
 E-mail Alert
E-mail Alert RSS
RSS
Lightweight Swin Transformer combined with multi-scale feature fusion for face expression recognition
-
摘要:
针对Swin Transformer模型应用在表情识别上参数量过大、实时性较差和对表情中存在的复杂且微小的表情变化特征捕捉能力有限的问题,提出了一个轻量型Swin Transformer和多尺度特征融合 (EMA)模块相结合的人脸表情识别方法。该方法首先利用提出的SPST模块替换掉原Swin Transformer模型第四个stage中的Swin Transformer block模块,来降低模型的参数量,实现模型的轻量化。然后在轻量型模型的第二个stage后嵌入了多尺度特征融合 (EMA)模块,通过多尺度特征提取和跨空间信息聚合,有效地增强了模型对人脸表情细节的捕捉能力,从而提高人脸表情识别的准确性和鲁棒性。实验结果表明,所提方法在JAFFE、FERPLUS、RAF-DB和FANE这4个公共数据集上分别达到了97.56%、86.46%、87.29%和70.11%的识别准确率,且相比于原Swin Transformer模型,改进后的模型参数量下降了15.8%,FPS提升了9.6%,在保持模型较低参数量的同时,显著增强了模型的实时性。
-
关键词:
- 表情识别 /
- Swin Transformer /
- SPST模块 /
- EMA模块
Abstract:A lightweight Swin Transformer and multi-scale feature fusion (EMA) module combination is proposed for face expression recognition, which addresses the problems of the Swin Transformer model, such as excessive parameter quantity, poor real-time performance, and limited ability to capture the complex and small expression change features present in the expressions. The method first uses the proposed SPST module to replace the Swin Transformer block module in the fourth stage of the original Swin Transformer model to reduce the number of parameters of the model and realize the lightweight model. Then, the multi-scale feature fusion (EMA) module is embedded after the second stage of the lightweight model, which effectively improves the model's ability to capture the details of facial expressions through multi-scale feature extraction and cross-space information aggregation, thus improving the accuracy and robustness of facial expression recognition. The experimental results show that the proposed method achieves 97.56%, 86.46%, 87.29%, and 70.11% recognition accuracy on four public datasets, namely, JAFFE, FERPLUS, RAF-DB, and FANE, respectively. Compared with the original Swin Transformer model, the number of parameters of the improved model is decreased by 15.8% and the FPS is improved by 9.6%, which significantly enhances the real-time performance of the model while keeping the number of parameters of the model low.
-
Overview: Currently, most facial recognition algorithms rely on convolutional neural networks (CNNs). However, CNNs heavily depend on spatial locality, limiting their ability to capture global features of facial expressions early on. Stacking convolutional layers to expand the receptive field often leads to information loss, increasing computational load and gradient vanishing. To address these issues, researchers are increasingly exploring Transformer models for image tasks.
Transformers, with their powerful self-attention mechanism for capturing local features, show promise in expression recognition but face practical limitations. Traditional Transformers operate within fixed-size windows, restricting their ability to model long-range dependencies. Since facial expressions often involve coordinated changes across regions, relying solely on local windows can hinder global feature perception, impacting recognition performance. Moreover, stacking layers to capture global information results in higher parameters and greater computational demands.
In 2021, Microsoft Research Asia introduced the Swin Transformer, utilizing sliding window-based and window-based multi-head self-attention mechanisms (SW-MSA and W-MSA) to integrate cross-window information. This approach addresses the limitations of traditional Transformers by effectively balancing global feature learning and computational efficiency, making it a promising model for facial recognition tasks.
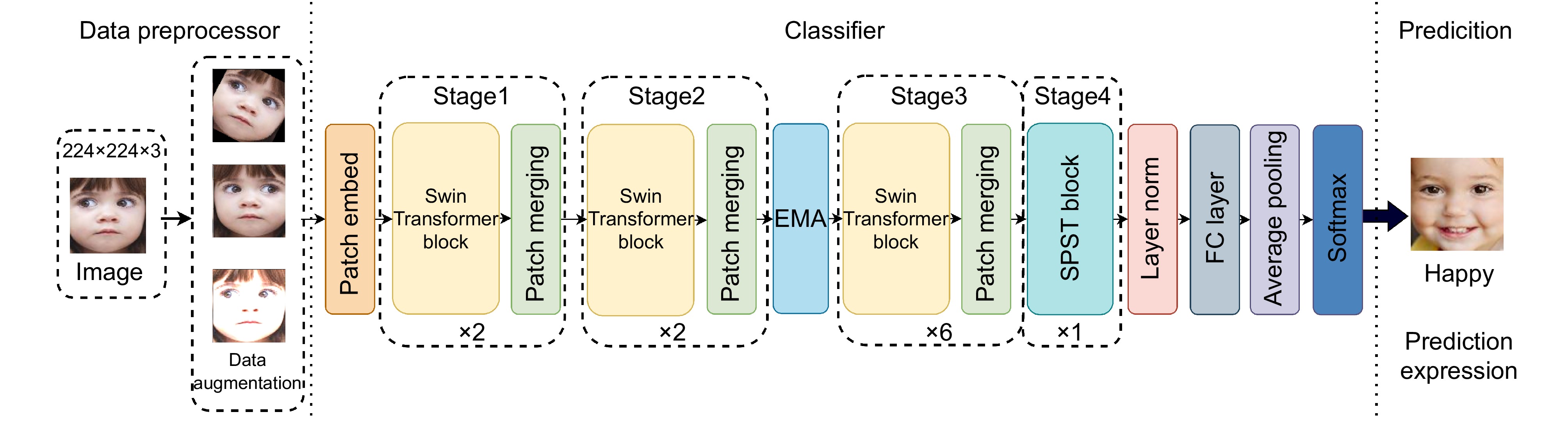
To summarize, a lightweight Swin Transformer and multi-scale feature fusion (EMA) module combination is proposed for face expression recognition, which addresses the problems of the Swin Transformer model, such as excessive parameter quantity, poor real-time performance, and limited ability to capture the complex and small expression change features present in the expressions. The method first uses the proposed SPST module to replace the Swin Transformer block module in the fourth stage of the original Swin Transformer model to reduce the number of parameters of the model and realize the lightweight model. Then, the multi-scale feature fusion (EMA) module is embedded behind the second stage of the lightweight model, which effectively improves the model's ability to capture the details of facial expressions through multi-scale feature extraction and cross-space information aggregation, thus improving the accuracy and robustness of facial expression recognition. The experimental results show that the proposed method achieves 97.56%, 86.46%, 87.29%, and 70.11% recognition accuracy on four public datasets, namely, JAFFE, FERPLUS, RAF-DB, and FANE, respectively. Compared with the original Swin Transformer model, the number of parameters of the improved model is decreased by 15.8% and the FPS is improved by 9.6%, which significantly enhances the real-time performance of the model while keeping the number of parameters of the model low.
-

-
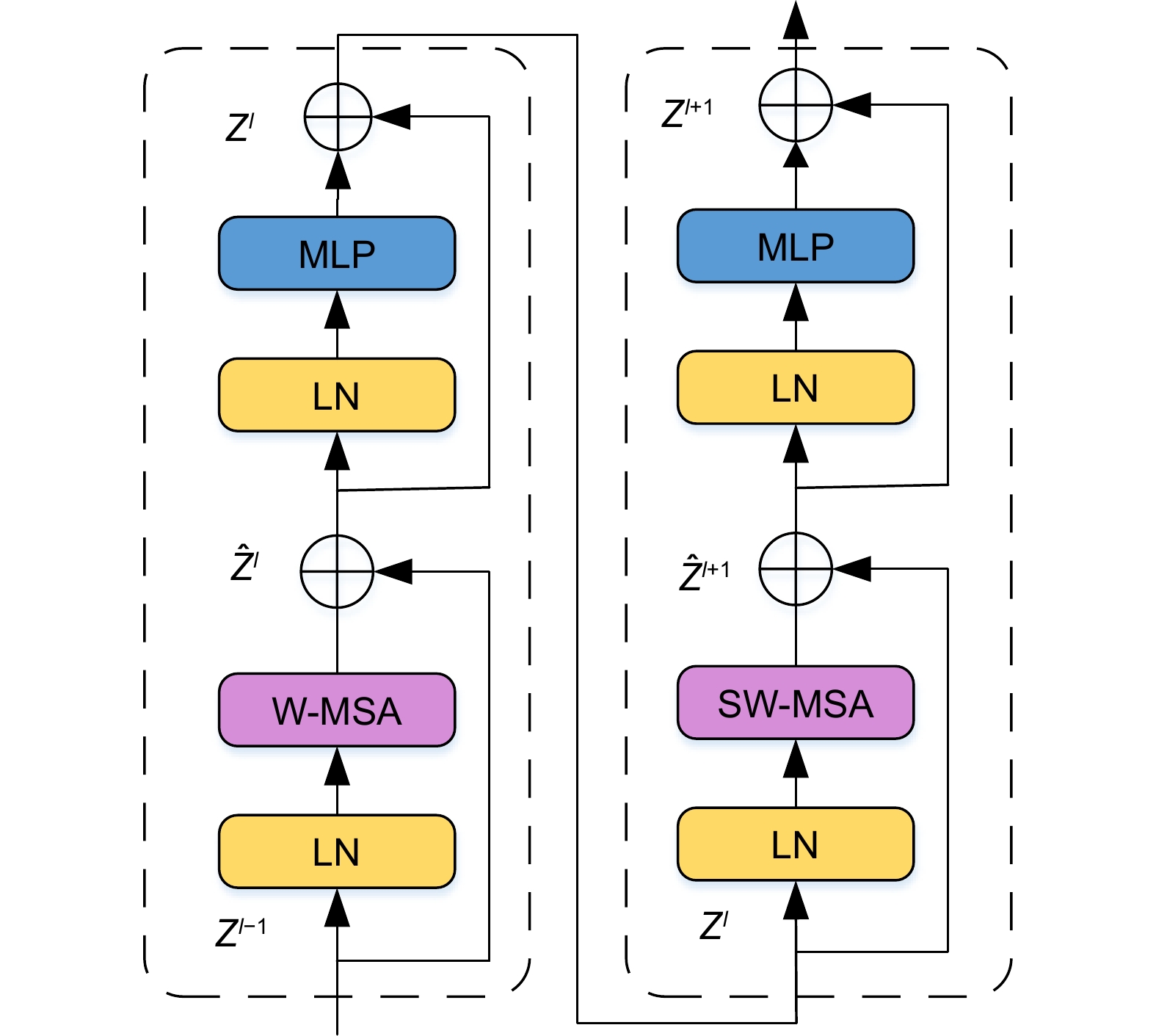
图 2 Swin Transformer block 模块框架图
Figure 2. Swin Transformer block module structure diagram
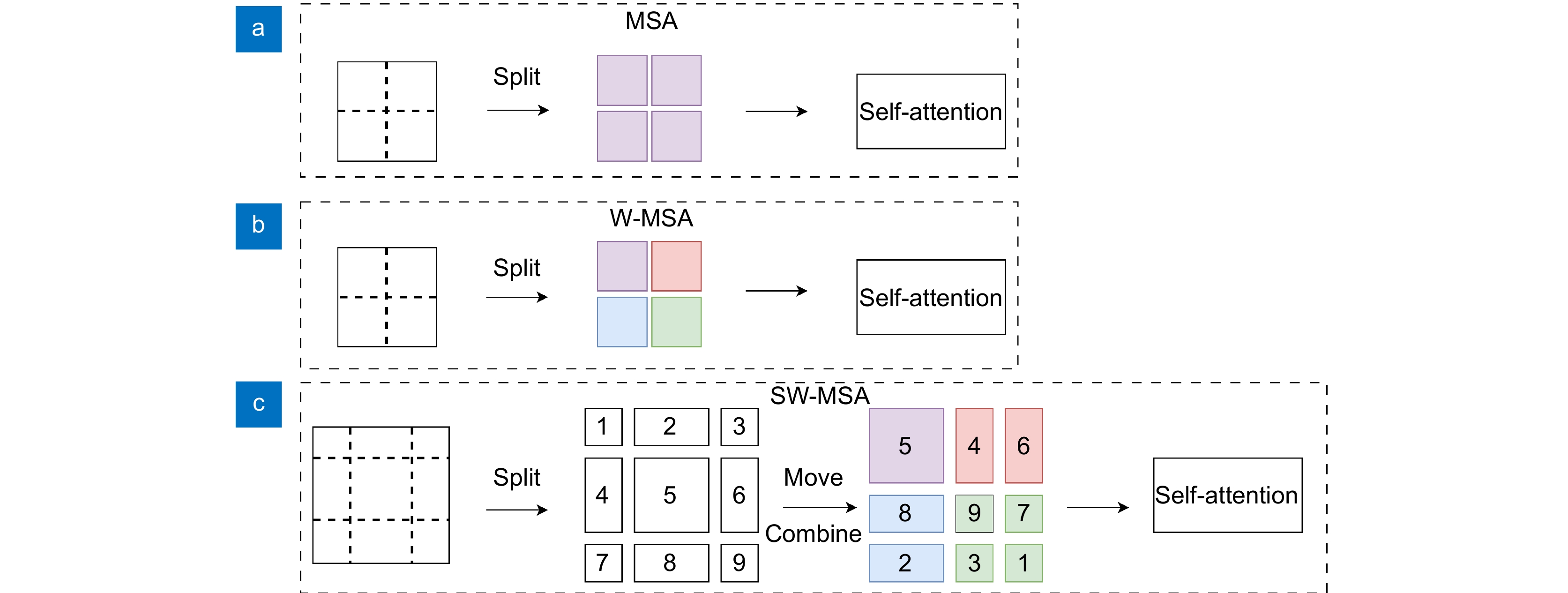
图 3 自注意力计算区域。(a) MSA; (b) W-MSA; (c) SW-MSA
Figure 3. Self-attention computing area. (a) MSA; (b) W-MSA; (c) SW-MSA
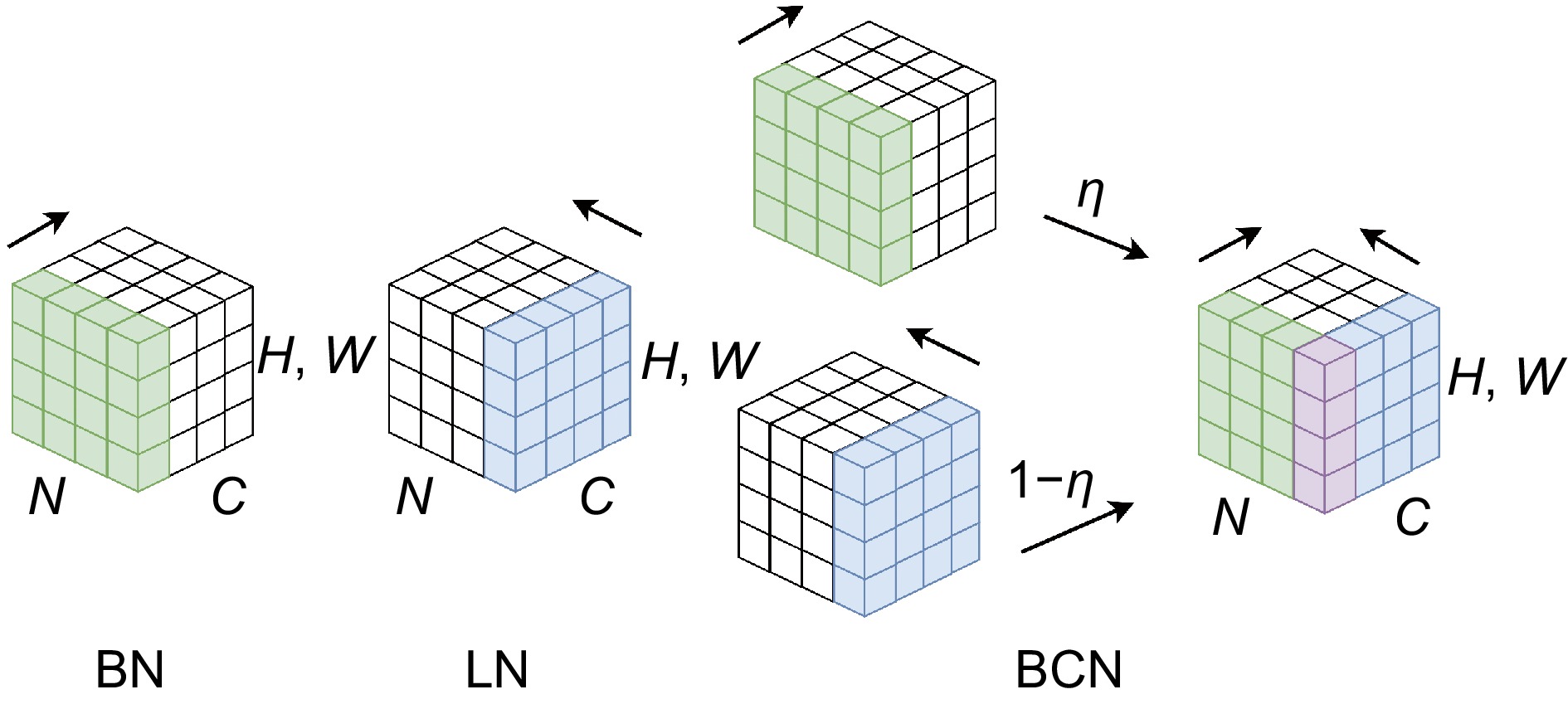
图 6 BN、LN、BCN标准化技术可视图
Figure 6. A visual view of the BN, LN, and BCN standardization technology

图 8 加入EMA模块前后模型的热力图
Figure 8. Activation maps of the model before and after adding EMA module
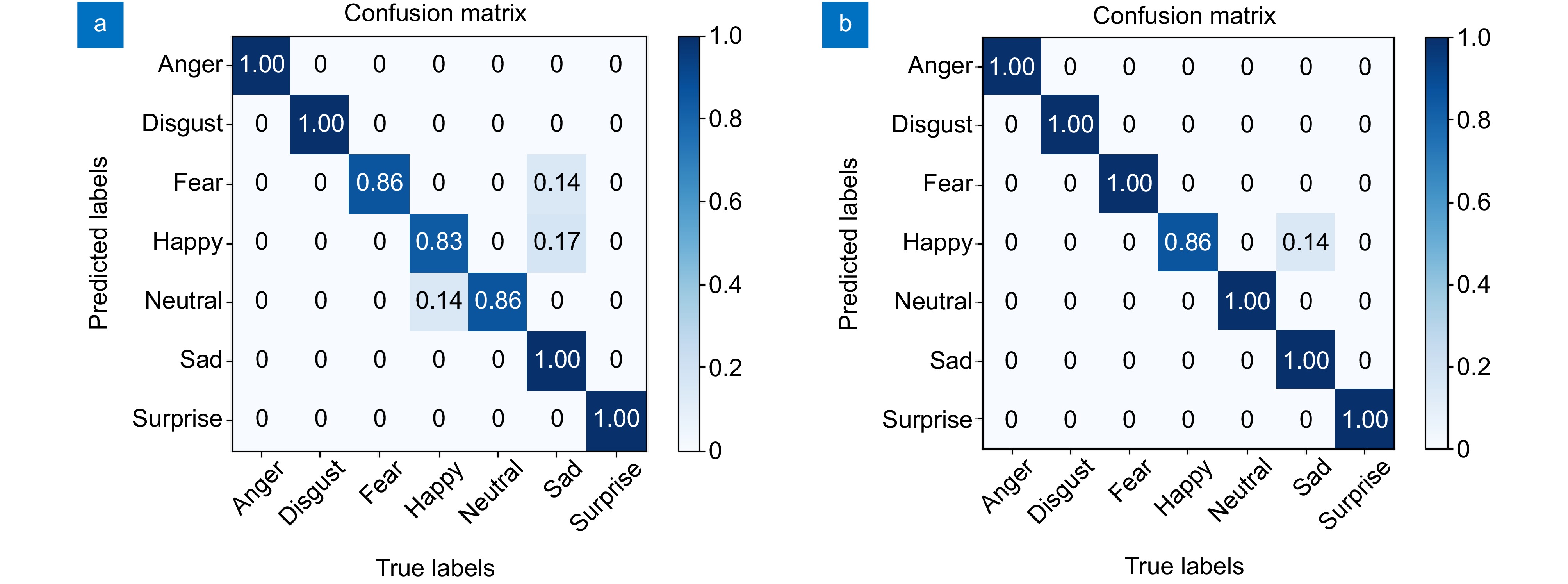
图 10 JAFFE数据集上的混淆矩阵验证结果。(a)原始Swin Transformer模型; (b)改进Swin Transformer模型
Figure 10. Confusion matrix validation results on JAFFE. (a) Original Swin Transformer model; (b) Improved Swin Transformer model
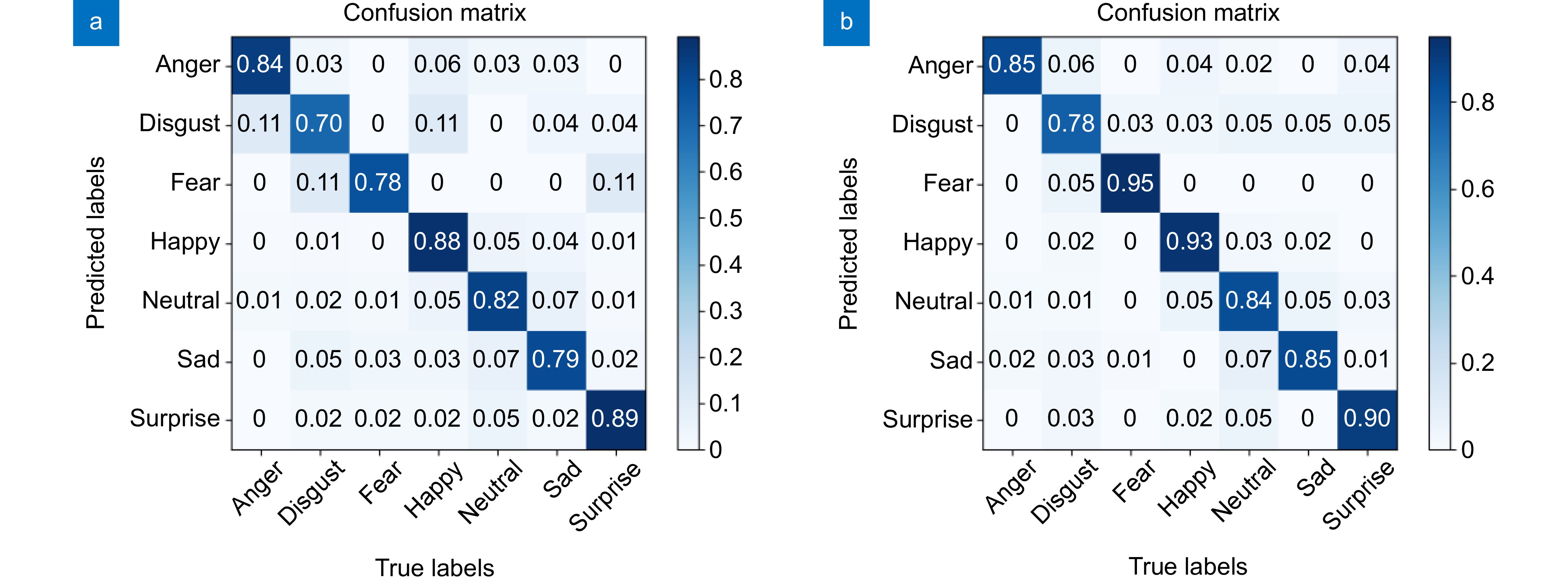
图 11 RAF-DB数据集上的混淆矩阵验证结果。(a)原始Swin Transformer模型; (b)改进Swin Transformer模型
Figure 11. Confusion matrix validation results on RAF-DB. (a) Original Swin Transformer model; (b) Improved Swin Transformer model
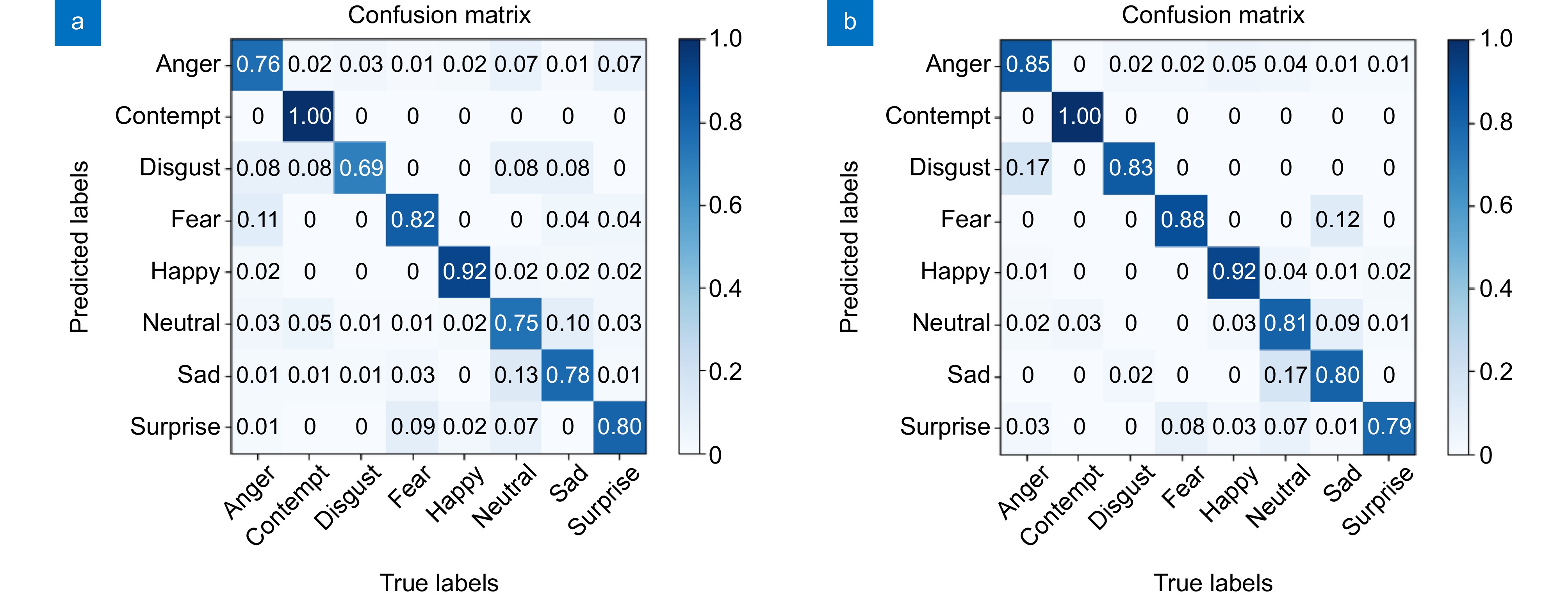
图 12 FERPLUS数据集上的混淆矩阵验证结果。(a)原始Swin Transformer模型; (b)改进Swin Transformer模型
Figure 12. Confusion matrix validation results on FERPLUS. (a) Original Swin Transformer model; (b) Improved Swin Transformer model
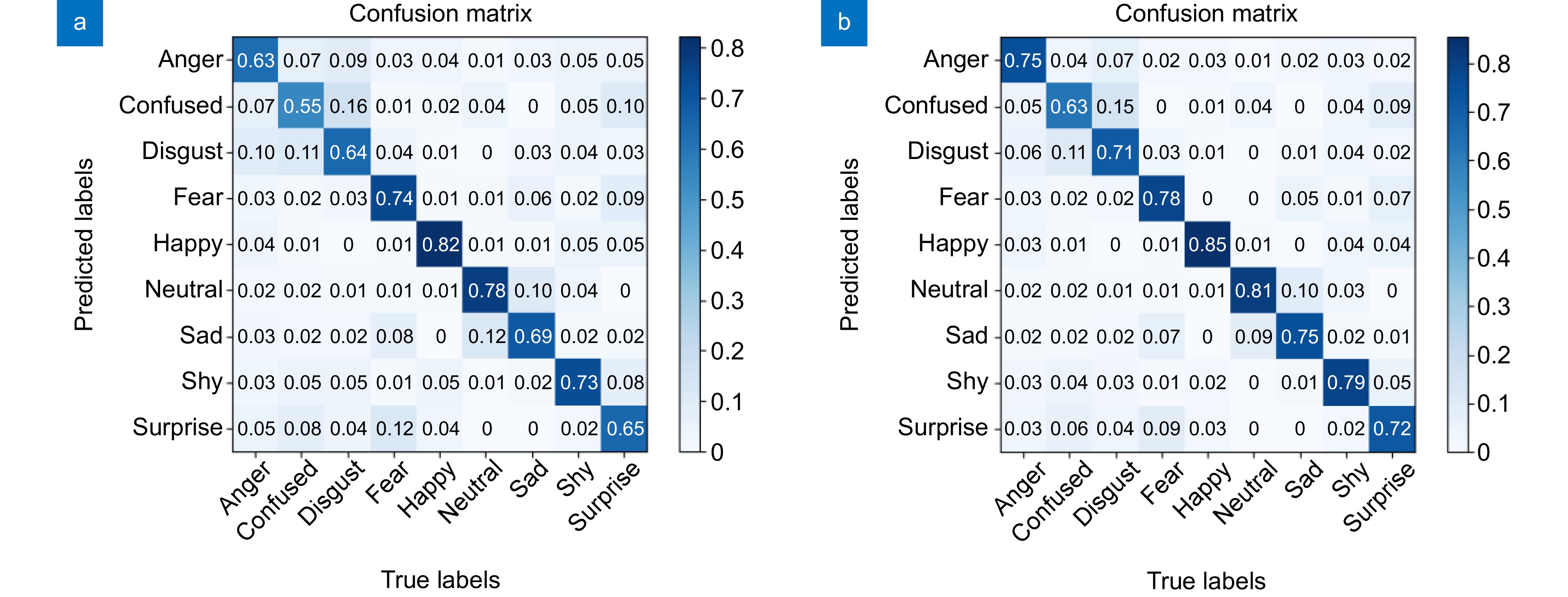
图 13 FANE数据集上的混淆矩阵验证结果。(a)原始Swin Transformer模型; (b)改进Swin Transformer模型
Figure 13. Confusion matrix validation results on FANE. (a) Original Swin Transformer model; (b) Improved Swin Transformer model
表 1 模型改进前后参数量对比
Table 1. Comparison of parameters before and after the model is improved
Model EMA module SPST module Parameters Original Swin Transformer × × 27,524,737 Improved Swin Transformer √ × 27,526,225 Improved Swin Transformer × √ 23,185,251 Improved Swin Transformer √ √ 23,186,739  下载: 导出CSV
下载: 导出CSV
表 2 在不同stage中替换SPST模块实验对比
Table 2. Experimental comparison of replacing SPST modules in different stages
Position Swin Transformer block SPST block Parameters RACC/% GFLOPs FPS Stage1 √ 34,331,981 72.33 19.06 86 Stage2 √ 29,625,428 75.27 12.44 152 Stage3 √ 24,190,413 82.17 5.84 281 Stage4 √ 23,185,251 86.86 4.12 335 Stage4 √ 27,524,737 85.69 4.51 301
下载: 导出CSV
表 3 热力图的熵值对比
Table 3. Entropy comparison of activation maps
Model Anger Disgust Fear Happy Sad Surprise Original Swin Transformer 10.5974 10.5325 10.4282 10.6150 10.5980 10.6626 Improved Swin Transformer 8.2437 9.4190 9.2204 8.1102 8.9906 8.9113
下载: 导出CSV
表 4 实验环境具体配置
Table 4. Configuration of the experimental environment
Configuration name Environmental parameter CPU Inter (R) Core (TM) i5-12400F 2.50 GHz GPU NVIDIA GeForce RTX 3060 (12 GB) Memory 16 G Python 3.9.19 CUDA 11.8 Torch 2.0.0
下载: 导出CSV
表 5 在不同stage后嵌入EMA模块的准确率
Table 5. Accuracy of embedding the EMA module behind different stages
Position RACC/% Parameters JAFFE FERPLUS RAF-DB FANE After stage1 95.57 85.53 86.80 68.84 23,185,635 After stage2 97.56 86.46 87.29 70.11 23,186,739 After stage3 96.80 85.56 86.99 68.60 23,191,107 After stage4 95.87 85.76 86.67 69.37 23,187,875
下载: 导出CSV
表 6 在FERPLUS、RAF-DB和FANE上的消融实验结果
Table 6. Results of ablation experiments on FERPLUS, RAF-DB, and FANE
SPST module EMA module RACC/% Parameters GFLOPs/G FPS FERPLUS RAF-DB FANE × × 85.43 85.69 68.47 27,524,737 4.51 301 × √ 85.73 86.99 69.67 27,526,225 4.52 297 √ × 85.87 86.86 69.72 23,185,251 4.12 335 √ √ 86.46 87.29 70.11 23,186,739 4.13 330
下载: 导出CSV
表 7 不同网络模型在JAFFE,FERPLUS和RAF-DB上的准确率对比
Table 7. Accuracy comparsion of different networks on JAFFE,FERPLUS, and RAF-DB
Model ACC/% JAFFE FERPLUS RAF-DB ARBEx[9] 96.67 —— —— LBP+HOG[7] 96.05 —— —— SCN[4] 86.33 85.97 87.03 RAN[8] 88.67 83.63 86.90 EfficientNetB0[25] —— 85.01 84.21 MobileNetV2[26] —— 84.03 83.54 MobileNetV3[27] —— 84.97 84.88 Ad-Corre[28] —— —— 86.96 POSTER[19] —— —— 86.03 R3HO-Net[29] —— —— 85.52 Ada-CM[30] —— —— 84.13 Swin Transformer (base) 95.12 85.43 85.69 Ours 97.56 86.46 87.29
下载: 导出CSV
-
[1] 田晨智, 宋敏, 田继伟, 等. 基于组合赋权和FCE的指控系统人机交互效能评估方法[J]. 电光与控制, 2024, 31 (7): 87−96. doi: 10.3969/j.issn.1671-637X.2024.07.014
Tian C Z, Song M, Tian J W, et al. Combination weighting and FCE based evaluation for human-computer interaction effectiveness of command and control system[J]. Electron Opt Control, 2024, 31 (7): 87−96. doi: 10.3969/j.issn.1671-637X.2024.07.014
[2] 李宇豪, 吕晓琪, 谷宇, 等. 基于改进S3FD网络的人脸检测算法[J]. 激光技术, 2021, 45 (6): 722−728. doi: 10.7510/jgjs.issn.1001-3806.2021.06.008
Li Y H, Lü X Q, Gu Y, et al. Face detection algorithm based on improved S3FD network[J]. Laser Technol, 2021, 45 (6): 722−728. doi: 10.7510/jgjs.issn.1001-3806.2021.06.008
[3] 孙锐, 单晓全, 孙琦景, 等. 双重对比学习框架下近红外-可见光人脸图像转换方法[J]. 光电工程, 2022, 49 (4): 210317. doi: 10.12086/oee.2022.210317
Sun R, Shan X Q, Sun Q J, et al. NIR-VIS face image translation method with dual contrastive learning framework[J]. Opto-Electron Eng, 2022, 49 (4): 210317. doi: 10.12086/oee.2022.210317
[4] Wang K, Peng X J, Yang J F, et al. Suppressing uncertainties for large-scale facial expression recognition[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 6896–6905.
[5] 张文雪, 罗一涵, 刘雅卿, 等. 基于主动位移成像的图像超分辨率重建[J]. 光电工程, 2024, 51 (1): 230290. doi: 10.12086/oee.2024.230290
Zhang W X, Luo Y H, Liu Y Q, et al. Image super-resolution reconstruction based on active displacement imaging[J]. Opto-Electron Eng, 2024, 51 (1): 230290. doi: 10.12086/oee.2024.230290
[6] 刘成, 曹良才, 靳业, 等. 基于Transformer的跨年龄人脸识别方法[J]. 激光与光电子学进展, 2023, 60 (10): 1010019. doi: 10.3788/LOP220785
Liu C, Cao L C, Jin Y, et al. Transformer for age-invariant face recognition[J]. Laser Optoelectron Prog, 2023, 60 (10): 1010019. doi: 10.3788/LOP220785
[7] Yaddaden Y, Adda M, Bouzouane A. Facial expression recognition using locally linear embedding with LBP and HOG descriptors[C]//2020 2nd International Workshop on Human-Centric Smart Environments for Health and Well-Being, 2021: 221–226. https://doi.org/10.1109/IHSH51661.2021.9378702.
[8] Wang K, Peng X J, Yang J F, et al. Region attention networks for pose and occlusion robust facial expression recognition[J]. IEEE Trans Image Process, 2020, 29: 4057−4069. doi: 10.1109/TIP.2019.2956143
[9] Wasi A T, Šerbetar K, Islam R, et al. ARBEx: attentive feature extraction with reliability balancing for robust facial expression learning[Z]. arXiv: 2305.01486, 2024. https://doi.org/10.48550/arXiv.2305.01486.
[10] 刘雅芝, 许喆铭, 郎丛妍, 等. 基于关系感知和标签消歧的细粒度面部表情识别算法[J]. 电子学报, 2024, 52 (10): 3336−3346. doi: 10.12263/DZXB.20240364
Liu Y Z, Xu Z M, Lang C Y, et al. Fine-grained facial expression recognition algorithm based on relationship-awareness and label disambiguation[J]. Acta Electron Sin, 2024, 52 (10): 3336−3346. doi: 10.12263/DZXB.20240364
[11] 陈妍, 吴乐晨, 王聪. 基于多层级信息融合网络的微表情识别方法[J]. 自动化学报, 2024, 50 (7): 1445−1457. doi: 10.16383/j.aas.c230641
Chen Y, Wu L C, Wang C. A micro-expression recognition method based on multi-level information fusion network[J]. Acta Autom Sin, 2024, 50 (7): 1445−1457. doi: 10.16383/j.aas.c230641
[12] 张晨晨, 王帅, 王文一, 等. 针对人脸识别卷积神经网络的局部背景区域对抗攻击[J]. 光电工程, 2023, 50 (1): 220266. doi: 10.12086/oee.2023.220266
Zhang C C, Wang S, Wang W Y, et al. Adversarial background attacks in a limited area for CNN based face recognition[J]. Opto-Electron Eng, 2023, 50 (1): 220266. doi: 10.12086/oee.2023.220266
[13] 魏鑫光. 基于卷积神经网络的面部表情识别方法研究[D]. 济南: 山东大学, 2023. https://doi.org/10.27272/d.cnki.gshdu.2023.006762.
Wei X G. Research on facial expression recognition method based on convolutional neural network[D]. Ji’nan: Shandong University, 2023. https://doi.org/10.27272/d.cnki.gshdu.2023.006762.
[14] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//31st International Conference on Neural Information Processing Systems, 2017: 6000–6010.
[15] Chen M, Radford A, Child R, et al. Generative pretraining from pixels[C]//37th International Conference on Machine Learning, 2020: 1691–1703.
[16] Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]//2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019: 4171–4186. https://doi.org/10.18653/v1/N19-1423.
[17] Liu C, Hirota K, Dai Y P. Patch attention convolutional vision transformer for facial expression recognition with occlusion[J]. Inf Sci, 2023, 619: 781−794. doi: 10.1016/j.ins.2022.11.068
[18] Chen X C, Zheng X W, Sun K, et al. Self-supervised vision transformer-based few-shot learning for facial expression recognition[J]. Inf Sci, 2023, 634: 206−226. doi: 10.1016/j.ins.2023.03.105
[19] Zheng C, Mendieta M, Chen C. POSTER: a pyramid cross-fusion transformer network for facial expression recognition[C]//2023 IEEE/CVF International Conference on Computer Vision Workshops, 2023: 3138–3147. https://doi.org/10.1109/ICCVW60793.2023.00339.
[20] Liu Z, Lin Y T, Cao Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows[C]//2021 IEEE/CVF International Conference on Computer Vision, 2021: 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986.
[21] Feng H Q, Huang W K, Zhang D H, et al. Fine-tuning Swin Transformer and multiple weights optimality-seeking for facial expression recognition[J]. IEEE Access, 2023, 11: 9995−10003. doi: 10.1109/ACCESS.2023.3237817
[22] Pinasthika K, Laksono B S P, Irsal R B P, et al. SparseSwin: Swin Transformer with sparse transformer block[J]. Neurocomputing, 2024, 580: 127433. doi: 10.1016/j.neucom.2024.127433
[23] Ouyang D L, He S, Zhang G Z, et al. Efficient multi-scale attention module with cross-spatial learning[C]//2023 IEEE International Conference on Acoustics, Speech and Signal Processing, 2023: 1–5. https://doi.org/10.1109/ICASSP49357.2023.10096516.
[24] Khaled A, Li C, Ning J, et al. BCN: batch channel normalization for image classification[Z]. arXiv: 2312.00596, 2023. https://doi.org/10.48550/arXiv.2312.00596.
[25] Bodavarapu P N R, Srinivas P V V S. Facial expression recognition for low resolution images using convolutional neural networks and denoising techniques[J]. Indian J Sci Technol, 2021, 14 (12): 971−983. doi: 10.17485/IJST/v14i12.14
[26] Sandler M, Howard A, Zhu M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 4510–4520. https://doi.org/10.1109/CVPR.2018.00474.
[27] Howard A, Sandler M, Chen B, et al. Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision, 2019: 1314–1324. https://doi.org/10.1109/ICCV.2019.00140.
[28] Fard A P, Mahoor M H. Ad-corre: adaptive correlation-based loss for facial expression recognition in the wild[J]. IEEE Access, 2022, 10: 26756−26768. doi: 10.1109/ACCESS.2022.3156598
[29] Zhu Y C, Wei L L, Lang C Y, et al. Fine-grained facial expression recognition via relational reasoning and hierarchical relation optimization[J]. Pattern Recognit Lett, 2022, 164: 67−73. doi: 10.1016/j.patrec.2022.10.020
[30] Li H Y, Wang N N, Yang X, et al. Towards semi-supervised deep facial expression recognition with an adaptive confidence margin[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 4156–4165. https://doi.org/10.1109/CVPR52688.2022.00413.
-




 点击扫一扫
点击扫一扫

图(14)
表(7)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


