
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
基于卷积神经网络(CNN)的识别器,由于其高识别率已经在人脸识别中广泛应用,但其滥用也带来隐私保护问题。本文提出了局部背景区域的人脸对抗攻击(BALA),可以作为一种针对CNN人脸识别器的隐私保护方案。局部背景区域添加扰动克服了现有方法在前景人脸区域添加扰动所导致的原始面部特征损失的缺点。BALA使用了两阶段损失函数以及灰度化、均匀化方法,在更好地生成对抗块的同时提升了数字域到物理域的对抗效果。在照片重拍和场景实拍实验中,BALA对VGG-FACE人脸识别器的攻击成功率(ASR)比现有方法分别提升12%和3.8%。
Abstract
Recognizers based on the convolutional neural networks (CNN) have been widely used in face recognition because of their high recognition rate. But its abuse also brings privacy protection problems. In this paper, we propose a local background area-based face confrontation attack (BALA), which can be used as a privacy protection scheme for CNN face recognizer. Adding disturbance in the local background region overcomes the loss of original facial features caused by adding disturbance to the foreground face region in existing methods. BALA uses a two-stage loss function, graying, and homogenization methods to better generate adversarial blocks and improve the adversarial effect after digital to physical domain conversion. In the photo retake and live shot experiments, BALA's attack success rate (ASR) against the VGG-FACE face recognizer is more than 12% and 3.8% higher than the current methods.
-
Key words:
- face recognition /
- CNN /
- adversarial attack /
- background /
- physical domain
-
Overview
Overview: At present, face recognition has been integrated into every aspect of everyone’s life, which makes face privacy protection an important topic. Face image recognizers based on convolutional neural networks (CNN) have been widely used, but CNN-based image classifiers are easily misled by adversarial examples with special human perturbations, resulting in the false label. However, many physical facial adversarial generation methods used obvious perturbation patterns in the foreground leading to hampering a clear face observation. Therefore, using physical background perturbation patches may be a suitable way to not only against illegal face recognizers but also keep clear face observation.
Taking advantage of the fact that adversarial examples can interfere with CNN face recognizers, this paper proposes a privacy protection scheme for intelligent face recognizers. In order to overcome the loss of original facial features caused by the addition of significant perturbation patches in the foreground face area by existing adversarial example generation methods, this paper adds background adversarial perturbation blocks in the physical domain, so as to achieve anti-unauthorized face recognition while maintaining all original facial features. Specifically, this paper proposes a novel adversarial perturbation patches generation and addition method, called Facial Adversarial Background Attack in a Limited Area (BALA). To the best of our knowledge, BALA is the first method to mislead face recognizers by modifying real local background regions.
The innovation of this paper is that (1) BALA optimizes the gradient back-propagation efficiency by using different loss functions in two iterative stages, so as to better generate perturbation patches; (2) BALA uses adversarial region grayscale and averaging to strengthen adversarial effects after digital to physical domain conversion. In experiments, the adversarial patches displayed on the background screen can mislead the VGG-FACE face recognizer without covering any face area, and the adversarial patch area is only 8.4% of the face detection area. In the photo retake experiment, BALA improves the attack success rate (ASR) by 12% compared with Adv-patch and LaVAN methods, and in the live shot experiment, BALA's ASR is 3.8% higher than Adv-patch. These results demonstrate that our proposed BALA has leading performance in adversarial attacks against background faces in the physical domain.
-

-
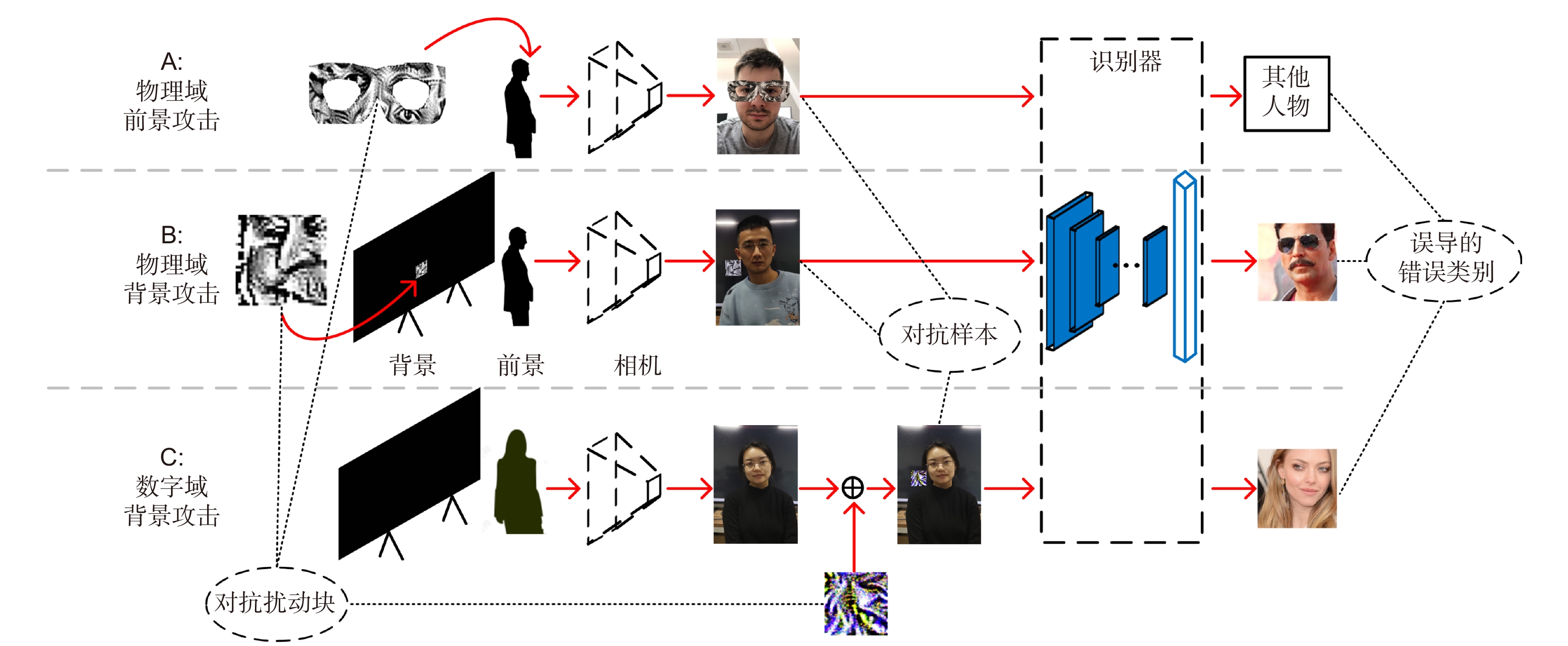
图 1 人脸对抗攻击流程图。板块A带有扰动块(来自于Mikhail等人[19]的补丁图片)的物理域前景攻击;板块B为物理域背景攻击;板块C为数字域背景攻击。每种攻击方法目的在于使用对抗样本误导人脸识别器从而产生错误的分类结果
Figure 1. Scheme of facial adversarial attacks. Panel A is a physical foreground attack with an adversarial patch (patch image from Mikhail et al.[19]); Panel B is a physical adversarial background attack, and panel C is a digital adversarial background attack. Every attack approach aims to mislead a face recognizer with an incorrect class using adversarial examples
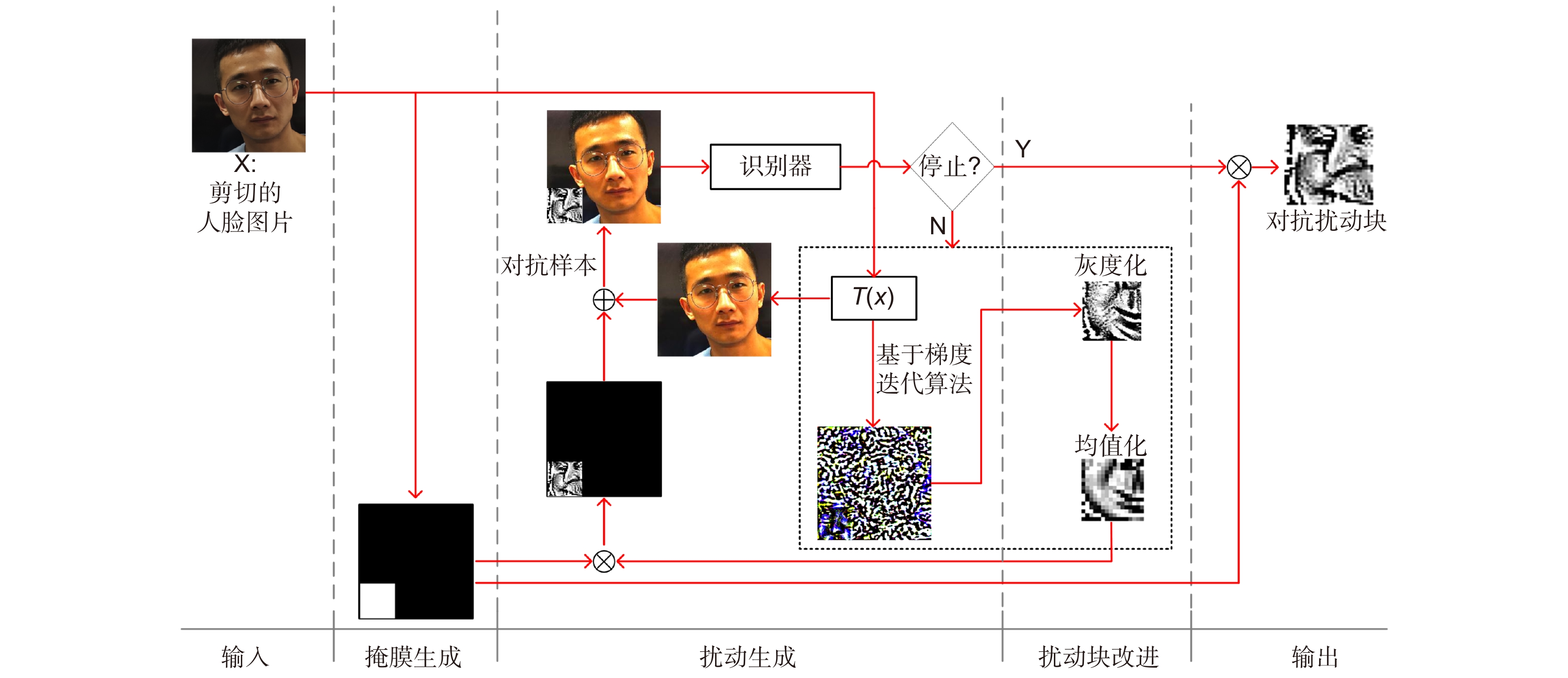
图 2 BALA产生一个对抗扰动块的流程。主要包括三个部分,分别是掩膜生成、扰动生成和扰动块的改进。T(•)表示一系列的物理变换
Figure 2. The scheme of generating an adversarial patch in BALA. This scheme mainly consists of three parts, mask generation, perturbation generation, and perturbation further improving. T(•) represents a set of transformations
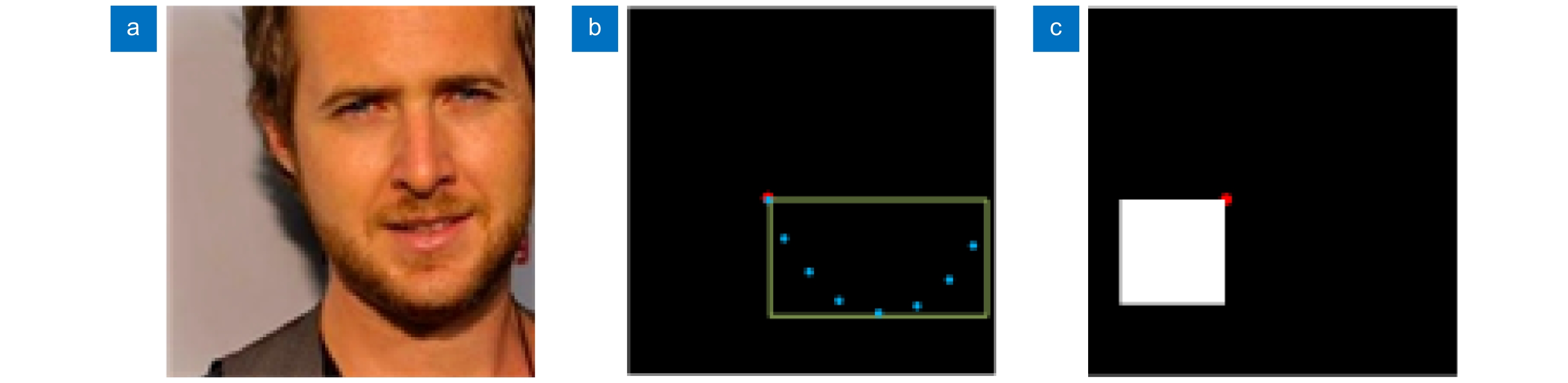
图 3 掩膜制作的示例。(a) 为一张裁剪的人脸图片;(b) 蓝色的点是脸部轮廓下颌线的采样点,绿色的线代表其最大外接矩形框;(c) 带有白色补丁的掩膜,白色补丁代表着对抗扰动块的位置,红色的点代表具体的候选点
Figure 3. The illustration of mask generation. (a) Cropped face image; (b) Blue points are mandible points of the face, and the green lines represent the maximum outside rectangular; (c) The mask with a white patch represents the location of an adversarial patch, and the red point represents the specific candidate

图 4 对抗扰动块的产生过程,在迭代过程中使用两种不同的损失函数。 ${{{L}}_{{\text{s1}}}}$ 和 ${{{L}}_{{\text{s2}}}}$ 分别从步骤1到步骤2(${p_{{{{y}}_{{\text{org}}}}}}$)和从步骤2到步骤3(${p_{{{{y}}_{{\text{anh}}}}}}$)的过程中的损失函数,并在点2处从 ${p_{{y_{{\text{org}}}}}}$ 到 ${p_{{y_{{\text{anh}}}}}}$ 的跳变
Figure 4. The generation process of an adversarial patch. Two different loss functions are used in iterations. ${{{L}}_{{\text{s1}}}}$ and ${{{L}}_{{\text{s2}}}}$ are used in stage of step 1 to step 2 (${p_{{{{y}}_{{\text{org}}}}}}$) and step 2 to step 3 (${p_{{y_{{\text{anh}}}}}}$), respectively. There is a change of ${p_{{y_{{\text{org}}}}}}$ to ${p_{{y_{{\text{anh}}}}}}$ at point 2

图 5 不同的BALA对抗扰动块。(a) 不带灰度化和均一化的彩色块;(b) 不带均一化的灰度块;(c) 带均一化的灰度块;(d), (e), (f) 分别对应(a),(b),(c)的屏幕重拍照片
Figure 5. The diverse BALA adversarial patches. (a) Generated color patch without graying and averaging; (b) Generated gray patch without averaging; (c) Generated gray patch with averaging; Images (d), (e), (f) are corresponding re-taken images (a), (b), (c), respectively

图 6 场景实拍实验设置。A为相机,B为三脚架,C为电子背景屏幕,D为前景人物
Figure 6. The real-world experiment setup. A is a camera and B is the tripod; C is the electronic screen background and D is the foreground person

图 7 两种背景对抗攻击实验的流程图。蓝色部分是照片重拍实验,绿色部分是场景实拍实验
Figure 7. The pipeline of two background adversarial attack experiments. The blue part is photo re-taken experiment and green part is the real-world experiment

图 8 在照片重拍实验中,LaVAN,BALA和Adv-patch三种方法生成的对抗样本。(a) 是原始人脸图片;(b) 表示将对抗扰动块显示到背景屏幕后重拍的照片;(c) 表示由VGG-FACE识别的错误类别对应的图像
Figure 8. The adversarial examples generated by LaVAN, BALA, and Adv-patch in re-taken experiment. (a) is the original face image; (b) Present re-taking photos after displaying the adversarial patches on the background; (c) Present images of incorrect output classes from the VGG-FACE

图 9 通过BALA在场景实拍实验中产生的对抗样本。(a) 原始照片;(b) 将扰动块添加到背景后重新拍摄的照片;(c) 剪切人脸之后的对抗样本;(d) VGG-FACE网络输出的错误分类对应的人脸
Figure 9. The adversarial examples generated by BALA in the real-world experiment. (a) The original photos; (b) Present re-taking photos after displaying the adversarial patches on the background; (c) Present adversarial examples from the cropped faces; (d) Present face images of incorrect output classes of the VGG-FACE network

图 10 采用灰度化BALA生成不同的均值对抗扰动块。(a) 无均值法生成的扰动块;(b) 采用2×2邻域均值化生成的扰动块;(c) 采用4×4邻域均值化生成的扰动块
Figure 10. The diverse averaging images of BALA with graying. (a) Generated patch using no averaging approach; (b) Generated patch by averaging pixels in 2 × 2 region; (c) Generated patch by averaging pixels in 4 × 4 region
算法1:BALA中生成对抗扰动块 输入:图片${\boldsymbol{x}}$,模型${\text{F}}$,掩膜${\boldsymbol{M}}$,$\varepsilon $,概率阈值s,迭代次数上限$ C $,变换集合$ T $ 输出:扰动块(${\boldsymbol{patch}}$) $\text { counter }=0,\;\; l_{\text {org }}=y(\mathrm{~F}, \boldsymbol{x}), \quad \boldsymbol{\delta}=\boldsymbol{0}, \quad \text { patch }=0.5 * \operatorname{crop}(\boldsymbol{M})$ $\boldsymbol{x}^{\prime}=(\boldsymbol{1}-\boldsymbol{M}) * {~T}(\boldsymbol{x})+\boldsymbol{M} \cdot \boldsymbol{\delta}, \quad l_{\text {pred }}=y(\mathrm{~F}, \boldsymbol{x})$ ${ {\bf{while}}\;\; {\rm{counter}} } < C \text { do }$ ${\bf{ if }} \; l_{\text {org }}==l_{\text {pred }} \quad {\bf{ then }}$ ${L}={L}_{\mathrm{s} 1}$ ${ {\bf{else}} \;\; {\bf{if}} } \; \; l_{\text {anh}}==l_{\text {pred }} { {\bf{then}} }$ ${L}={L}_{\mathrm{s} 2}$ $\boldsymbol{\delta}=\varepsilon * \operatorname{sign}\left(\partial L / \partial \boldsymbol{x}^{\prime}\right)$$\boldsymbol{p a t c h}^{\prime}=\operatorname{graying}\left(\boldsymbol{p a t c h}+ \operatorname{crop} \left(\boldsymbol{M} \cdot \boldsymbol{\delta}\right)\right)$ $\text { patch }=\text { averaging }\left(\text { patch }^{\prime}\right), $$\boldsymbol{p a t c h}^{\prime}=\operatorname{graying} (\boldsymbol{p a t c h}+\operatorname{crop} (\boldsymbol{M} \cdot \boldsymbol{\delta}))$ $l_{ {{\bf{pred}} }}=y\left(\mathrm{~F}, \boldsymbol{x}^{\prime}\right), { counter }++$ ${ {\bf{if}} } \quad p_{y_{\text {pee }}}\left(\mathrm{F}, \boldsymbol{x}^{\prime}\right) > s & l_{\text {org }} \neq l_{\text {pred }} { {\bf{then}} }$ break  下载: 导出CSV
下载: 导出CSV
表 1 在集合A2中照片重拍的平均ASR(%)
Table 1. Photo re-taken experiment results over set-A1 in terms of average ASR(%)
下载: 导出CSV
表 2 在集合A1中,场景实拍实验中前景和背景屏幕之间不同距离的平均ASR(%)
Table 2. Average ASR (%) of the different distance between foreground face and background screen in real-world experiments over set-A1
10 cm 20 cm 50 cm Adv-patch[16] 61.2 56.3 51.2 BALA 75.0 69.2 62.4
下载: 导出CSV
表 3 集合A中BALA的均一化作用下的平均ASR(%)
Table 3. The results of averaging effect of BALA over set-A in terms of average ASR(%)
BALA BALA-Color 无均值 2×2 4×4 2×2 数字攻击 98.7 94.6 75.4 97.2 照片重拍 71.5 78.0 70.2 66.3 场景实拍攻击 62.4 69.2 60.3 55.4
下载: 导出CSV
-
参考文献
[1] Lee S, Woo T, Lee S H. SBNet: segmentation-based network for natural language-based vehicle search[C]//2021IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2021: 4049−4055. https://doi.org/10.1109/CVPRW53098.2021.00457.
[2] 孙锐, 单晓全, 孙琦景, 等. 双重对比学习框架下近红外[J]. 光电工程, 2022, 49(4): 210317. doi: 10.12086/oee.2022.210317
Sun R, Shan X Q, Sun Q J, et al. NIR-VIS face image translation method with dual contrastive learning framework[J]. Opto-Electron Eng, 2022, 49(4): 210317. doi: 10.12086/oee.2022.210317
[3] Meng Q E, Shin'ichi S. ADINet: attribute driven incremental network for retinal image classification[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4032–4041. https://doi.org/10.1109/CVPR42600.2020.00409.
[4] Singh V, Hari S K S, Tsai T, et al. Simulation driven design and test for safety of AI based autonomous vehicles[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2021: 122−128. https://doi.org/10.1109/CVPRW53098.2021.00022.
[5] Liao M H, Zheng S S, Pan S X, et al. Deep-learning-based ciphertext-only attack on optical double random phase encryption[J]. Opto-Electron Adv, 2021, 4(5): 200016. doi: 10.29026/oea.2021.200016
[6] Ma T G, Tobah M, Wang H Z, et al. Benchmarking deep learning-based models on nanophotonic inverse design problems[J]. Opto-Electron Sci, 2022, 1(1): 210012. doi: 10.29026/oes.2022.210012
[7] Raji I D, Fried G. About face: a survey of facial recognition evaluation[Z]. arXiv: 2102.00813, 2021. https://arxiv.org/abs/2102.00813.
[8] Pesent J. An update on our use of face recognition[EB/OL]. (2021-11-02). https://about.fb.com/news/2021/11/update-on-use-of-face-recognition/.
[9] Sun Q R, Ma L Q, Oh S J, et al. Natural and Effective Obfuscation by Head Inpainting[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 5050–5059. https://doi.org/10.1109/CVPR.2018.00530.
[10] Wright E. The future of facial recognition is not fully known: developing privacy and security regulatory mechanisms for facial recognition in the retail sector[J]. Fordham Intell Prop Media Ent L J, 2019, 29: 611.
[11] Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[C]//2nd International Conference on Learning Representations, 2014.
[12] Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks[C]//6th International Conference on Learning Representations, 2018.
[13] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[C]//3rd International Conference on Learning Representations, 2015.
[14] Karmon D, Zoran D, Goldberg Y. LaVAN: localized and visible adversarial noise[C]//Proceedings of the 35th International Conference on Machine Learning, 2018: 2512–2520.
[15] Wu D X, Wang Y S, Xia S T, et al. Skip connections matter: on the transferability of adversarial examples generated with ResNets[C]//8th International Conference on Learning Representations, 2020.
[16] Brown T B, Mané D, Roy A, et al. Adversarial patch[Z]. arXiv: 1712.09665, 2017. https://arxiv.org/abs/1712.09665.
[17] Kurakin A, Goodfellow I J, Bengio S. Adversarial examples in the physical world[C]//5th International Conference on Learning Representations, 2017.
[18] Athalye A, Engstrom L, Ilyas A. Synthesizing robust adversarial examples[C]//Proceedings of the 35th International Conference on Machine Learning, 2018: 284–293.
[19] Pautov M, Melnikov G, Kaziakhmedov E, et al. On adversarial patches: real-world attack on ArcFace-100 face recognition system[C]//2019 International Multi-Conference on Engineering, Computer and Information Sciences, 2019: 391–396.
[20] Komkov S, Petiushko A. AdvHat: real-world adversarial attack on ArcFace face ID system[C]//2020 25th International Conference on Pattern Recognition, 2021: 819–826. https://doi.org/10.1109/ICPR48806.2021.9412236.
[21] Nguyen D L, Arora S S, Wu Y H, et al. Adversarial light projection attacks on face recognition systems: a feasibility study[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 3548−3556. https://doi.org/10.1109/CVPRW50498.2020.00415.
[22] Jan S T K, Messou J, Lin Y C, et al. Connecting the digital and physical world: improving the robustness of adversarial attacks[C]//Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, 2019: 119. https://doi.org/10.1609/aaai.v33i01.3301962.
[23] Moosavi-Dezfooli S M, Fawzi A, Frossard P. DeepFool: a simple and accurate method to fool deep neural networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 2574−2582. https://doi.org/10.1109/CVPR.2016.282.
[24] Su J W, Vargas D V, Sakurai K. One pixel attack for fooling deep neural networks[J]. IEEE Trans Evol Comput, 2019, 23(5): 828−841. doi: 10.1109/TEVC.2019.2890858
[25] Sharif M, Bhagavatula S, Bauer L, et al. Accessorize to a crime: real and stealthy attacks on state-of-the-art face recognition[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016: 1528–1540. https://doi.org/10.1145/2976749.2978392.
[26] Xu K D, Zhang G Y, Liu S J, et al. Adversarial T-shirt! Evading person detectors in a physical world[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 665–681. https://doi.org/10.1007/978-3-030-58558-7_39.
[27] Rahmati A, Moosavi-Dezfooli S M, Frossard P, et al. GeoDA: a geometric framework for black-box adversarial attacks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 8443–8452. https://doi.org/10.1109/CVPR42600.2020.00847.
[28] Sun Y, Wang X G, Tang X O. Deep convolutional network cascade for facial point detection[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition, 2013: 3476–3483. https://doi.org/10.1109/CVPR.2013.446.
[29] Wang J F, Yuan Y, Yu G. Face attention network: an effective face detector for the occluded faces[Z]. arXiv: 1711.07246, 2017. https://arxiv.org/abs/1711.07246.
[30] Parkhi O M, Vedaldi A, Zisserman A. Deep face recognition[C]//Proceedings of the British Machine Vision Conference 2015, 2015: 41.1–41.12.
[31] Peng H Y, Yu S Q. A systematic IoU-related method: beyond simplified regression for better localization[J]. IEEE Trans Image Process, 2021, 30: 5032−5044. doi: 10.1109/TIP.2021.3077144
[32] Duan R J, Ma X J, Wang Y S, et al. Adversarial camouflage: hiding physical-world attacks with natural styles[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 997−1005. https://doi.org/10.1109/CVPR42600.2020.00108.
-
访问统计

 点击扫一扫
点击扫一扫
图(11)
表(4)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


