
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
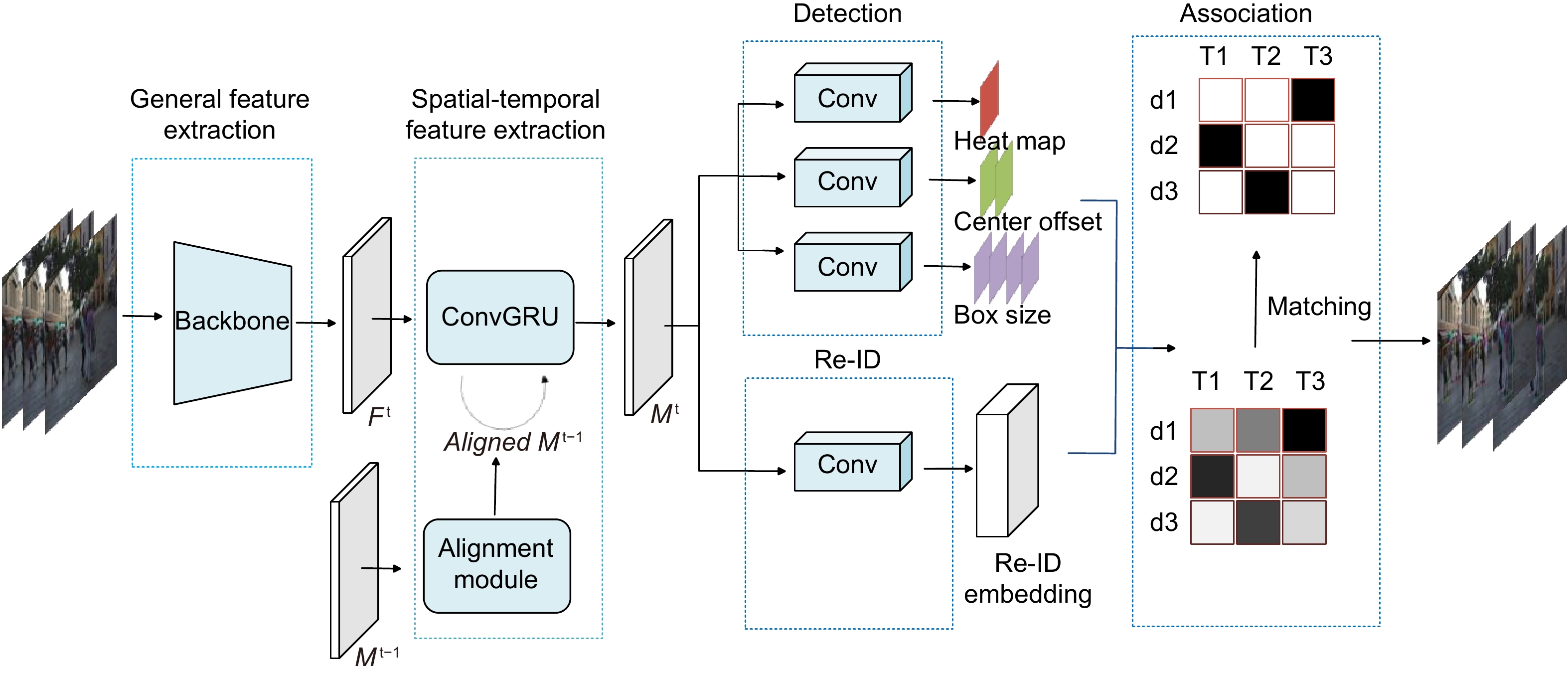
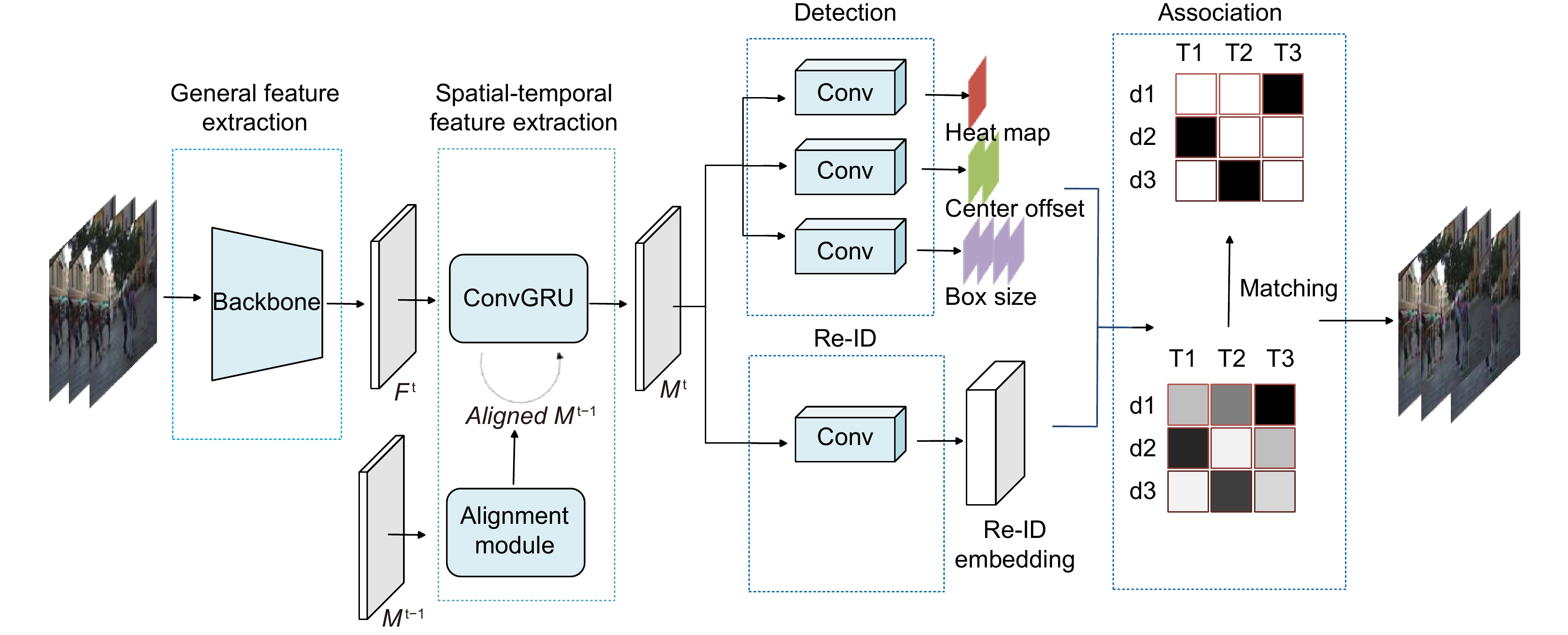
多目标跟踪 (Multi-object tracking, MOT)是计算机视觉领域的一项重要任务,现有研究大多针对目标检测和数据关联进行改进,通常忽视了不同帧之间的相关性,未能充分利用视频时序信息,导致算法在运动模糊,遮挡和小目标场景中的性能显著下降。为解决上述问题,本文提出了一种时空特征对齐的多目标跟踪方法。首先,引入卷积门控递归单元(convolutional gated recurrent unit, ConvGRU),对视频中目标的时空信息进行编码;该结构通过考虑整个历史帧序列,有效提取时序信息,以增强特征表示。然后,设计特征对齐模块,保证历史帧信息和当前帧信息的时间一致性,以降低误检率。最后,本文在MOT17和MOT20数据集上进行了测试,所提算法的MOTA (multiple object tracking accurary)值分别为74.2和67.4,相比基准方法FairMOT提升了0.5和5.6;IDF1 (identification F1 score)值分别为73.9和70.6,相比基准方法FairMOT提升了1.6和3.3。此外,定性和定量实验结果表明,本文方法的综合跟踪性能优于目前大多数先进方法。
Abstract
Multiple object tracking (MOT) is an important task in computer vision. Most of the MOT methods improve object detection and data association, usually ignoring the correlation between different frames. They don’t make good use of the temporal information in the video, which makes the tracking performance significantly degraded in motion blur, occlusion, and small target scenes. In order to solve these problems, this paper proposes a multiple object tracking method with the aligned spatial-temporal feature. First, the convolutional gated recurrent unit (ConvGRU) is introduced to encode the spatial-temporal information of the object in the video; By considering the whole history frame sequence, this structure effectively extracts the spatial-temporal information to enhance the feature representation. Then, the feature alignment module is designed to ensure the time consistency between the historical frame information and the current frame information to reduce the false detection rate. Finally, this paper tests on MOT17 and MOT20 datasets, and multiple object tracking accuracy (MOTA) values are 74.2 and 67.4, respectively, which is increased by 0.5 and 5.6 compared with the baseline FairMOT method. Our identification F1 score (IDF1) values are 73.9 and 70.6, respectively, which are increased by 1.6 and 3.3 compared with the baseline FairMOT method. In addition, the qualitative and quantitative experimental results show that the overall tracking performance of this method is better than that of most of the current advanced methods.
-
Key words:
- multiple object tracking /
- spatial-temporal feature /
- ConvGRU /
- time consistency /
- feature alignment
-
Overview
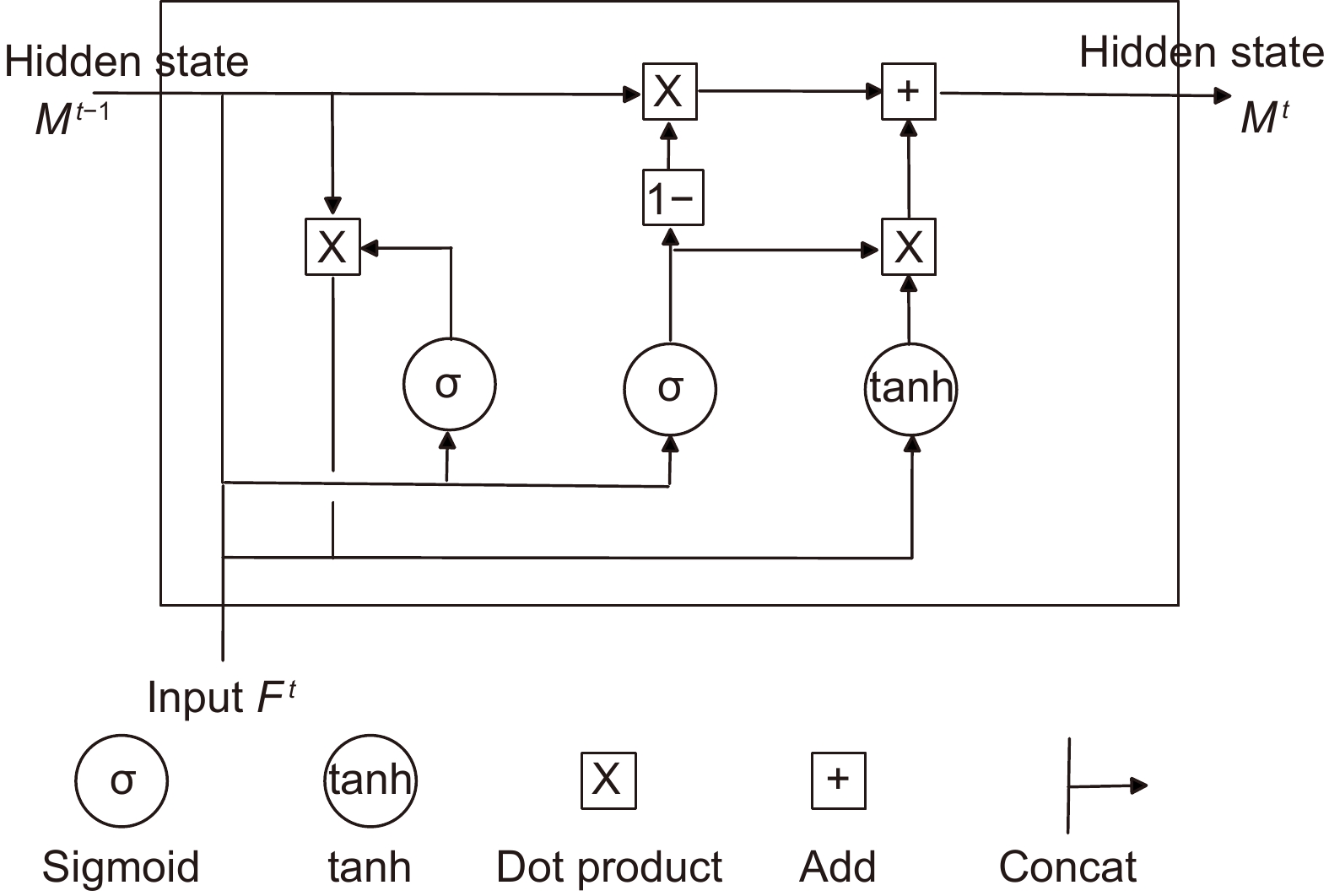
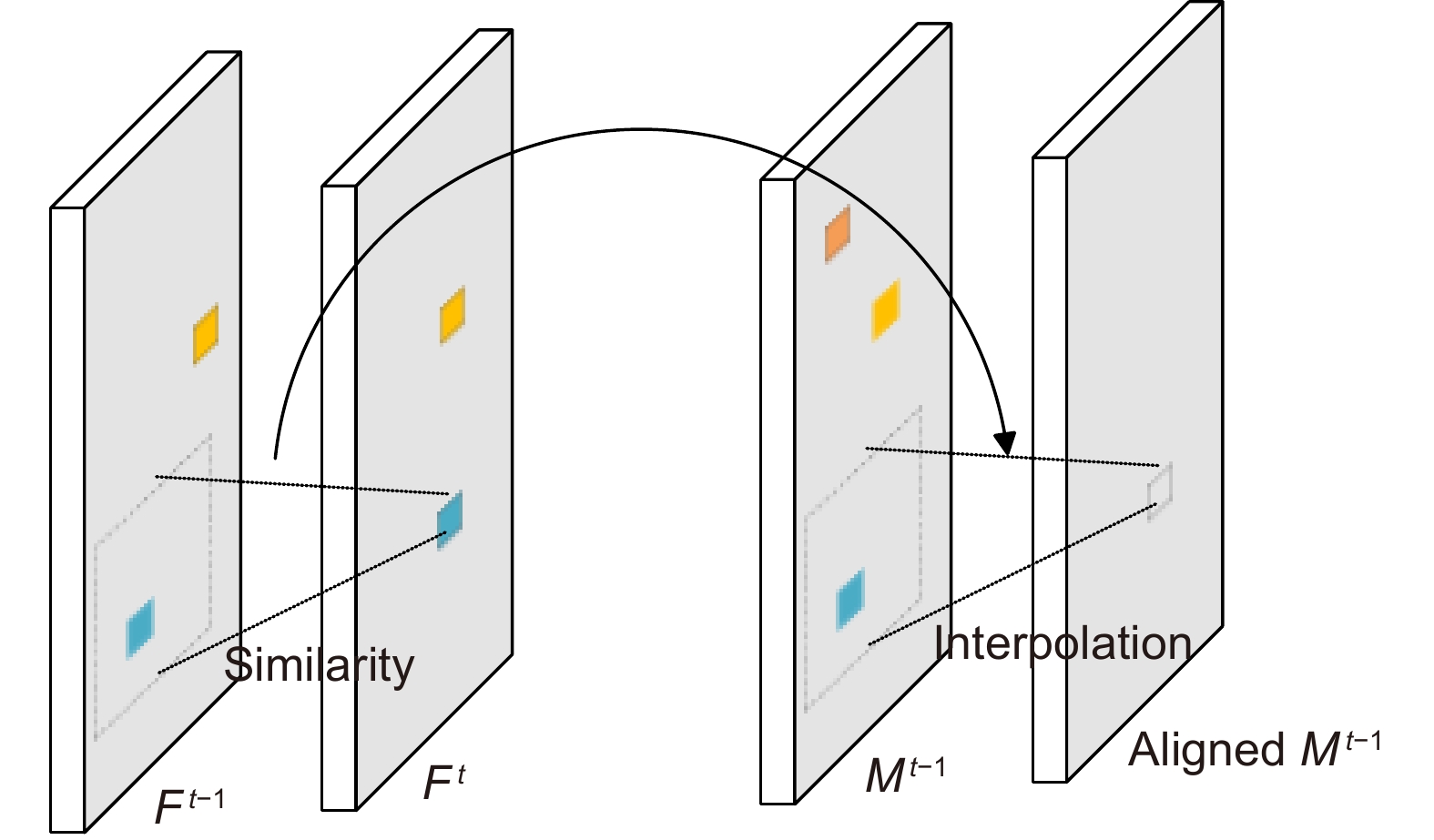
Overview: Multiple object tracking (MOT) is an important task in computer vision. It is widely used in the fields of surveillance video analysis and automatic driving. MOT is to locate multiple objects of interest, maintain the unique identification number (ID) of each object, and record continuous tracks. The difficulty of multi-target tracking is false positives (FP), false negatives (FN), ID switches (IDs), and the uncertainty of the target number. Most of the MOT methods improve object detection and data association, usually ignoring the correlation between different frames. Although some methods have tried to construct the correlation between different frames in recent years, they only stay in the adjacent frames and do not explicitly model the temporal information in the video. They don’t make good use of the temporal information in the video, which makes the tracking performance significantly degraded in motion blur, occlusion, and small target scenes. In order to solve these problems, this paper proposes a multiple object tracking method with the aligned spatial-temporal feature. First, the convolutional gated recurrent unit (ConvGRU) is introduced to encode the spatial-temporal information of the object in the video; By considering the whole history frame sequence, this structure effectively extracts the spatial-temporal information to enhance the feature representation. However, the target in the video is moving, and the spatial position of the target in the current frame is different from that in the previous frame, and ConvGRU is difficult to forget the spatial position of the target in the historical frame, thus overlaying the misaligned features, resulting in the spatial position of the target in the historical frame on the feature map has a high response, which makes the detector think that the target is still in the spatial position of the previous frame. Then, the feature alignment module is designed to ensure the time consistency between the historical frame information and the current frame information to reduce the false detection rate. Finally, this paper tests MOT17 and MOT20 datasets, and the multiple object tracking accuracy (MOTA) values are 74.2 and 67.4, respectively, which are increased by 0.5 and 5.6 compared with the baseline FairMOT method. Our identification F1 score (IDF1) value is 73.9 and 70.6, respectively, which is increased by 1.6 and 3.3 compared with the baseline FairMOT method. In addition, the qualitative and quantitative experimental results show that the overall tracking performance of this method is better than that of most of the current advanced methods.
-

-

图 4 本文方法与基准方法在验证集上的可视化结果对比。(a) ID切换;(b) 误检和漏检;(c) 特定的误检
Figure 4. The visualization results comparison between baseline and our method on validation set. (a) ID switch; (b) FP and FN; (c) special FP

图 5 本文方法在KITTI测试集上的可视化结果。图片左侧为视频号。图片左上角为帧号
Figure 5. Visualization results of this method on the KITTI test set. The video number is in the left side of the figure. The frame number is in the upper left of the figure
表 1 本文方法与其他先进方法在MOT17数据集上的对比结果
Table 1. The tracking performance comparision between our method and other advanced methods on MOT17 data set
Method Year MOTA↑ IDF1↑ HOTA↑ FP↓ FN↓ MT↑ ML↓ IDS↓ FPS↑ TubeTK[39] CVPR2020 63.0 58.6 48.0 27060 177483 31.2 19.9 5529 3.0 CTracker[26] ECCV2020 66.6 57.4 49.0 22284 160491 32.2 24.2 5529 6.8 CenterTrack[12] ECCV2020 67.8 64.7 52.2 18489 160332 34.6 24.6 3309 22.0 TraDes[40] CVPR2021 69.1 63.9 52.7 20892 150060 36.4 21.5 3555 3.4 FairMOT[10] IJCV2021 73.7 72.3 59.3 27507 117477 43.2 17.3 3303 18.9 TrackFormer[15] CVPR2022 65.0 63.9 - 70443 123552 - - 3528 - MOTR[16] ECCV2022 67.4 67.0 - 32355 149400 34.6 24.5 1992 - CSTrack[20] TIP2022 74.9 72.3 - 23847 114303 41.5 17.5 3567 16.4 Ours 74.2 73.9 60.1 27129 116337 43.8 19.1 2367 10.9  下载: 导出CSV
下载: 导出CSV
表 2 本文方法与其他先进方法在MOT20数据集上的对比结果
Table 2. The tracking performance comparision between our method and other advanced methods on MOT20 data set
Method Year MOTA↑ IDF1↑ HOTA↑ FP↓ FN↓ MT↑ ML↓ IDS↓ FPS↑ FairMOT[10] IJCV2021 61.8 67.3 54.6 103440 88901 68.8 7.6 5243 8.9 TransTrack[14] arXiv2021 64.5 59.2 - 28566 151377 49.1 13.6 3565 - CorrTracker[22] CVPR2021 65.2 73.6 - 29808 99510 47.6 12.7 3369 - CSTrack[20] TIP2022 66.6 68.6 54.0 25404 144358 50.4 15.5 3196 4.5 Ours 67.4 70.6 55.6 49358 117370 59.6 12.3 2066 4.8
下载: 导出CSV
表 3 不同模块对跟踪性能的影响
Table 3. The impact of different components on the overall tracking performance
Method MOTA↑ IDF1↑ FP↓ FN↓ MT↑ ML↓ IDS↓ Baseline 69.1 72.8 1976 14443 143 53 299 Baseline+ConvGRU 69.6 73.4 2434 13729 150 50 321 Baseline+ConvGRU+Alignment Module 70.0 74.8 2201 13715 153 51 320
下载: 导出CSV
表 4 视频序列输入长度对跟踪性能的影响
Table 4. The impact of video sequence input length on the overall tracking performance
Input length MOTA↑ IDF1↑ FP↓ FN↓ MT↑ ML↓ IDS↓ 2 68.9 73.5 2412 14092 143 52 311 3 69.6 74.1 2108 13990 144 51 319 4 69.6 73.9 2156 13949 152 52 293 5 69.5 74.1 2221 13947 151 52 313 8 70.0 74.8 2201 13715 153 51 320
下载: 导出CSV
表 5 本文方法与其他先进方法在KITTI车辆类测试集上的对比结果
Table 5. The tracking performance comparision between our method and other advanced methods on KITTI vehicle class test set
下载: 导出CSV
-
参考文献
[1] Ciaparrone G, Sánchez F L, Tabik S, et al. Deep learning in video multi-object tracking: a survey[J]. Neurocomputing, 2020, 381: 61−88. doi: 10.1016/j.neucom.2019.11.023
[2] Bewley A, Ge Z Y, Ott L, et al. Simple online and realtime tracking[C]//2016 IEEE International Conference on Image Processing (ICIP), 2016: 3464–3468. https://doi.org/10.1109/ICIP.2016.7533003.
[3] Wojke N, Bewley A, Paulus D. Simple online and realtime tracking with a deep association metric[C]//2017 IEEE International Conference on Image Processing, 2018: 3645–3649. https://doi.org/10.1109/ICIP.2017.8296962.
[4] 鄂贵, 王永雄. 基于R-FCN框架的多候选关联在线多目标跟踪[J]. 光电工程, 2020, 47(1): 190136. doi: 10.12086/oee.2020.190136
E G, Wang Y X. Multi-candidate association online multi-target tracking based on R-FCN framework[J]. Opto-Electron Eng, 2020, 47(1): 190136. doi: 10.12086/oee.2020.190136
[5] Berclaz J, Fleuret F, Fua P. Robust people tracking with global trajectory optimization[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06), 2006: 744–750. https://doi.org/10.1109/CVPR.2006.258.
[6] Pirsiavash H, Ramanan D, Fowlkes C C. Globally-optimal greedy algorithms for tracking a variable number of objects[C]//CVPR 2011, 2011: 1201–1208. https://doi.org/10.1109/CVPR.2011.5995604.
[7] Brasó G, Leal-Taixé L. Learning a neural solver for multiple object tracking[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 6246–6256. https://doi.org/10.1109/CVPR42600.2020.00628.
[8] Xu J R, Cao Y, Zhang Z, et al. Spatial-temporal relation networks for multi-object tracking[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, 2019: 3987–3997. https://doi.org/10.1109/ICCV.2019.00409.
[9] Wang Z D, Zheng L, Liu Y X, et al. Towards real-time multi-object tracking[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 107–122. https://doi.org/10.1007/978-3-030-58621-8_7.
[10] Zhang Y F, Wang C Y, Wang X G, et al. FairMOT: On the fairness of detection and re-identification in multiple object tracking[J]. Int J Comput Vision, 2021, 129(11): 3069−3087. doi: 10.1007/s11263-021-01513-4
[11] Bergmann P, Meinhardt T, Leal-Taixé L. Tracking without bells and whistles[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, 2019: 941–951. https://doi.org/10.1109/ICCV.2019.00103.
[12] Zhou X Y, Koltun V, Krähenbühl P. Tracking objects as points[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 474–490. https://doi.org/10.1007/978-3-030-58548-8_28.
[13] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 213–229. https://doi.org/10.1007/978-3-030-58452-8_13.
[14] Sun P Z, Cao J K, Jiang Y, et al. Transtrack: Multiple object tracking with transformer[Z]. arXiv: 2012.15460, 2020. https://arxiv.org/abs/2012.15460.
[15] Meinhardt T, Kirillov A, Leal-Taixé L, et al. TrackFormer: Multi-object tracking with transformers[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 8834–8844. https://doi.org/10.1109/CVPR52688.2022.00864.
[16] Zeng F G, Dong B, Zhang Y A, et al. MOTR: End-to-end multiple-object tracking with transformer[C]//Proceedings of the 17th European Conference on Computer Vision, 2022: 659–675. https://doi.org/10.1007/978-3-031-19812-0_38.
[17] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 6000–6010.
[18] Ballas N, Yao L, Pal C, et al. Delving deeper into convolutional networks for learning video representations[C]//Proceedings of the 4th International Conference on Learning Representations, 2015.
[19] Yu F W, Li W B, Li Q Q, et al. POI: Multiple object tracking with high performance detection and appearance feature[C]//Proceedings of the European Conference on Computer Vision, 2016: 36–42. https://doi.org/10.1007/978-3-319-48881-3_3.
[20] Liang C, Zhang Z P, Zhou X, et al. Rethinking the competition between detection and ReID in multiobject tracking[J]. IEEE Trans Image Process, 2022, 31: 3182−3196. doi: 10.1109/TIP.2022.3165376
[21] Yu E, Li Z L, Han S D, et al. RelationTrack: Relation-aware multiple object tracking with decoupled representation[J]. IEEE Trans Multimedia, 2022. https://doi.org/10.1109/TMM.2022.3150169.
[22] Wang Q, Zheng Y, Pan P, et al. Multiple object tracking with correlation learning[C]//Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 3875–3885. https://doi.org/10.1109/CVPR46437.2021.00387.
[23] Tokmakov P, Li J, Burgard W, et al. Learning to track with object permanence[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, 2021: 10840–10849. https://doi.org/10.1109/ICCV48922.2021.01068
[24] Welch G, Bishop G. An Introduction to the Kalman Filter[M]. Chapel Hill: University of North Carolina at Chapel Hill, 1995.
[25] Kuhn H W. The Hungarian method for the assignment problem[J]. Naval Res Logist Q, 1955, 2(1–2): 83–97.https://doi.org/10.1002/nav.3800020109.
[26] Peng J L, Wang C A, Wan F B, et al. Chained-tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 145–161. https://doi.org/10.1007/978-3-030-58548-8_9.
[27] Zheng L, Bie Z, Sun Y F, et al. MARS: A video benchmark for large-scale person re-identification[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 868–884. https://doi.org/10.1007/978-3-319-46466-4_52.
[28] McLaughlin N, Del Rincon J M, Miller P. Recurrent convolutional network for video-based person re-identification[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1325–1334. https://doi.org/10.1109/CVPR.2016.148.
[29] Zhou Z, Huang Y, Wang W, et al. See the forest for the trees: Joint spatial and temporal recurrent neural networks for video-based person re-identification[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6776–6785. https://doi.org/10.1109/CVPR.2017.717.
[30] Fu Y, Wang X Y, Wei Y C, et al. STA: Spatial-temporal attention for large-scale video-based person re-identification[C]//Proceedings of the 33rd AAAI Conference on Artificial Intelligence, 2019: 8287–8294. https://doi.org/10.1609/aaai.v33i01.33018287.
[31] Li J N, Zhang S L, Huang T J. Multi-scale 3D convolution network for video based person re-identification[C]//Proceedings of the 33rd AAAI Conference on Artificial Intelligence, 2019: 8618–8625. https://doi.org/10.1609/aaai.v33i01.33018618.
[32] 王迪聪, 白晨帅, 邬开俊. 基于深度学习的视频目标检测综述[J]. 计算机科学与探索, 2021, 15(9): 1563−1577. doi: 10.3778/j.issn.1673-9418.2103107
Wang D C, Bai C S, Wu K J. Survey of video object detection based on deep learning[J]. J Front Comput Sci Technol, 2021, 15(9): 1563−1577. doi: 10.3778/j.issn.1673-9418.2103107
[33] 陆康亮, 薛俊, 陶重犇. 融合空间掩膜预测与点云投影的多目标跟踪[J]. 光电工程, 2022, 49(9): 220024. doi: 10.12086/oee.2022.220024
Lu K L, Xue J, Tao C B. Multi target tracking based on spatial mask prediction and point cloud projection[J]. Opto-Electron Eng, 2022, 49(9): 220024. doi: 10.12086/oee.2022.220024
[34] Zhu X Z, Xiong Y W, Dai J F, et al. Deep feature flow for video recognition[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 4141–4150. https://doi.org/10.1109/CVPR.2017.441.
[35] Kang K, Ouyang W L, Li H S, et al. Object detection from video tubelets with convolutional neural networks[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 817–825. https://doi.org/10.1109/CVPR.2016.95.
[36] Feichtenhofer C, Pinz A, Zisserman A. Detect to track and track to detect[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision, 2017: 3057–3065. https://doi.org/10.1109/ICCV.2017.330.
[37] Xiao F Y, Lee Y J. Video object detection with an aligned spatial-temporal memory[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 494–510. https://doi.org/10.1007/978-3-030-01237-3_30.
[38] Yu F, Wang D Q, Shelhamer E, et al. Deep layer aggregation[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 2403–2412. https://doi.org/10.1109/CVPR.2018.00255.
[39] Pang B, Li Y Z, Zhang Y F, et al. TubeTK: adopting tubes to track multi-object in a one-step training model[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 6307–6317. https://doi.org/10.1109/CVPR42600.2020.00634.
[40] Wu J J, Cao J L, Song L C, et al. Track to detect and segment: an online multi-object tracker[C]//Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 12347–12356. https://doi.org/10.1109/CVPR46437.2021.01217.
[41] Pang J M, Qiu L L, Li X, et al. Quasi-dense similarity learning for multiple object tracking[C]//Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 164–173. https://doi.org/10.1109/CVPR46437.2021.00023.
-
访问统计
 点击扫一扫
点击扫一扫
图(6)
表(5)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


