
 E-mail Alert
E-mail Alert RSS
RSS
Multi-scale feature enhanced Transformer network for efficient semantic segmentation
-
摘要
针对现有基于Transformer的语义分割网络存在的多尺度语义信息利用不充分、处理图像时生成冗长序列导致的高计算成本等问题,本文提出了一种基于多尺度特征增强的高效语义分割主干网络MFE-Former。该网络主要包括多尺度池化自注意力模块(multi-scale pooling self-attention, MPSA)和跨空间前馈网络模块(cross-spatial feed-forward network, CS-FFN)。其中,MPSA利用多尺度池化操作对特征图序列进行降采样,在减少计算成本的同时还高效地从特征图序列中提取多尺度的上下文信息,增强Transformer对多尺度信息的建模能力;CS-FFN通过采用简化的深度卷积层替代传统的全连接层,减少前馈网络初始线性变换层的参数量,并在前馈网络中引入跨空间注意力(cross-spatial attention, CSA),使模型更有效地捕捉不同空间的交互信息,进一步增强模型的表达能力。MFE-Former在数据集ADE20K、Cityscapes和COCO-Stuff上的平均交并比分别达到44.1%、80.6%和38.0%,与主流分割算法相比,MFE-Former能够以更低的计算成本获得具有竞争力的分割精度,有效改善了现有方法多尺度信息利用不足和计算成本高的问题。
-
关键词:
- 语义分割 /
- Transformer /
- 深度学习 /
- 注意力机制
Abstract
To address the issues of insufficient utilization of multi-scale semantic information and high computational costs resulting from the generation of lengthy sequences in existing Transformer-based semantic segmentation networks, this paper proposes an efficient semantic segmentation backbone named MFE-Former, based on multi-scale feature enhancement. The network mainly includes the multi-scale pooling self-attention (MPSA) and the cross-spatial feed-forward network (CS-FFN). MPSA employs multi-scale pooling to downsample the feature map sequences, thereby reducing computational cost while efficiently extracting multi-scale contextual information, enhancing the Transformer’s capacity for multi-scale information modeling. CS-FFN replaces the traditional fully connected layers with simplified depth-wise convolution layers to reduce the parameters in the initial linear transformation of the feed-forward network and introduces a cross-spatial attention (CSA) to better capture different spaces interaction information, further enhancing the expressive power of the model. On the ADE20K, Cityscapes, and COCO-Stuff datasets, MFE-Former achieves mean intersection-over-union (mIoU) scores of 44.1%, 80.6%, and 38.0%, respectively. Compared to mainstream segmentation algorithms, MFE-Former demonstrates competitive segmentation accuracy at lower computational costs, effectively improving the utilization of multi-scale information and reducing computational burden.
-
Key words:
- semantic segmentation /
- transformer /
- deep learning /
- attention mechanism
-
Overview
Overview: In recent years, advancements in deep learning have propelled the field of semantic segmentation forward, resulting in the development of numerous innovative algorithms. The approach of employing extensive datasets to train deep learning models that automatically extract features has become the predominant method in semantic segmentation. Since Dosovitskiy introduced the Transformer to image vision tasks, many scholars have attempted to use Transformer models to address semantic segmentation issues, achieving notable results. In visual Transformers, the sequence length obtained after image encoding is much longer than the sequences in natural language processing. This leads to the need for large-scale matrix multiplication operations in the multi-head self-attention mechanism layers, significantly increasing the computational burden. This is also the main challenge faced when directly introducing Transformers from the NLP field to the computer vision field. PVT proposed a solution to reduce the computation by shortening the sequence length through a single pooling operation. However, the relative importance of different elements and positions in the image varies, and a single pooling operation cannot fully capture the multi-scale features under different receptive fields, leading to the loss of some information in the original sequence. Moreover, the traditional feed-forward network uses multi-layer perceptrons to enhance the model's representational power, but its fully connected architecture results in a large number of parameters in each Transformer block, and it is not adept at learning spatial relationships. In response to the aforementioned issues, this paper introduces an efficient semantic segmentation backbone network based on multi-scale feature enhancement, named MFE-Former. The network mainly includes the multi-scale pooling self-attention (MPSA) module and the cross-spatial feed-forward network (CS-FFN) module. The MPSA utilizes multi-scale pooling operations to downsample the feature map sequence, achieving a reduction in computational costs while efficiently extracting multi-scale contextual information from the feature map sequence, enhancing the Transformer's ability to model multi-scale information. The CS-FFN replaces the traditional fully connected layers with simplified depth convolutional layers, reducing the parameter count of the initial linear transformation layer in the feed-forward network, and introduces the cross-spatial attention module, enabling the model to more effectively capture interactions between different spatial regions and further enhancing the model's expressive power. The MFE-Former achieves mIoU of 44.1%, 80.6%, and 38.0% on the datasets ADE20K, Cityscapes, and COCO-Stuff, respectively. Compared to mainstream segmentation algorithms, MFE-Former can achieve competitive segmentation accuracy at a lower computational cost, effectively improving the issues of insufficient utilization of multi-scale information and high computational costs in existing methods.
-

-

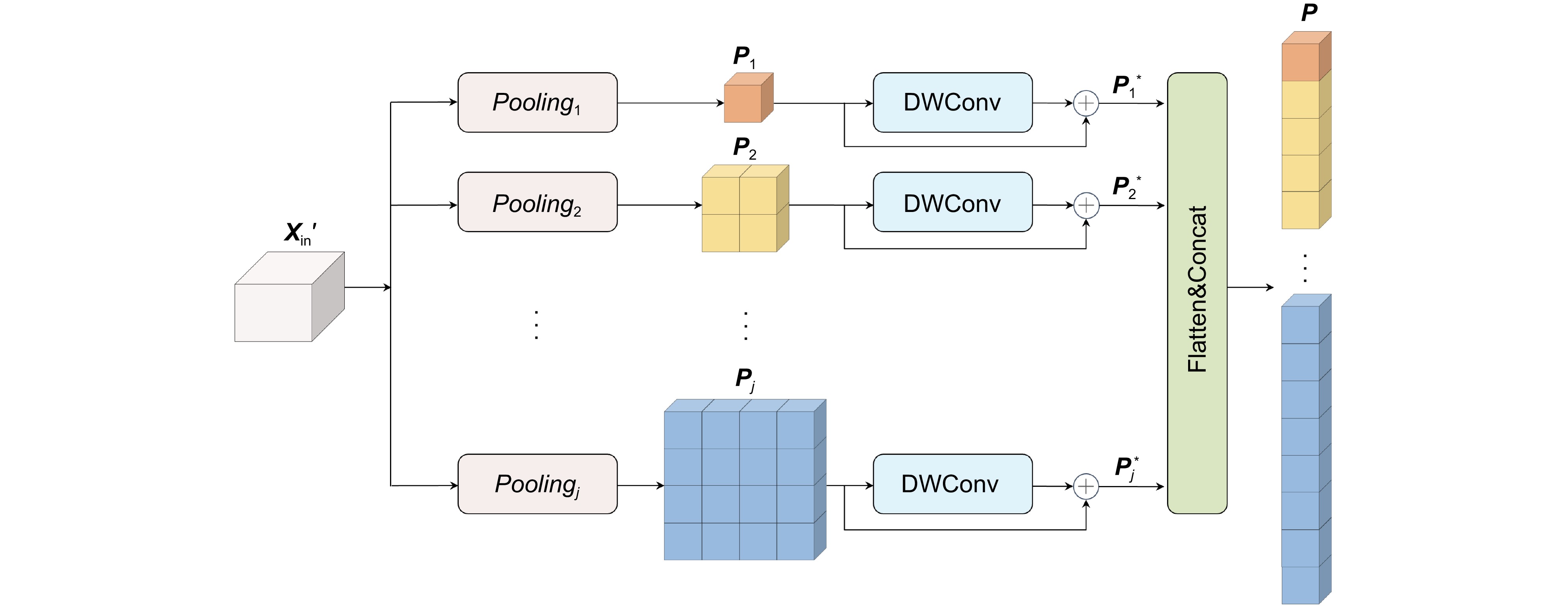
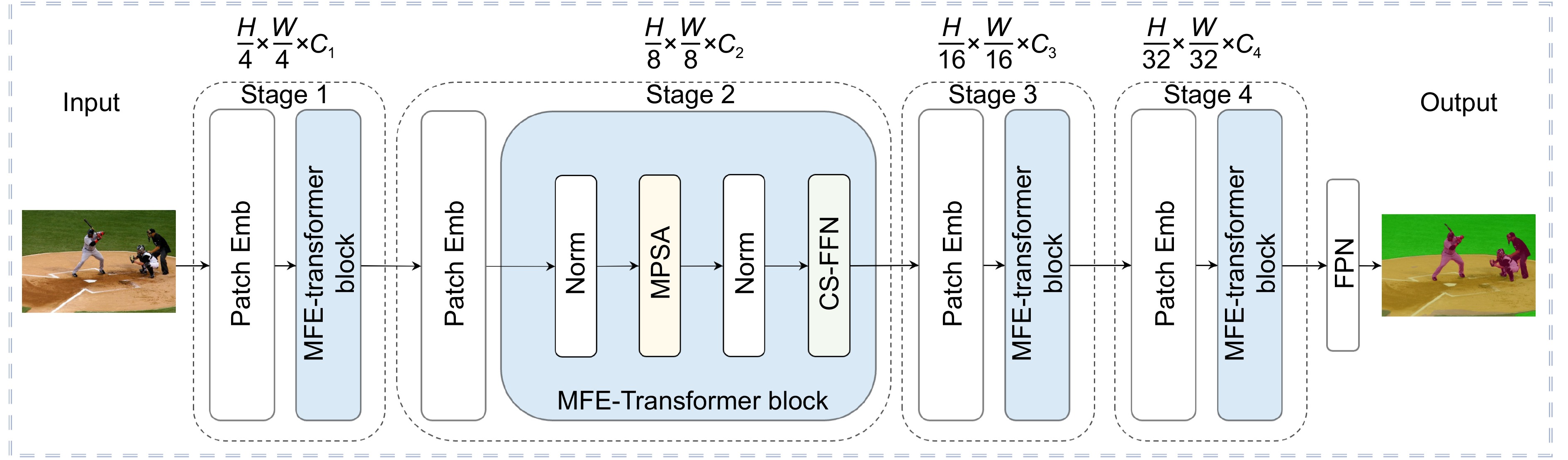
图 1 基于多尺度特征增强的高效Transformer语义分割网络。(a)多尺度池化自注意力模块;(b)跨空间前馈网络模块
Figure 1. An efficient Transformer-based semantic segmentation network enhanced by multi-scale features. (a) Multi-scale pooling self-attention module; (b) Cross-spatial feed-forward network module

图 4 不同算法在ADE20K数据集上分割结果可视化
Figure 4. Visualization of segmentation results of different algorithms on the ADE20K dataset
表 1 MFE-Former的详细设置,输出大小代表每个阶段输出的图片分辨率,操作代表第i阶段所使用的操作。此外,参数设置包括每个MFE-Transformer块使用通道缩减率r和池化因子
$ {p_l} $ Table 1. Detailed settings of the MFE-Former, output size refers to the resolution of the output at each stage, and operation represents the operations used in the i stage. Additionally, the parameter settings include the channel reduction ratio r and the pooling factor
$ p_l $ 阶段 输出大小 操作 参数设置 1 128×128×48 Patch Embed
, MFE-Transformer block×2r=1, {p1=8, p2=16, p3=24, p4=32, p5=40} 2 64×64×96 Patch Embed, MFE-Transformer block×2 r=2, {p1=4, p2=8, p3=12, p4=16, p5=20} 3 32×32×260 Patch Embed,
MFE-Transformer block×6r=4, {p1=2, p2=4, p3=6, p4=8, p5=10} 4 16×16×384 Patch Embed,
MFE-Transformer block×3r=8, {p1=1, p2=2, p3=3, p4=4, p5=5}  下载: 导出CSV
下载: 导出CSV
表 2 不同分割模型在ADE20K数据集上的模型评估结果
Table 2. Model evaluation results of different segmentation models on ADE20K dataset
Method #Param/M FLOPs/G mIoU/% FCN[19] 9.8 39.6 19.7 ResNet18[11] 15.5 32.2 32.9 PSPNet[9] 13.7 52.2 29.6 DeepLabV3+[6] 15.4 25.9 38.1 ViT[13] 10.2 24.6 37.4 PVT-Tiny[17] 17.0 33.2 35.7 PoolFormer-S12[42] 15.7 — 37.2 Conv-PVT-Tiny[43] 16.4 — 37.2 EdgeViT-XS[44] 10.3 27.7 41.4 Swin-tiny [14] 31.9 46.0 41.5 PVT-Large[17] 65.1 79.6 42.1 Segformer-B1[29] 13.7 15.9 42.2 PoolFormer-M48[42] 77.1 — 42.7 Twins-SVT-S[45] 28.3 37.0 43.2 Xcit-T12/16[46] 33.7 — 43.5 TBFormer-T[47] 20.5 24.3 42.8 SCTNet-B[48] 17.4 — 43.0 MFE-Former (Ours) 15.9 31.1 44.1
下载: 导出CSV
表 3 在Cityscapes数据集上的模型评估结果(FLOPs的测试在1024×2048分辨率下进行)
Table 3. The model evaluation results on the Cityscapes dataset (the FLOPs test was performed at a resolution of 1024×2048)
Method #Param/M FLOPs/G mIoU/% FCN[19] 9.8 317 61.5 PSPNet[9] 13.7 423 70.2 DeepLabV3+[6] 15.4 555 75.2 SwiftNetRN[49] 11.8 104 75.5 EncNet[50] 55.1 1748 76.9 PVT-Tiny[17] 17.0 — 71.7 MLT[51] 20.1 — 77.4 RTFormer-Bas[52] 16.8 — 79.3 SFNet(ResNet-18)[53] 12.87 247.0 78.9 DDRNet-39[54] 32.3 281.2 80.4 PIDNet-L[55] 36.9 275.8 80.6 MFE-Former (Ours) 15.9 238.6 80.6
下载: 导出CSV
表 4 与COCO-stuff数据集上先进的模型进行比较(采用512×512输入分辨率的进行测试)
Table 4. Compare with the state-of-the-art models on the COCO stuff dataset (testing was conducted using an input resolution of 512×512)
下载: 导出CSV
表 5 三种模型在ADE20K、Cityscapes和COCO-stuff数据集上的分割性能指标
Table 5. The segmentation performance metrics of 3 models on the ADE20K, Cityscapes, and COCO-stuff datasets
Method ADE20K Cityscapes COCO-stuff mIoU/% aAcc/% mAcc/% mDice/% mIoU/% aAcc/% mAcc/% mDice/% mIoU/% aAcc/% mAcc/% mDice/% Segformer-B1 42.1 79.6 52.7 56.3 78.5 95.8 83.4 85.4 — — — — SCTNet-B 43.0 80.2 56.1 57.2 80.1 96.4 86.6 88.3 35.9 67.1 48.5 47.9 MFE-Former(Ours) 44.1 81.0 56.1 57.4 80.6 96.5 87.7 87.5 38.0 69.1 49.1 48.1
下载: 导出CSV
表 6 不同池化方法的消融实验
Table 6. Experiment results on ablation using different pooling methods
池化方法 FLOPs/G mIoU/% 最大池化 30.7 40.8 多尺度最大池化 31.1 43.1 平均池化 30.7 42.5 多尺度平均池化 31.1 44.1
下载: 导出CSV
表 7 池化因子参数设置的消融实验和ADE20K数据集的参数设置实验结果
Table 7. Experiment results on ablation with multi-scale pooling ratio parameter settings and experimental results of parameter setting for ADE20K dataset
池化因子$ {p_l} $ R FLOPs/G mIoU/% 4 — — — — 16 31.5 42.3 8 — — — — 64 30.9 42.5 16 — — — — 256 30.6 41.9 24 — — — — 576 30.5 41.3 32 — — — — 1024 30.5 40.9 40 — — — — 1600 30.5 40.4 8 16 24 — — 47 31.1 43.7 8 16 24 32 40 43 31.1 44.1
下载: 导出CSV
表 8 在ADE20K数据集上对跨空间注意力的不同组成部分进行的消融实验
Table 8. An ablation experiment was conducted on different components of cross spatial attention on the ADE20K dataset
Setting #Param/M FLOPs/G mIoU/% 不添加跨空间注意力 15.8 30.3 43.1 仅添加通道交互分支 15.8 30.3 43.3 添加跨空间注意力 15.9 31.1 44.1
下载: 导出CSV
表 9 在ADE20K数据集上对CSA模块中的超参数N的参数设置进行的消融实验
Table 9. Ablation study on the hyperparameter N in the CSA module on the ADE20K dataset
N #Param/M FLOPs/G mIoU/% 4 16.3 31.8 43.9 8 15.9 31.1 44.1 16 15.8 30.8 43.3
下载: 导出CSV
-
参考文献
[1] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial networks[J]. Commun ACM, 2020, 63(11): 139−144. doi: 10.1145/3422622
[2] Kingma D P. Auto-encoding variational Bayes[Z]. arXiv: 1312.6114, 2013. https://doi.org/abs/1312.6114.
[3] 姜文涛, 董睿, 张晟翀. 局部注意力引导下的全局池化残差分类网络[J]. 光电工程, 2024, 51(7): 240126. doi: 10.12086/oee.2024.240126
Jiang W T, Dong R, Zhang S C. Global pooling residual classification network guided by local attention[J]. Opto-Electron Eng, 2024, 51(7): 240126. doi: 10.12086/oee.2024.240126
[4] 贺锋涛, 吴倩倩, 杨祎, 等. 基于深度学习的激光散斑图像识别技术研究[J]. 激光技术, 2024, 48(3): 443−448. doi: 10.7510/jgjs.issn.1001-3806.2024.03.022
He F T, Wu Q Q, Yang Y, et al. Research on laser speckle image recognition technology based on transfer learning[J]. Laser Technol, 2024, 48(3): 443−448. doi: 10.7510/jgjs.issn.1001-3806.2024.03.022
[5] 张冲, 黄影平, 郭志阳, 等. 基于语义分割的实时车道线检测方法[J]. 光电工程, 2022, 49(5): 210378. doi: 10.12086/oee.2022.210378
Zhang C, Huang Y P, Guo Z Y, et al. Real-time lane detection method based on semantic segmentation[J]. Opto-Electron Eng, 2022, 49(5): 210378. doi: 10.12086/oee.2022.210378
[6] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Trans Pattern Anal Mach Intell, 2018, 40(4): 834−848. doi: 10.1109/TPAMI.2017.2699184
[7] Lin T Y, Maire M, Belongie S, et al. Microsoft coco: common objects in context[C]//Proceedings of the 13th European Conference on Computer Vision -- ECCV 2014, 2014: 740–755. https://doi.org/10.1007/978-3-319-10602-1_48.
[8] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 2980–2988. https://doi.org/10.1109/ICCV.2017.322.
[9] Zhao H S, Shi J P, Qi X J, et al. Pyramid scene parsing network[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6230–6239. https://doi.org/10.1109/CVPR.2017.660.
[10] Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[Z]. arXiv: 1412.7062, 2014. https://doi.org/abs/1412.7062.
[11] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90.
[12] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 6000–6010.
[13] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale[C]//Proceedings of ICLR 2021, 2021.
[14] Liu Z, Lin Y T, Cao Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proceedings of ICCV 2021, 2021.
[15] Strudel R, Garcia R, Laptev I, et al. Segmenter: transformer for semantic segmentation[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 7242–7252. https://doi.org/10.1109/ICCV48922.2021.00717.
[16] Zheng S X, Lu J C, Zhao H S, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 6877–6886. https://doi.org/10.1109/CVPR46437.2021.00681.
[17] Wang W H, Xie E Z, Li X, et al. Pyramid vision transformer: a versatile backbone for dense prediction without convolutions[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 548–558. https://doi.org/10.1109/ICCV48922.2021.00061.
[18] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936–944. https://doi.org/10.1109/CVPR.2017.106.
[19] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3431–3440.
[20] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[21] Wang Q L, Wu B G, Zhu P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155.
[22] Wang X L, Girshick R, Gupta A, et al. Non-local neural networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7794–7803. https://doi.org/10.1109/CVPR.2018.00813.
[23] Fu J, Liu J, Tian H J, et al. Dual attention network for scene segmentation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 3141–3149. https://doi.org/10.1109/CVPR.2019.00326.
[24] Zhao H S, Qi X J, Shen X Y, et al. ICNet for real-time semantic segmentation on high-resolution images[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 418–434. https://doi.org/10.1007/978-3-030-01219-9_25.
[25] Mehta S, Rastegari M, Caspi A, et al. ESPNet: efficient spatial pyramid of dilated convolutions for semantic segmentation[C]// Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 561–580. https://doi.org/10.1007/978-3-030-01249-6_34.
[26] Ranftl R, Bochkovskiy A, Koltun V. Vision transformers for dense prediction[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 12159–12168. https://doi.org/10.1109/ICCV48922.2021.01196.
[27] Liu X Y, Peng H W, Zheng N X, et al. EfficientViT: memory efficient vision transformer with cascaded group attention[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 14420–14430. https://doi.org/10.1109/CVPR52729.2023.01386.
[28] Cheng B W, Misra I, Schwing A G, et al. Masked-attention mask transformer for universal image segmentation[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 1280–1289. https://doi.org/10.1109/CVPR52688.2022.00135.
[29] Xie E Z, Wang W H, Yu Z D, et al. SegFormer: simple and efficient design for semantic segmentation with transformers[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021: 924.
[30] Wan Q, Huang Z L, Lu J C, et al. SeaFormer: squeeze-enhanced axial transformer for mobile semantic segmentation[C]//Proceedings of ICLR 2023, 2023.
[31] Zhang Q L, Yang Y B. ResT: an efficient transformer for visual recognition[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021: 1185.
[32] Wu H P, Xiao B, Codella N, et al. CvT: introducing convolutions to vision transformers[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021: 22–31. https://doi.org/10.1109/ICCV48922.2021.00009.
[33] Mehta S, Rastegari M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer[Z]. arXiv: 2110.02178, 2021. https://doi.org/abs/2110.02178.
[34] Chen Y P, Dai X Y, Chen D D, et al. Mobile-Former: bridging MobileNet and transformer[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5260–5269. https://doi.org/10.1109/CVPR52688.2022.00520.
[35] Wang W H, Xie E Z, Li X, et al. Pvt v2: improved baselines with pyramid vision transformer[J]. Comp Visual Media, 2022, 8(3): 415−424. doi: 10.1007/s41095-022-0274-8
[36] Yuan L, Chen Y P, Wang T, et al. Tokens-to-token ViT: training vision transformers from scratch on ImageNet[C]// Proceedings of CVPR 2021, 2021: 558–567.
[37] Zhou B L, Zhao H, Puig X, et al. Scene parsing through ADE20K dataset[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5122–5130. https://doi.org/10.1109/CVPR.2017.544.
[38] Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 3213–3223. https://doi.org/10.1109/CVPR.2016.350.
[39] Caesar H, Uijlings J, Ferrari V. COCO-stuff: thing and stuff classes in context[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 1209–1218. https://doi.org/10.1109/CVPR.2018.00132.
[40] Contributors M M S. MMSegmentation: openmmlab semantic segmentation toolbox and benchmark[EB/OL]. (2020). https://github.com/open-mmlab/mmsegmentation.
[41] Loshchilov I, Hutter F. Decoupled weight decay regularization[C]//Proceedings of ICLR 2019, 2019.
[42] Yu W H, Luo M, Zhou P, et al. MetaFormer is actually what you need for vision[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 10809–10819. https://doi.org/10.1109/CVPR52688.2022.01055.
[43] Zhang X, Zhang Y. Conv-PVT: a fusion architecture of convolution and pyramid vision transformer[J]. Int J Mach Learn Cyber, 2023, 14(6): 2127−2136. doi: 10.1007/s13042-022-01750-0
[44] Pan J T, Bulat A, Tan F W, et al. EdgeViTs: competing light-weight CNNs on mobile devices with vision transformers[C]//Proceedings of the 17th European Conference on Computer Vision, 2022: 294–311. https://doi.org/10.1007/978-3-031-20083-0_18.
[45] Chu X X, Tian Z, Wang Y Q, et al. Twins: revisiting the design of spatial attention in vision transformers[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021: 716.
[46] El-Nouby A, Touvron H, Caron M, et al. XCiT: cross-covariance image transformers[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021: 1531.
[47] Wei C, Wei Y. TBFormer: three-branch efficient transformer for semantic segmentation[J]. Signal, Image Video Process, 2024, 18(4): 3661−3672. doi: 10.1007/S11760-024-03030-6
[48] Xu Z Z, Wu D Y, Yu C Q, et al. SCTNet: single-branch CNN with transformer semantic information for real-time segmentation[C]//Proceedings of the 38th AAAI Conference on Artificial Intelligence, 2024: 6378–6386. https://doi.org/10.1609/aaai.v38i6.28457.
[49] Oršic M, Krešo I, Bevandic P, et al. In defense of pre-trained ImageNet architectures for real-time semantic segmentation of road-driving images[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 12599–12608. https://doi.org/10.1109/CVPR.2019.01289.
[50] Zhang H, Dana K, Shi J P, et al. Context encoding for semantic segmentation[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7151–7160. https://doi.org/10.1109/CVPR.2018.00747.
[51] Zhou Q, Sun Z H, Wang L J, et al. Mixture lightweight transformer for scene understanding[J]. Computers and Electrical Engineering, 2023, 108: 108698. doi: 10.1016/j.compeleceng.2023.108698
[52] Wang J, Gou C H, Wu Q M, et al. RTFormer: efficient design for real-time semantic segmentation with transformer[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems, 2022: 539.
[53] Li X T, You A S, Zhu Z, et al. Semantic flow for fast and accurate scene parsing[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 775–793. https://doi.org/10.1007/978-3-030-58452-8_45.
[54] Pan H H, Hong Y D, Sun W C, et al. Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes[J]. IEEE Trans Intell Transp Syst, 2023, 24(3): 3448−3460. doi: 10.1109/TITS.2022.3228042
[55] Xu J C, Xiong Z X, Bhattacharyya S P. PIDNet: a real-time semantic segmentation network inspired by PID controllers[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 19529–19539. https://doi.org/10.1109/CVPR52729.2023.01871.
[56] Howard A, Sandler M, Chen B, et al. Searching for MobileNetV3[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 1314–1324. https://doi.org/10.1109/ICCV.2019.00140.
[57] Cheng B W, Schwing A G, Kirillov A. Per-pixel classification is not all you need for semantic segmentation[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021: 1367.
-
访问统计

 点击扫一扫
点击扫一扫
图(5)
表(9)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


