
 E-mail Alert
E-mail Alert RSS
RSS
Design and implementation of edge-based human action recognition algorithm based on ascend processor
-
摘要:
针对现有的人体动作识别算法精度不足、计算量大、缺少在边端设备上的部署等问题,本文提出一种基于昇腾处理器的边端轻量化人体动作识别时空图卷积算法。通过设计隐性联系骨架连接方法并构建隐性邻接矩阵,结合自然骨架连接邻接矩阵,构造显隐性融合空间图卷积。在时间维度加入空间注意力机制,使模型关注不同帧间关节点位置空间特征,进一步设计时间图卷积,构建时空图卷积。此外设计网络中的Ascend-Enisum算子,进行张量融合运算,降低了计算复杂度,使模型轻量化。针对上述改进,在KTH数据集上进行实验验证,与经典单流算法ST-GCN相比,模型计算量减小了22.28%,Top-1精度达到84.17%,提升了5%。基于上述算法设计了昇腾AI人体动作识别系统,并在边端设备成功部署,可以进行实时人体动作识别。
Abstract:Aiming at the problems of existing human action recognition algorithms such as insufficient accuracy, large amount of calculation, and lack of deployment on edge devices, this paper proposes an edge-side lightweight human action recognition spatial temporal graph convolutional algorithm based on the Ascend processor. By designing an implicit skeletal connection method and constructing an implicit adjacency matrix, combined with the natural skeletal connection adjacency matrix, we create an explicit-implicit fusion spatial graph convolution. A spatial attention mechanism is added to the temporal dimension, enabling the model to focus on spatial features of joint positions across different frames. Furthermore, we design a temporal graph convolution to construct a spatiotemporal graph convolution. Additionally, the Ascend-Enisum operator is designed within the network to perform tensor fusion operations, reducing computational complexity and lightening the model. Experimental validation on the KTH dataset demonstrates that, compared to the classical single-stream ST-GCN algorithm, our model achieves a 22.28% reduction in computational cost while attaining a Top-1 accuracy of 84.17%, representing a 5% improvement. Based on this algorithm, we have designed the Ascend AI human action recognition system, which has been successfully deployed on edge devices for real-time human action recognition.
-
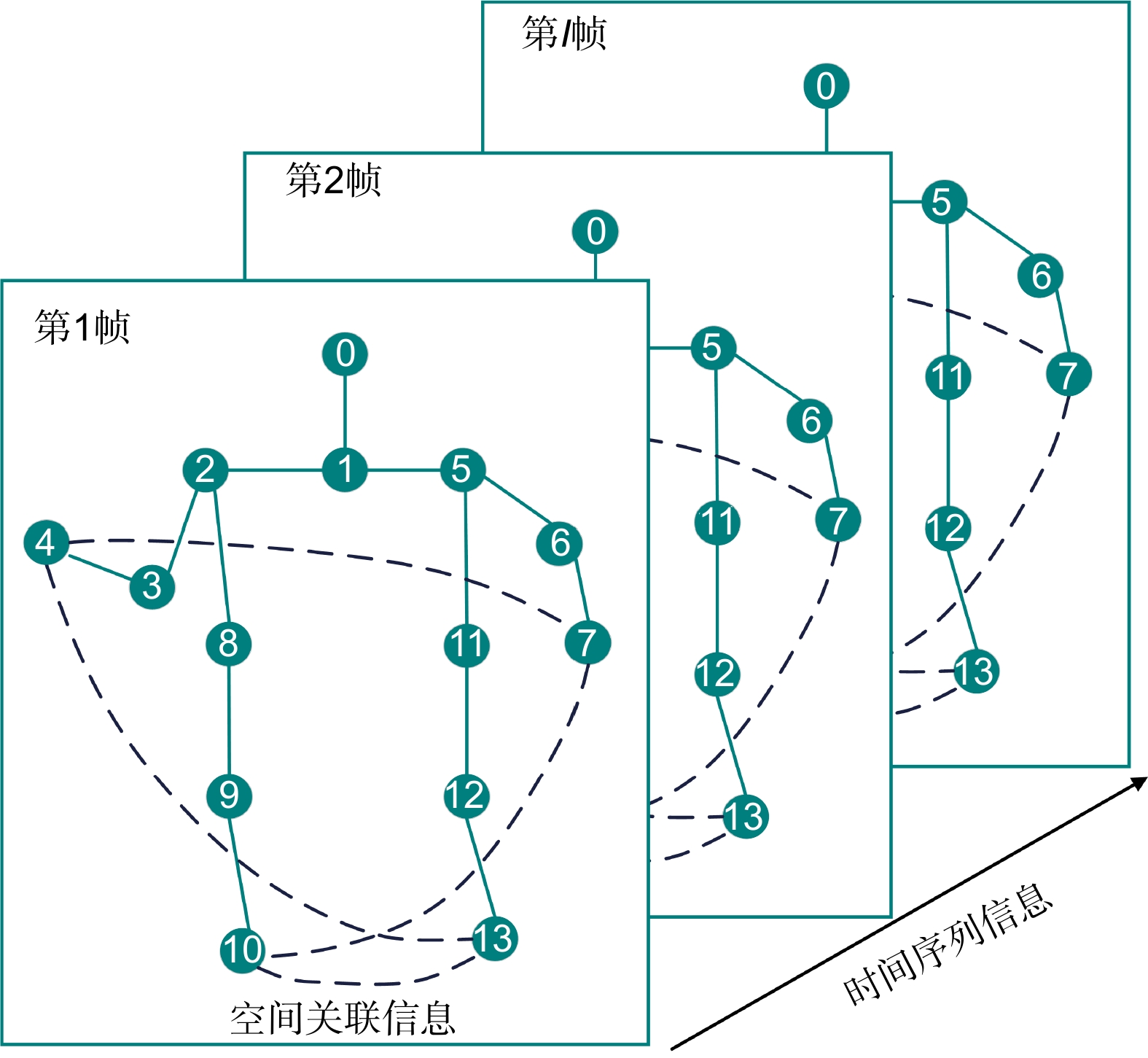
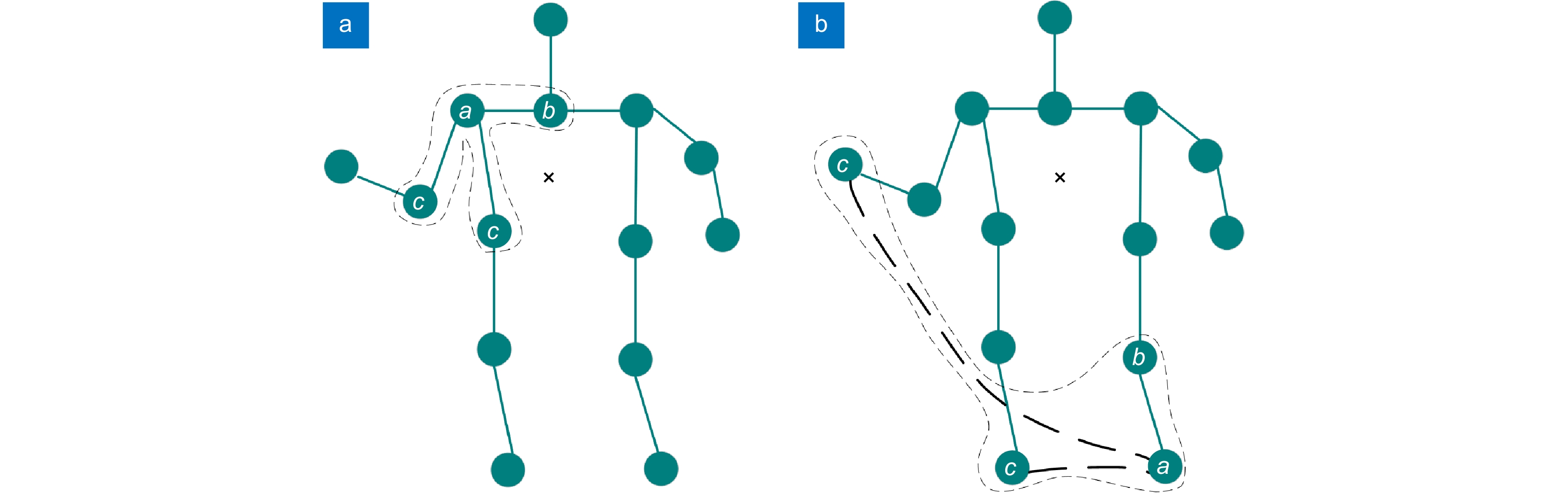
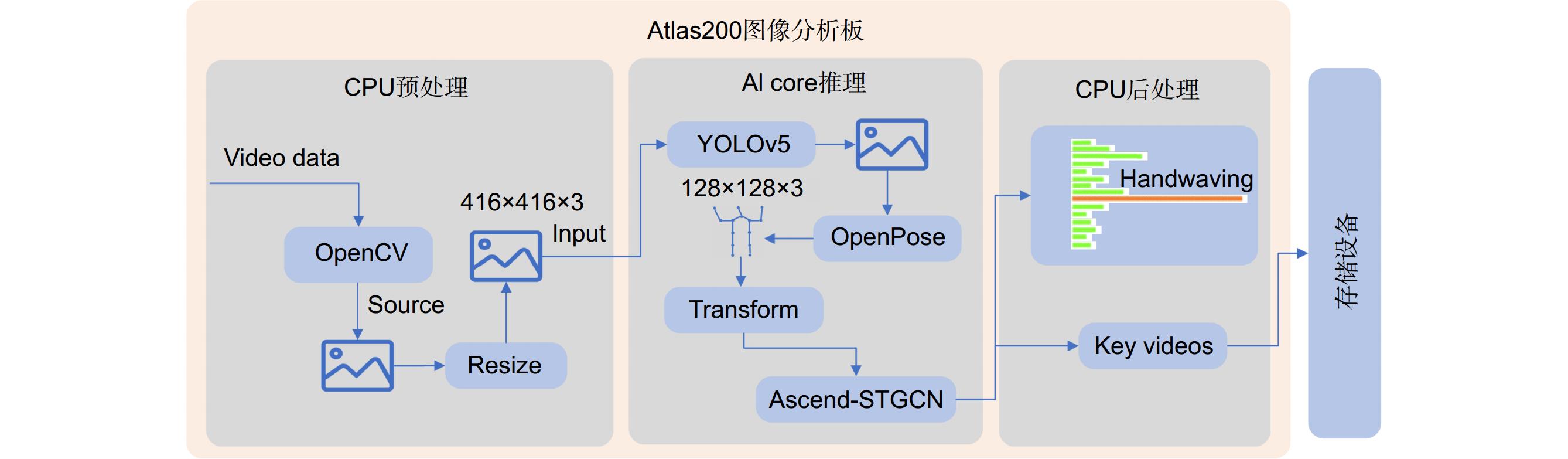
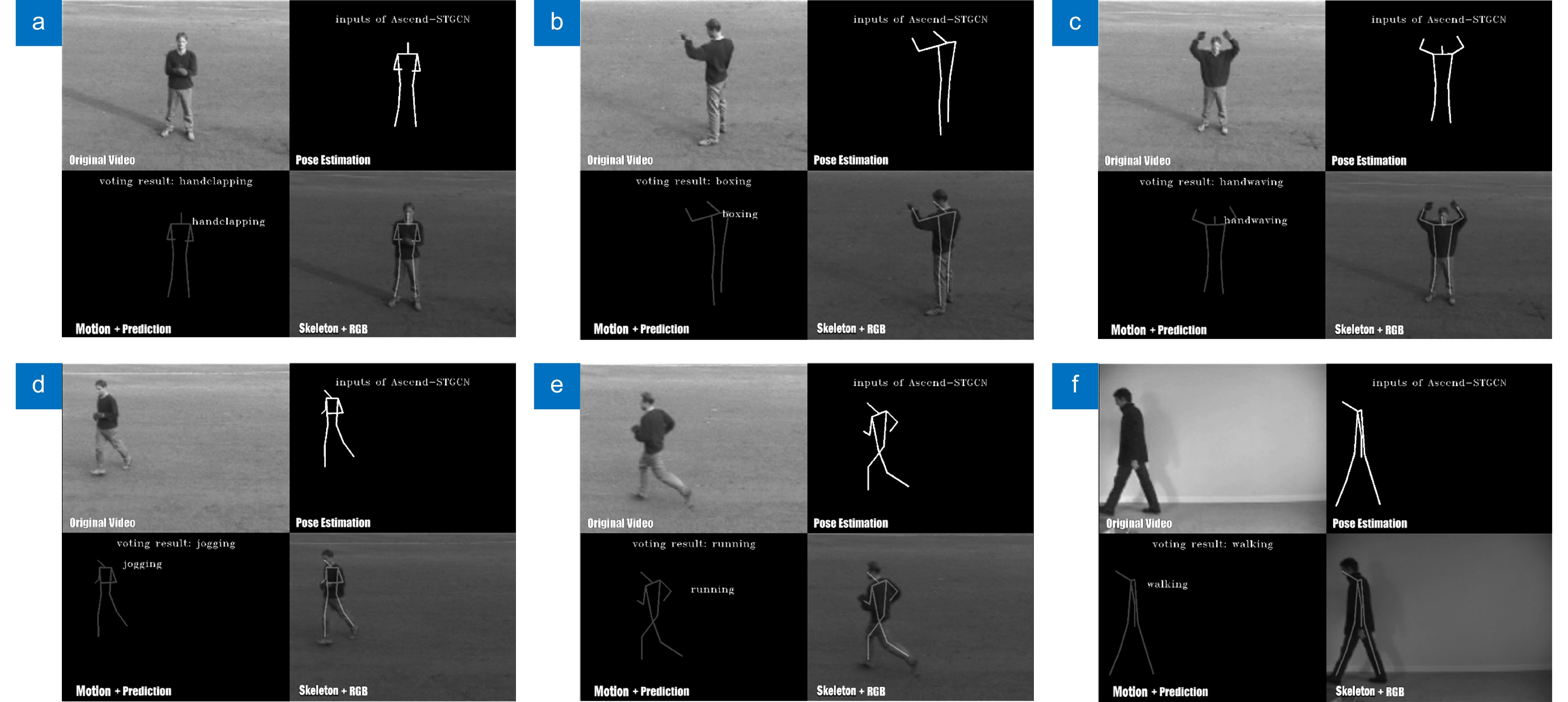
Overview: In practical applications, human action recognition has always been an immensely challenging task in the visual domain, demanding not only the system's ability to comprehend and categorize a wide range of human movements but also to perform real-time analysis and provide instant feedback. Presently, most human action recognition algorithms are deployed in the cloud, which poses issues such as network dependency and computational resource wastage compared to edge-based deployment. Therefore, deploying human action recognition on resource-constrained edge devices has emerged as a significant research focus. Addressing the challenges of insufficient accuracy, high computational complexity, and limited deployment on edge devices in current human action recognition algorithms, this paper presents a lightweight spatio-temporal graph convolutional algorithm for human action recognition optimized for the Ascend processor. It introduces an implicit connection-based skeleton approach and constructs an implicit adjacency matrix, which is combined with the explicit skeleton connection adjacency matrix to create a fused spatial graph convolution encompassing both explicit and implicit connections. Meanwhile, to overcome inadequate attention to joint spatial position information across frames, spatial attention is introduced in the temporal dimension, enhancing the focus on spatial features of skeletal points between frames. Furthermore, temporal graph convolution is designed and integrated with spatial graph convolution to form a spatio-temporal graph convolution. To address the computational intensity and incompatibility issues of the Enisum operator with the Ascend processor, an Ascend-Enisum operator is devised, optimizing the computational load and facilitating model lightweighting. The trained model, converted into Ascend-compatible format, is integrated with the YOLOv5 object detection algorithm and the OpenPose pose estimation algorithm to develop an end-to-end YOP-Ascend-STGCN human action recognition system. Experimental deployment on cameras equipped with Ascend processors demonstrates the high accuracy of the proposed method, suitable for real-time human action recognition in edge devices.
-

-
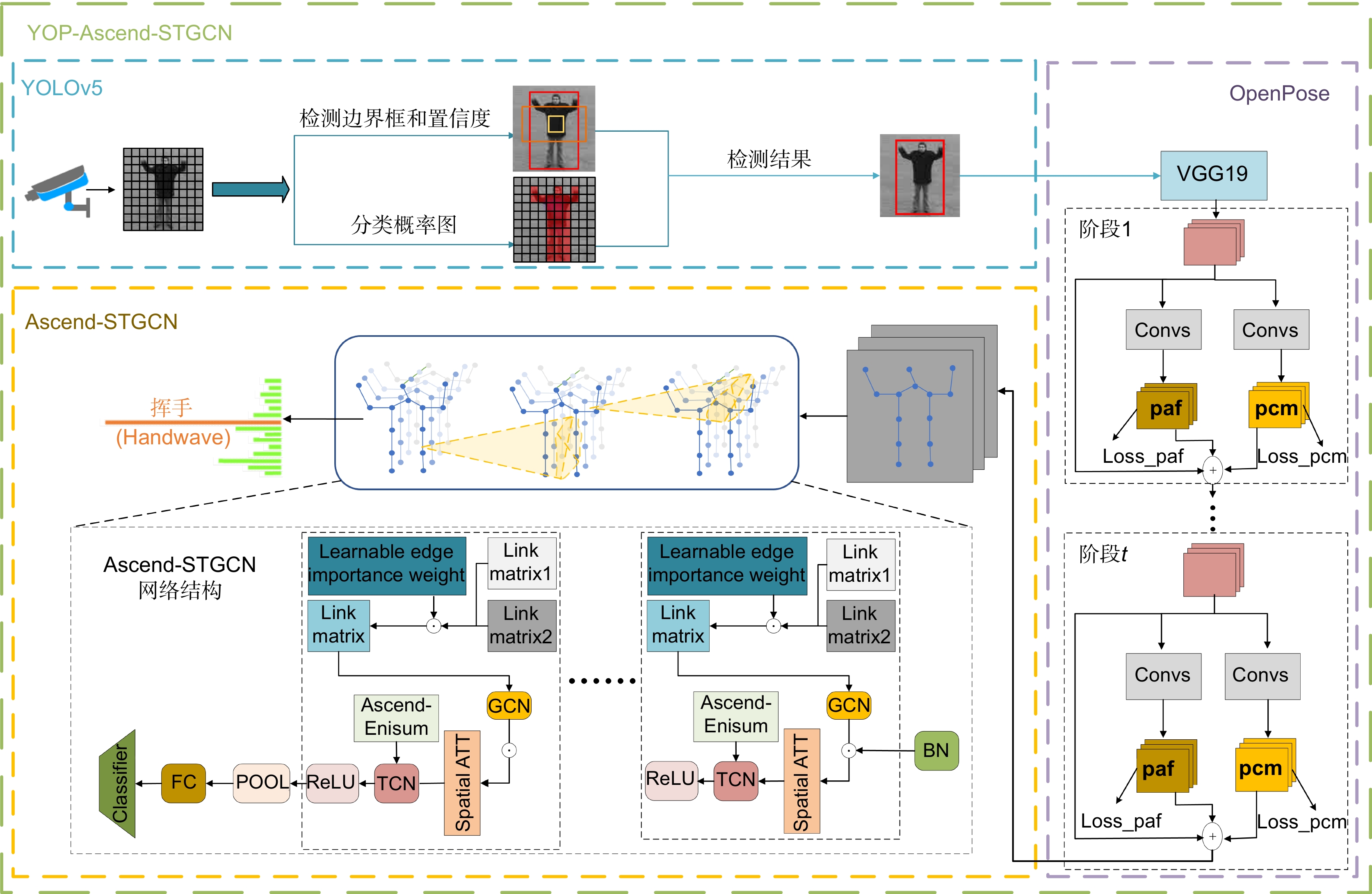
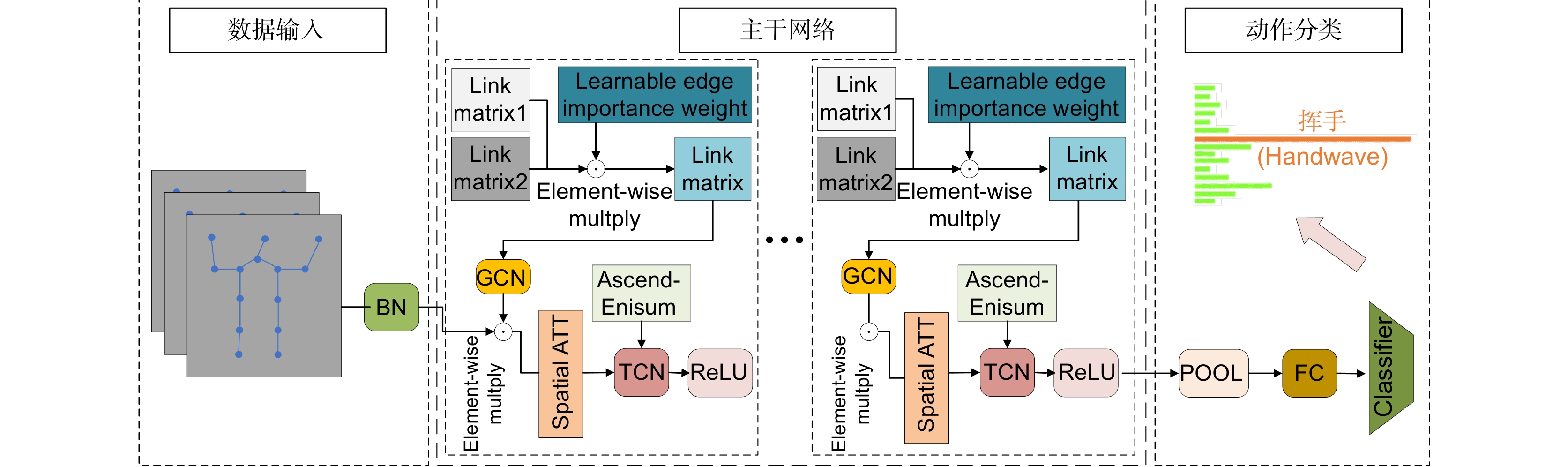
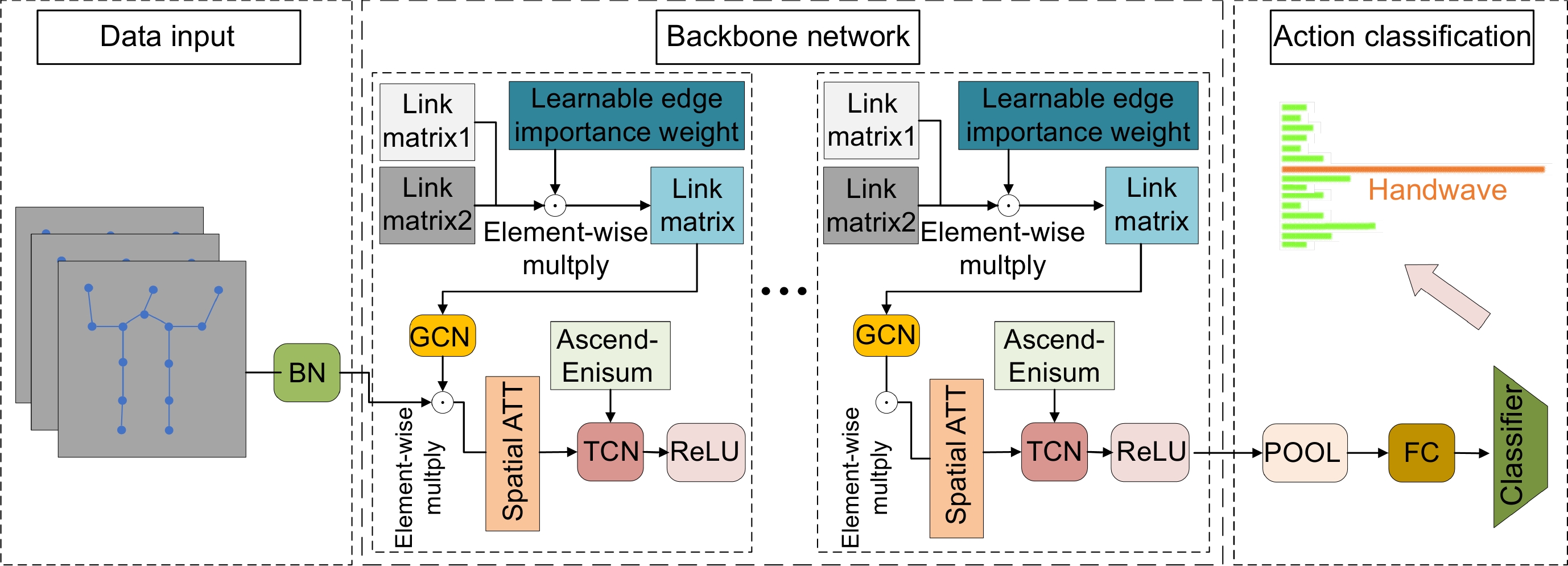
图 1 YOP-Ascend-STGCN算法总体框架
Figure 1. Overall framework of the YOP-Ascend-STGCN algorithm
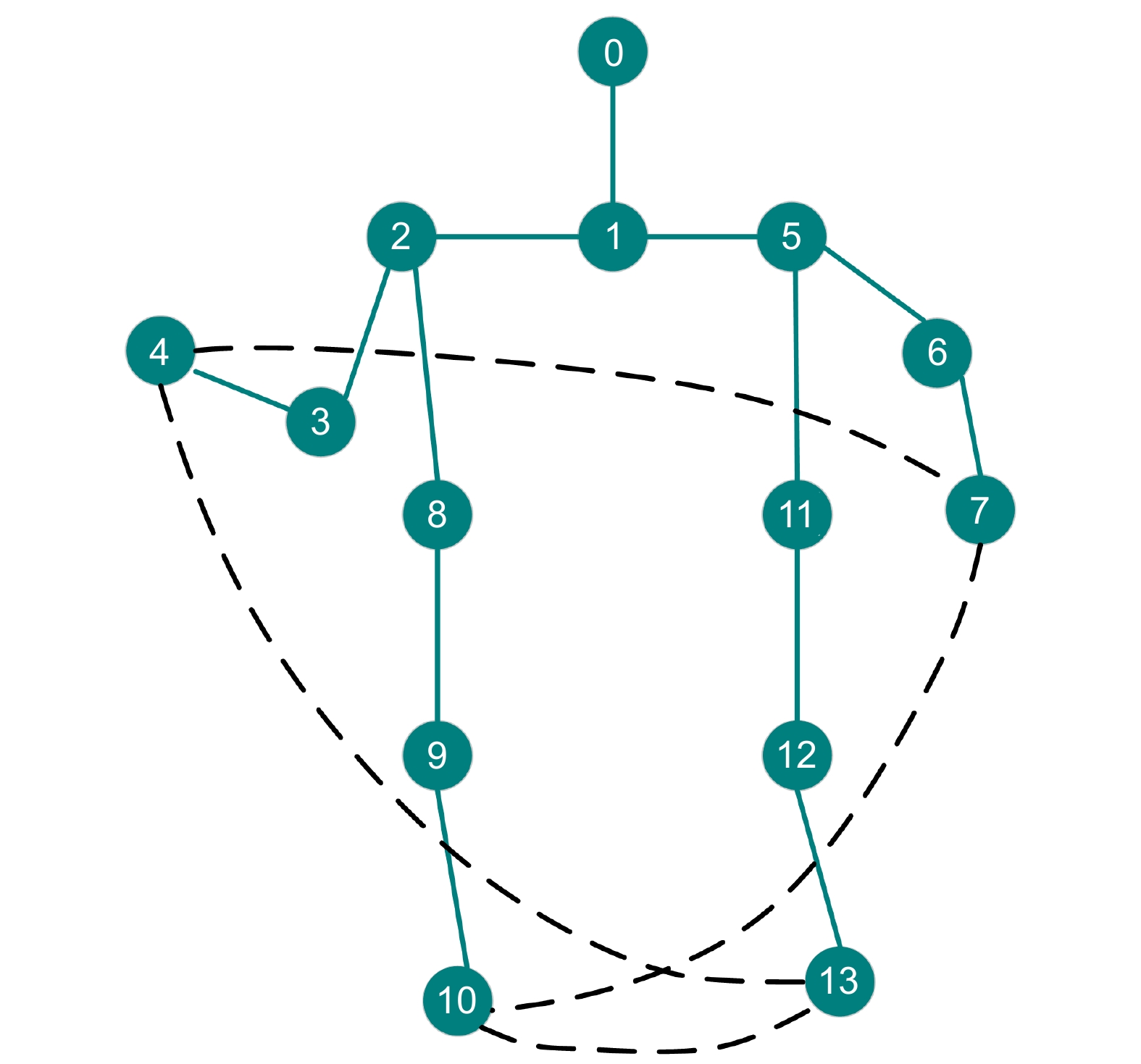
图 2 跑步动作的骨架显性关联和隐性关联结构图
Figure 2. Skeleton explicit and implicit association structure diagram of the running action
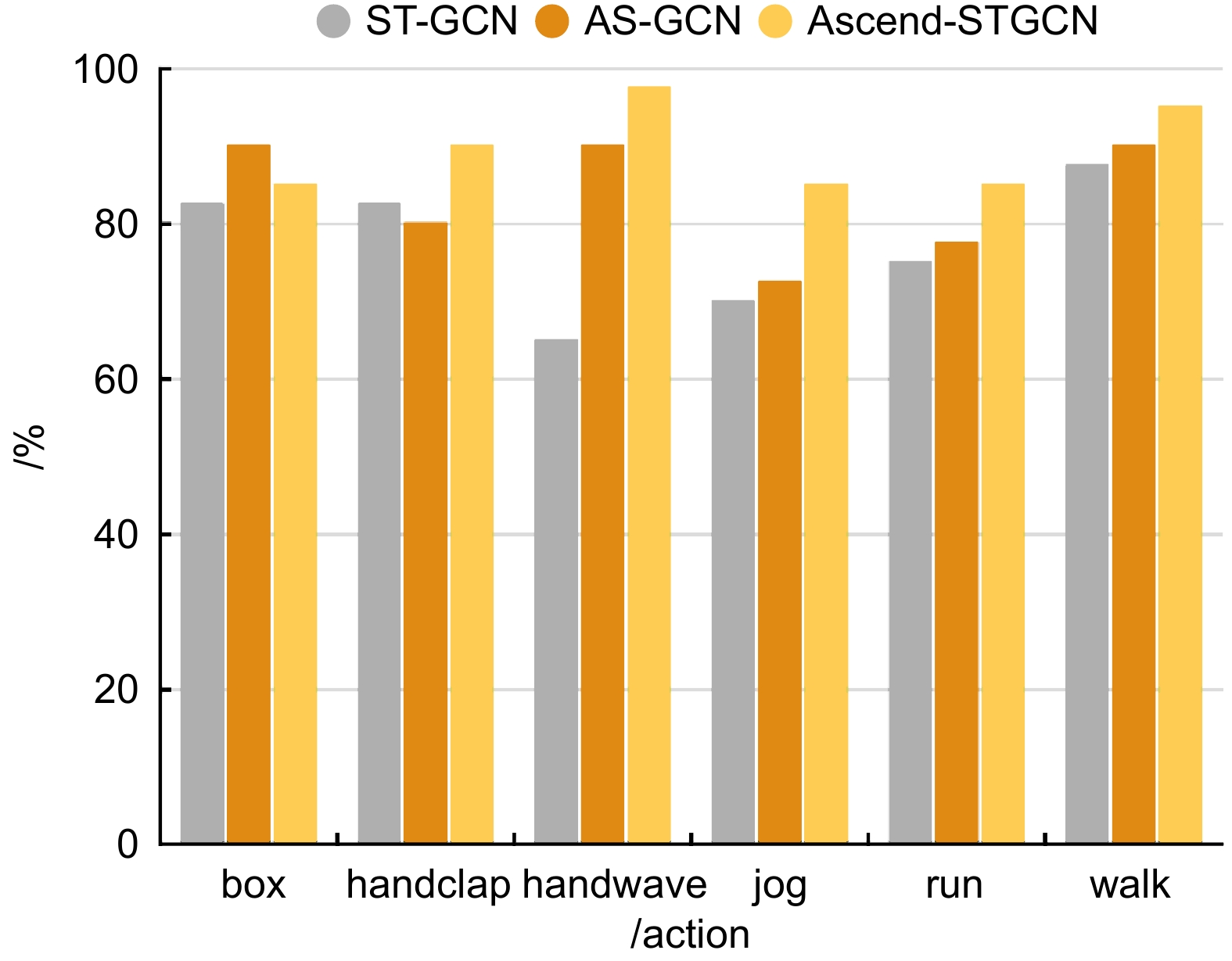
表 1 KTH数据集上的对比试验
Table 1. Comparative experiments on the KTH dataset
Algorithm Top-1/% Params/M Flops/G ST-GCN 79.17 3.68 5.88 AS-GCN 83.08 7.00 10.69 ST-TR 83.83 11.51 13.88 PoseConv3D 85.67 3.23 16.1 This paper 84.17 3.01 4.57  下载: 导出CSV
下载: 导出CSV
表 2 KTH数据集上的消融实验
Table 2. Ablation experiments on the KTH dataset
Algorithm Top-1/% Params/M FLOPs/G Epochs/轮 ST-GCN (EC+TC) 79.17 3.68 5.88 50 EC+TC+AE 81.67 2.93 4.57 50 EC+TC+IC 82.50 3.79 5.88 50 EC+TC+SA 83.33 3.68 5.88 50 Ours (EC+IC+TC+AE+SA) 84.17 3.01 4.57 50
下载: 导出CSV
-
[1] 李艳荻, 徐熙平. 基于空-时域特征决策级融合的人体行为识别算法[J]. 光学学报, 2018, 38(8): 0810001. doi: 10.3788/AOS201838.0810001
Li Y D, Xu X P. Human action recognition by decision-making level fusion based on spatial-temporal features[J]. Acta Opt Sin, 2018, 38(8): 0810001. doi: 10.3788/AOS201838.0810001
[2] Sun Z H, Ke Q H, Rahmani H, et al. Human action recognition from various data modalities: a review[J]. IEEE Trans Pattern Anal Mach Intell, 2023, 45(3): 3200−3225. doi: 10.1109/TPAMI.2022.3183112
[3] Chen C, Liu K, Kehtarnavaz N. Real-time human action recognition based on depth motion maps[J]. J Real-Time Image Process, 2016, 12(1): 155−163. doi: 10.1007/s11554-013-0370-1
[4] Li C K, Hou Y H, Wang P C, et al. Joint distance maps based action recognition with convolutional neural networks[J]. IEEE Signal Process Lett, 2017, 24(5): 624−628. doi: 10.1109/LSP.2017.2678539
[5] Kumar S S, John M. Human activity recognition using optical flow based feature set[C]//2016 IEEE International Carnahan Conference on Security Technology (ICCST), Orlando, 2016: 1–5.https://doi.org/10.1109/CCST.2016.7815694.
[6] 冷佳旭, 谭明圮, 胡波, 等. 基于隐式视角转换的视频异常检测[J]. 计算机科学, 2022, 49(2): 142−148. doi: 10.11896/jsjkx.210900266
Leng J X, Tan M P, Hu B, et al. Video anomaly detection based on implicit view transformation[J]. Comput Sci, 2022, 49(2): 142−148. doi: 10.11896/jsjkx.210900266
[7] 李国友, 李晨光, 王维江, 等. 基于单样本学习的多特征人体姿态模型识别研究[J]. 光电工程, 2021, 48(2): 200099. doi: 10.12086/oee.2021.200099
Li G Y, Li C G, Wang W J, et al. Research on multi-feature human pose model recognition based on one-shot learning[J]. Opto-Electron Eng, 2021, 48(2): 200099. doi: 10.12086/oee.2021.200099
[8] Wu H B, Ma X, Li Y B. Spatiotemporal multimodal learning with 3D CNNs for video action recognition[J]. IEEE Trans Circuits Syst Video Technol, 2022, 32(3): 1250−1261. doi: 10.1109/TCSVT.2021.3077512
[9] Liu Z Y, Zhang H W, Chen Z H, et al. Disentangling and unifying graph convolutions for skeleton-based action recognition[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 140–149.https://doi.org/10.1109/CVPR42600.2020.00022.
[10] Cheng K, Zhang Y F, He X Y, et al. Skeleton-based action recognition with shift graph convolutional network[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 180–189.https://doi.org/10.1109/CVPR42600.2020.00026.
[11] 解宇, 杨瑞玲, 刘公绪, 等. 基于动态拓扑图的人体骨架动作识别算法[J]. 计算机科学, 2022, 49(2): 62−68. doi: 10.11896/jsjkx.210900059
Xie Y, Yang R L, Liu G X, et al. Human skeleton action recognition algorithm based on dynamic topological graph[J]. Comput Sci, 2022, 49(2): 62−68. doi: 10.11896/jsjkx.210900059
[12] 刘宝龙, 周森, 董建锋, 等. 基于骨架的人体动作识别技术研究进展[J]. 计算机辅助设计与图形学学报, 2023, 35(9): 1299−1322. doi: 10.3724/SP.J.1089.2023.19640
Liu B L, Zhou S, Dong J F, et al. Research progress in skeleton-based human action recognition[J]. J Comput-Aided Des Comput Graphics, 2023, 35(9): 1299−1322. doi: 10.3724/SP.J.1089.2023.19640
[13] Law H, Deng J. CornerNet: detecting objects as paired keypoints[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, 2018: 765–781.https://doi.org/10.1007/978-3-030-01264-9_45.
[14] Duan K W, Bai S, Xie L X, et al. CenterNet: keypoint triplets for object detection[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, 2019: 6568–6577.https://doi.org/10.1109/ICCV.2019.00667.
[15] Zhu C C, He Y H, Savvides M. Feature selective anchor-free module for single-shot object detection[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 840–849.https://doi.org/10.1109/CVPR.2019.00093.
[16] Zhu C C, Chen F Y, Shen Z Q, et al. Soft anchor-point object detection[C]//Proceedings of the 16th European Conference on Computer Vision, Glasgow, 2020: 91–107.https://doi.org/10.1007/978-3-030-58545-7_6.
[17] 马梁, 苟于涛, 雷涛, 等. 基于多尺度特征融合的遥感图像小目标检测[J]. 光电工程, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363
Ma L, Gou Y T, Lei T, et al. Small object detection based on multi-scale feature fusion using remote sensing images[J]. Opto-Electron Eng, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363
[18] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, 2014: 580–587.https://doi.org/10.1109/CVPR.2014.81.
[19] Girshick R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, 2015: 1440–1448.https://doi.org/10.1109/ICCV.2015.169.
[20] 彭昊, 王婉祺, 陈龙, 等. 在线推断校准的小样本目标检测[J]. 光电工程, 2023, 50(1): 220180. doi: 10.12086/oee.2023.220180
Peng H, Wang W Q, Chen L, et al. Few-shot object detection via online inferential calibration[J]. Opto-Electron Eng, 2023, 50(1): 220180. doi: 10.12086/oee.2023.220180
[21] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision, Amsterdam, 2016: 21–37.https://doi.org/10.1007/978-3-319-46448-0_2.
[22] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, 2017: 2999–3007.https://doi.org/10.1109/ICCV.2017.324.
[23] 陈旭, 彭冬亮, 谷雨. 基于改进YOLOv5s的无人机图像实时目标检测[J]. 光电工程, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
Chen X, Peng D L, Gu Y. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electron Eng, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
[24] 赵冬冬, 谢墩翰, 陈朋, 等. 基于ZYNQ的轻量化YOLOv5声呐图像目标检测算法及实现[J]. 光电工程, 2024, 51(1): 230284. doi: 10.12086/oee.2024.230284
Zhao D D, Xie D H, Chen P, et al. Lightweight YOLOv5 sonar image object detection algorithm and implementation based on ZYNQ[J]. Opto-Electron Eng, 2024, 51(1): 230284. doi: 10.12086/oee.2024.230284
[25] Fang H S, Xie S Q, Tai Y W, et al. RMPE: regional multi-person pose estimation[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, 2017: 2353–2362.https://doi.org/10.1109/ICCV.2017.256.
[26] Debnath B, O’Brien M, Yamaguchi M, et al. Adapting MobileNets for mobile based upper body pose estimation[C]//2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, 2018: 1–6.https://doi.org/10.1109/AVSS.2018.8639378.
[27] Qiao S, Wang Y L, Li J. Real-time human gesture grading based on OpenPose[C]//2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, 2017: 1–6.https://doi.org/10.1109/CISP-BMEI.2017.8301910.
[28] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[C]//Proceedings of the 5th International Conference on Learning Representations, Toulon, 2017.
[29] Zhao L, Song Y J, Zhang C, et al. T-GCN: a temporal graph convolutional network for traffic prediction[J]. IEEE Trans Intell Transp Syst, 2020, 21(9): 3848−3858. doi: 10.1109/TITS.2019.2935152
[30] Klaus J, Blacher M, Giesen J. Compiling tensor expressions into einsum[C]//Proceedings of the 23rd International Conference on Computational Science, Prague, 2023: 129–136.https://doi.org/10.1007/978-3-031-36021-3_10.
[31] Zhao D D, Zhou H C, Chen P, et al. Design of forward-looking sonar system for real-time image segmentation with light multiscale attention net[J]. IEEE Trans Instrum Meas, 2024, 73: 4501217. doi: 10.1109/TIM.2023.3341127
[32] 何英春, 詹益镐, 许桂清, 等. 人体姿势估计OpenPose技术在康复领域的应用进展[J]. 中国康复, 2023, 38(7): 437−441. doi: 10.3870/zgkf.2023.07.012
He Y C, Zhan Y G, Xu G Q, et al. Progress in the application of OpenPose technology for human pose estimation in rehabilitation[J]. Chin J Rehabil, 2023, 38(7): 437−441. doi: 10.3870/zgkf.2023.07.012
[33] 戚亚明, 陈树越, 孙磊. 基于改进ViBe算法的双流CNN跌倒检测[J]. 计算机工程与设计, 2023, 44(6): 1812−1819. doi: 10.16208/j.issn1000-7024.2023.06.030
Qi Y M, Chen S Y, Sun L. Two-stream CNN fall detection based on improved ViBe algorithm[J]. Comput Eng Des, 2023, 44(6): 1812−1819. doi: 10.16208/j.issn1000-7024.2023.06.030
[34] Yan S J, Xiong Y J, Lin D H. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]//Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, 2018: 912.
[35] Li M S, Chen S H, Chen X, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 3590–3598.https://doi.org/10.1109/CVPR.2019.00371.
[36] Plizzari C, Cannici M, Matteucci M. Skeleton-based action recognition via spatial and temporal transformer networks[J]. Comput Vision Image Underst, 2021, 208–209 : 103219.https://doi.org/10.1016/j.cviu.2021.103219.
[37] Duan H D, Zhao Y, Chen K, et al. Revisiting skeleton-based action recognition[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, 2022: 2959–2968.https://doi.org/10.1109/CVPR52688.2022.00298.
-



 点击扫一扫
点击扫一扫
图(12)
表(2)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


