
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
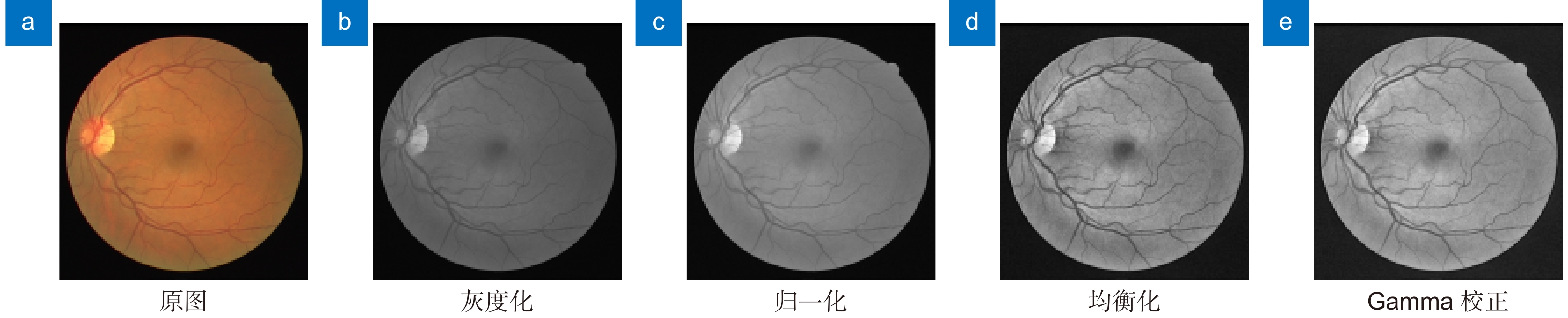
针对眼底视网膜分割存在病理伪影干扰、微小血管分割不完全和血管前景与非血管背景对比度低等问题,本文提出一种自适应特征融合级联Transformer视网膜血管分割算法。该算法首先通过限制对比度直方图均衡化和Gamma校正等方法进行图像预处理,以增强血管纹理特征;其次在编码部分设计自适应增强注意模块,降低计算冗余度同时消除视网膜背景图像噪声;然后在编解码结构底部加入级联群体Transformer模块,建立血管特征长短距离依赖;最后在解码部分引入门控特征融合模块,实现编解码语义融合,提升视网膜血管分割光滑度。在公共数据集DRIVE、CHASE_DB1和STARE上进行验证,准确率达到97.09%、97.60%和97.57%,灵敏度达到80.38%、81.05%和80.32%,特异性达到98.69%、98.71%和98.99%。实验结果表明,本文算法总体性能优于现有大多数先进算法,对临床眼科疾病的诊断具有一定应用价值。
-
关键词:
- 视网膜血管分割 /
- Transformer /
- 自适应增强注意力 /
- 门控特征融合
Abstract
An adaptive feature fusion cascaded Transformer retinal vessel segmentation algorithm is proposed in this paper to address issues such as pathological artifacts interference, incomplete segmentation of small vessels, and low contrast between vascular foreground and non-vascular background. Firstly, image preprocessing is performed through contrast-limited histogram equalization and Gamma correction to enhance vascular texture features. Secondly, an adaptive enhancing attention module is designed in the encoding part to reduce computational redundancy while eliminating noise in retinal background images. Furthermore, a cascaded ensemble Transformer module is introduced at the bottom of the encoding-decoding structure to establish dependencies between long and short-distance vascular features. Lastly, a gate-controlled feature fusion module is introduced in the decoding part to achieve semantic fusion between encoding and decoding, enhancing the smoothness of retinal vessel segmentation. Validation on public datasets DRIVE, CHASE_DB1, and STARE yielded accuracy rates of 97.09%, 97.60%, and 97.57%, sensitivity rates of 80.38%, 81.05%, and 80.32%, and specificity rates of 98.69%, 98.71%, and 98.99%, respectively. Experimental results indicate that the overall performance of this algorithm surpasses that of most existing state-of-the-art methods and holds potential value in the diagnosis of clinical ophthalmic diseases.
-
Overview
Overview: Retinal blood vessel images contain rich geometric structures, such as vessel diameter, branching angle, and length, which allow ophthalmologists to prevent and diagnose diseases such as hypertension, diabetes, and atherosclerosis by observing information about retinal blood vessel structure. However, the topology of the fundus blood vessels is intricate and difficult to extract medically, so it is important to study a retinal vessel segmentation algorithm that can be efficient and automatic for clinicopathologic diagnosis. The contemporary retinal vessel segmentation methods are mainly categorized into traditional machine- and deep-learning-based methods. Traditional machine learning methods include morphology-based processing, matched filter-based, and wavelet transform, etc. Such methods usually do not require a priori labeling information, but rather utilize the similarity between the data for analysis. The deep learning method is an end-to-end learning method, that can automatically extract the bottom and high-level feature information of the image, compared with the traditional segmentation methods to avoid the process of manual feature extraction, and at the same time reduce the subjectivity of segmentation, and its generalization ability is significantly better than that of the traditional methods. However, the fundus retinal segmentation task still suffers from pathologic artifact interference, incomplete segmentation of tiny vessels, and low contrast between the vascular foreground and the nonvascular background. To solve the above problems, an adaptive feature fusion cascade Transformer retinal vessel segmentation algorithm is proposed. The original image of the retina dataset was first subjected to dataset expansion to ensure adequate training and prediction of the model, and operations such as gamma correction were performed to perform dataset image enhancement and to improve the contrast of the blood vessel texture. Secondly, the adaptive enhancement attention module is designed in the encoding part to improve the information interaction ability between different channels, and at the same time, the background noise information of the image is eliminated to reduce the interference of pathological artifacts and enhance the nonlinear ability of the vascular image. Then the cascade group Transformer module is added at the bottom end of the codec to effectively aggregate the contextual vascular feature information and fully capture the local features of tiny blood vessels. Finally, a gated feature fusion module is introduced in the decoding part to capture the spatial feature information of different sizes in the codec layer, which improves the feature utilization and algorithm robustness. Validated on the public datasets DRIVE, CHASE_DB1, and STARE, the accuracy reaches 97.09%, 97.60%, and 97.57%, the sensitivity reaches 80.38%, 81.05%, and 80.32%, and the specificity reaches 98.69%, 98.71%, and 98.99%. The experimental results show that the overall performance of the algorithm in this paper is better than most of the existing state-of-the-art algorithms, and it has a certain application value for the diagnosis of clinical ophthalmic diseases.
-

-
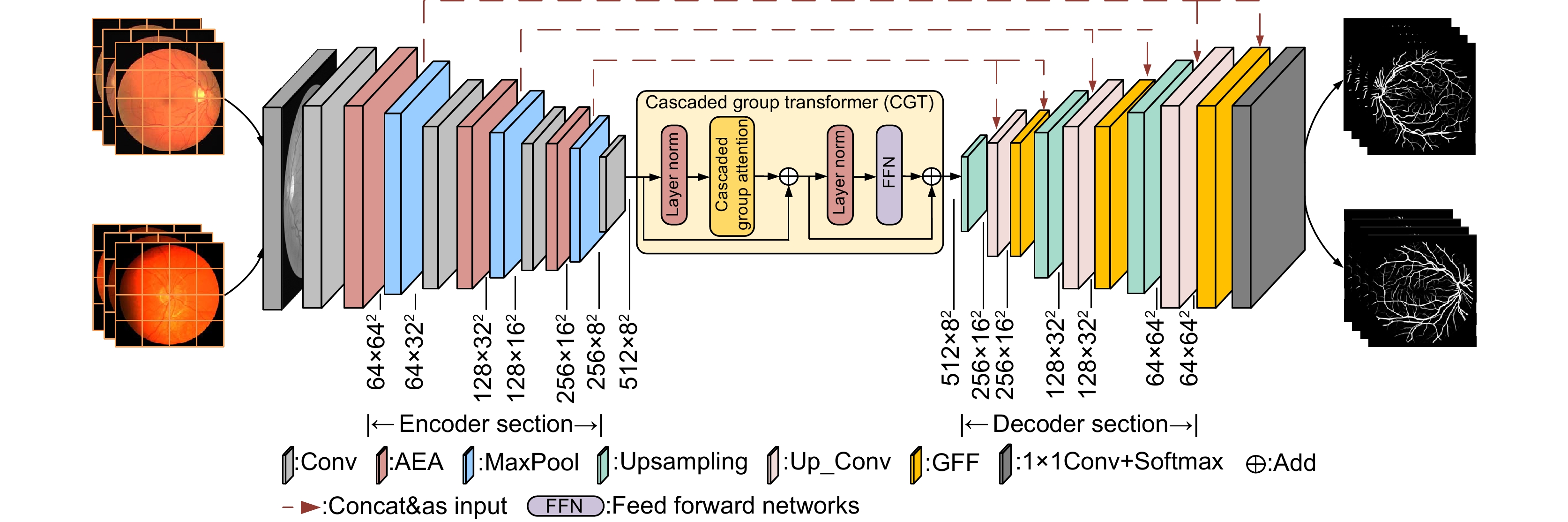
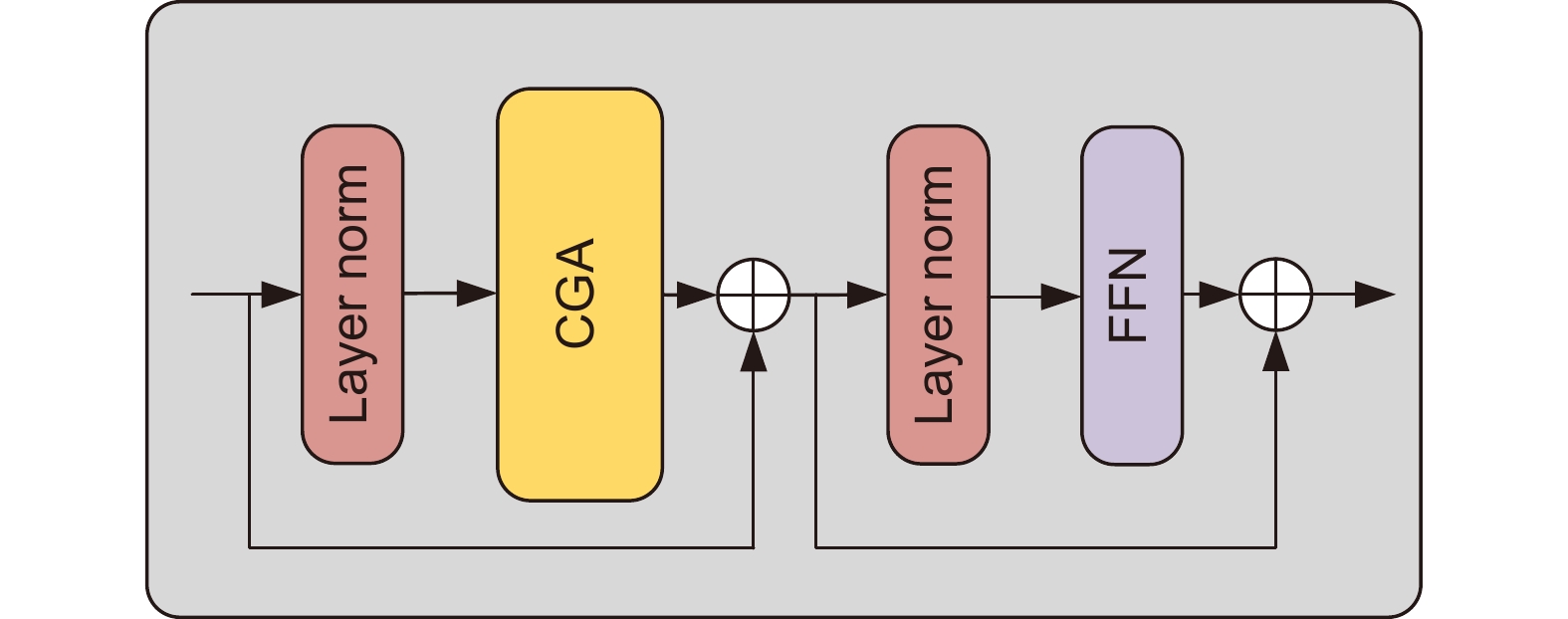
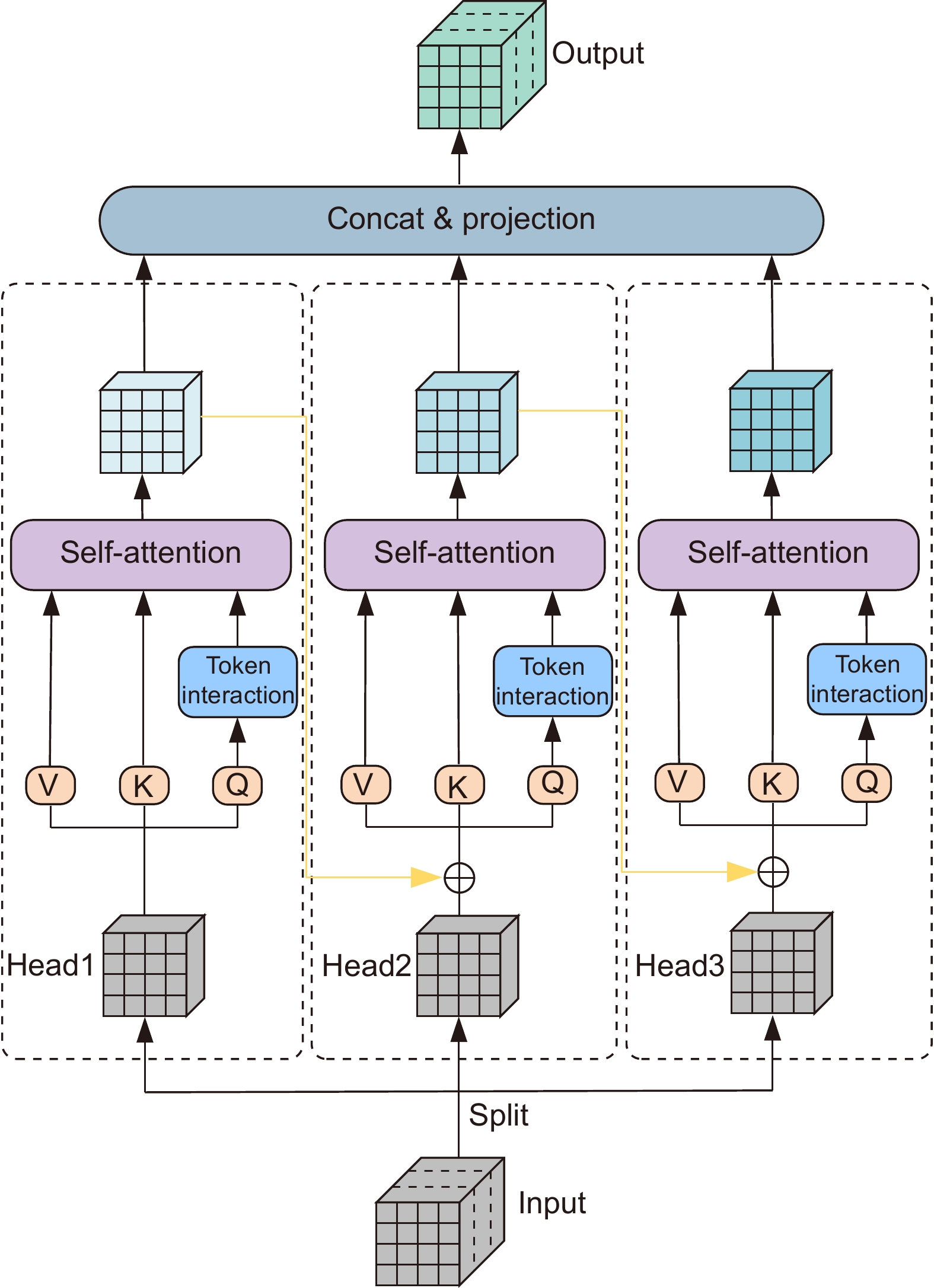
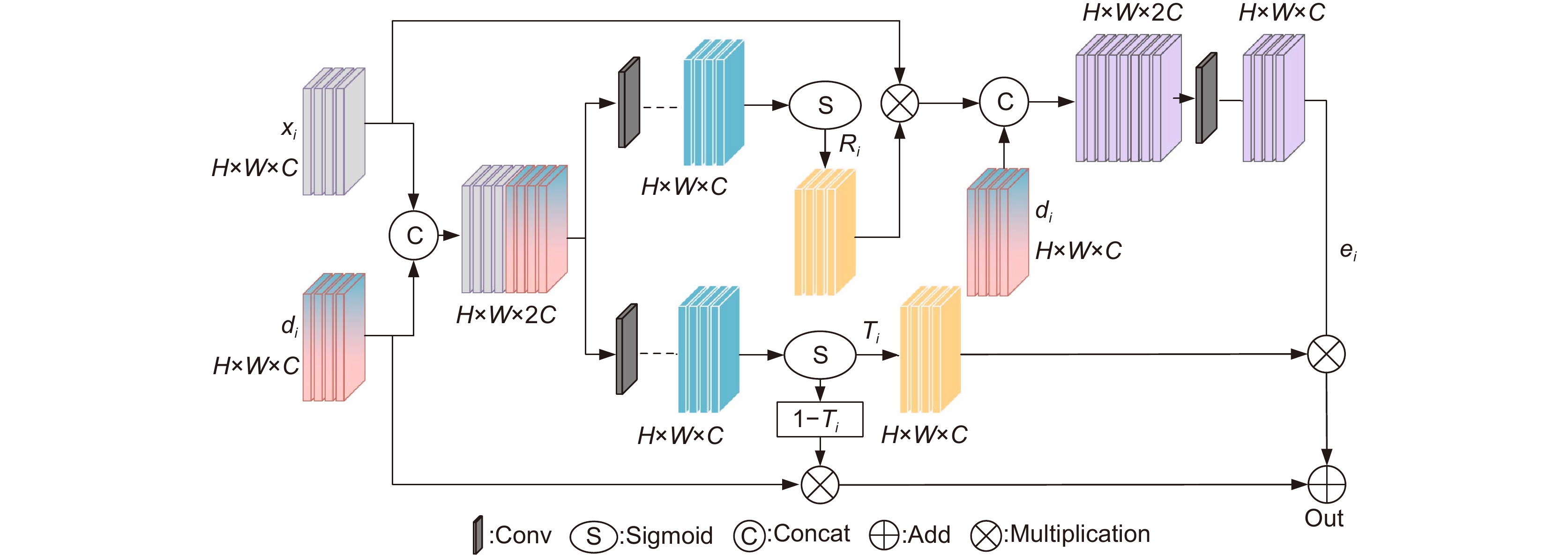
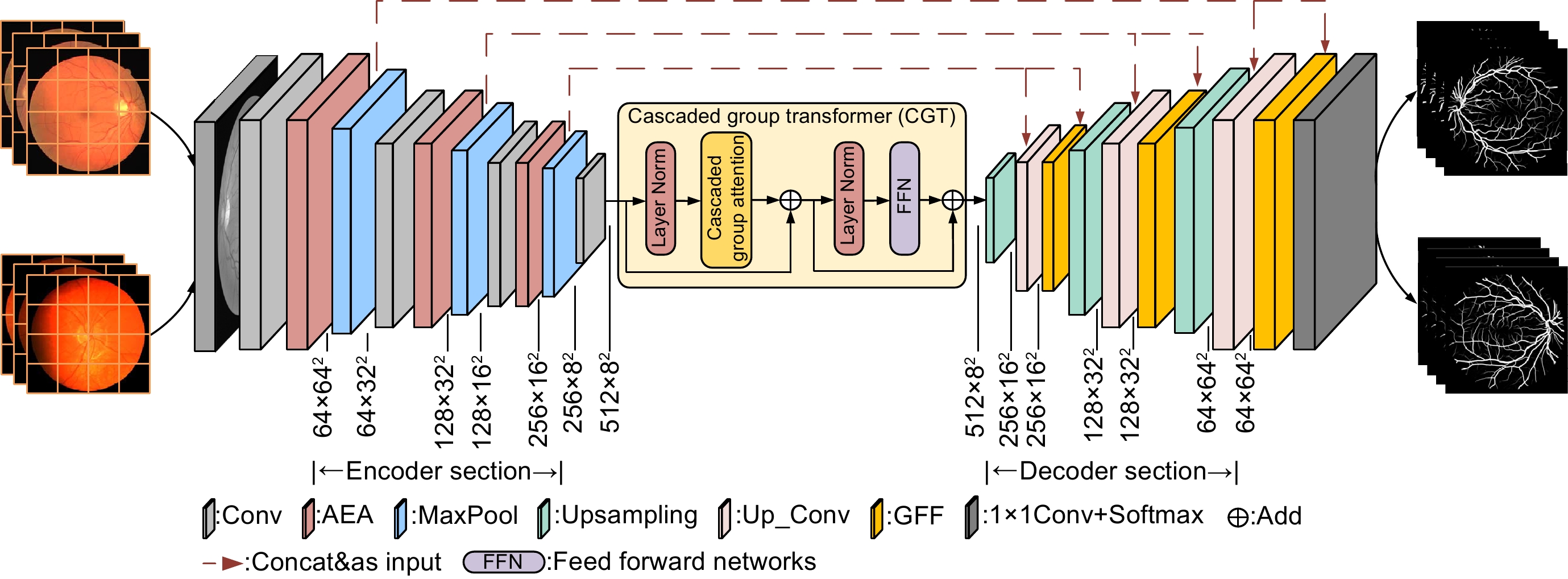
图 1 自适应特征融合级联Transformer视网膜血管分割算法
Figure 1. Adaptive feature fusion cascade Transformer retinal vessel segmentation algorithm
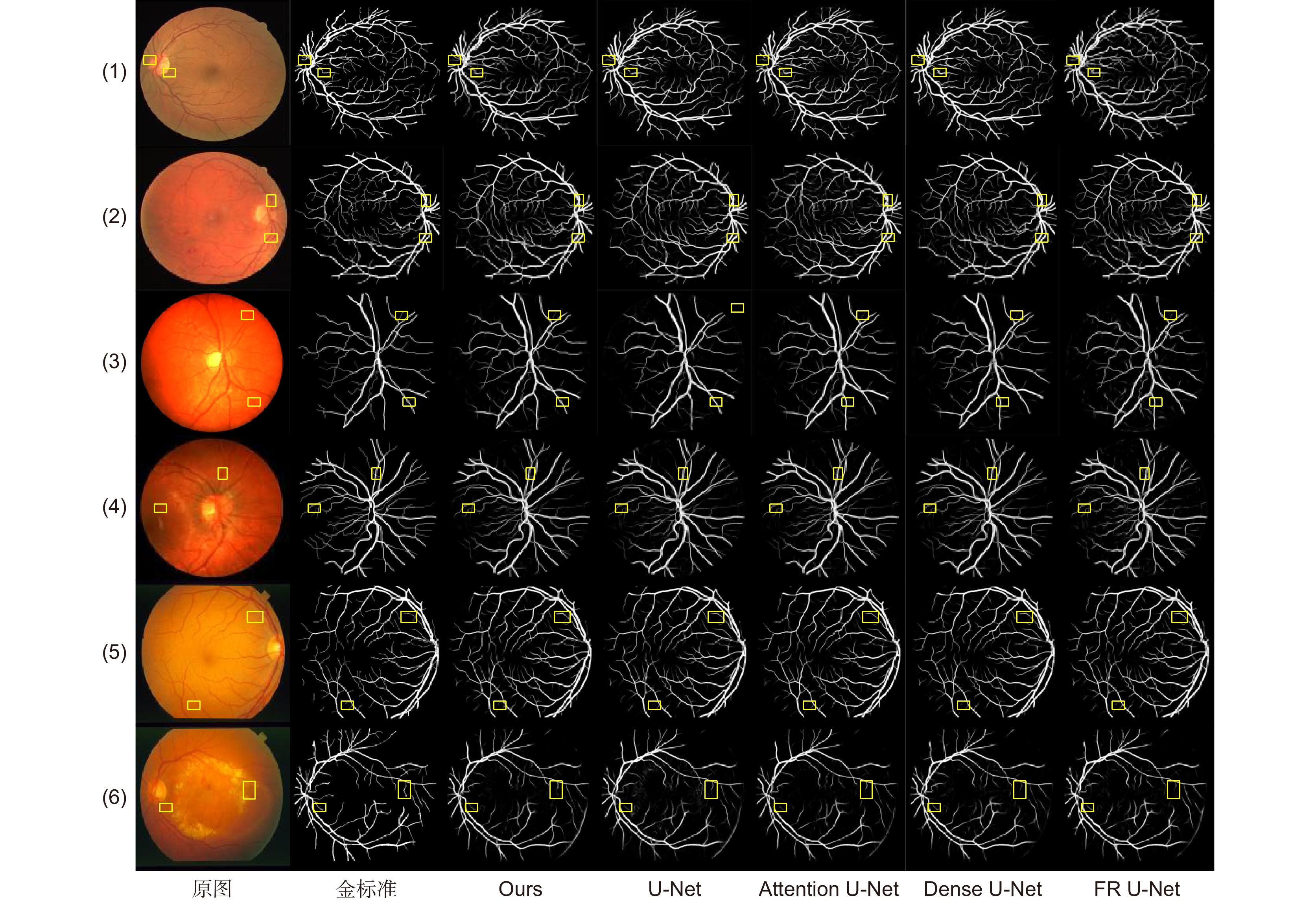
图 8 不同算法视网膜血管分割结果
Figure 8. Results of retinal vessel segmentation by different algorithms
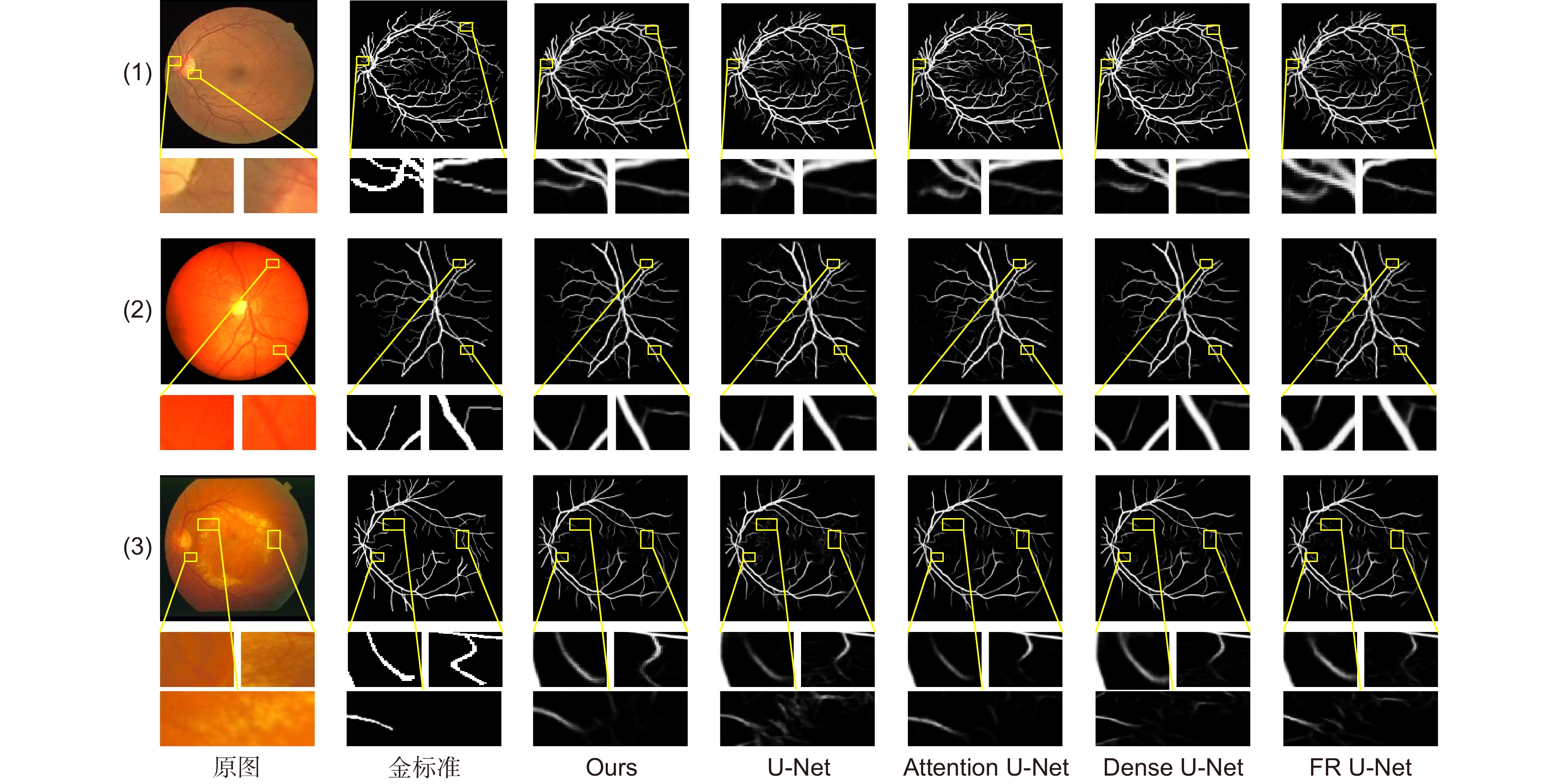
图 9 不同算法视网膜血管局部分割图像
Figure 9. Image of retinal blood vessel local segmentation by different algorithms
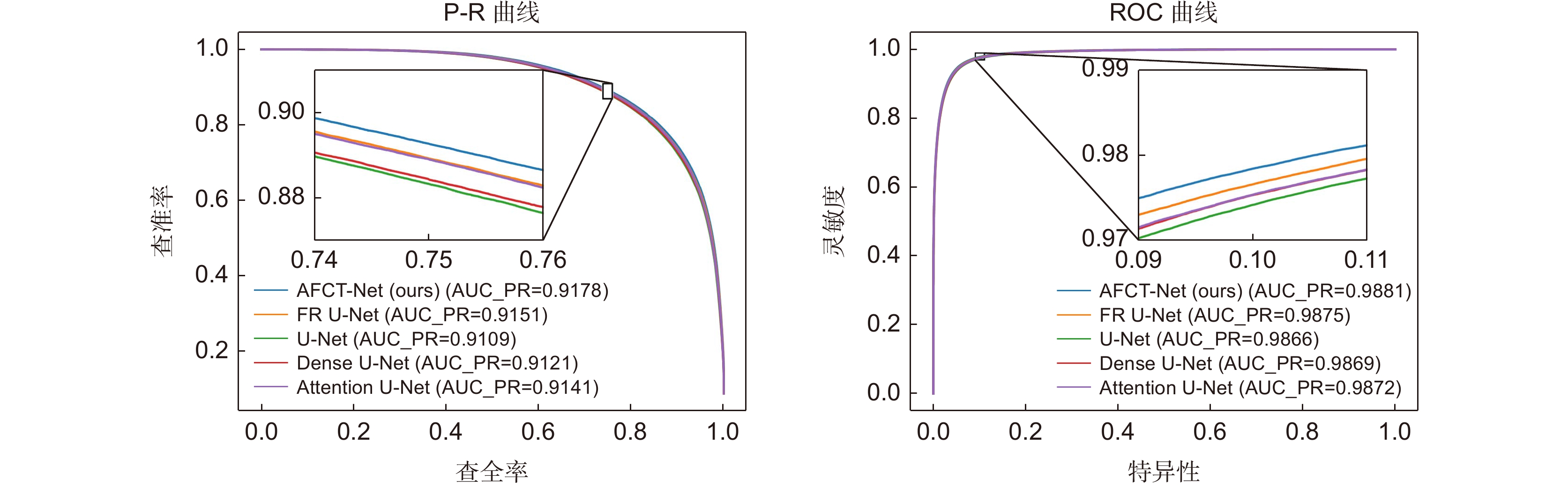
图 10 不同算法在DRIVE数据集P-R曲线与ROC曲线对比图
Figure 10. Comparison between P-R curve and ROC curve of different algorithms in DRIVE dataset
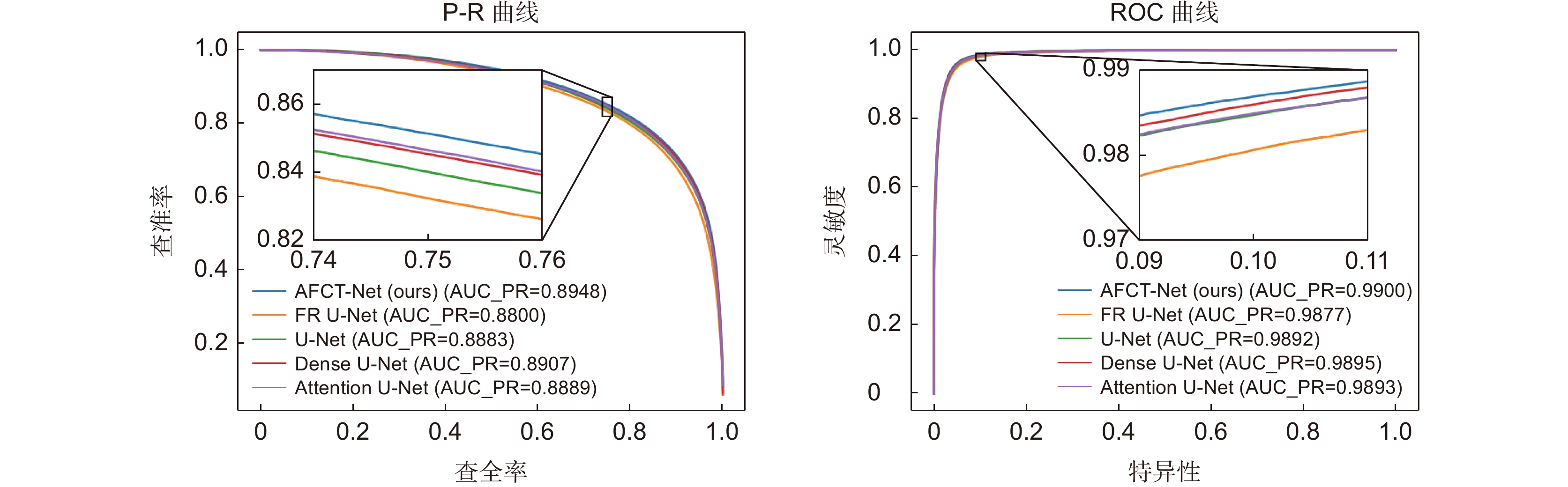
图 11 不同算法在CHASE_DB1数据集P-R曲线与ROC曲线对比图
Figure 11. Comparison between P-R curve and ROC curve of different algorithms in CHASE_DB1 dataset
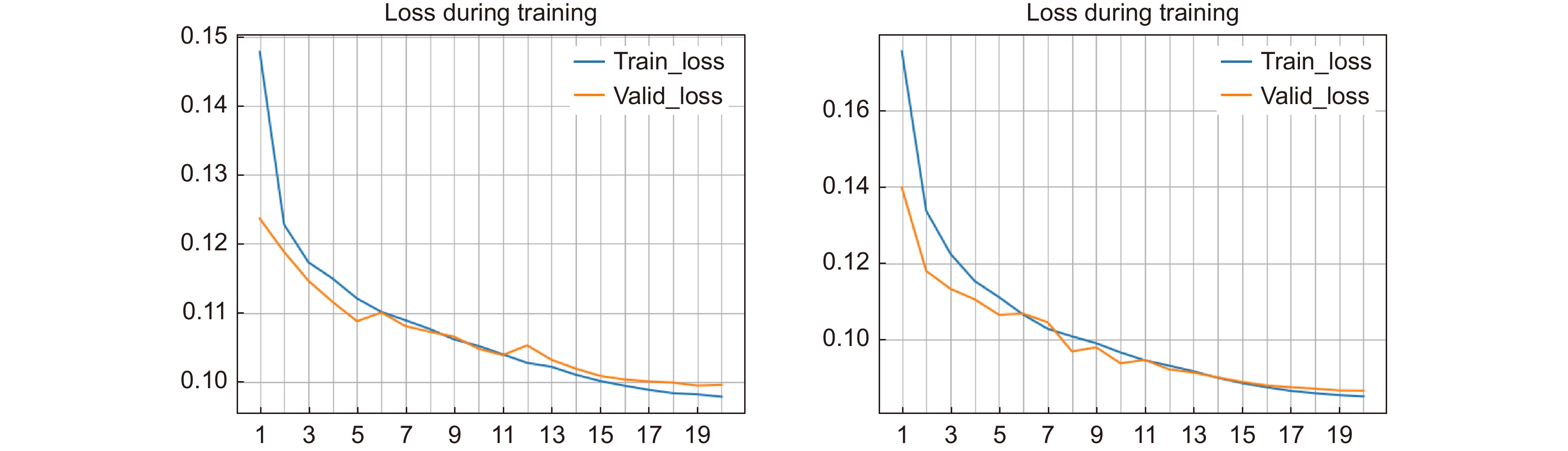
图 12 DRIVE数据集和CHASE_DB1数据集中训练损失曲线图
Figure 12. Plot of training loss curves in DRIVE dataset and CHASE_DB1 dataset
表 1 DRIVE数据集不同算法性能指标/%
Table 1. Performance metrics of different algorithms for the DRIVE dataset /%
数据集 方法 Acc Sen Spe F1 AUC
DRIVEU-Net 96.97 80.19 98.58 82.26 98.66 Attention U-Net 97.04 79.19 98.75 82.41 98.72 Dense U-Net 96.99 79.60 98.66 82.25 98.69 FR U-Net 97.04 78.96 98.78 82.42 98.74 Ours 97.09 80.38 98.69 82.87 98.81  下载: 导出CSV
下载: 导出CSV
表 2 CHASE_DB1数据集不同算法性能指标/%
Table 2. Performance metrics of different algorithms for the CHASE-DB1 dataset /%
数据集 方法 Acc Sen Spe F1 AUC
CHASE_DB1U-Net 97.50 80.79 98.62 80.32 98.92 Attention U-Net 97.57 78.99 98.82 80.43 98.92 Dense U-Net 97.53 81.51 98.54 80.80 98.95 FR U-Net 97.44 80.28 98.60 79.85 98.76 Ours 97.60 81.05 98.71 81.02 98.99
下载: 导出CSV
表 3 STARE数据集不同算法性能指标/%
Table 3. Performance metrics of different algorithms for the STARE dataset /%
数据集 方法 Acc Sen Spe F1 AUC
STAREU-Net 97.53 79.22 99.06 83.15 99.05 Attention U-Net 97.55 78.98 99.09 83.17 99.06 Dense U-Net 97.55 79.68 99.05 83.36 99.09 FR U-Net 97.51 79.84 98.96 82.99 99.01 Ours 97.57 80.32 98.99 83.42 99.10
下载: 导出CSV
表 7 DRIVE数据集消融实验分析/%
Table 7. Analysis of ablation experiments on the DRIVE dataset /%
模型 Acc Sen Spe F1 AUC S1 96.97 80.19 98.58 82.26 98.66 S2 97.06 79.69 98.73 82.62 98.75 S3 97.06 78.18 98.87 82.36 98.87 S4 97.09 80.38 98.69 82.87 98.81
下载: 导出CSV
表 8 CHASE_DB1数据集消融实验分析/%
Table 8. Analysis of ablation experiments on the CHASE-DB1 dataset /%
模型 Acc Sen Spe F1 AUC S1 97.50 80.79 98.62 80.32 98.66 S2 97.55 79.01 98.80 80.31 98.95 S3 97.59 80.52 98.74 80.85 98.99 S4 97.60 81.05 98.71 81.02 98.99
下载: 导出CSV
表 9 SATRE数据集消融实验分析/%
Table 9. Analysis of ablation experiments on the STARE dataset /%
模型 Acc Sen Spe F1 AUC S1 97.53 79.22 99.06 83.15 99.05 S2 97.55 79.38 99.04 83.16 99.04 S3 97.55 79.90 99.01 83.32 99.08 S4 97.57 80.32 98.99 83.42 99.10
下载: 导出CSV
-
参考文献
[1] 梁礼明, 周珑颂, 陈鑫, 等. 鬼影卷积自适应视网膜血管分割算法[J]. 光电工程, 2021, 48(10): 210291. doi: 10.12086/oee.2021.210291
Liang L M, Zhou L S, Chen X, et al. Ghost convolution adaptive retinal vessel segmentation algorithm[J]. Opto-Electron Eng, 2021, 48(10): 210291. doi: 10.12086/oee.2021.210291
[2] 梁礼明, 阳渊, 何安军, 等. 跨级可变形Transformer编解码视网膜图像分割算法[J]. 无线电工程, 2023, 53(9): 1990−2001. doi: 10.3969/j.issn.1003-3106.2023.09.002
Liang L M, Yang Y, He A J, et al. Cross-stage deformable transformer encoding and decoding algorithm for retinal image segmentation[J]. Radio Eng, 2023, 53(9): 1990−2001. doi: 10.3969/j.issn.1003-3106.2023.09.002
[3] 梁礼明, 董信, 李仁杰, 等. 基于注意力机制多特征融合的视网膜病变分级算法[J]. 光电工程, 2023, 50(1): 220199. doi: 10.12086/oee.2023.220199
Liang L M, Dong X, Li R J, et al. Classification algorithm of retinopathy based on attention mechanism and multi feature fusion[J]. Opto-Electron Eng, 2023, 50(1): 220199. doi: 10.12086/oee.2023.220199
[4] 吕佳, 王泽宇, 梁浩城. 边界注意力辅助的动态图卷积视网膜血管分割[J]. 光电工程, 2023, 50(1): 220116. doi: 10.12086/oee.2023.220116
Lv J, Wang Z Y, Liang H C. Boundary attention assisted dynamic graph convolution for retinal vascular segmentation[J]. Opto-Electron Eng, 2023, 50(1): 220116. doi: 10.12086/oee.2023.220116
[5] Vlachos M, Dermatas E. Multi-scale retinal vessel segmentation using line tracking[J]. Comput Med Imaging Graph, 2010, 34(3): 213−227. doi: 10.1016/j.compmedimag.2009.09.006
[6] Azzopardi G, Strisciuglio N, Vento M, et al. Trainable COSFIRE filters for vessel delineation with application to retinal images[J]. Med Image Analy, 2015, 19(1): 46−57. doi: 10.1016/j.media.2014.08.002
[7] 王晓红, 赵于前, 廖苗, 等. 基于多尺度2D Gabor小波的视网膜血管自动分割[J]. 自动化学报, 2015, 41(5): 970−980. doi: 10.16383/j.aas.2015.c140185
Wang X H, Zhao Y Q, Liao M, et al. Automatic segmentation for retinal vessel based on multi-scale 2D Gabor wavelet[J]. Acta Autom Sin, 2015, 41(5): 970−980. doi: 10.16383/j.aas.2015.c140185
[8] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, 2015: 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965.
[9] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation[C]//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, 2015: 234–241. https://doi.org/10.1007/978-3-319-24574-4_28.
[10] Bakas S, Reyes M, Jakab A, et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge[Z]. arXiv: 1811.02629, 2018. https://doi.org/10.48550/arXiv.1811.02629.
[11] Heller N, Sathianathen N, Kalapara A, et al. The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgical outcomes[Z]. arXiv: 1904.00445, 2019. https://doi.org/10.48550/arXiv.1904.00445.
[12] Li Y, Zhang Y, Cui W G, et al. Dual encoder-based dynamic-channel graph convolutional network with edge enhancement for retinal vessel segmentation[J]. IEEE Trans Med Imag, 2022, 41(8): 1975−1989. doi: 10.1109/TMI.2022.3151666
[13] Wang X, Li Z S, Huang Y P, et al. Multimodal medical image segmentation using multi-scale context-aware network[J]. Neurocomputing, 2022, 486: 135−146. doi: 10.1016/j.neucom.2021.11.017
[14] Yang B, Qin L, Peng H, et al. SDDC-Net: A U-shaped deep spiking neural P convolutional network for retinal vessel segmentation[J]. Digital Signal Process, 2023, 136: 104002. doi: 10.1016/j.dsp.2023.104002
[15] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, 2017: 6000–6010. https://dl.acm.org/doi/10.5555/3295222.3295349
[16] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]//Proceedings of the 9th International Conference on Learning Representations, 2021.
[17] Liu X Y, Peng H W, Zheng N X, et al. EfficientViT: memory efficient vision transformer with cascaded group attention[C]//Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, 2023: 14420–14430. https://doi.org/10.1109/CVPR52729.2023.01386.
[18] Azad R, Jia Y W, Aghdam E K, et al. Enhancing medical image segmentation with TransCeption: a multi-scale feature fusion approach[Z]. arXiv: 2301.10847, 2023. https://doi.org/10.48550/arXiv.2301.10847.
[19] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[20] Ni J J, Sun H Z, Xu J X, et al. A feature aggregation and feature fusion network for retinal vessel segmentation[J]. Biomed Signal Process Control, 2023, 85: 104829. doi: 10.1016/j.bspc.2023.104829
[21] Zhang R F, Liu S S, Yu Y Z, et al. Self-supervised correction learning for semi-supervised biomedical image segmentation[C]//Proceedings of the 24th International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, 2021: 134–144. https://doi.org/10.1007/978-3-030-87196-3_13.
[22] Oktay O, Schlemper J, Folgoc L L, et al. Attention U-Net: Learning where to look for the pancreas[Z]. arXiv: 1804.03999, 2018. https://doi.org/10.48550/arXiv.1804.03999.
[23] Wang C, Zhao Z Y, Ren Q Q, et al. Dense U-net based on patch-based learning for retinal vessel segmentation[J]. Entropy, 2019, 21(2): 168. doi: 10.3390/e21020168
[24] Liu W T, Yang H H, Tian T, et al. Full-resolution network and dual-threshold iteration for retinal vessel and coronary angiograph segmentation[J]. IEEE J Biomed Health Inform, 2022, 26(9): 4623−4634. doi: 10.1109/JBHI.2022.3188710
[25] Zhang H B, Zhong X, Li Z J, et al. TiM-Net: transformer in M-Net for retinal vessel segmentation[J]. J Healthcare Eng, 2022, 2022: 9016401. doi: 10.1155/2022/9016401
[26] Tchinda B S, Tchiotsop D, Noubom M, et al. Retinal blood vessels segmentation using classical edge detection filters and the neural network[J]. Inf Med Unlocked, 2021, 23: 100521. doi: 10.1016/j.imu.2021.100521
[27] Du X F, Wang J S, Sun W Z. UNet retinal blood vessel segmentation algorithm based on improved pyramid pooling method and attention mechanism[J]. Phys Med Biol, 2021, 66(17): 175013. doi: 10.1088/1361-6560/ac1c4c
[28] Khan T M, Khan M A U, Rehman N U, et al. Width-wise vessel bifurcation for improved retinal vessel segmentation[J]. Biomed Signal Process Control, 2022, 71: 103169. doi: 10.1016/j.bspc.2021.103169
[29] Guo S. CSGNet: Cascade semantic guided net for retinal vessel segmentation[J]. Biomed Signal Process Control, 2022, 78: 103930. doi: 10.1016/j.bspc.2022.103930
[30] Li X, Jiang Y C, Li M L, et al. Lightweight attention convolutional neural network for retinal vessel image segmentation[J]. IEEE Trans Ind Inf, 2021, 17(3): 1958−1967. doi: 10.1109/TII.2020.2993842
[31] Yang X, Li Z Q, Guo Y Q, et al. DCU-net: A deformable convolutional neural network based on cascade U-net for retinal vessel segmentation[J]. Multimedia Tools Appl, 2022, 81(11): 15593−15607. doi: 10.1007/s11042-022-12418-w
[32] Khan T M, Naqvi S S, Robles-Kelly A, et al. Retinal vessel segmentation via a Multi-resolution Contextual Network and adversarial learning[J]. Neural Netw, 2023, 165: 310−320. doi: 10.1016/j.neunet.2023.05.029
-
访问统计

 点击扫一扫
点击扫一扫
图(13)
表(9)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


