
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
针对无人机航拍视角下的道路损伤图像背景复杂、目标尺度差异大的检测难题,提出了一种融合多分支混合注意力机制的道路损伤检测方法MAS-YOLOv8n。首先,设计了一种多分支混合注意力机制,并将该结构添加到C2f结构中,加强了特征的表达能力,在捕获到更为丰富的特征信息的同时,减少噪声对检测结果的影响,以解决YOLOv8n模型中残差结构易受干扰,导致信息丢失的问题。其次,针对道路损伤形态差异大导致检测效果差的问题,利用ShapeIoU对YOLOv8n模型使用的TaskAlignedAssigner标签分配算法进行改进,使其更适用于形态多变的目标,进一步提高了检测精度。将MAS-YOLOv8n模型在无人机拍摄的道路损伤数据集China-Drone上进行实验,相较于基线模型YOLOv8n,本文模型的平均精度均值提高了3.1%,且没有额外增加计算代价。为进一步验证模型通用性,在RDD2022_Chinese和RDD2022_Japanese两个数据集上进行实验,精度均有所提升。与YOLOv5n、YOLOv8n、YOLOv10n、GOLD-YOLO、Faster-RCNN、TOOD、RTMDet-Tiny、RT-DETR相比,本文模型检测精度更高,性能更为优秀,展现了其较好的泛化能力。
Abstract
To address the detection challenges posed by the complex backgrounds and significant variations in target scales in road damage images captured from drone aerial perspectives, a road damage detection method called MAS-YOLOv8n, incorporating a multi-branch hybrid attention mechanism, is proposed. Firstly, to address the problem of the residual structure in the YOLOv8n model being prone to interference, resulting in information loss, a multi-branch mixed attention (MBMA) mechanism is introduced. This MBMA structure is integrated into the C2f structure, strengthening the feature representation capabilities. It not only captures richer feature information but also reduces the impact of noise on the detection results. Secondly, to address the issue of poor detection performance resulting from significant variations in road damage morphologies, the TaskAlignedAssigner label assignment algorithm used in the YOLOv8n model is improved by utilizing ShapeIoU (shape-intersection over union), making it more suitable for targets with diverse shapes and further enhancing detection accuracy. Experimental evaluations of the MAS-YOLOv8n model on the China-Drone dataset of road damages captured by drones reveal that compared to the baseline YOLOv8n model, our model achieves a 3.1% increase in mean average precision (mAP) without incurring additional computational costs. To further validate the model's generalizability, tests on the RDD2022_Chinese and RDD2022_Japanese datasets also demonstrate improved accuracy. Compared to YOLOv5n, YOLOv8n, YOLOv10n, GOLD-YOLO, Faster-RCNN, TOOD, RTMDet-Tiny, and RT-DETR, our model exhibits superior detection accuracy and performance, showcasing its robust generalization capabilities.
-
Key words:
- damage detection /
- YOLOv8n /
- attention mechanism /
- label allocation algorithm
-
Overview
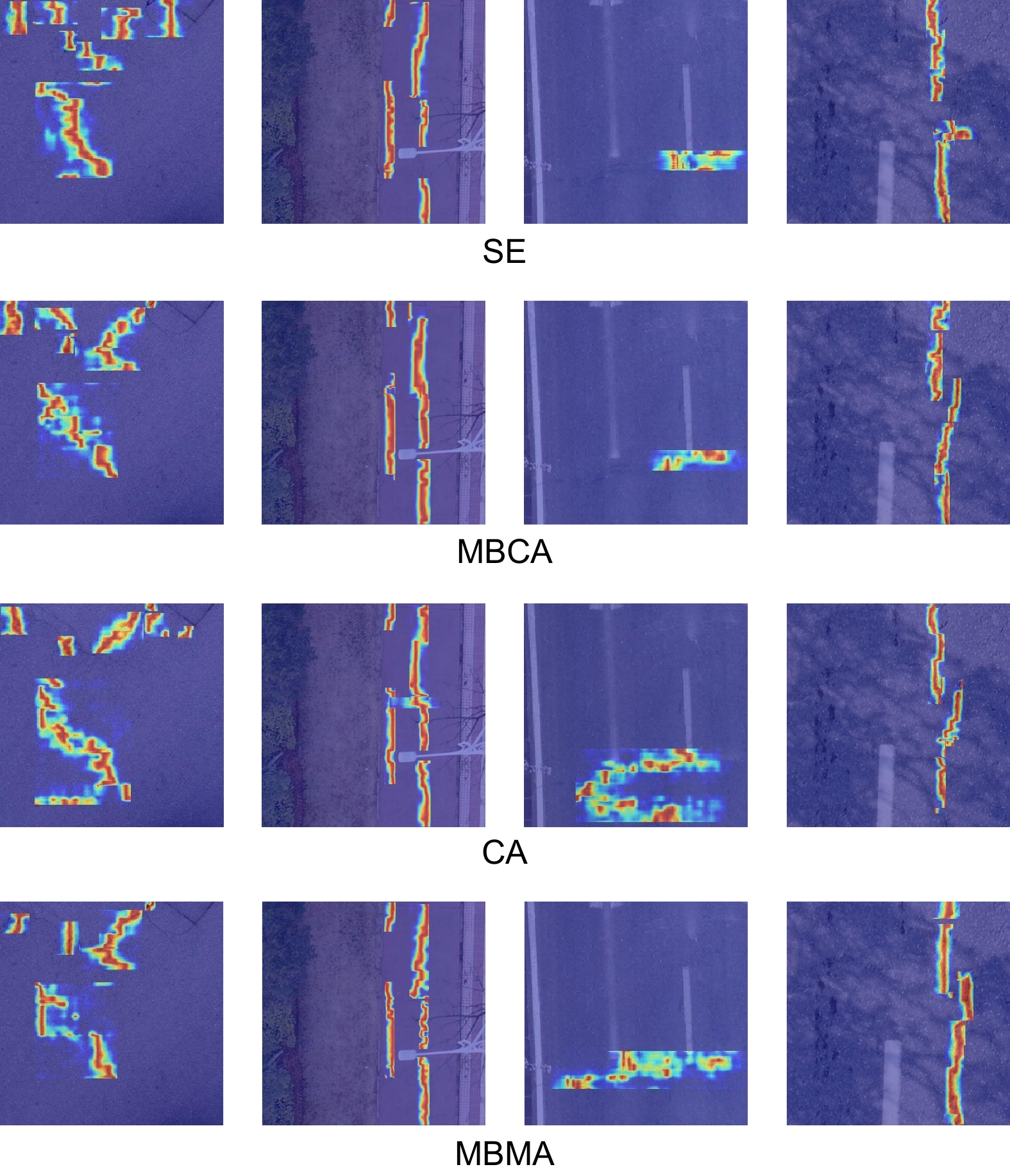
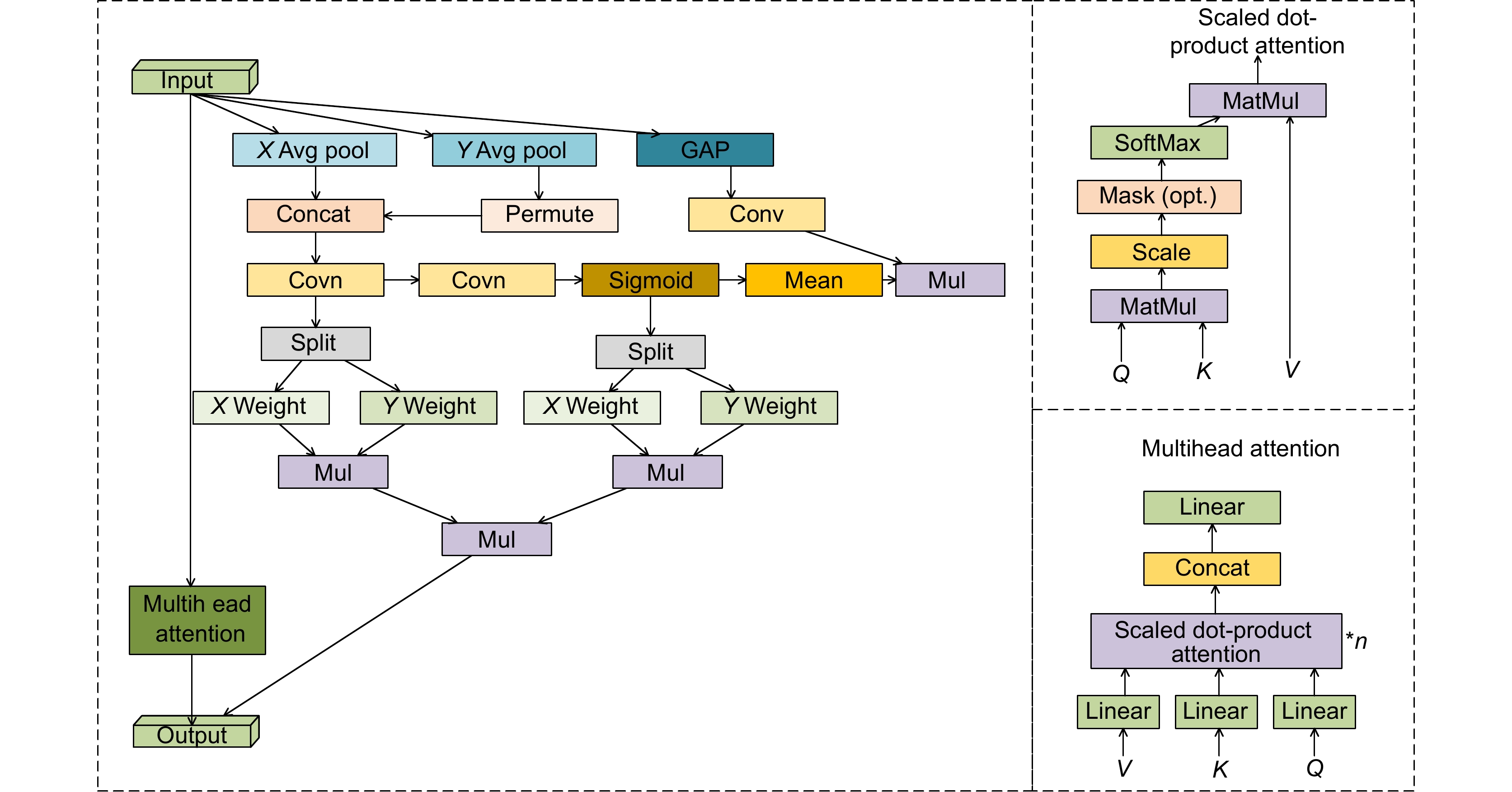
Overview: Drones, with their capabilities of rapid movement and agile flight, can scan and inspect large road areas within a short period and have now been applied to the field of road inspection. Compared to traditional manual inspections, drone-based road damage detection significantly enhances detection efficiency. From the perspective of drones, road damage images have complex backgrounds and significant differences in target scales, which makes feature extraction difficult and detection results unsatisfactory. In response to the above issues, this article has improved the YOLOv8n model and proposed a road damage detection model MAS-YOLOv8n that integrates a multi-branch hybrid attention mechanism. Among them, a multi-branch hybrid attention mechanism (MBMA module) is proposed to solve the problem of residual structures being easily affected by noise interference and loss of details. This module is used to modify the C2f structure in YOLOv8. The MBMA module processes input features through multiple branches, each focusing on different feature dimensions (height, width, and channel), enabling a more comprehensive capture of feature information. At the same time, utilizing a multi-head attention mechanism allows the model to focus on different parts of the input data through multiple independent attention heads, enabling the model to capture more diverse information in different spatial positions, channels, or feature dimensions. It can also reduce the bias and noise effects that may be caused by single-head attention, capture richer feature representations, and improve the robustness of the module. In addition, ShapeIoU is introduced to address the characteristics of large morphological differences and the high probability of small targets appearing in road damage images. ShapeIoU improves the task-aligned assistant label assignment algorithm by introducing scale factors and shape-related weights, taking into account the shape and scale of bounding boxes. This enhances the matching accuracy between predicted and real boxes in object detection, making it more suitable for targets with variable shapes and further improving the detection performance of the model. The MAS-YOLOv8n model was tested on the Chinese drone road damage dataset captured by drones. Compared with the baseline model YOLOv8n, our model has improved the average accuracy by 3.1%, with almost no additional computational cost. To further verify the generality of the model, experiments were conducted on two datasets, RDD2022_China and RDD2022_Japanese, to improve accuracy. Compared with YOLOv5n, YOLOv8n, YOLOv10n, GOLD YOLO, Faster RCNN, TOOD, RTMDet Tiny, and RT-DETR, the model proposed in this paper has higher detection accuracy and better performance, proving its good generalization ability.
-

-
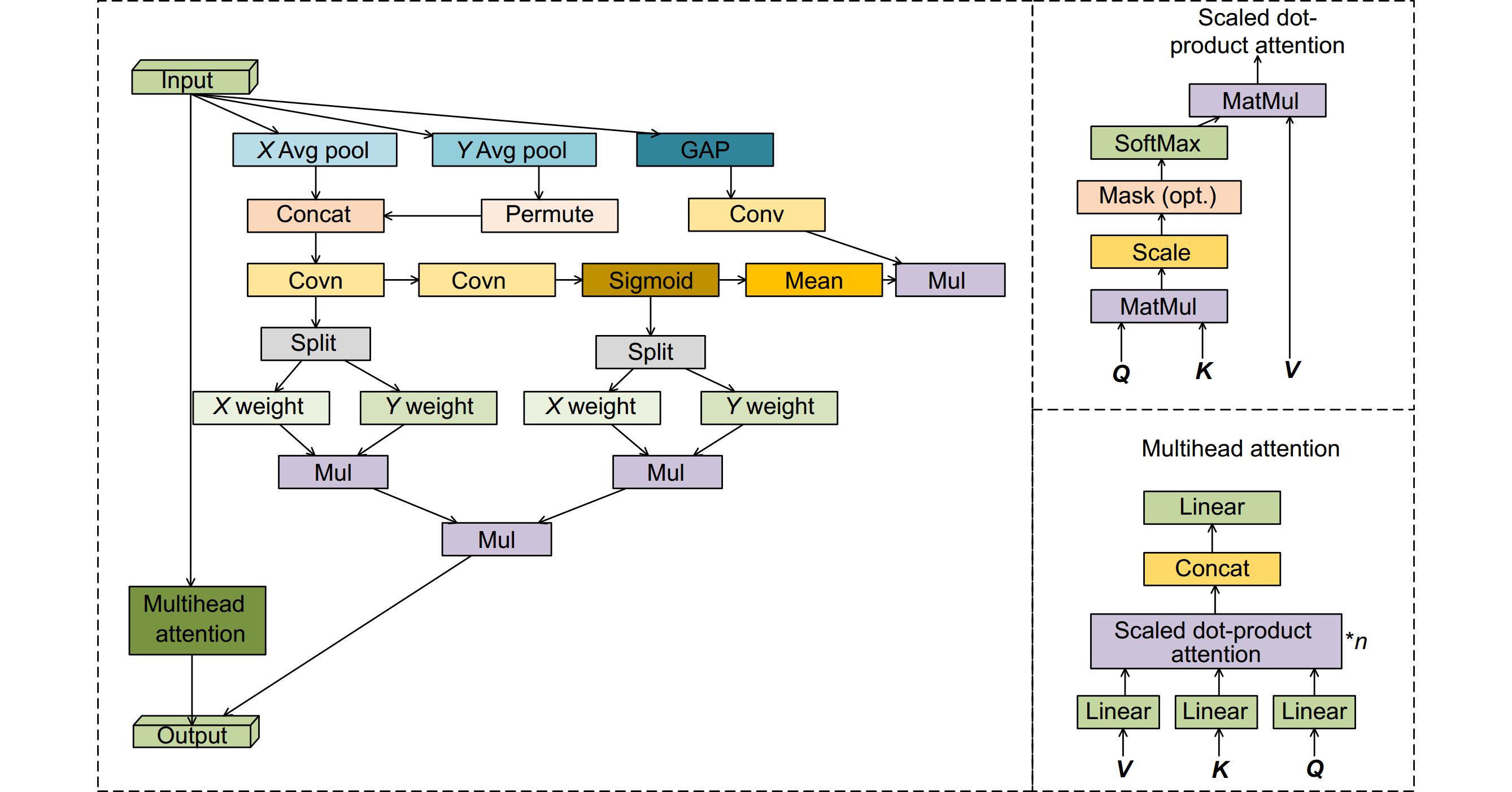
图 2 多分支混合注意力机制(MBMA模块)结构
Figure 2. Multi-branch hybrid attention mechanism (MBMA module) structure
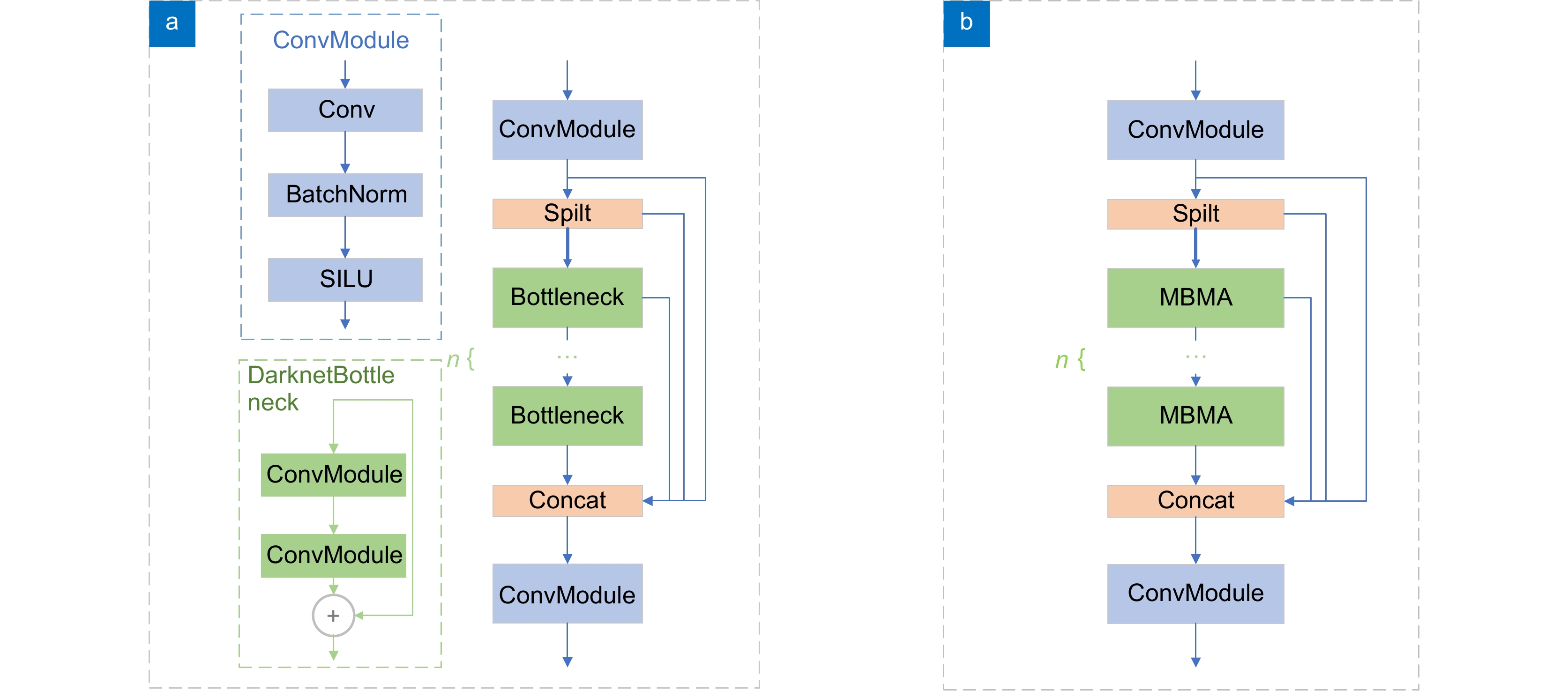
图 3 C2f结构改进。 (a)原C2f结构;(b)改进后C2f结构
Figure 3. C2f structure improvement. (a) Original C2f structure; (b) Improved C2f structure
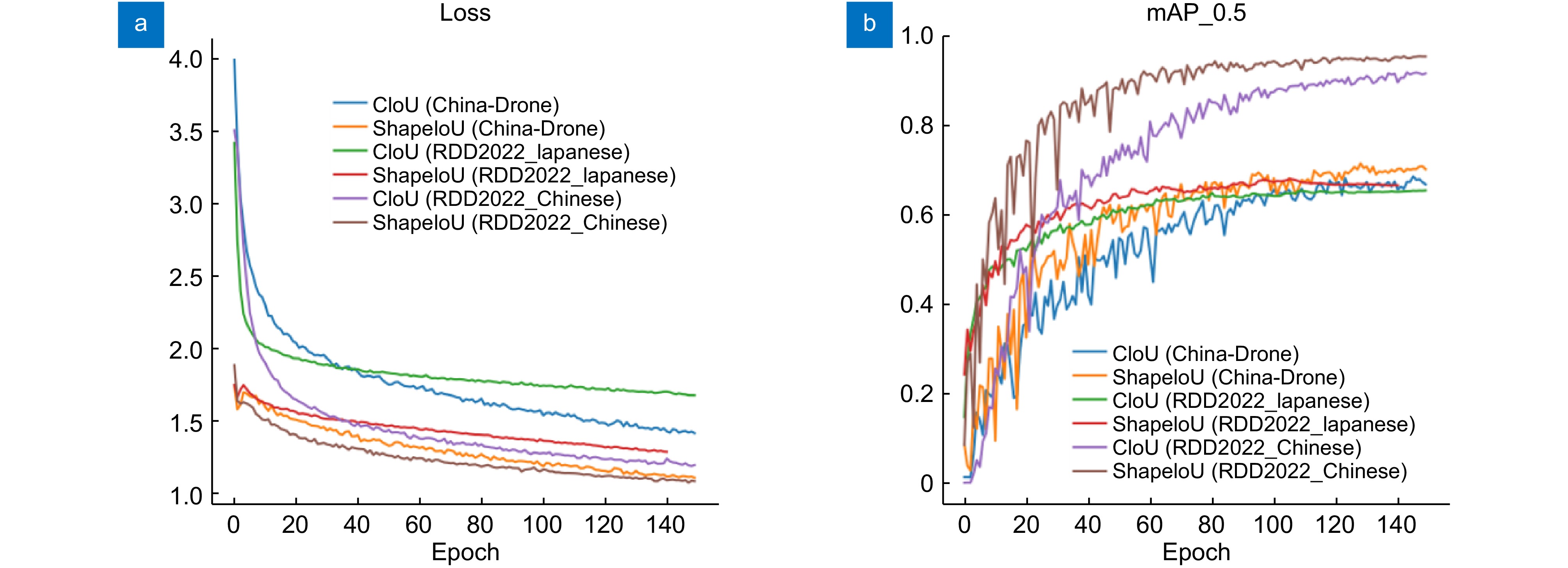
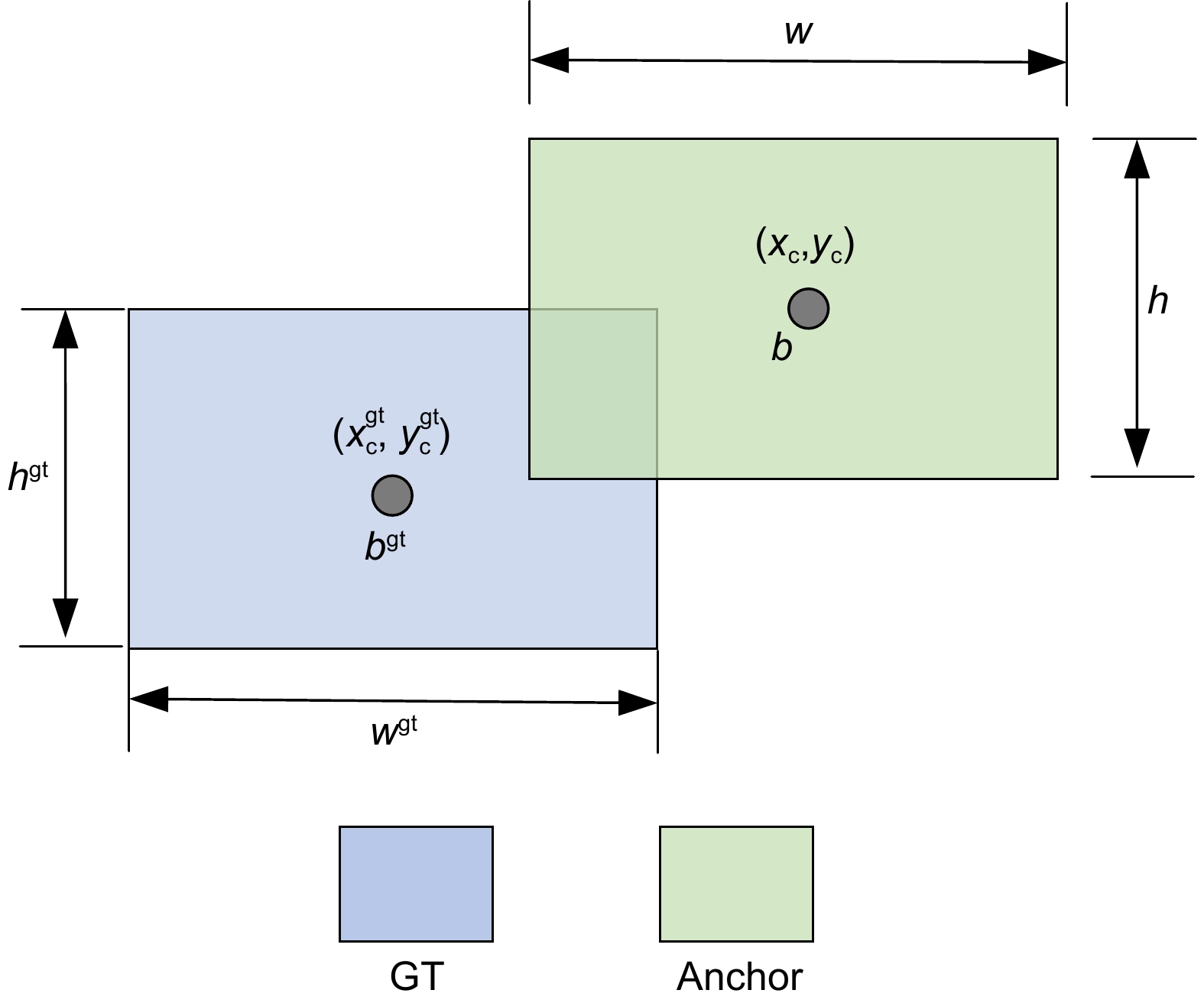
图 11 标签分配算法改进前后的实验结果。(a) Loss值变化对比图;(b) mAP变化对比图
Figure 11. Experimental results before and after improvement of the label allocation algorithm. (a) Comparison of Loss value changes; (b) Comparison of mAP changes
表 1 数据集道路损伤详情
Table 1. Dataset road damage details
Damage type Detail Class name Number of China-Drone Number of dataset1 Number of dataset2 Crack Longitudinal crack D00 1426 3995 2678 Lateral crack D10 1263 3979 1096 Alligator crack D20 293 6199 641 Other corruption Rutting, bump, pothole,
separationD40 86 2243 235 Crosswalk blur D43 — 736 — White line blur D44 — 3995 — Special signs Manhole cover D50 — 3553 — Repair Repair 769 — 277  下载: 导出CSV
下载: 导出CSV
表 2 实验环境配置
Table 2. Experimental environment configuration
Category Environment condition CPU AMD Ryzen 7 5800X 8-Core Processor GPU NVIDIA GeForce RTX 3060 Graphics memory 12 G Operating system Ubuntu 22.04 CUDA version CUDA 12.0 Scripting language Python
下载: 导出CSV
表 3 对比实验结果
Table 3. Comparative experimental results
Model China-Drone
mAP@0.5/%Dataset1
mAP@0.5/%Dataset2
mAP@0.5/%Parameter/M Model volume/MB YOLOv5n 64.7 64.0 92.2 2.5 5.03 YOLOv8n 68.5 64.7 93.6 3.0 5.96 YOLOv10n 62.4 61.8 91.4 2.7 5.51 GOLD-YOLO 66.1 65.9 94.5 7.2 11.99 Faster-RCNN 67.8 66.4 94.7 34.6 310.24 TOOD 69.0 65.6 94.9 28.3 243.95 RTMDet-Tiny 65.6 64.1 93.0 4.4 77.76 RT-DETR 68.2 67.2 87.5 20.0 308 MAS-YOLOv8n 71.6 67.3 95.3 3.2 5.96
下载: 导出CSV
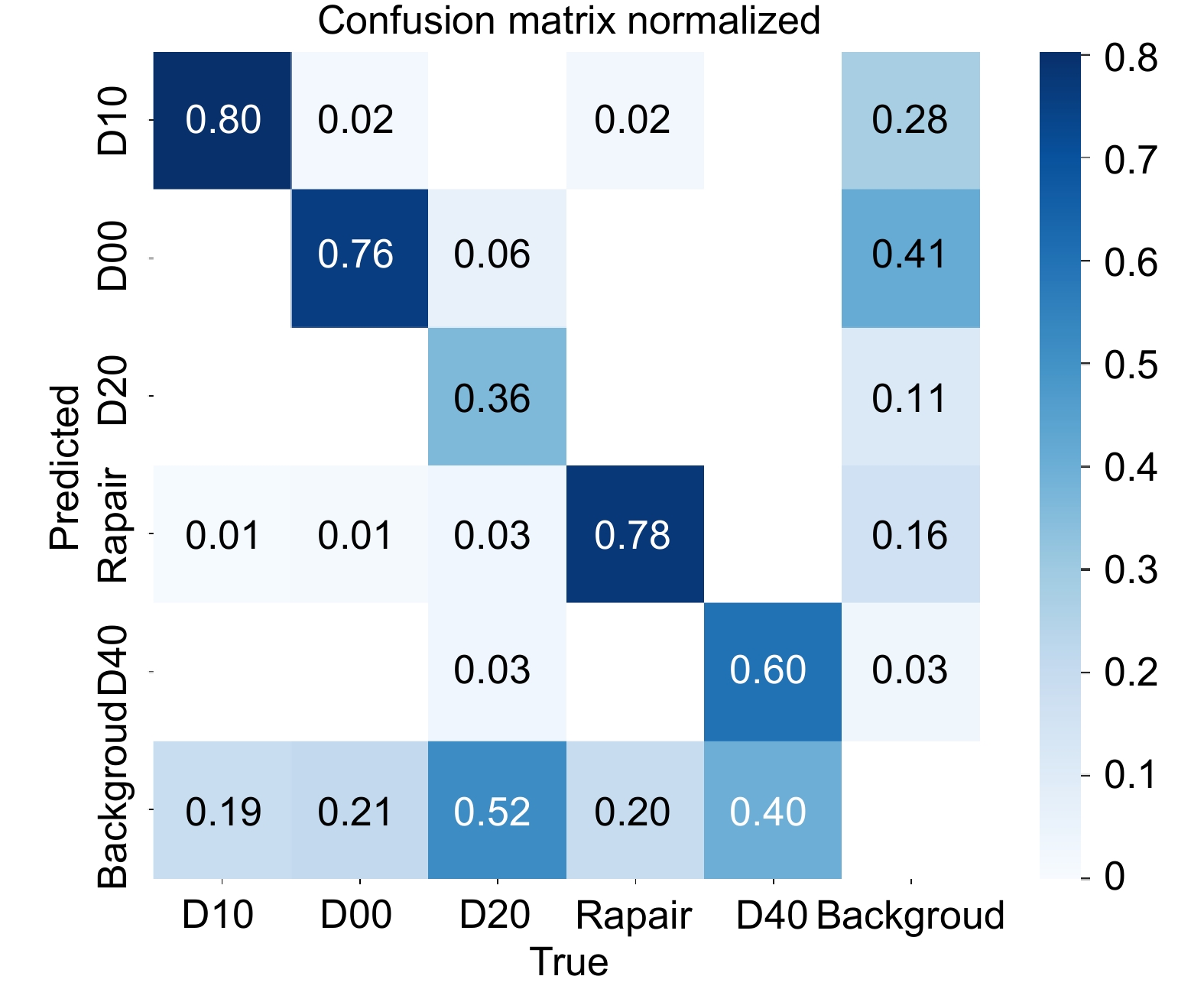
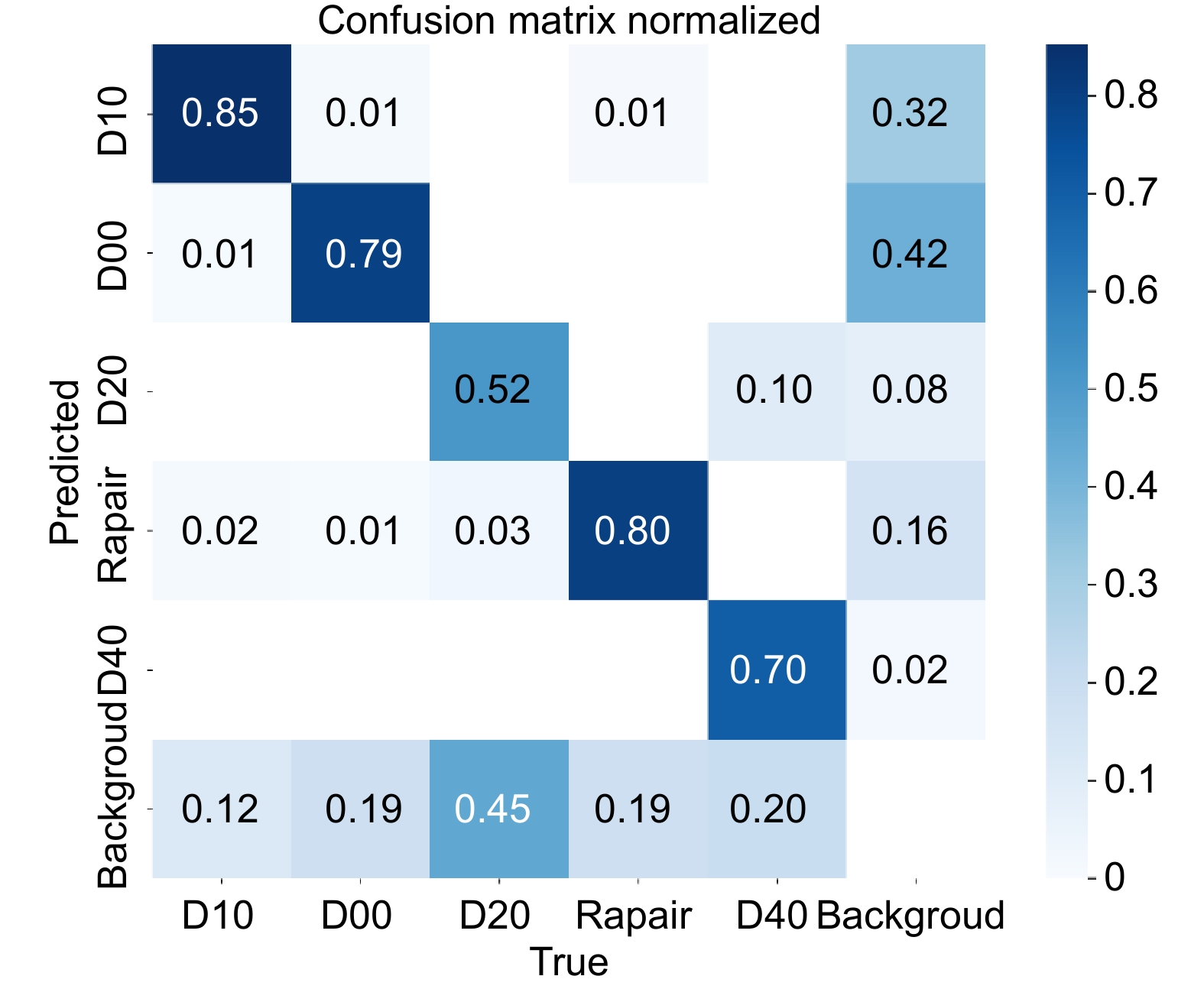
表 4 注意力机制验证结果
Table 4. Verification results of attention mechanism
Attention mechanism China-Drone
mAP@0.5/%Dataset1
mAP@0.5/%Dataset2
mAP@0.5/%Parameter/M — 68.5 64.7 93.6 3.0 SE 69.1 64.1 93.5 3.1 CMBA 67.4 65.5 94.5 3.2 CA 68.8 65.7 94.5 3.2 MBMA 70.7 66.7 94.8 3.2
下载: 导出CSV
表 5 消融实验结果
Table 5. Results of the ablation experiment
Model China-Drone
mAP@0.5/%Dataset1
mAP@0.5/%Dataset2
mAP@0.5/%Parameter/M GFLOPS Model volume/MB FPS 1 YOLOv8n 68.5 64.7 93.6 3.0 8.1 5.96 137 2 +MBMA 70.7 66.7 94.8 3.2 8.1 5.96 116 3 +ShapeIoU 70.9 67.0 95.0 3.0 8.1 5.96 135 4 MAS-YOLOv8n 71.6 67.3 95.3 3.2 8.1 5.96 114
下载: 导出CSV
-
参考文献
[1] Pan Y F, Zhang X F, Cervone G, et al. Detection of asphalt pavement potholes and cracks based on the unmanned aerial vehicle multispectral imagery[J]. IEEE J Sel Top Appl Earth Obs Remote Sens, 2018, 11(10): 3701−3712. doi: 10.1109/JSTARS.2018.2865528
[2] 安学刚, 党建武, 王阳萍, 等. 基于改进YOLOv4的无人机影像路面病害检测方法[J]. 无线电工程, 2023, 53(6): 1285−1294. doi: 10.3969/j.issn.1003-3106.2023.06.007
An X G, Dang J W, Wang Y P, et al. UAV image pavement disease detection based on improved YOLOv4[J]. Radio Eng, 2023, 53(6): 1285−1294. doi: 10.3969/j.issn.1003-3106.2023.06.007
[3] 张润梅, 肖钰霏, 贾振楠, 等. 改进YOLOv7的无人机视角下复杂环境目标检测算法[J]. 光电工程, 2024, 51(5): 240051. doi: 10.12086/oee.2024.240051
Zhang R M, Xiao Y F, Jia Z N, et al. Improved YOLOv7 algorithm for target detection in complex environments from UAV perspective[J]. Opto-Electron Eng, 2024, 51(5): 240051. doi: 10.12086/oee.2024.240051
[4] Kahmann S L, Rausch V, Plümer J, et al. The automized fracture edge detection and generation of three-dimensional fracture probability heat maps[J]. Med Eng Phys, 2022, 110: 103913. doi: 10.1016/j.medengphy.2022.103913
[5] Di Benedetto A, Fiani M, Gujski L M. U-Net-based CNN architecture for road crack segmentation[J]. Infrastructures, 2023, 8(5): 90. doi: 10.3390/infrastructures8050090
[6] Arman M S, Hasan M M, Sadia F, et al. Detection and classification of road damage using R-CNN and faster R-CNN: a deep learning approach[C]//Second EAI International Conference on Cyber Security and Computer Science, 2020: 730–741. https://doi.org/10.1007/978-3-030-52856-0_58.
[7] Girshick R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 2015: 1440–1448. https://doi.org/10.1109/ICCV.2015.169.
[8] 吕本远, 禚真福, 韩永赛, 等. 基于Faster区域卷积神经网络的目标检测[J]. 激光与光电子学进展, 2021, 58(22): 2210017. doi: 10.3788/LOP202158.2210017
Lü B Y, Zhuo Z F, Han Y S, et al. Target detection based on faster region convolution neural network[J]. Laser Optoelectron Prog, 2021, 58(22): 2210017. doi: 10.3788/LOP202158.2210017
[9] 陈旭, 彭冬亮, 谷雨. 基于改进YOLOv5s的无人机图像实时目标检测[J]. 光电工程, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
Chen X, Peng D L, Gu Y. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electron Eng, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
[10] Ajmera S, Kumar C A, Yakaiah P, et al. Real-time pothole detection using YOLOv5[C]//2022 International Conference on Advancements in Smart, Secure and Intelligent Computing (ASSIC), 2022: 1–5. https://doi.org/10.1109/ASSIC55218.2022.10088290.
[11] Eriksson M. Road damage detection withYolov8 on Swedish roads[EB/OL]. [2024-07-10]. https://www.diva-portal.org/smash/record.jsf?pid=diva2:1803747.
[12] Pham V, Nguyen D, Donan C. Road damage detection and classification with YOLOv7[C]//2022 IEEE International Conference on Big Data (Big Data), 2022: 6416–6423. https://doi.org/10.1109/BigData55660.2022.10020856.
[13] Jiang Y T, Yan H T, Zhang Y R, et al. RDD-YOLOv5: road defect detection algorithm with self-attention based on unmanned aerial vehicle inspection[J]. Sensors, 2023, 23(19): 8241. doi: 10.3390/s23198241
[14] 程期浩, 陈东方, 王晓峰. 基于NDM-YOLOv8的无人机图像小目标检测[J]. 计算机技术与发展, 2024. doi: 10.20165/j.cnki.ISSN1673-629X.2024.0177
Cheng Q H, Chen D F, Wang X F. Small target detection in UAV images based on NDM-YOLOv8[J]. Comput Technol Dev, 2024. doi: 10.20165/j.cnki.ISSN1673-629X.2024.0177
[15] Li Y T, Fan Q S, Huang H S, et al. A modified YOLOv8 detection network for UAV aerial image recognition[J]. Drones, 2023, 7(5): 304. doi: 10.3390/drones7050304
[16] 龙伍丹, 彭博, 胡节, 等. 基于加强特征提取的道路病害检测算法[J]. 计算机应用, 2024, 44(7): 2264−2270. doi: 10.11772/j.issn.1001-9081.2023070956
Long W D, Peng B, Hu J, et al. Road damage detection algorithm based on enhanced feature extraction[J]. J Comput Appl, 2024, 44(7): 2264−2270. doi: 10.11772/j.issn.1001-9081.2023070956
[17] 孟鹏帅, 王峰, 翟伟光, 等. 基于YOLO-DSBE的无人机对地目标检测[J]. 航空兵器, 2024. doi: 10.12132/ISSN.1673-5048.2024.0064
Meng P S, Wang F, Zhai W G, et al. UAV-to-ground target detection based on YOLO-DSBE[J]. Aero Weapon, 2024. doi: 10.12132/ISSN.1673-5048.2024.0064
[18] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[19] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 3–19. https://doi.org/10.1007/978-3-030-01234-2_1.
[20] Hou Q B, Zhou D Q, Feng J S. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13708–13717. https://doi.org/10.1109/CVPR46437.2021.01350.
[21] Zheng Z H, Wang P, Liu W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, 2020: 12993–13000. https://doi.org/10.1609/aaai.v34i07.69993.
[22] Zhang H, Zhang S J. Shape-IoU: more accurate metric considering bounding box shape and scale[Z]. arXiv: 2312.17663, 2023. https://doi.org/10.48550/arXiv.2312.17663.
[23] Arya D, Maeda H, Ghosh S K, et al. RDD2022: a multi-national image dataset for automatic Road Damage Detection[Z]. arXiv: 2209.08538, 2022. https://doi.org/10.48550/arXiv.2209.08538.
[24] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031
[25] Wang C C, He W, Nie Y, et al. Gold-YOLO: efficient object detector via gather-and-distribute mechanism[C]//Proceedings of the 37th International Conference on Neural Information Processing Systems, 2023: 2224.
[26] Feng C J, Zhong Y J, Gao Y, et al. TOOD: task-aligned one-stage object detection[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021: 3490–3499. https://doi.org/10.1109/ICCV48922.2021.00349.
[27] Xiang H F, Jing N F, Jiang J F, et al. RTMDet-R2: an improved real-time rotated object detector[C]//6th Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 2024: 352–364. https://doi.org/10.1007/978-981-99-8555-5_28.
[28] Zhao Y A, Lv W Y, Xu S L, et al. DETRs beat YOLOs on real-time object detection[Z]. arXiv: 2304.08069, 2023. https://doi.org/10.48550/arXiv.2304.08069.
-
访问统计


 点击扫一扫
点击扫一扫
图(12)
表(5)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


