
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
针对基于CNN的立体匹配方法中特征提取难以较好学习全局和远程上下文信息的问题,提出一种基于Swin Transformer的立体匹配网络改进模型 (stereo matching net with swin transformer fusion, STransMNet)。分析了在立体匹配过程中,聚合局部和全局上下文信息的必要性和匹配特征的差异性。改进了特征提取模块,把基于CNN的方法替换为基于Transformer的Swin Transformer方法;并在Swin Transformer中加入多尺度特征融合模块,使得输出特征同时包含浅层和深层语义信息;通过提出特征差异化损失改进了损失函数,以增强模型对细节的注意力。最后,在多个公开数据集上与STTR-light模型进行了对比实验,误差(End-Point-Error, EPE) 和匹配错误率3 px error均有明显降低。
-
关键词:
- 立体匹配 /
- Swin Transformer /
- 深度学习 /
- STransMNet
Abstract:Feature extraction in the CNN-based stereo matching models has the problem that it is difficult to learn global and long-range context information. To solve this problem, an improved model STransMNet stereo matching network based on the Swin Transformer is proposed in this paper. We analyze the necessity of the aggregated local and global context information. Then the difference in matching features during the stereo matching process is discussed. The feature extraction module is improved by replacing the CNN-based algorithm with the Transformer-based Swin Transformer algorithm to enhance the model's ability to capture remote context information. The multi-scale fusion module is added in Swin Transformer to make the output features contain shallow and deep semantic information. The loss function is improved by introducing the feature differentiation loss to enhance the model's attention to details. Finally, the comparative experiments with the STTR-light model are conducted on multiple public datasets, showing that the End-Point-Error (EPE) and the matching error rate of 3 px error are significantly reduced.
-
Key words:
- stereo matching /
- Swin Transformer /
- deep learning /
- STransMNet
-
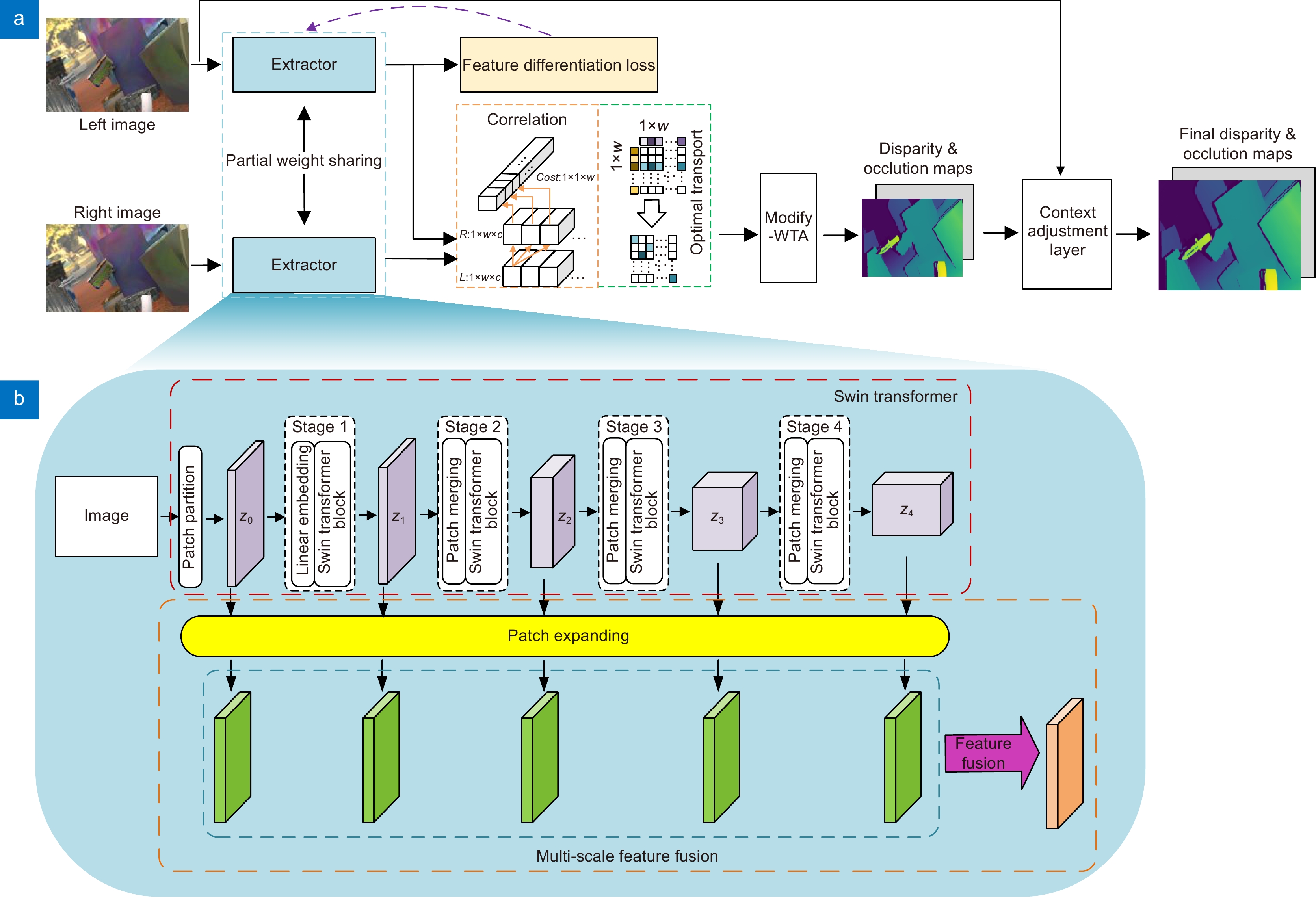
Overview: In the stereo matching process, unique pixel features are extracted by aggregating local and global context information. The pixel features on the pole lines of the left and right images are then matched. With the rapid application of deep learning (DL) methods in the field of image processing, end-to-end neural networks of DL are used to estimate the disparity maps. Although CNN-based algorithms have excellent feature representation capabilities, they often exhibit limitations in modeling explicit long-range relationships due to the inherent locality of the convolution operations. For objects with weak textures and large differences in shape and size, the results of using CNN alone are often unsatisfactory. To solve this problem, an improved model STransMNet stereo matching network based on the Swin Transformer is proposed in this paper. We analyze the necessity of the aggregated local and global context information. Then the difference in matching features during the stereo matching process is discussed. The feature extraction module is improved by replacing the CNN-based algorithm with the Transformer-based Swin Transformer algorithm. The rectified left and right images are fed into Swin Transformer module to generate multi-scale features. Then the multi-scale features are fed into the patch expanding module, the transformation of the linear layer, to make them the same size. Finally, the multi-scale features are fused in the channel dimension. The additional multi-scale fusion module makes the features output by the improved Swin Transformer fuse shallow and deep semantic information. The Swin Transformer used to extract the left and right image features is partially shared by the weights. Although weight sharing makes the model converge faster, our proposed feature differentiation loss can only supervise left or right images. If the full weights are shared, it is equivalent to supervising the left and right images at the same time. Partial weight sharing speeds up the convergence of the model to a certain extent. In addition, partial weight sharing enables the model to extract not only the commonalities of left and right image but also the differences. Furthermore, a feature differentiation loss is proposed in this work to improve the model's ability to pay attention to details. The loss is trained by forcing the classification of pixel features on the epipolar line of the left image, which makes each pixel feature unique. The experimental results on the Sceneflow and KITTI datasets show that our algorithm reduces the 3 px error and EPE compared to the previous algorithms. Experiments show that the proposed STransMNet model reduces the matching error and improves the quality of the disparity maps. It shows that the excellent performance of the improved Swin Transformer in capturing long-distance context information is beneficial to improving the accuracy of stereo matching; feature differentiation loss helps to enhance the detailed information of the disparity maps.
-

-
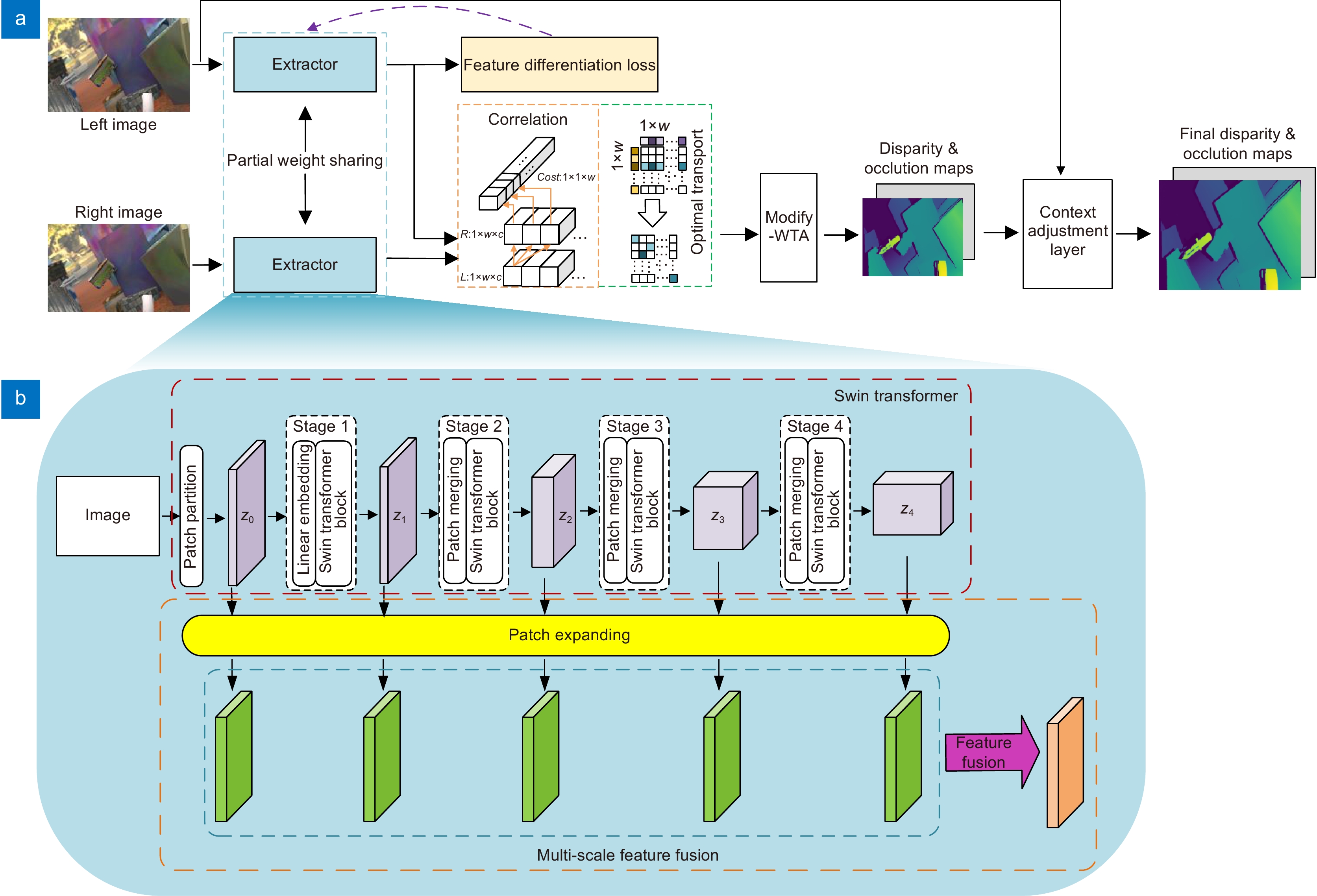
图 2 (a) STransMNet网络结构;(b) 特征提取器的结构
Figure 2. (a) The network structure of STransMNet; (b) The structure of extractor
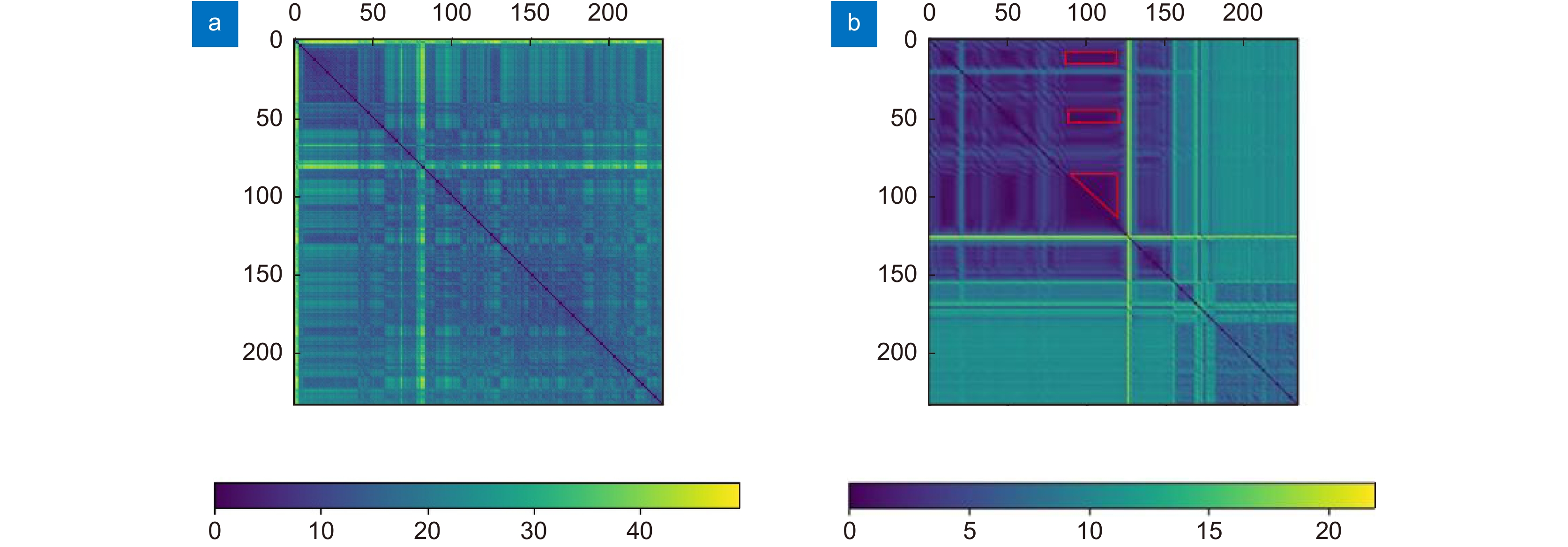
图 3 左图像上的像素特征之间的欧式距离。(a) 加入特征差异化损失;(b) 未加入特征差异化损失
Figure 3. Euclidean distance between the pixel features on the left image. (a) There is a feature differentiation loss; (b) No a feature differentiation loss

图 4 不同方法在Sceneflow数据集上的估计的视差图
Figure 4. Disparity map estimated by different methods on the Sceneflow datasets

图 5 不同方法在KITTI数据集上的估计的视差图
Figure 5. Disparity map estimated by different methods on the KITTI datasets
表 1 消融实验
Table 1. Ablation study
实验 基于Swin Transformer模块 相关运算 特征差异化损失 3 px error / % ↓ EPE ↓ Occ IOU ↑ 第1组 1.68 0.56 0.94 第2组 √ 1.36 0.48 0.96 第3组 √ √ 1.40 0.51 0.95 第4组 √ √ √ 1.03 0.42 0.97  下载: 导出CSV
下载: 导出CSV
表 2 不同的损失权重实验结果
Table 2. Experimental results of different loss weights
Ld1,r Ld1,f Lrr Lbe,f Ldiff 3 px error /%↓ EPE ↓ Occ IOU ↑ 0.2 0.2 0.2 0.2 0.2 0.85 0.41 0.97 0.2 0.2 0.2 0.1 0.3 0.93 0.51 0.84 0.3 0.3 0.1 0.1 0.2 0.89 0.43 0.85 0.3 0.4 0.1 0.1 0.1 0.84 0.39 0.96 0.4 0.3 0.1 0.1 0.1 0.87 0.40 0.91
下载: 导出CSV
-
[1] 李珣, 李林鹏, Lazovik A, 等. 基于改进双流卷积递归神经网络的RGB-D物体识别方法[J]. 光电工程, 2021, 48(2): 200069. doi: 10.12086/oee.2021.200069
Li X, Li L P, Lazovik A, et al. RGB-D object recognition algorithm based on improved double stream convolution recursive neural network[J]. Opto-Electron Eng, 2021, 48(2): 200069. doi: 10.12086/oee.2021.200069
[2] Hoffman J, Gupta S, Leong J, et al. Cross-modal adaptation for RGB-D detection[C]//2016 IEEE International Conference on Robotics and Automation (ICRA), 2016: 5032–5039. https://doi.org/10.1109/ICRA.2016.7487708.
[3] Schwarz M, Milan A, Periyasamy A S, et al. RGB-D object detection and semantic segmentation for autonomous manipulation in clutter[J]. Int J Robot Res, 2018, 37(4–5): 437–451. https://doi.org/10.1177/0278364917713117.
[4] 曹春林, 陶重犇, 李华一, 等. 实时实例分割的深度轮廓段落匹配算法[J]. 光电工程, 2021, 48(11): 210245. doi: 10.12086/oee.2021.210245
Cao C L, Tao C B, Li H Y, et al. Deep contour fragment matching algorithm for real-time instance segmentation[J]. Opto-Electron Eng, 2021, 48(11): 210245. doi: 10.12086/oee.2021.210245
[5] Scharstein D, Szeliski R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. Int J Comput Vision, 2002, 47(1–3): 7–42. https://doi.org/10.1023/A:1014573219977.
[6] Tippetts B, Lee D J, Lillywhite K, et al. Review of stereo vision algorithms and their suitability for resource-limited systems[J]. J Real-Time Image Proc, 2016, 11(1): 5−25. doi: 10.1007/s11554-012-0313-2
[7] Hirschmuller H. Stereo processing by semiglobal matching and mutual information[J]. IEEE Trans Pattern Anal Mach Intell, 2008, 30(2): 328−341. doi: 10.1109/TPAMI.2007.1166
[8] Mayer N, Ilg E, Häusser P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 4040–4048. https://doi.org/10.1109/CVPR.2016.438.
[9] Kendall A, Martirosyan H, Dasgupta S, et al. End-to-end learning of geometry and context for deep stereo regression[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 66–75. https://doi.org/10.1109/ICCV.2017.17.
[10] Chang J R, Chen Y S. Pyramid stereo matching network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 5410–5418. https://doi.org/10.1109/CVPR.2018.00567.
[11] Xu H F, Zhang J Y. AANet: Adaptive aggregation network for efficient stereo matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1956–1965. https://doi.org/10.1109/CVPR42600.2020.00203.
[12] Khamis S, Fanello S, Rhemann C, et al. StereoNet: Guided hierarchical refinement for real-time edge-aware depth prediction[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 596–613. https://doi.org/10.1007/978-3-030-01267-0_35.
[13] Chopra S, Hadsell R, LeCun Y. Learning a similarity metric discriminatively, with application to face verification[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), 2005, 1: 539–546. https://doi.org/10.1109/CVPR.2005.202.
[14] He K M, Zhang X Y, Ren S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans Pattern Anal Mach Intell, 2015, 37(9): 1904−1916. doi: 10.1109/TPAMI.2015.2389824
[15] Zhao H S, Shi J P, Qi X J, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6230–6239. https://doi.org/10.1109/CVPR.2017.660.
[16] Nie G Y, Cheng M M, Liu Y, et al. Multi-level context ultra-aggregation for stereo matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 3278–3286. https://doi.org/10.1109/CVPR.2019.00340.
[17] Zhang F H, Prisacariu V, Yang R G, et al. Ga-Net: guided aggregation net for end-to-end stereo matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 185–194. https://doi.org/10.1109/CVPR.2019.00027.
[18] Chabra R, Straub J, Sweeney C, et al. StereoDRNet: dilated residual StereoNet[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 11778–11787. https://doi.org/10.1109/CVPR.2019.01206.
[19] Li Z S, Liu X T, Drenkow N, et al. Revisiting stereo depth estimation from a sequence-to-sequence perspective with Transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021: 6177–6186. https://doi.org/10.1109/ICCV48922.2021.00614.
[20] Tulyakov S, Ivanov A, Fleuret F. Practical deep stereo (PDS): toward applications-friendly deep stereo matching[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems, 2018: 5875–5885. https://doi.org/10.5555/3327345.3327488.
[21] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[22] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 3–19. https://doi.org/10.1007/978-3-030-01234-2_1.
[23] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale[C]//9th International Conference on Learning Representations, 2021.
[24] Han K, Xiao A, Wu E H, et al. Transformer in transformer[C]//Proceedings of the 35th Conference on Neural Information Processing Systems, 2021: 15908–15919.
[25] Fang Y X, Liao B C, Wang X G, et al. You only look at one sequence: rethinking transformer in vision through object detection[C]//Proceedings of the 35th Conference on Neural Information Processing Systems, 2021: 26183–26197.
[26] Liu Z, Lin Y T, Cao Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021: 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986.
[27] Courty N, Flamary R, Tuia D, et al. Optimal transport for domain adaptation[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(9): 1853−1865. doi: 10.1109/TPAMI.2016.2615921
[28] Liu Y B, Zhu L C, Yamada M, et al. Semantic correspondence as an optimal transport problem[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4463–4472. https://doi.org/10.1109/CVPR42600.2020.00452.
[29] Sarlin P E, DeTone D, Malisiewicz T, et al. Superglue: learning feature matching with graph neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4937–4946. https://doi.org/10.1109/CVPR42600.2020.00499.
[30] Cao H, Wang Y Y, Chen J, et al. Swin-Unet: Unet-like pure Transformer for medical image segmentation[C]//Proceedings of the International Conference on Computer Vision, 2022: 205–218. https://doi.org/10.1007/978-3-031-25066-8_9.
[31] Menze M, Geiger A. Object scene flow for autonomous vehicles[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3061–3070. https://doi.org/10.1109/CVPR.2015.7298925.
[32] He K M, Girshick R, Dollár P. Rethinking ImageNet pre-training[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 4917–4926. https://doi.org/10.1109/ICCV.2019.00502.
-
 点击扫一扫
点击扫一扫
图(6)
表(6)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


