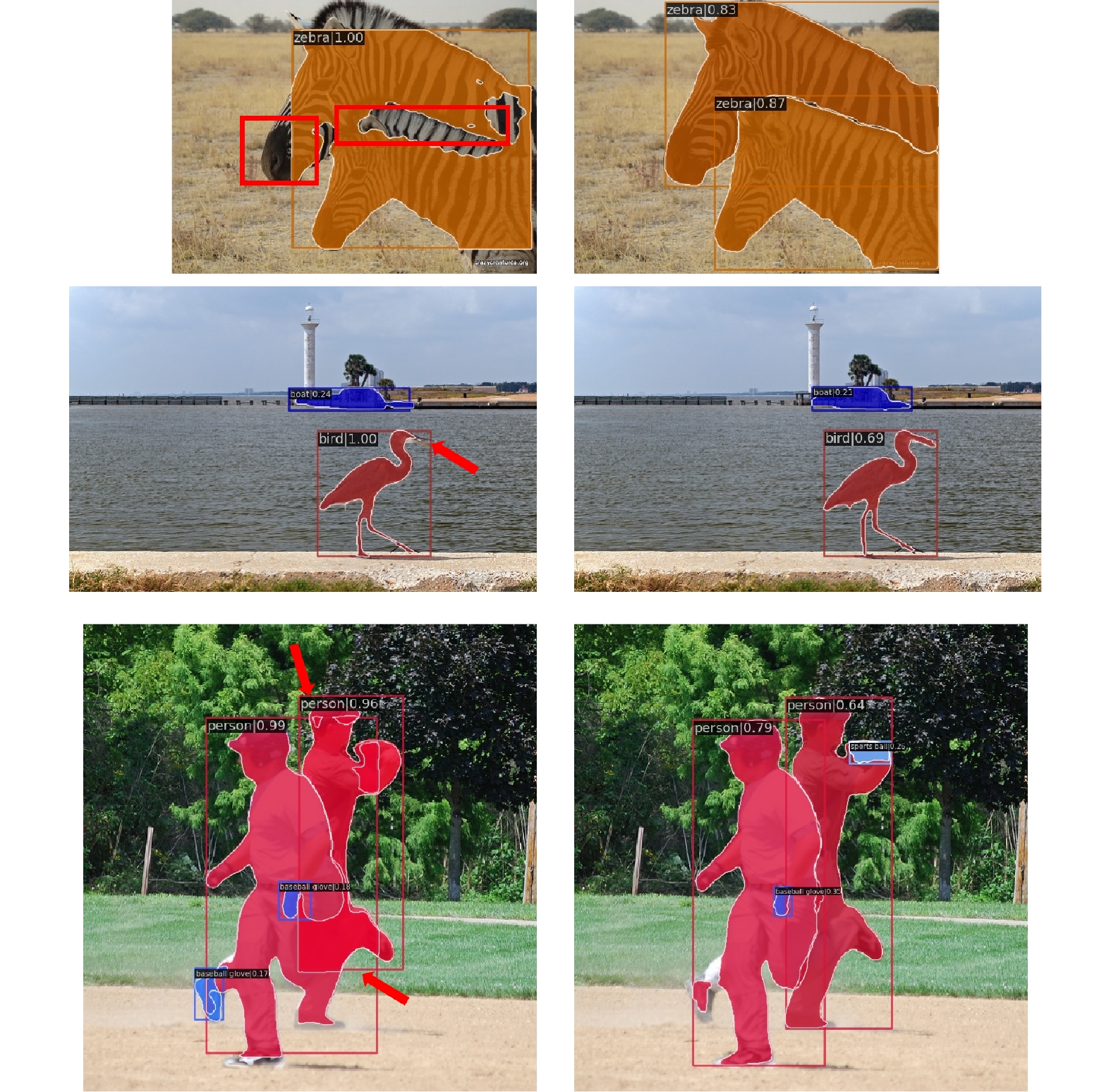
图 13 改进前(左)、后(右)对比图
Figure 13. Comparison diagrams before improvement (left) and after improvement (right)
表 1 实验环境配置
Table 1. Experimental environment configuration
Operating system Framework CPU GPU Memory Video memory Python CUDNN CUDA Ubuntu 20.04.3 LTS Pytorch AMD EPYC 7601 NVIDIA GeForce RTX 3090 × 2 32 GB 48 GB 3.8.10 8.0.5 11.0  下载: 导出CSV
下载: 导出CSV
表 2 不同损失函数配置下的分割结果
Table 2. Segmentation results under different loss function configurations
Loss function configuration AP/% AP50/% AP75/% Replace dice loss 3.0 4.8 3.6 Replace focal loss 11.5 23.8 10.2 Dice loss + focal loss 12.7 26.9 10.9
下载: 导出CSV
表 3 不同Transformer层数的分割结果
Table 3. Segmentation results with different numbers of transformer layers
Transformer layers AP/% AP50/% AP75/% APS/% APM/% APL/% 2 layers 12.7 26.9 10.9 1.0 5.1 28.9 6 layers 14.1 29.3 12.4 2.0 6.6 34.7
下载: 导出CSV
表 4 在COCO数据集上的实例分割结果
Table 4. Instance segmentation results on the COCO dataset
Network model AP/% AP50/% AP75/% APS/% APM/% APL/% YOLACT 28.0 46.2 29.1 8.9 30.2 47.0 Mask R-CNN 30.5 51.1 32.1 14.2 34.1 43.1 YOLACTR 29.1 48.7 30.0 10.2 31.4 46.8 PolarMask[28] 30.4 51.9 31.0 13.4 32.4 42.8 SOLO 33.1 53.5 35.0 12.2 36.1 50.8 QueryInst 37.5 58.7 40.5 18.4 40.2 57.2 Mask2Former 42.9 65.3 46.0 22.1 46.3 64.8 Proposed algorithm 35.2 55.4 37.5 12.2 38.0 57.3
下载: 导出CSV
-
参考文献
[1] 周涛, 赵雅楠, 陆惠玲, 等. 医学图像实例分割:从有候选区域向无候选区域[J]. 生物医学工程学杂志, 2022, 39(6): 1218−1232 doi: 10.7507/1001-5515.202201034
Zhou T, Zhao Y N, Lu H L, et al. Medical image instance segmentation: from candidate region to no candidate region[J]. J Biomed Eng, 2022, 39(6): 1218−1232. doi: 10.7507/1001-5515.202201034
[2] Pei S W, Ni B, Shen T M, et al. RISAT: real-time instance segmentation with adversarial training[J]. Multimed Tools Appl, 2023, 82(3): 4063−4080. doi: 10.1007/s11042-022-13447-1
[3] Hong S L, Jiang Z H, Liu L Z, et al. Improved mask R-CNN combined with Otsu preprocessing for rice panicle detection and segmentation[J]. Appl Sci, 2022, 12(22): 11701. doi: 10.3390/app122211701
[4] 吴马靖, 张永爱, 林珊玲, 等. 基于BiLevelNet的实时语义分割算法[J]. 光电工程, 2024, 51(5): 240030. doi: 10.12086/oee.2024.240030
Wu M J, Zhang Y A, Lin S L, et al. Real-time semantic segmentation algorithm based on BiLevelNet[J]. Opto-Electron Eng, 2024, 51(5): 240030. doi: 10.12086/oee.2024.240030
[5] 苏丽, 孙雨鑫, 苑守正. 基于深度学习的实例分割研究综述[J]. 智能系统学报, 2021, 17(1): 16−31. doi: 10.11992/tis.202109043
Su L, Sun Y X, Yuan S Z. A survey of instance segmentation research based on deep learning[J]. CAAI Trans Intell Syst, 2021, 17(1): 16−31. doi: 10.11992/tis.202109043
[6] 张继凯, 赵君, 张然, 等. 深度学习的图像实例分割方法综述[J]. 小型微型计算机系统, 2021, 42(1): 161−171. doi: 10.3969/j.issn.1000-1220.2021.01.028
Zhang J K, Zhao J, Zhang R, et al. Survey of image instance segmentation methods using deep learning[J]. J Chin Comput Syst, 2021, 42(1): 161−171. doi: 10.3969/j.issn.1000-1220.2021.01.028
[7] Minaee S, Boykov Y, Porikli F, et al. Image segmentation using deep learning: a survey[J]. IEEE Trans Pattern Anal Mach Intell, 2022, 44(7): 3523−3542. doi: 10.1109/TPAMI.2021.3059968
[8] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision, 2017: 2980–2988. https://doi.org/10.1109/ICCV.2017.322.
[9] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 29th International Conference on Neural Information Processing Systems, 2015: 91–99.
[10] Cai Z W, Vasconcelos N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 6154–6162. https://doi.org/10.1109/CVPR.2018.00644.
[11] 肖振久, 田昊, 张杰浩, 等. 融合动态特征增强的遥感建筑物分割[J]. 光电工程, 2020, 52(3): 240231 doi: 10.12086/oee.2025.240231
Xiao Z J, Tian H, Zhang J H, et al. Fusion of dynamic features enhances remote sensing building segmentation[J]. Opto-Electron Eng, 2020, 52(3): 240231 doi: 10.12086/oee.2025.240231
[12] Chen K, Pang J M, Wang J Q, et al. Hybrid task cascade for instance segmentation[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 4969–4978. https://doi.org/10.1109/CVPR.2019.00511.
[13] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779–788. https://doi.org/10.1109/CVPR.2016.91.
[14] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580–587. https://doi.org/10.1109/CVPR.2014.81.
[15] Tian Z, Shen C H, Chen H, et al. FCOS: fully convolutional one-stage object detection[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, 2019: 9626–9635. https://doi.org/10.1109/ICCV.2019.00972.
[16] Zhou X Y, Wang D Q, Krähenbühl P. Objects as points[Z]. arXiv: 1904.07850, 2019. https://arxiv.org/abs/1904.07850.
[17] Wang X L, Kong T, Shen C H, et al. SOLO: segmenting objects by locations[C]//16th European Conference on Computer Vision, 2020: 649–665. https://doi.org/10.1007/978-3-030-58523-5_38.
[18] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90.
[19] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936–944. https://doi.org/10.1109/CVPR.2017.106.
[20] 刘腾, 刘宏哲, 李学伟, 等. 基于无锚框分割网络改进的实例分割方法[J]. 计算机工程, 2022, 48(9): 239−247,253. doi: 10.19678/j.issn.1000-3428.0062846
Liu T, Liu H Z, Li X W, et al. Improved instance segmentation method based on anchor-free segmentation network[J]. Comput Eng, 2022, 48(9): 239−247,253. doi: 10.19678/j.issn.1000-3428.0062846
[21] Kirillov A, Wu Y X, He K M, et al. PointRend: image segmentation as rendering[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 9796–9805. https://doi.org/10.1109/CVPR42600.2020.00982.
[22] Yang S S, Wang X G, Li Y, et al. Temporally efficient vision transformer for video instance segmentation[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 2875–2885. https://doi.org/10.1109/CVPR52688.2022.00290.
[23] Cheng B W, Misra I, Schwing A G, et al. Masked-attention mask transformer for universal image segmentation[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 1280–1289. https://doi.org/10.1109/CVPR52688.2022.00135.
[24] Bolya D, Zhou C, Xiao F Y, et al. YOLACT: real-time instance segmentation[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, 2019: 9156–9165. https://doi.org/10.1109/ICCV.2019.00925.
[25] 赵敬伟, 林珊玲, 梅婷, 等. 基于YOLACT与Transformer相结合的实例分割算法研究[J]. 半导体光电, 2023, 44(1): 134−140. doi: 10.16818/j.issn1001-5868.2022110201
Zhao J W, Lin S L, Mei T, et al. Research on instance segmentation algorithm based on YOLACT and Transformer[J]. Semicond Optoelectron, 2023, 44(1): 134−140. doi: 10.16818/j.issn1001-5868.2022110201
[26] Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 3213–3223. https://doi.org/10.1109/CVPR.2016.350.
[27] Cordts M, Omran M, Ramos S, et al. The cityscapes dataset[C]//CVPR Workshop on the Future of Datasets in Vision, 2015: 1. https://doi.org/10.48550/arXiv.1604.01685
[28] Xie E Z, Sun P Z, Song X G, et al. PolarMask: single shot instance segmentation with polar representation[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 12190–12199. https://doi.org/10.1109/CVPR42600.2020.01221.
-
访问统计




 点击扫一扫
点击扫一扫
图(16)
表(4)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


