
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
针对非机动车驾驶员头盔检测任务中常存在复杂背景以及检测场景中存在的检测目标尺寸大小不一的现象,进而导致检测效率低和误检漏检的问题,提出了一种面向非机动车驾驶员的头盔检测的YOLOv8算法。在C2f模块中结合GSConv和CBAM的优点,设计C2f_BC模块,在降低模型参数量的同时,有效提升了模型的特征提取能力。设计了多核并行感知网络 (MP-Parnet),提高了模型对不同尺度目标的感知和特征提取能力,使其能更好地应用到复杂场景中。为缓解复杂场景出现的正负样本不平衡等问题,在原模型损失函数CIoU基础上引入Focaler-IoU,引入阈值参数来改进IoU损失计算方式,从而缓解正负样本的不平衡的现象,有效提升了模型在复杂背景下目标框定位的准确性。实验结果表明,改进的YOLOv8n相较于原模型,在保持参数量下降的同时,mAP50和mAP50∶95在自建数据集Helmet上分别提升了2.2%和1.9%,在开源数据集TWHD上分别提升了1.8%和1.9%,说明改进的模型可以更好地应用到非机动车驾驶员的头盔检测场景。
Abstract
Aiming at the phenomenon that complex background often exists in non-motorized drivers' helmet detection and the diversity of detection target scales often exists in the detection scene, which in turn leads to the low detection efficiency and misdetection and omission, a YOLOv8 algorithm oriented to the detection of traffic helmets is proposed. Combining the advantages of GSConv and CBAM in the C2f module, the C2f_BC module is designed to effectively improve the feature extraction capability of the model while reducing the number of model parameters. A multi-core parallel perception network (MP-Parnet) is designed to improve the model's perception and feature extraction ability for multi-scale targets so that it can be better applied to complex scenes. To alleviate the problem of positive and negative sample imbalance in complex scenes, Focaler-IoU is introduced based on the original model's loss function CIoU, and a threshold parameter is introduced to improve the calculation of the IoU loss, thus alleviating the phenomenon of positive and negative sample imbalance,and effectively improves the model's accuracy of target frame localization in complex background. The experimental results show that compared with the original model, the improved YOLOv8n maintains a decrease in the number of parameters while the mAP50 and mAP50: 95 increase by 2.2% and 1.9% on the self-built dataset Helmet, and 1.8% and 1.9% on the open-source dataset TWHD, which suggests that the improved model can be better applied to the helmet detection of non-motorized drivers in the scenario.
-
Key words:
- object detection /
- YOLOv8 /
- attention mechanism /
- loss function /
- feature extraction
-
Overview
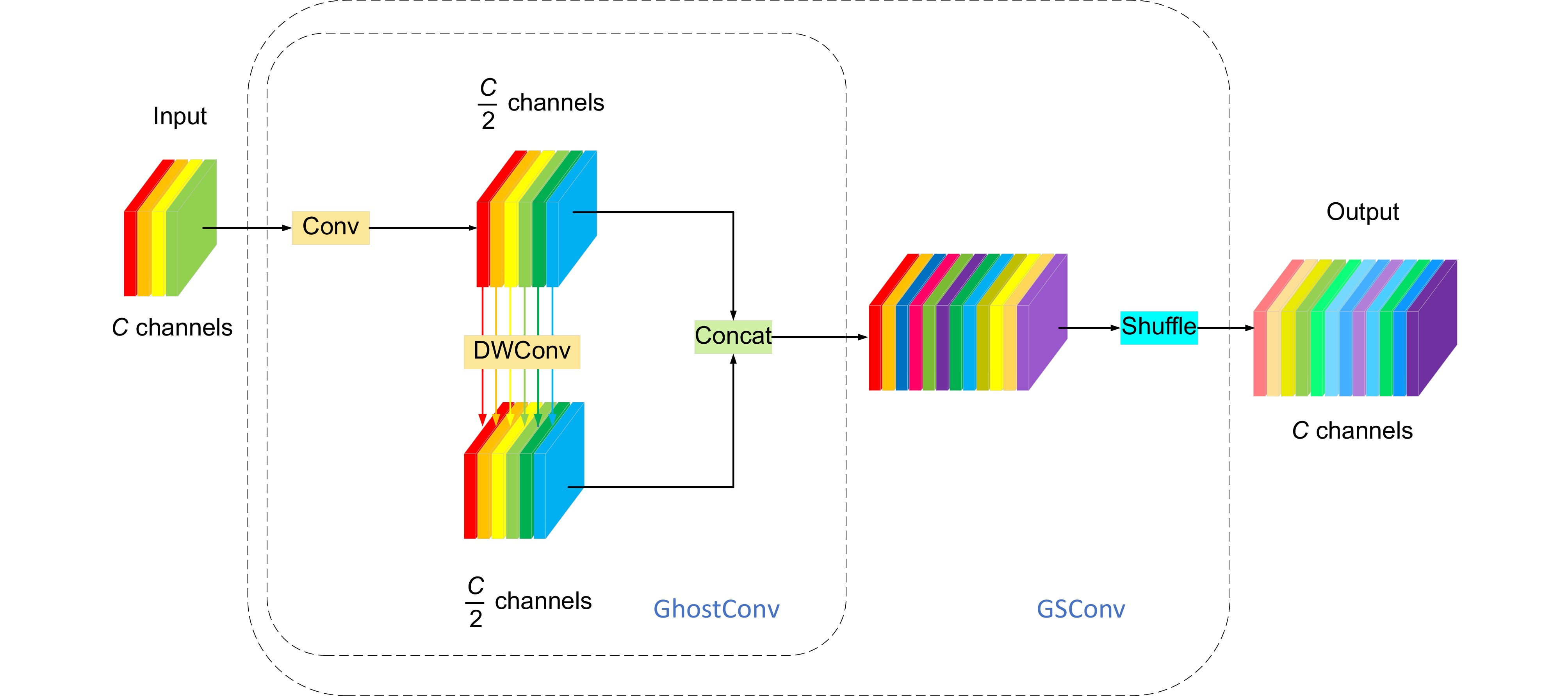
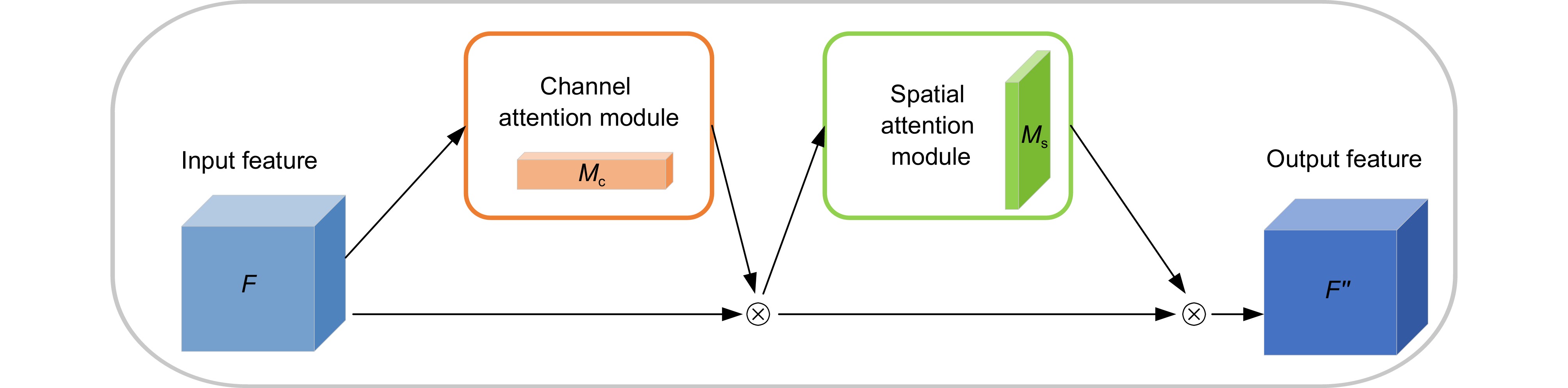
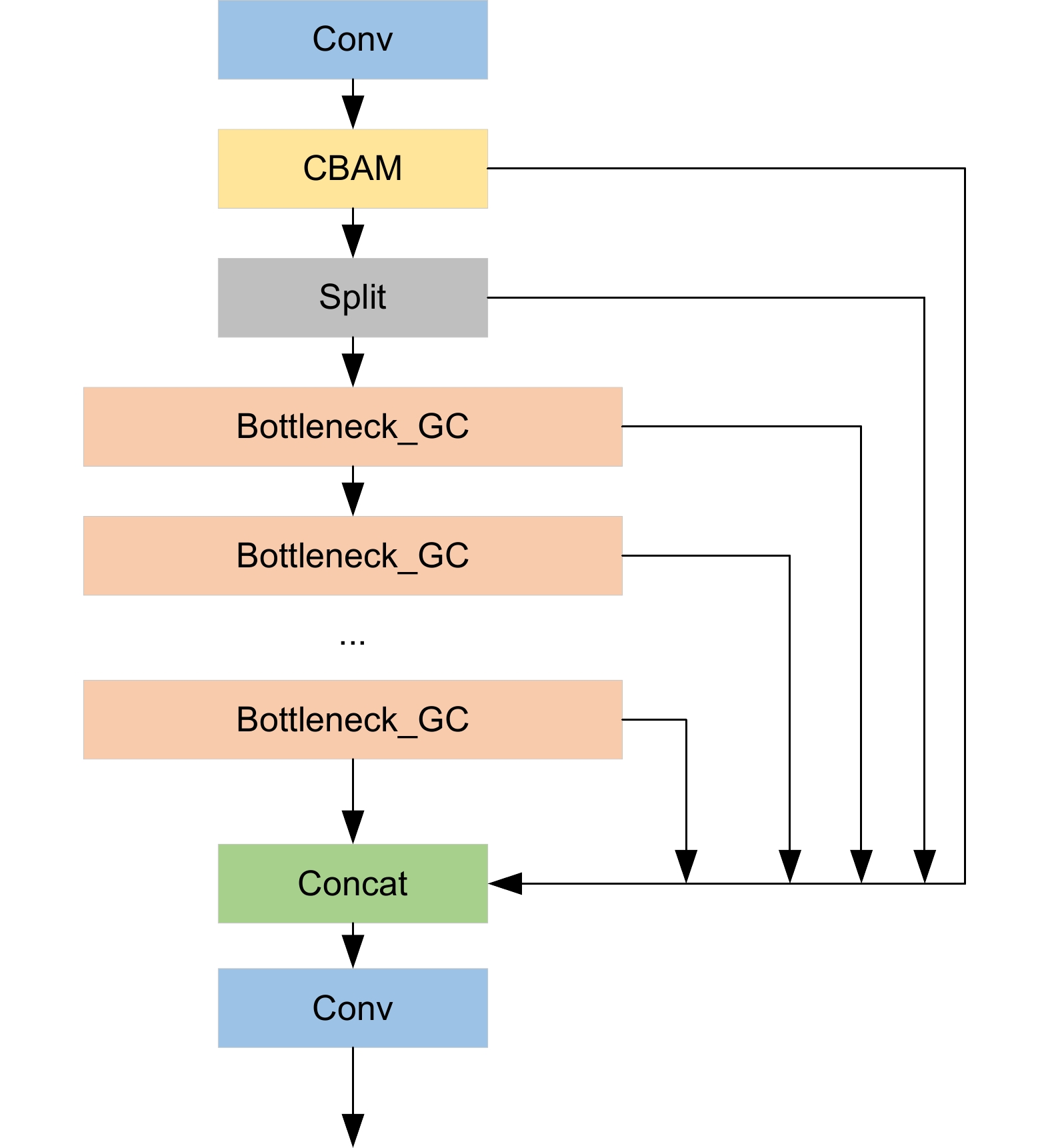
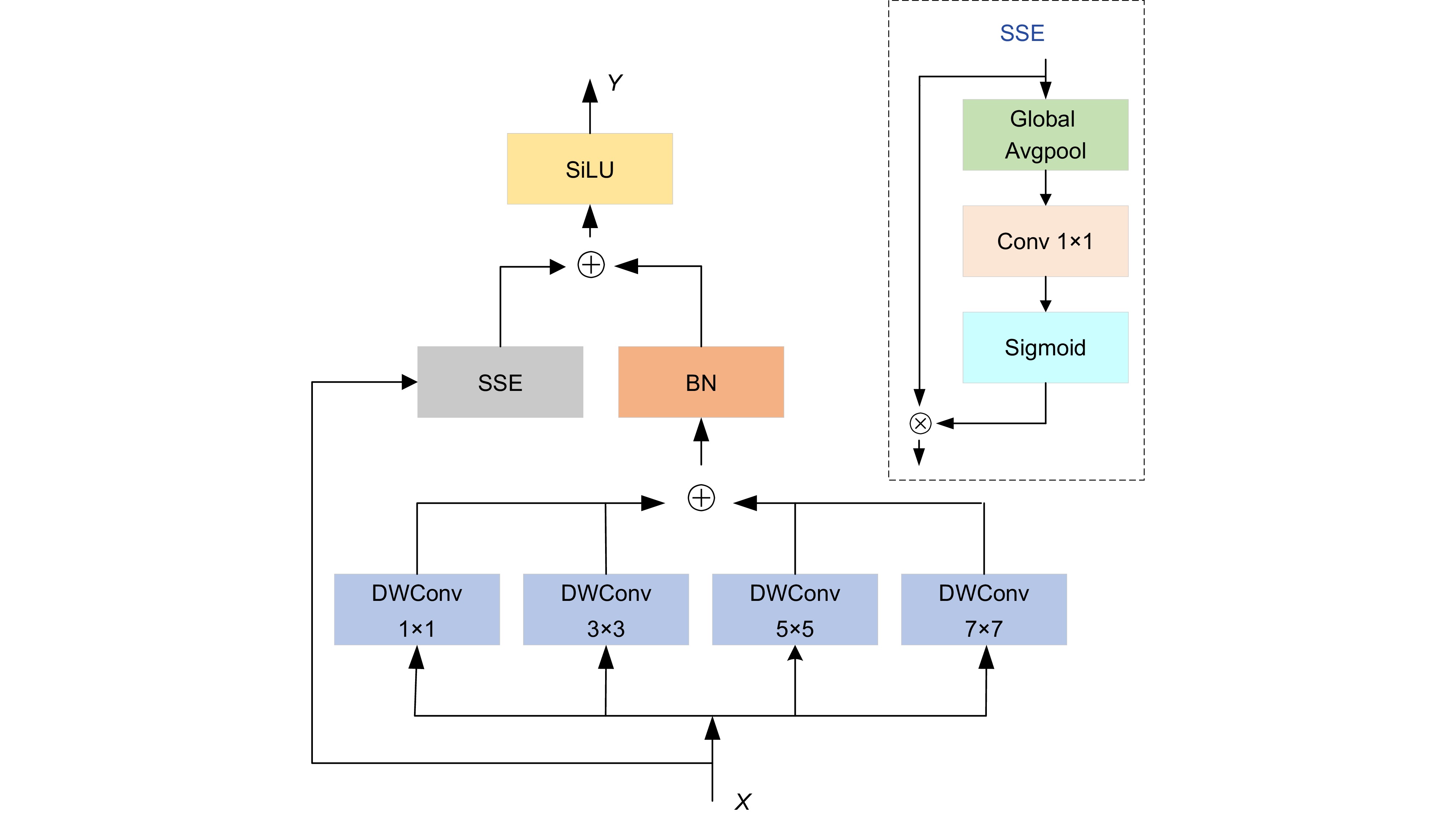
Overview: With the gradual emergence of computer vision in recent years, target detection algorithms are also constantly innovating and developing, and the detection of safety helmets on two-wheeled vehicles is also one of the focuses of research scholars. Two-wheeled vehicles have become the main means of transportation for citizens to travel at this stage, but the phenomena of citizens running red lights and not wearing safety helmets are still common, so it is especially urgent to design a helmet-wearing detection method for cyclists. At the present stage of safety helmet detection, there are still some difficulties, such as complex background information, the detection target exists in different scales of the diversity of changes, so the design of higher performance helmet detection algorithms needs to carry out further research. Aiming at the phenomenon that complex background often exists in non-motorized drivers' helmet detection and the diversity of detection target scales often exists in the detection scene, which in turn leads to low detection efficiency and misdetection and omission, a YOLOv8 algorithm oriented to traffic helmet detection is proposed. The alteration points of this paper mainly contain the following two blocks. The first is the C2f_BC module, the GSConv module with the idea of combining group convolution and spatial convolution is introduced, and the attention mechanism combining channel and space (convolutional block attention module, CBAM) is introduced in Bottleneck in C2f. To effectively reduce the computational complexity and enhance the extraction of local and global features, we designed the parallel multiscale feature fusion module MP-Parnet (parallel multiscale perception networks) and redesigned the Parnet (parallel networks) by using the parallel depth-separable feature fusion module with different scales. The second is a parallel depthwise separable convolution (DWConv) kernel for different scales. It is used instead of the ordinary convolution of the original module, which effectively adapts to the acquisition ability of different scales of targets. 3. Focaler-IoU is introduced into the original model, and Focaler-CIoU is designed, which effectively enhances the performance of the detection model in both classification and detection. detection performance. The experimental results show that compared with the original model, the improved YOLOv8n maintains a decrease in the number of parameters while the mAP50 and mAP50: 95 increase by 2.2% and 1.9% on the self-built dataset Helmet, and 1.8% and 1.9% on the open-source dataset TWHD, which suggests that the improved model can be better applied to the helmet detection of non-motorized drivers in the scenario.
-

-
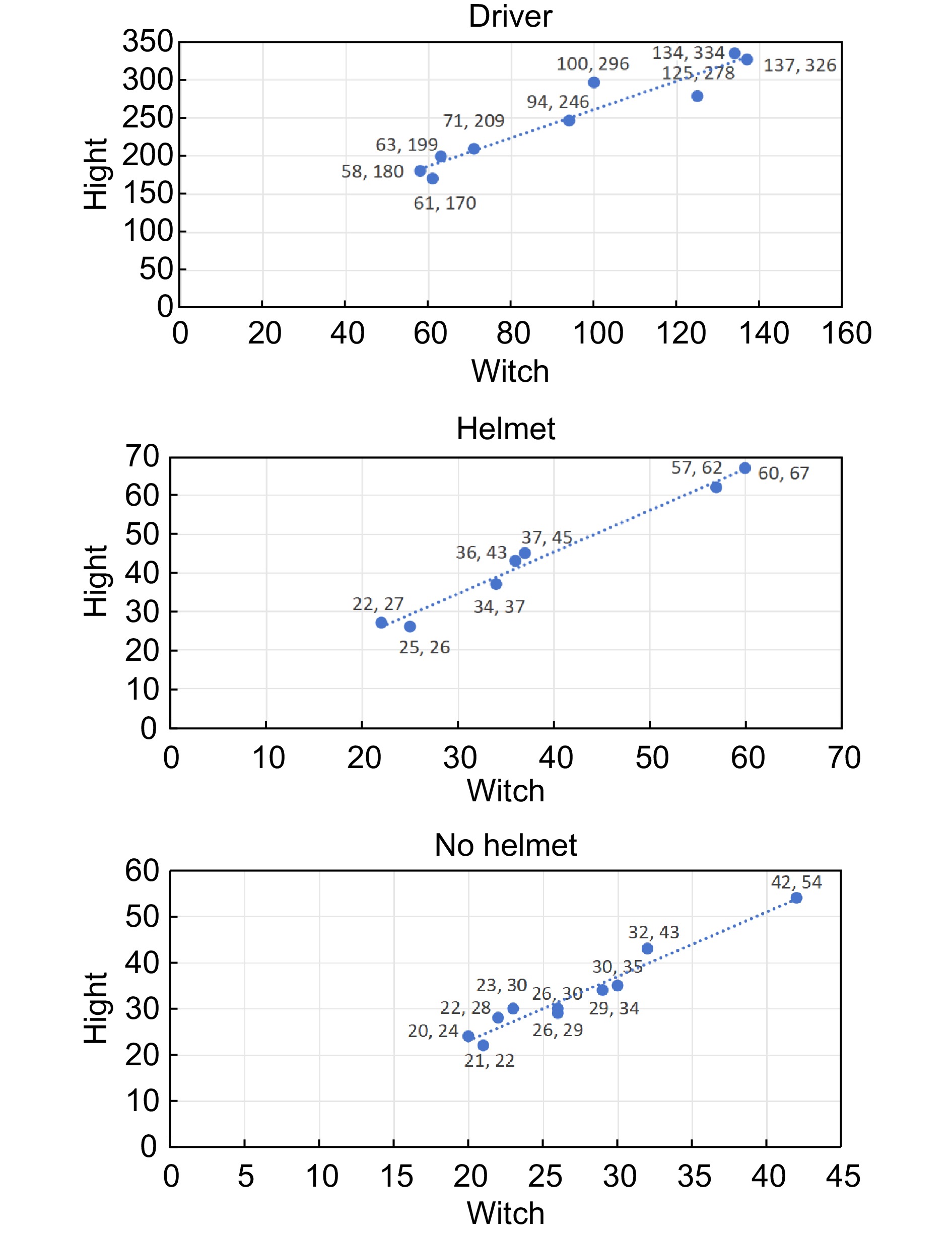
图 10 不同类别长宽分布散点图
Figure 10. Scatterplots of length and width distribution of different categories

图 12 定性检测结果展示。(a)漏检情况;(b)误检情况;(c)骑行人员密集场景检测效果对比
Figure 12. Display of qualitative experiment results. (a) Cases of object leakage; (b) Cases of object misdetections; (c) Comparison of detection effects for dense scenes of drivers
表 1 Helmet数据集处理后各目标数量
Table 1. Number of target after Helmet dataset processing
Class Driver Helmet No helmet Target number 9027 7743 3184  下载: 导出CSV
下载: 导出CSV
表 2 TWHD数据集处理后各目标数量
Table 2. Number of target after TWHD dataset processing
Class Two_wheeler Helmet Without_helmet Target number 13790 11742 6895
下载: 导出CSV
表 3 实验参数配置
Table 3. Configuration of experimental parameters
Key parameter Parameter value Epoch 200 lr0 0.01 Imgsz 640 Batch 8 Momentum 0.937
下载: 导出CSV
表 4 不同阈值下mAP50值
Table 4. mAP50 values at different thresholds
d u 1 0.9 0.8 0.7 0.6 0 0.842 0.840 0.840 0.841 0.842 0.1 0.842 0.842 0.838 0.840 0.842 0.2 0.840 0.840 0.839 0.842 0.840 0.3 0.841 0.842 0.843 0.842 0.838 0.4 0.839 0.841 0.842 0.838 0.840
下载: 导出CSV
表 5 不同阈值下mAP50∶95值
Table 5. mAP50∶95 values at different thresholds
d u 1 0.9 0.8 0.7 0.6 0 0.681 0.682 0.684 0.681 0.681 0.1 0.684 0.685 0.682 0.682 0.682 0.2 0.682 0.684 0.686 0.686 0.679 0.3 0.685 0.685 0.690 0.686 0.678 0.4 0.683 0.682 0.688 0.680 0.679
下载: 导出CSV
表 6 改进前后mAP对比
Table 6. Comparison of mAP before and after improvement
Algorithm Pre-improvement loss Post-improvement loss mAP50 mAP50∶95 mAP50 mAP50∶95 YOLOv5n 0.830 0.652 0.832 (+0.2%) 0.656 (+0.4%) YOLOv8n 0.839 0.686 0.843 (+0.4%) 0.690 (+0.4%)
下载: 导出CSV
表 7 GSConv和普通卷积对比
Table 7. Comparison of GSConv and Conv
Convolutional type mAP50 mAP50∶95 Params/106 Conv 0.843 0.690 3.15 GSConv 0.849 (+0.6%) 0.693 (+0.3%) 2.93 (−7.0%)
下载: 导出CSV
表 8 在不同位置引入CBAM
Table 8. Introducing CBAM at different convolutional layers
Module mAP50 mAP50∶95 Params/106 C2f+GSConv 0.849 0.693 2.93 C2f_B1 0.849 0.691 3.02 C2f_B2 0.853 (+0.4%) 0.696 (+0.3%) 3.02 (+3.1%)
下载: 导出CSV
表 9 不同注意力之间精度对比
Table 9. Comparison of mAP among different attentions
No. Module Params/106 mAP50 mAP50∶95 1 C2f+GSConv 2.93 0.849 0.693 2 1+ECA 2.93 0.848 0.694 3 1+SE 2.98 0.849 0.695 4 1+GAM 3.47 0.853 0.697 5 1+EMA 2.94 0.852 0.692 6 1+CBAM 3.02 0.853 0.696
下载: 导出CSV
表 10 在不同网络颈部加入MP-Parnet
Table 10. Adding MP-Parnet to different network necks
Module Pre-Improvement Post-Improvement mAP50 mAP50∶95 mAP50 mAP50∶95 YOLOv5n 0.832 0.656 0.840 (+0.8%) 0.674 (+1.8%) YOLOv6n 0.822 0.663 0.841 (+1.9%) 0.671 (+0.8%) YOLOv8n 0.843 0.690 0.856 (+1.3%) 0.698 (+0.8%) YOLOv10n 0.837 0.685 0.844 (+0.7%) 0.690 (+0.5%) RT-DETR (r18) 0.802 0.651 0.829 (+2.7%) 0.674 (+2.3%)
下载: 导出CSV
表 11 消融实验
Table 11. Comparison of ablation experiments
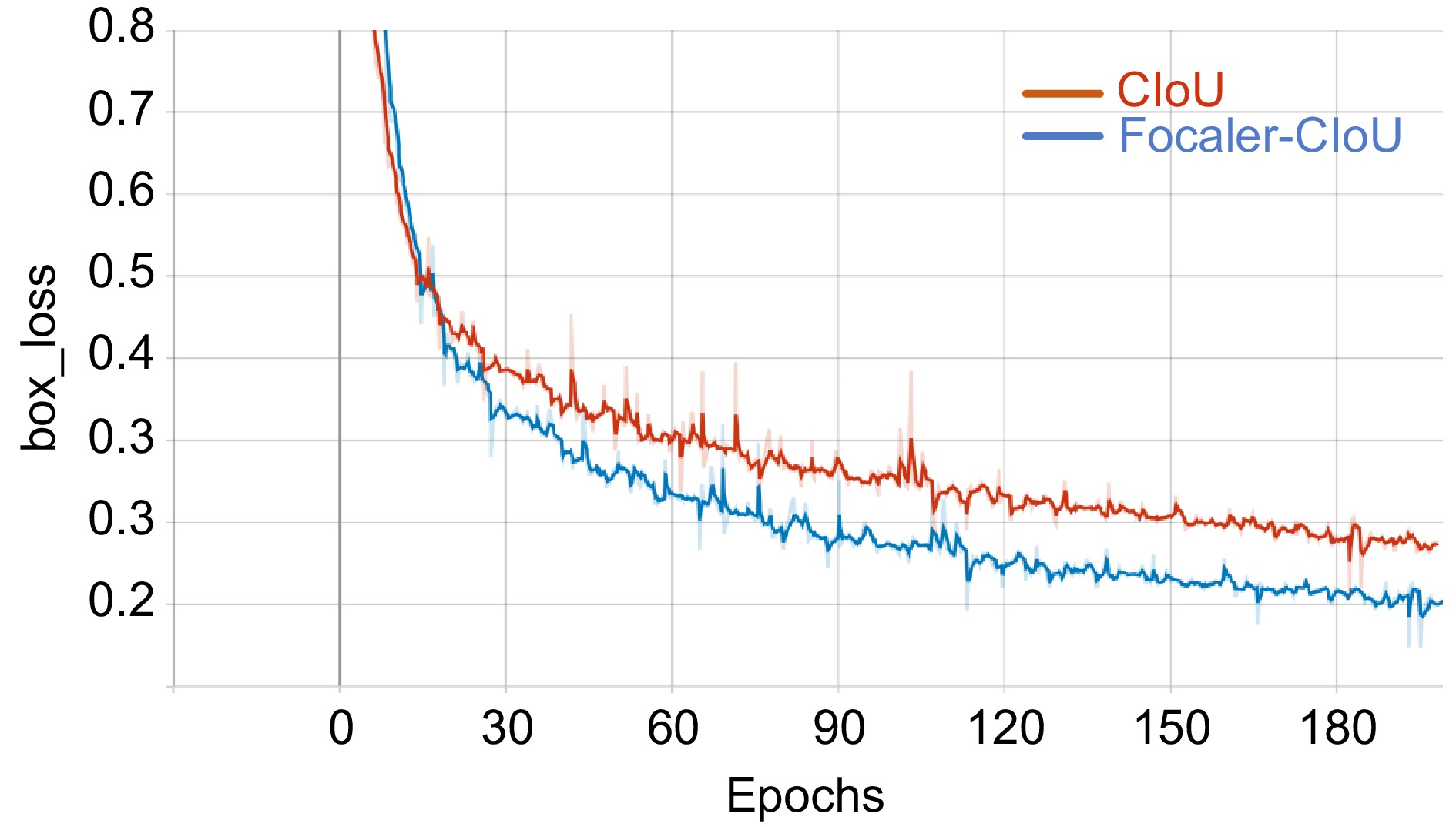
No. YOLOv8n Focaler-CIoU C2f_BC MP-Parnet Helmet TWHD Params/106 GFLOPs mAP50 mAP50∶95 mAP50 mAP50∶95 1 √ 0.839 0.686 0.725 0.437 3.15 8.7 2 √ √ 0.843 0.691 0.730 0.440 3.15 8.7 3 √ √ √ 0.853 0.696 0.741 0.454 3.02 8.2 4 √ √ √ 0.856 0.698 0.739 0.452 3.31 9.0 5 √ √ √ √ 0.861 0.705 0.743 0.456 3.12 8.4
下载: 导出CSV
表 12 与其他模型对比
Table 12. Comparison with other models
Module Helmet TWHD Params/106 GFLOPs mAP50 mAP50: 95 mAP50 mAP50: 95 YOLOv5n 0.832 0.656 0.719 0.430 2.5 7.1 YOLOv5s 0.848 0.691 0.724 0.446 9.11 23.8 YOLOv6n 0.822 0.663 0.713 0.432 4.23 11.8 YOLOv8s 0.859 0.700 0.738 0.453 11.12 28.4 YOLOv8n-ghost 0.834 0.655 0.720 0.429 1.71 5.0 YOLOv10n 0.837 0.685 0.729 0.441 2.69 8.2 RT-DETR (r18) 0.802 0.651 0.696 0.417 19.9 57.0 Ours 0.861 0.705 0.743 0.456 3.12 8.4
下载: 导出CSV
-
参考文献
[1] 李斌, 侯德藻, 张纪升, 等. 论智能车路协同的概念与机理[J]. 公路交通科技, 2020, 37 (10): 134−141. doi: 10.3969/j.issn.1002-0268.2020.10.015
Li B, Hou D Z, Zhang J S, et al. Study on conception and mechanism of intelligent vehicle-infrastructure cooperation[J]. J Highw Transp Res Dev, 2020, 37 (10): 134−141. doi: 10.3969/j.issn.1002-0268.2020.10.015
[2] 岑晏青, 宋向辉, 王东柱, 等. 智慧高速公路技术体系构建[J]. 公路交通科技, 2020, 37 (7): 111−121. doi: 10.3969/j.issn.1002-0268.2020.07.015
Cen Y Q, Song X H, Wang D Z, et al. Establishment of technology system of smart expressway[J]. J Highw Transp Res Dev, 2020, 37 (7): 111−121. doi: 10.3969/j.issn.1002-0268.2020.07.015
[3] Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015, 1: 91–99.
[4] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision (ECCV), 2016: 21–37. https://doi.org/10.1007/978-3-319-46448-0_2.
[5] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 213–229. https://doi.org/10.1007/978-3-030-58452-8_13.
[6] 刘超, 高健. 一种改进的YOLOv5电动车头盔佩戴检测方法[J]. 软件导刊, 2024, 23 (6): 143−149. doi: 10.11907/rjdk.231506
Liu C, Gao J. An improved YOLOv5 electric vehicle helmet wearing detection method[J]. Software Guide, 2024, 23 (6): 143−149. doi: 10.11907/rjdk.231506
[7] 王茹, 刘大明, 张健. Wear-YOLO: 变电站电力人员安全装备检测方法研究[J]. 计算机工程与应用, 2024, 60 (9): 111−121. doi: 10.3778/j.issn.1002-8331.2308-0317
Wang R, Liu D M, Zhang J. Wear-YOLO: research on detection methods of safety equipment for power personnel in substations[J]. Comput Eng Appl, 2024, 60 (9): 111−121. doi: 10.3778/j.issn.1002-8331.2308-0317
[8] 王鹏飞, 黄汉明, 王梦琪. 改进YOLOv5的复杂道路目标检测算法[J]. 计算机工程与应用, 2022, 58 (17): 81−92. doi: 10.3778/j.issn.1002-8331.2205-0158
Wang P F, Huang H M, Wang M Q. Complex road target detection algorithm based on improved YOLOv5[J]. Comput Eng Appl, 2022, 58 (17): 81−92. doi: 10.3778/j.issn.1002-8331.2205-0158
[9] 周顺勇, 彭梓洋, 张航领, 等. Helmet-YOLO: 一种更高精度的道路安全头盔检测算法[J]. 计算机工程与应用, 2024, . doi: http://kns.cnki.net/kcms/detail/11.2127.TP.20240909.1514.018.html
Zhou S Y, Peng Z Y, Zhang H L, et al. Helmet-YOLO: a higher-accuracy road safety helmet detection algorithm[J]. Comput Eng Appl, 2024, . doi: http://kns.cnki.net/kcms/detail/11.2127.TP.20240909.1514.018.html
[10] Li H L, Li J, Wei H B, et al. Slim-neck by GSConv: a better design paradigm of detector architectures for autonomous vehicles[Z]. arXiv: 2206.02424, 2022. https://doi.org/10.48550/arXiv.2206.02424.
[11] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 3–19. https://doi.org/10.1007/978-3-030-01234-2_1.
[12] Goyal A, Bochkovskiy A, Deng J, et al. Non-deep networks[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems, 2022: 492.
[13] Chollet F. Xception: deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1251–1258. https://doi.org/10.1109/CVPR.2017.195.
[14] Zhang H, Zhang S J. Focaler-IoU: more focused intersection over union loss[Z]. arXiv: 2401.10525, 2024. https://doi.org/10.48550/arXiv.2401.10525.
[15] 陈旭, 彭冬亮, 谷雨. 基于改进YOLOv5s的无人机图像实时目标检测[J]. 光电工程, 2022, 49 (3): 210372. doi: 10.12086/oee.2022.210372
Chen X, Peng D L, Gu Y. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electron Eng, 2022, 49 (3): 210372. doi: 10.12086/oee.2022.210372
[16] Han K, Wang Y H, Tian Q, et al. GhostNet: more features from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1577–1586. https://doi.org/10.1109/CVPR42600.2020.00165.
[17] Zhang X Y, Zhou X Y, Lin M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 6848–6856. https://doi.org/10.1109/CVPR.2018.00716.
[18] Zhang H, Xu C, Zhang S J. Inner-IoU: more effective intersection over union loss with auxiliary bounding box[Z]. arXiv: 2311.02877, 2023. https://doi.org/10.48550/arXiv.2311.02877.
[19] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[20] Liu Y C, Shao Z R, Hoffmann N. Global attention mechanism: retain information to enhance channel-spatial interactions[Z]. arXiv: 2112.05561, 2021. https://doi.org/10.48550/arXiv.2112.05561.
[21] Ouyang D L, He S, Zhang G Z, et al. Efficient multi-scale attention module with cross-spatial learning[C]//ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023: 1–5. https://doi.org/10.1109/ICASSP49357.2023.10096516.
[22] Wang A, Chen H, Liu L H, et al. YOLOv10: real-time end-to-end object detection[Z]. arXiv: 2405.14458, 2024. https://doi.org/10.48550/arXiv.2405.14458.
[23] Lv W Y, Xu S L, Zhao Y A, et al. DETRs beat YOLOs on real-time object detection[Z]. arXiv: 2304.08069, 2023. https://doi.org/10.48550/arXiv.2304.08069.
[24] 熊恩杰, 张荣芬, 刘宇红, 等. 面向交通标志的Ghost-YOLOv8检测算法[J]. 计算机工程与应用, 2023, 59 (20): 200−207. doi: 10.3778/j.issn.1002-8331.2306-0032
Xiong E J, Zhang R F, Liu Y H, et al. Ghost-YOLOv8 detection algorithm for traffic signs[J]. Comput Eng Appl, 2023, 59 (20): 200−207. doi: 10.3778/j.issn.1002-8331.2306-0032
-
访问统计





 点击扫一扫
点击扫一扫

图(13)
表(12)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


