
 E-mail Alert
E-mail Alert RSS
RSS
Dual low-light images combining color correction and structural information enhance
-
摘要
为改善暗环境下图像的成像效果,本文提出了一种无监督双路低光照图像增强算法,结合了色彩校正和结构信息。该算法基于生成对抗网络,其中生成器采用双分支结构同时处理图像的色彩与结构细节,以实现更自然的颜色恢复和更清晰的纹理细节。判别器引入空间辨别模块 (spatial-discriminative block, SDB),以增强其判别能力,推动生成器生成更真实的图像。图像色彩校正模块 (Illumination-guided color correction block, IGCB)利用光照特征引导,减少低光照环境下噪声和伪影的影响。通过多尺度通道融合模块 (selective kernel channel fusion, SKCF)和优化的注意力卷积模块 (convolution attention block, CAB),增强了图像的语义信息和局部细节。实验结果表明,该算法在LOL和LSRW数据集上表现优于经典方法,在LOLv1和LOLv2数据集上,PSNR和SSIM指标分别达到19.89与0.672,以及20.08与0.693,整体性能优于现有无监督算法。实际应用验证了该算法在恢复低光照图像的亮度、对比度和色彩方面的有效性。
Abstract
To enhance image quality in low-light conditions, an unsupervised dual-path low-light image enhancement algorithm is proposed, integrating color correction and structural information. The algorithm utilizes a generative adversarial network (GAN) with a generator that employs a dual-branch architecture to concurrently handle color and structural details, resulting in natural color restoration and clear texture details. A spatial-discriminative block (SDB) is introduced in the discriminator to improve its judgment capability, leading to more realistic image generation. An illumination-guided color correction block (IGCB) uses illumination features to mitigate noise and artifacts in low-light environments. The selective kernel channel fusion (SKCF) and convolution attention block (CAB) modules enhance the semantic and local details of the image. Experimental results show that the algorithm outperforms classical methods on the LOL and LSRW datasets, achieving PSNR and SSIM scores of 19.89 and 0.672, respectively, on the LOLv1 dataset, and 20.08 and 0.693 on the LOLv2 dataset. Practical applications confirm its effectiveness in restoring brightness, contrast, and color in low-light images.
-
Overview
Overview: During the image acquisition process, insufficient or uneven external lighting, differences in the positioning of the shooting equipment, or varying exposures of the same equipment can result in images that are relatively dark, leading to low-light image problems. These issues not only affect the observation experience but also pose significant challenges to feature extraction, object detection, and image understanding in image processing or machine vision, seriously impacting their application effectiveness. Although deep learning methods have achieved significant success in the field of low-light image enhancement, several issues remain: 1) poor generalization caused by paired dataset training; 2) noise amplification and color deviation introduced during the enhancement process; 3) loss of structural details during the transmission process of deep learning networks.
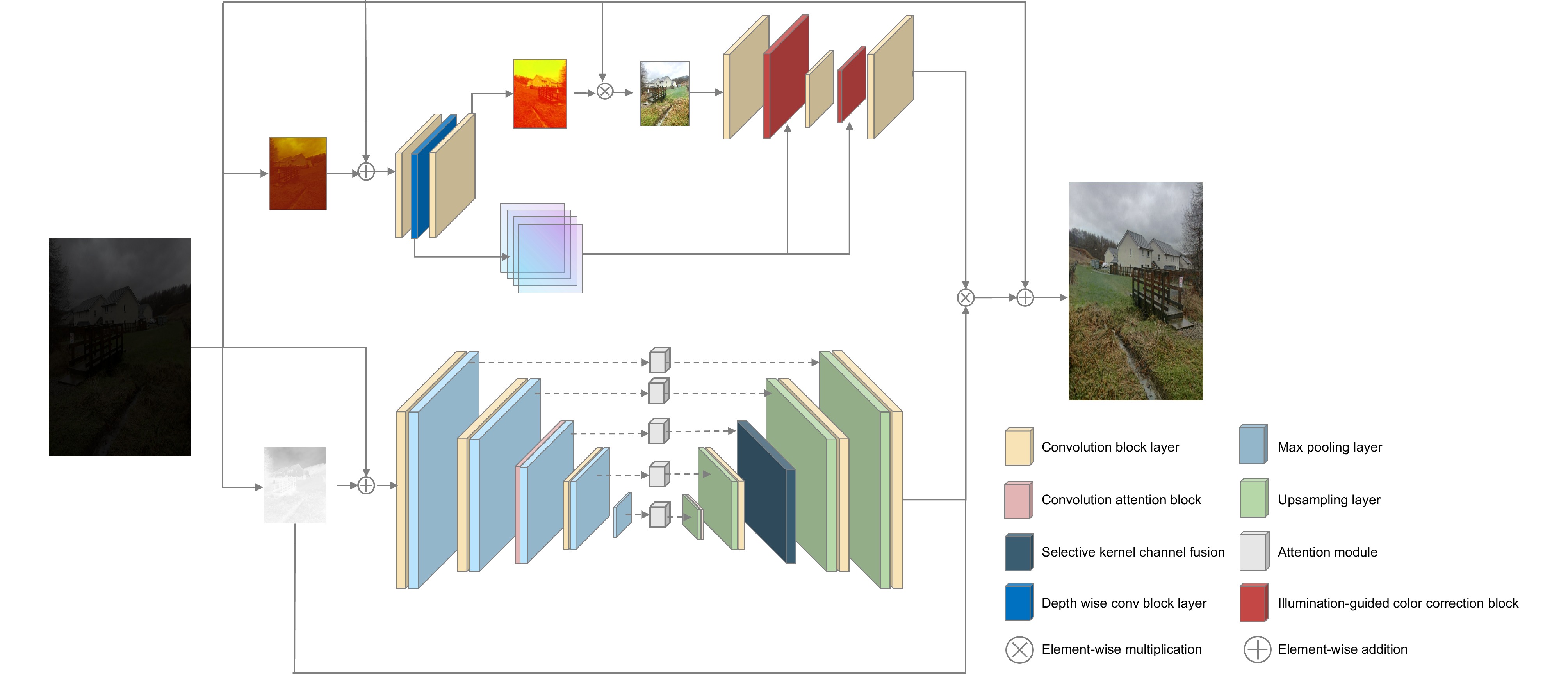
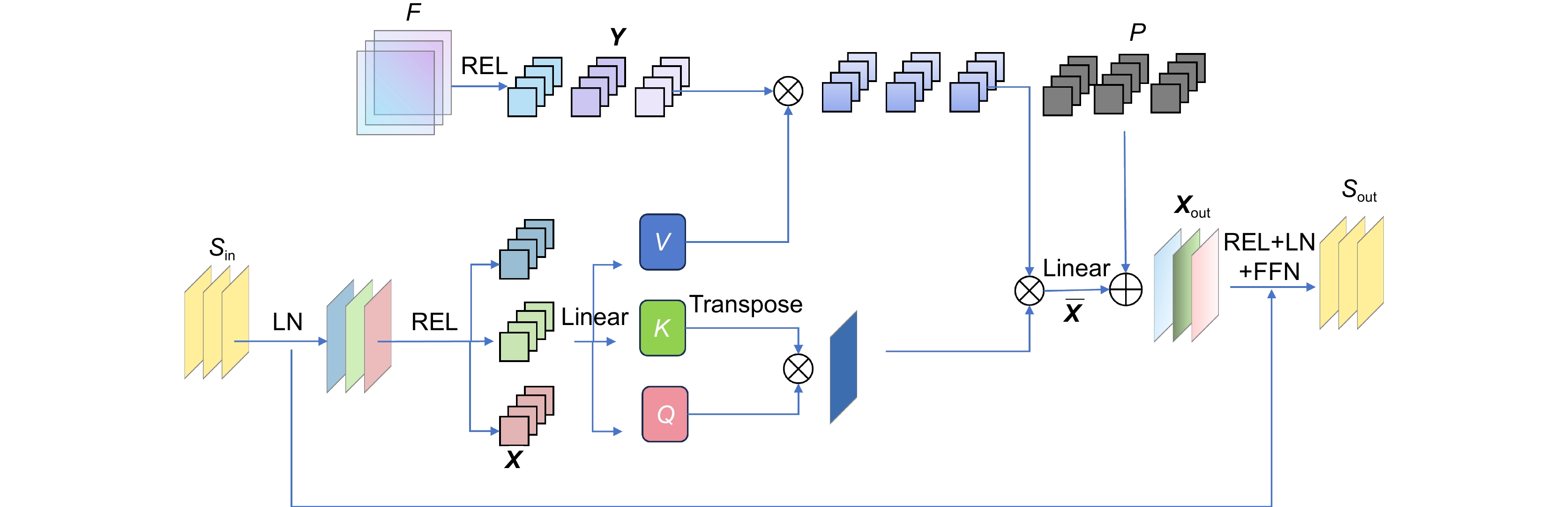
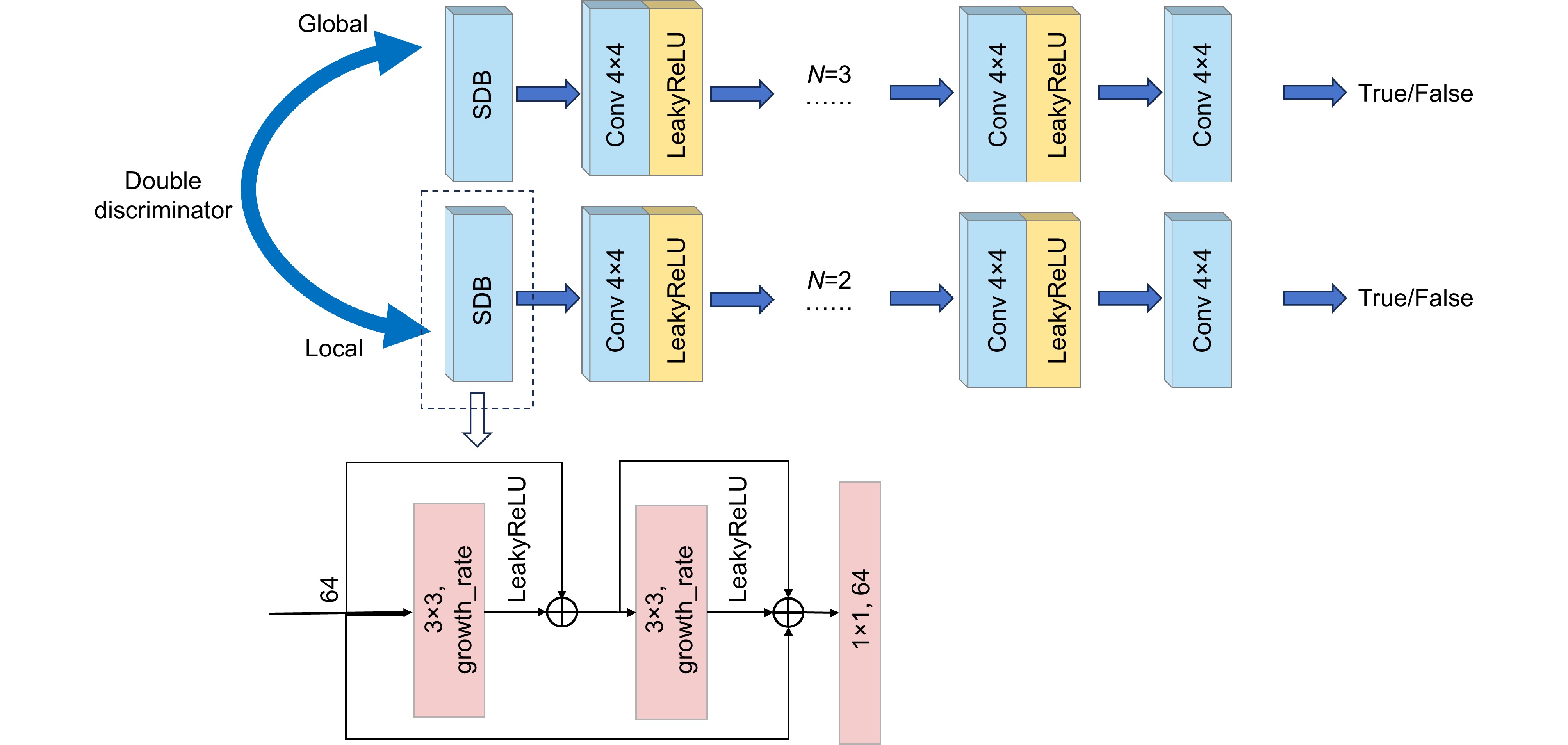
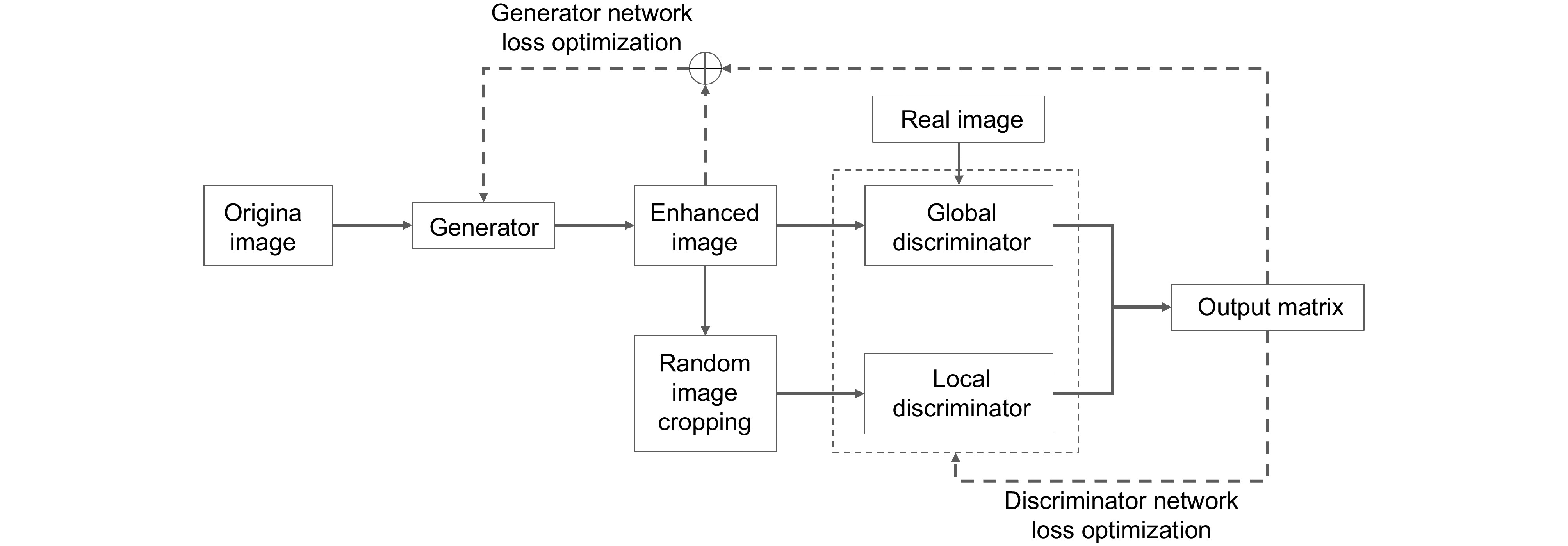
To address these issues, an unsupervised dual low-light image enhancement method that combines color correction and structural information is proposed. Firstly, based on generative adversarial networks, the generator adopts a dual-branch network structure to process image colors and structural details in parallel, resulting in restored images with more natural colors and clearer texture details. The addition of a spatial discrimination module (SDB) to the discriminator enhances its judgment capability, encouraging the generator to produce more realistic images. Secondly, an image color correction module (IGCB) is proposed based on the lighting characteristics of the image itself, using lighting features as guidance to reduce the impact of noise and artifacts caused by environmental factors on low-light images. Finally, the proposed attention convolution module (CAB) and multi-scale channel fusion module (SKCF) are utilized to enhance the semantic and local information at each level of the image. In the color branch, an image correction module introduces lighting features at each stage of image processing, enhancing the interaction between regions with different exposure levels, and resulting in an enhanced image with rich color and illumination information. In the structural branch, attention convolution modules are introduced during the encoding stage to perform fine-grained spatial feature optimization and enhance high-frequency information. During the decoding stage, a multi-scale channel fusion module is used to gather comprehensive feature information from different scales, improving the texture recovery ability of the image network. Experimental results show that, compared with classical algorithms, this method restores images with more natural colors and clearer texture details across multiple datasets.
-

-

图 9 在LOL和LSRW数据集上不同方法的可视化对比
Figure 9. Visual comparison of different methods on LOL and LSRW

图 10 在无参考数据集上不同方法的可视化对比
Figure 10. Visual comparison of different methods on unreferenced datasets
表 1 不同模块消融试验
Table 1. Different module ablation tests
模型 CAB SKCF 上分支 SDB PSNR SSIM F0 × × × × 15.66 0.498 F1 √ × × × 17.81 0.621 F2 × √ × × 17.47 0.678 F3 × × √ × 18.75 0.693 F4 × × × √ 17.13 0.623 F5 × √ √ √ 18.47 0.615 F6 √ × √ √ 19.12 0.644 F7 √ √ × √ 18.25 0.613 F8 √ √ √ × 19.31 0.669 Ours √ √ √ √ 19.89 0.672  下载: 导出CSV
下载: 导出CSV
表 2 与主流方法的客观评价结果
Table 2. Objective evaluation results with mainstream methods
Method Type LOLv1_test LOLv2_test LSRW-huawei LSRW-Nikon PSNR SSIM LPIPS PSNR SSIM LPIPS PSNR SSIM LPIPS PSNR SSIM LPIPS Retinex-Net[7] S 17.56 0.604 0.474 17.68 0.594 0.440 16.76 0.566 0.432 13.84 0.392 0.352 URetinex-Net[28] S 17.48 0.625 0.182 18.16 0.616 0.156 12.52 0.454 0.369 12.51 0.454 0.256 EnGAN[9] U 15.66 0.498 0.354 17.34 0.594 0.310 18.04 0.607 0.362 15.32 0.490 0.267 SCI[10] U 13.81 0.517 0.339 17.25 0.563 0.322 15.10 0.473 0.381 15.28 0.446 0.244 Zero-DCE[8] U 12.18 0.477 0.335 14.87 0.509 0.318 16.35 0.564 0.366 15.03 0.448 0.239 RUAS[29] U 12.77 0.334 0.418 13.12 0.329 0.374 12.54 0.362 0.443 13.80 0.406 0.287 PairLIE[11] U 18.47 0.647 0.245 19.88 0.777 0.234 18.98 0.563 0.387 15.52 0.437 0.257 PIE[12] U 13.54 0.485 0.353 14.04 0.537 0.325 17.46 0.588 0.415 15.93 0.544 0.298 Ours U 19.89 0.672 0.234 20.08 0.693 0.242 18.57 0.623 0.383 17.03 0.559 0.239
下载: 导出CSV
表 3 不同方法在各个数据集上的NIQE值
Table 3. NIQE values of different methods on each dataset
Method MEF LIME NPE DICM ALL Retinex-Net 5.339 6.860 5.542 5.385 5.782 URetinex-Net 4.976 5.197 6.974 5.239 5.597 EnGAN 4.310 4.571 5.020 4.547 4.612 Zero-DCE 4.102 4.884 4.635 4.375 4.474 SCI 4.581 5.487 4.978 5.009 5.014 RUAS 4.522 4.780 6.318 5.185 5.201 PairLIE 4.530 4.735 4.563 4.529 4.589 PIE 4.166 4.322 4.509 4.361 4.340 Ours 4.063 4.142 4.599 4.502 4.327
下载: 导出CSV
-
参考文献
[1] Lan R S, Sun L, Liu Z B, et al. MADNet: a fast and lightweight network for single-image super resolution[J]. IEEE Trans Cybern, 2021, 51(3): 1443−1453. doi: 10.1109/TCYB.2020.2970104
[2] Lin J P, Liao L Z, Lin S L, et al. Deep and adaptive feature extraction attention network for single image super-resolution[J]. J Soc Inf Disp, 2024, 32(1): 23−33. doi: 10.1002/jsid.1269
[3] 徐胜军, 杨华, 李明海, 等. 基于双频域特征聚合的低照度图像增强[J]. 光电工程, 2023, 50(12): 230225. doi: 10.12086/oee.2023.230225
Xu S J, Yang H, Li M H, et al. Low-light image enhancement based on dual-frequency domain feature aggregation[J]. Opto-Electron Eng, 2023, 50(12): 230225. doi: 10.12086/oee.2023.230225
[4] 刘光辉, 杨琦, 孟月波, 等. 一种并行混合注意力的渐进融合图像增强方法[J]. 光电工程, 2023, 50(4): 220231. doi: 10.12086/oee.2023.220231
Liu G H, Yang Q, Meng Y B, et al. A progressive fusion image enhancement method with parallel hybrid attention[J]. Opto-Electron Eng, 2023, 50(4): 220231. doi: 10.12086/oee.2023.220231
[5] Jin X, Han L H, Li Z, et al. DNF: decouple and feedback network for seeing in the dark[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 18135–18144. https://doi.org/10.1109/CVPR52729.2023.01739.
[6] Lore K G, Akintayo A, Sarkar S. LLNet: a deep autoencoder approach to natural low-light image enhancement[J]. Pattern Recognit, 2017, 61: 650−662. doi: 10.1016/j.patcog.2016.06.008
[7] Wei C, Wang W J, Yang W H, et al. Deep retinex decomposition for low-light enhancement[C]//British Machine Vision Conference 2018, 2018: 155.
[8] Guo X J, Li Y, Ling H B. LIME: low-light image enhancement via illumination map estimation[J]. IEEE Trans Image Process, 2017, 26(2): 982−993. doi: 10.1109/TIP.2016.2639450
[9] Gong Y F, Liao P Y, Zhang X D, et al. Enlighten-GAN for super resolution reconstruction in mid-resolution remote sensing images[J]. Remote Sens, 2021, 13(6): 1104. doi: 10.3390/rs13061104
[10] Ma L, Ma T Y, Liu R S, et al. Toward fast, flexible, and robust low-light image enhancement[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5627–5636. https://doi.org/10.1109/CVPR52688.2022.00555.
[11] Fu Z Q, Yang Y, Tu X T, et al. Learning a simple low-light image enhancer from paired low-light instances[C]// Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 22252–22261. https://doi.org/10.1109/CVPR52729.2023.02131.
[12] Liang D, Xu Z Y, Li L, et al. PIE: physics-inspired low-light enhancement[Z]. arXiv: 2404.04586, 2024. https://arxiv.org/abs/2404.04586.
[13] 林坚普, 王栋, 肖智阳, 等. 图像边缘权重优化的最小生成树分割提取[J]. 电子与信息学报, 2023, 45(4): 1494−1504. doi: 10.11999/JEIT220182
Lin J P, Wang D, Xiao Z Y, et al. Minimum spanning tree segmentation and extract with image edge weight optimization[J]. J Electron Inf Technol, 2023, 45(4): 1494−1504. doi: 10.11999/JEIT220182
[14] 程德强, 尤杨杨, 寇旗旗, 等. 融合暗通道先验损失的生成对抗网络用于单幅图像去雾[J]. 光电工程, 2022, 49(7): 210448. doi: 10.12086/oee.2022.210448
Cheng D Q, You Y Y, Kou Q Q, et al. A generative adversarial network incorporating dark channel prior loss used for single image defogging[J]. Opto-Electron Eng, 2022, 49(7): 210448. doi: 10.12086/oee.2022.210448
[15] 刘皓轩, 林珊玲, 林志贤, 等. 基于GAN的轻量级水下图像增强网络[J]. 液晶与显示, 2023, 38(3): 378−386. doi: 10.37188/CJLCD.2022-0212
Liu H X, Lin S L, Lin Z X, et al. Lightweight underwater image enhancement network based on GAN[J]. Chin J Liq Cryst Disp, 2023, 38(3): 378−386. doi: 10.37188/CJLCD.2022-0212
[16] Cai Y H, Bian H, Lin J, et al. Retinexformer: one-stage retinex-based transformer for low-light image enhancement[C]// Proceedings of 2023 IEEE/CVF International Conference on Computer Vision, 2023: 12470–12479. https://doi.org/10.1109/ICCV51070.2023.01149.
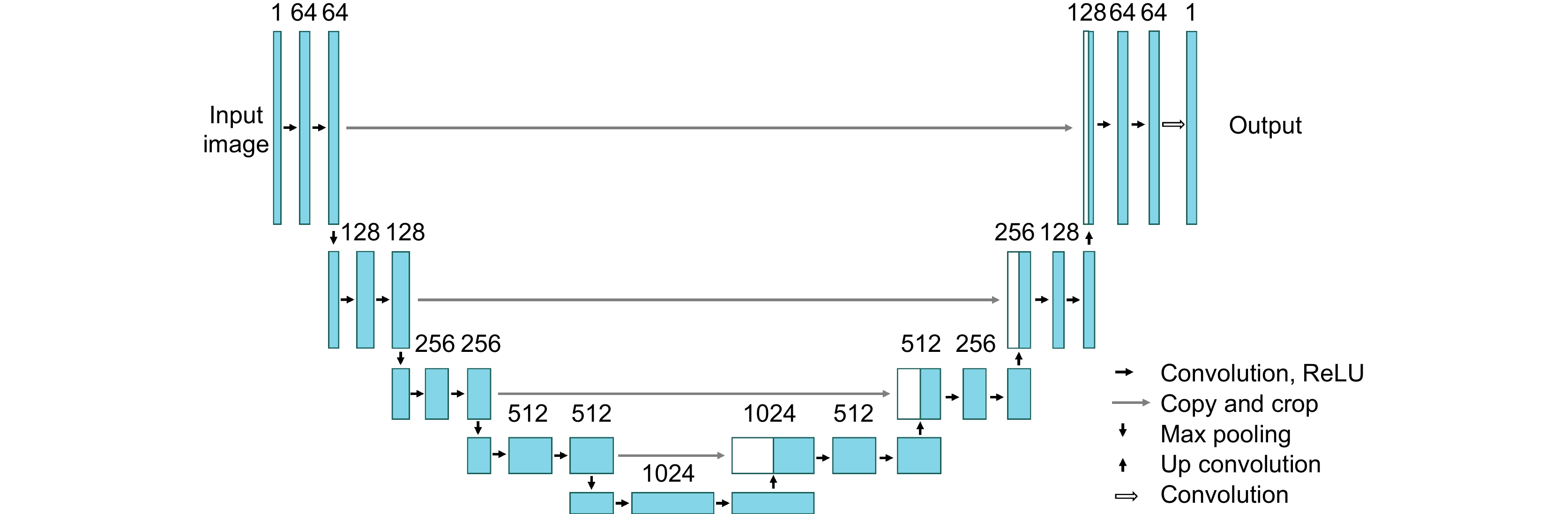
[17] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation [C]//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015: 234–241. https://doi.org/10.1007/978-3-319-24574-4_28.
[18] Joshy A A, Rajan R. Dysarthria severity assessment using squeeze-and-excitation networks[J]. Biomed Signal Process Control, 2023, 82: 104606. doi: 10.1016/j.bspc.2023.104606
[19] Zhang S, Liu Z W, Chen Y P, et al. Selective kernel convolution deep residual network based on channel-spatial attention mechanism and feature fusion for mechanical fault diagnosis[J]. ISA Transactions, 2023, 133: 369−383. doi: 10.1016/j.isatra.2022.06.035
[20] Ponomarenko N, Silvestri F, Egiazarian K, et al. On between-coefficient contrast masking of DCT basis functions[C]//Third International Workshop on Video Processing and Quality Metrics for Consumer Electronics, 2007: 1–4.
[21] Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans Image Process, 2004, 13(4): 600−612. doi: 10.1109/TIP.2003.819861
[22] Zhang R, Isola P, Efros A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 586–595. https://doi.org/10.1109/CVPR.2018.00068.
[23] Zhang L, Zhang L, Bovik A C. A feature-enriched completely blind image quality evaluator[J]. IEEE Trans Image Process, 2015, 24(8): 2579−2591. doi: 10.1109/TIP.2015.2426416
[24] Hai J, Xuan Z, Yang R, et al. R2RNet: low-light image enhancement via real-low to real-normal network[J]. J Vis Commun Image Represent, 2023, 90: 103712. doi: 10.1016/j.jvcir.2022.103712
[25] Lee C, Lee C, Kim C S. Contrast enhancement based on layered difference representation[C]//2012 19th IEEE International Conference on Image Processing, 2012: 965–968. https://doi.org/10.1109/ICIP.2012.6467022.
[26] Ma K D, Zeng K, Wang Z. Perceptual quality assessment for multi-exposure image fusion[J]. IEEE Trans Image Process, 2015, 24(11): 3345−3356. doi: 10.1109/TIP.2015.2442920
[27] Wang S H, Zheng J, Hu H M, et al. Naturalness preserved enhancement algorithm for non-uniform illumination images[J]. IEEE Trans Image Process, 2013, 22(9): 3538−3548. doi: 10.1109/TIP.2013.2261309
[28] Wu W H, Weng J, Zhang P P, et al. URetinex-Net: retinex-based deep unfolding network for low-light image enhancement [C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5891–5900. https://doi.org/10.1109/CVPR52688.2022.00581.
[29] Liu R S, Ma L, Zhang J A, et al. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 10556–10565. https://doi.org/10.1109/CVPR46437.2021.01042.
-
访问统计




 点击扫一扫
点击扫一扫
图(11)
表(3)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


