
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
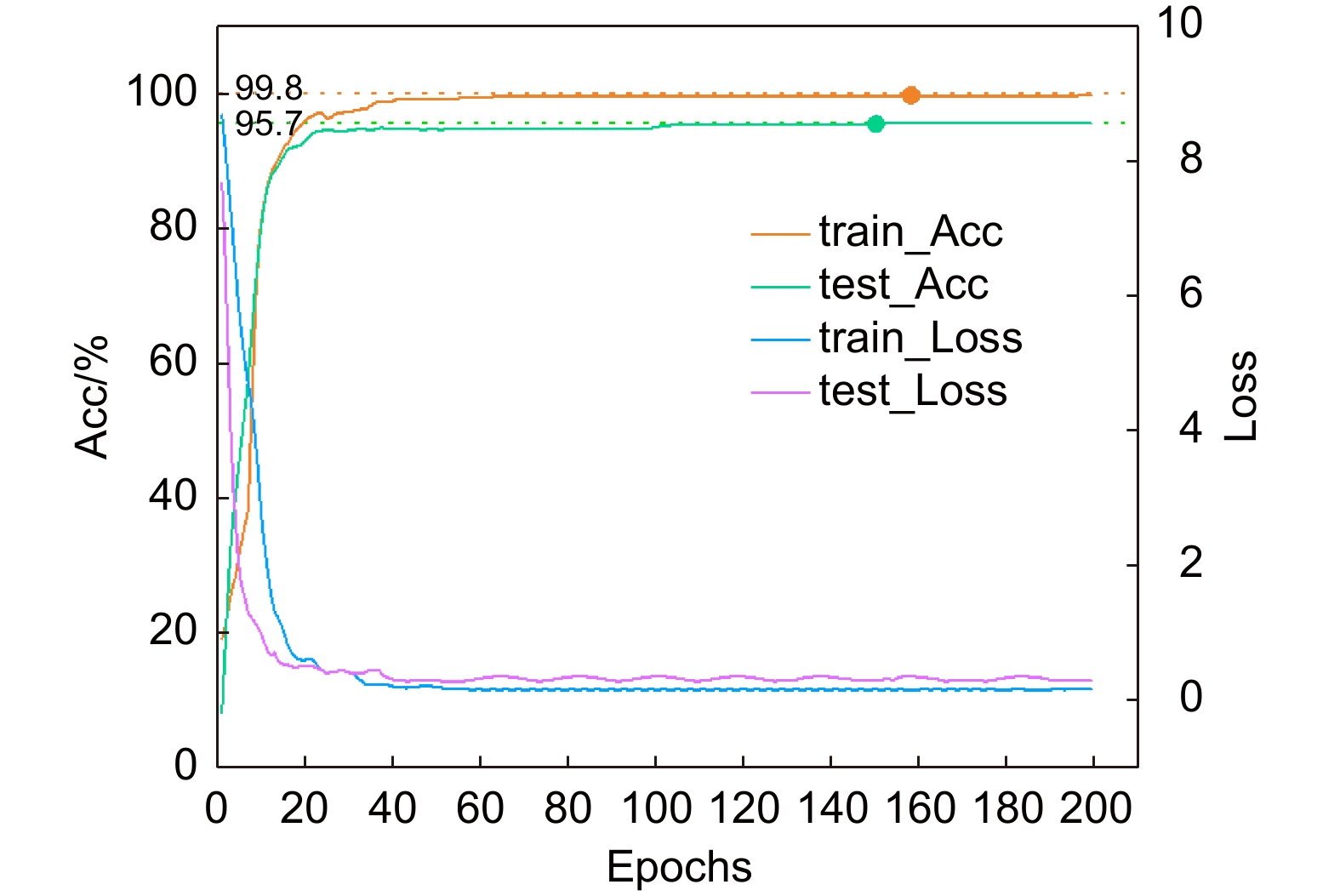
针对车辆因姿态、视角等成像差异造成车型难以识别问题,提出一种基于渐进式多粒度ResNet车型识别网络。首先,以ResNet网络作为主干网络,提出渐进式多粒度局部卷积模块,对不同粒度级别的车辆图像进行局部卷积操作,使网络重构时能够关注到不同粒度级别的车辆局部特征;其次,对多粒度局部特征图利用随机通道丢弃模块进行随机通道丢弃,抑制网络对车辆显著性区域特征的注意力,提高非显著性特征的关注度;最后,提出一种渐进式多粒度训练模块,在每个训练步骤中增加分类损失,引导网络提取更具辨别力和多样性的车辆多尺度特征。实验结果表明,在Stanford cars数据集、Compcars网络数据集和真实场景下的车型数据集VMRURS上,所提网络的识别准确率分别达到了95.7%、98.8%和97.4%,和对比网络相比,所提网络不仅具有较高的识别准确率,而且具有更好的鲁棒性。
-
关键词:
- 车型识别 /
- ResNet网络 /
- 渐进式多粒度局部卷积 /
- 随机通道丢弃 /
- 渐进式多粒度训练
Abstract
Aiming at the problem that vehicle models are difficult to recognize due to differences in vehicle posture and viewing angles, a vehicle model recognition network based on progressive multi-granularity ResNet is proposed. Firstly, a progressive multi-granularity local convolution module is proposed by using the ResNet network as the backbone network to perform local convolution operations on vehicle images of different granularity levels, so that local features of vehicles at different granularity levels can be paid attention to when the network is reconstructed. Secondly, for the multi-granularity local feature map, the random channel discarding module is adopted to perform random channel discarding, which suppresses the network's attention to the vehicle's salient regional features and improves the attention of non-salient features. Finally, a progressive multi-granularity training module is proposed. A classification loss is added in each training step to guide the network to extract more discriminative and diverse vehicle multi-scale features. Experimental results show that the recognition accuracy of the proposed network reaches 95.7%, 98.8%, and 97.4% respectively on the Stanford-cars dataset, the Compcars network dataset, and the vehicle model dataset VMRURS in real scenes. In comparison with the comparative network, the proposed network not only has higher recognition accuracy but also has better robustness.
-
Overview
Overview: Model recognition aims to identify specific information such as the brand, model, and year of the vehicle, which can help verify the accuracy of tracking vehicle information. There are two research strategies for model recognition tasks. The strategy of strong supervision and learning involves utilizing image-level labeling information as well as additional bounding boxes in the model, component information, etc. Based on the strategy of weak supervision and learning, only the image-level label can be completely classified by fine particle size models. Most classification methods for weak supervision and learning adopt strategies such as attention mechanisms, dual-linear convolutional neural networks, and measurement learning. Pay more attention to the significant particle size of the vehicle's grid, tire tires, and other large granularity, and ignore the characteristics of small-size vehicle characteristics with distinguishing power such as car logo and door handles. Aiming at the difficulty of the vehicle due to the imaging differences such as posture and perspective, it is difficult to identify the model and propose a variety of multi-granular ResNet model recognition networks. First of all, using the ResNet network as the main network, propose a gradual multi-granular local convolution module to perform local convolution operations on vehicle images of different particle sizes, so that the network can be paid attention to the local characteristics of different particle-level vehicles when restructuring. Use the random channel discarding module to discard the multi-scale local feature map for random channel discarding, inhibit the network's attention to the characteristics of the vehicle's significant regional characteristics, and increase the attention of non-significant characteristics. Each training step is added to the classification loss. By dividing the network training process into different stages, the network can effectively integrate the multi-size features of the vehicle withdrawal, and guide the network extraction of multi-scale characteristics of vehicles with more discerning and diverse vehicles. The experimental results show that on the Stanford Cars dataset, the Compcars network dataset, and the model data set in the real scene, the accuracy of the network recognition accuracy has reached 95.7%, 98.8%, and 97.4%, respectively. Compared with the comparison network, the proposed network not only has the accuracy of recognition but also has better robustness. It has achieved very outstanding results in real scenes such as low light intensity and deformation of vehicles. The effectiveness of the model recognition on the road.
-

-
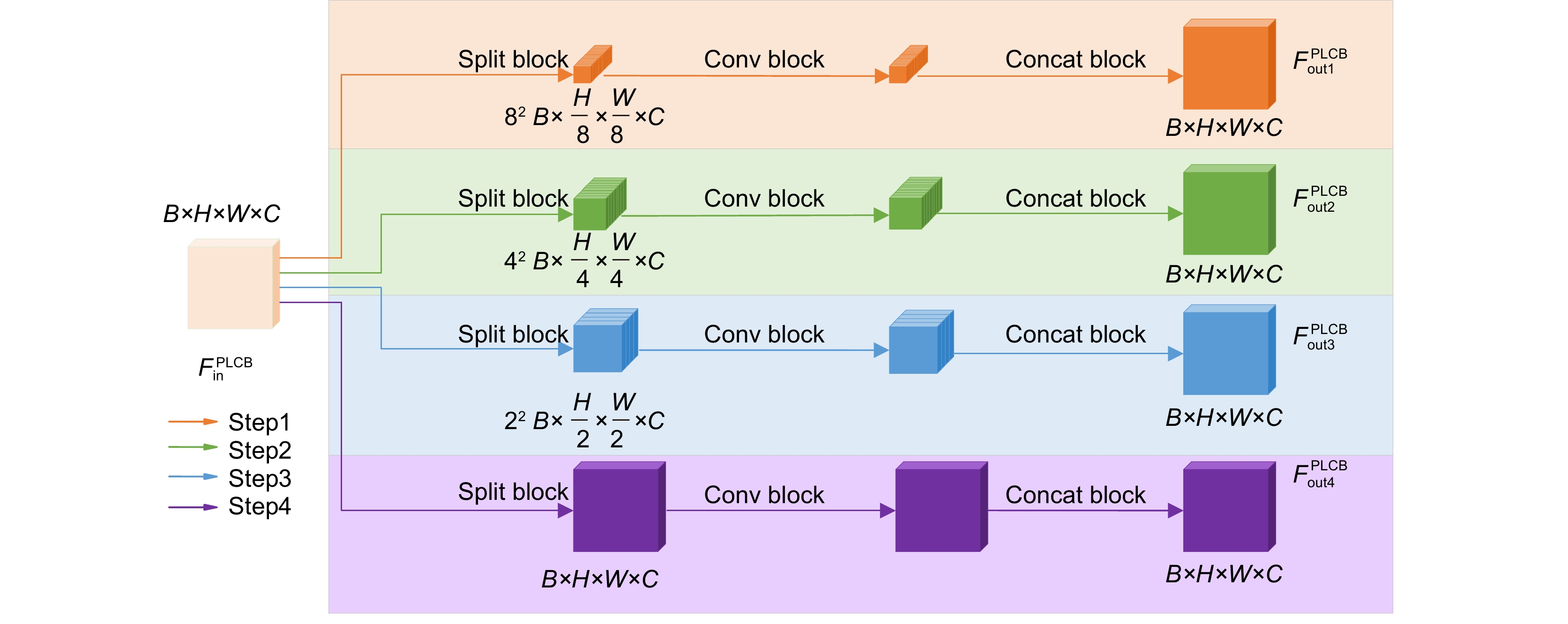
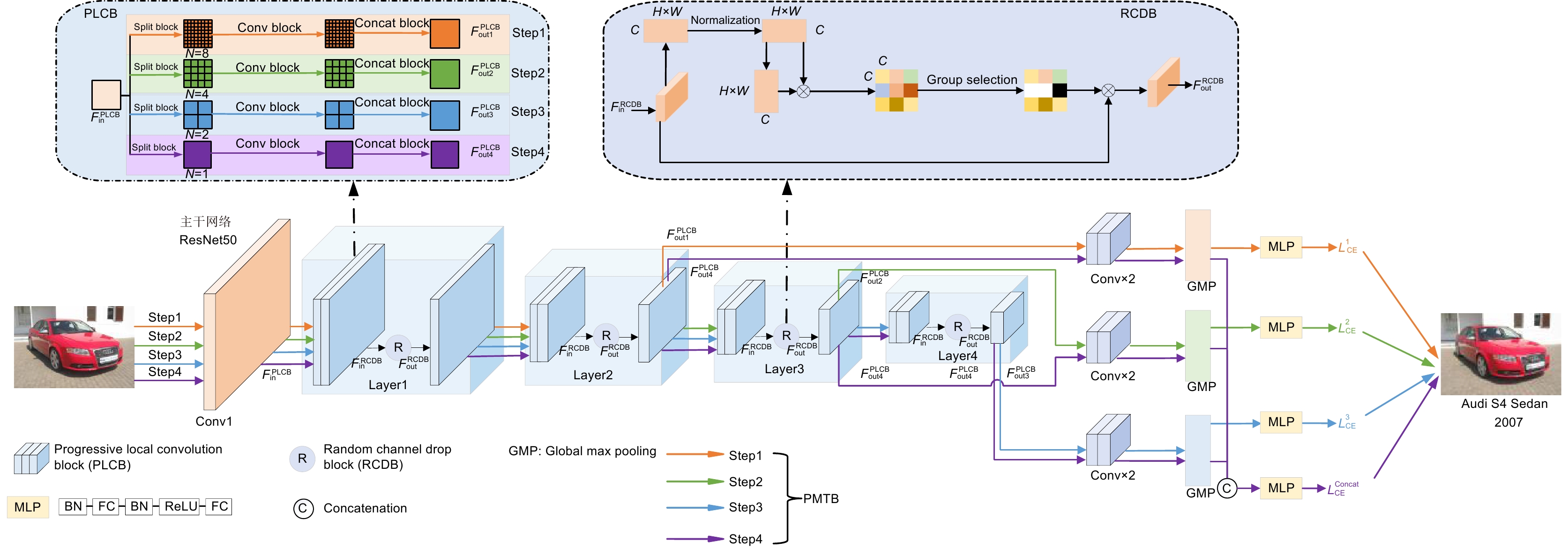
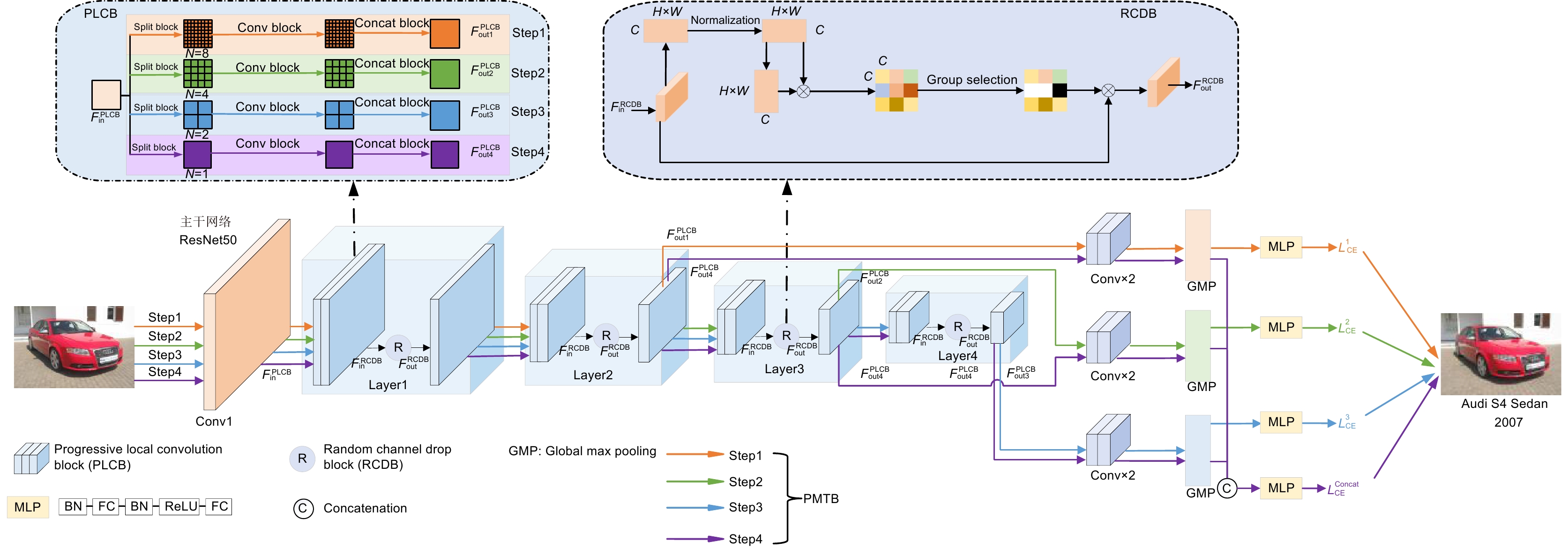
图 2 渐进式多粒度局部卷积模块(PLCB)
Figure 2. Progressive multi-granularity Local Convolution Block
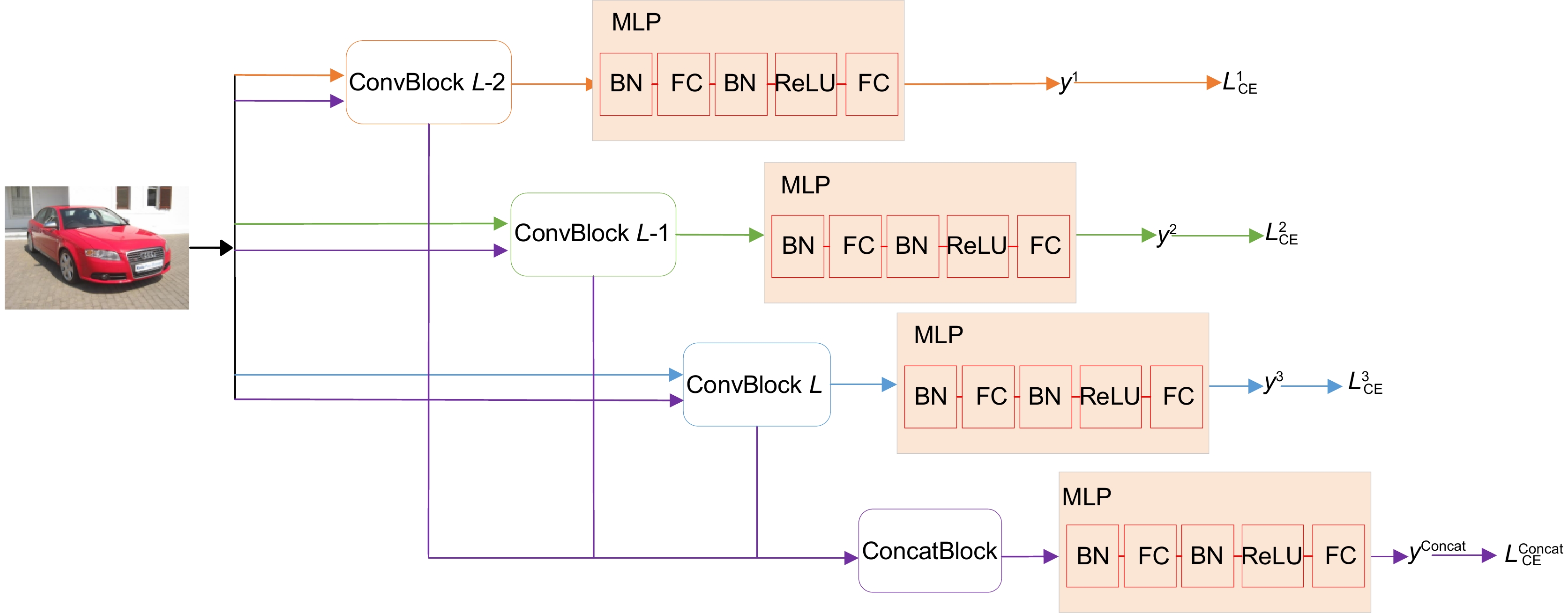
图 4 渐进式多粒度训练模块(PMTB)示意图
Figure 4. Progressive multi-granularity training block schematic diagram

图 5 Top1/%变化曲线图。(a) Stanford-cars 上 β 值对 RCDB 的影响;(b) Compcars 上 β 值对 RCDB 的影响;(c) VMRURS 上 β 值对 RCDB 的影响
Figure 5. Top1/% curve of change. (a) Effect of β values on RCDB on Stanford-cars; (b) Effect of β values on RCDB on Compcars; (c) Effect of β values on RCDB on VMRURS
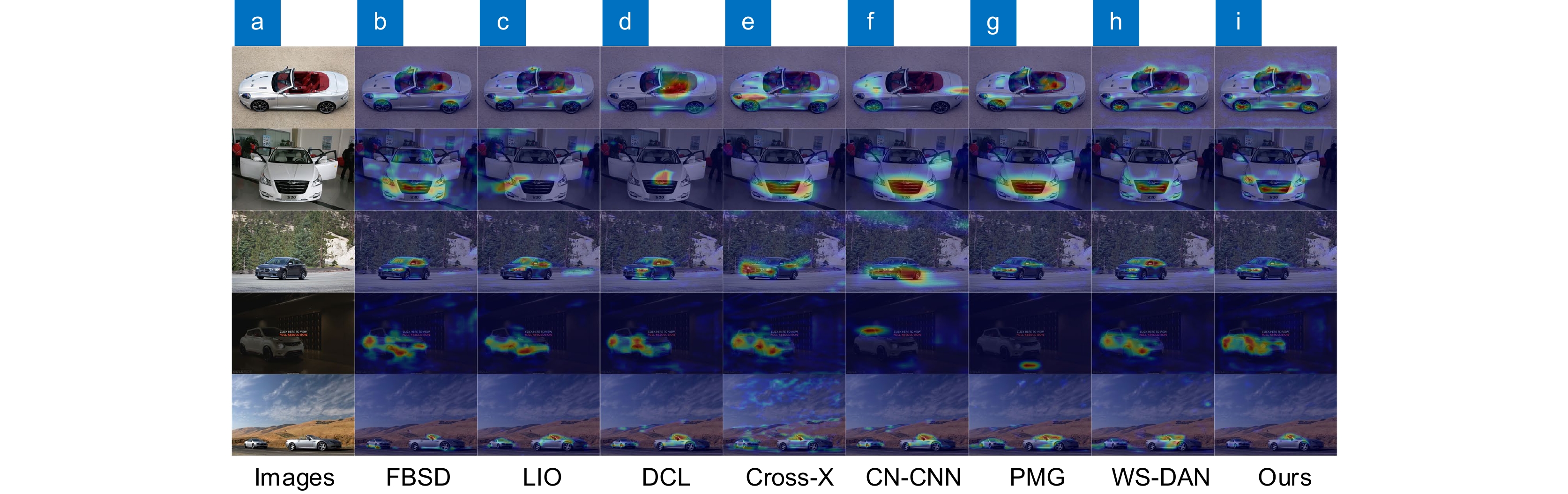
图 9 不同网络车型识别可视化对比
Figure 9. Visual comparison of different network vehicle recognition
表 1 渐进式多粒度训练步骤
Table 1. Progressive multi-granularity training steps
渐进式多粒度训练过程 输入:训练数据集D,训练数据的批次为x,标签样本为y,P代表多粒度渐进式网络学习,${L_{\rm{CE}}}$代表交叉熵损失(cross entropy loss, CE) ${\text{For }epoch } \in \left[ {0,epochs} \right]{\text{do} }$ $ {\text{For }}b \in \left[ {0,batchs} \right]{\text{do}} $ $x,y \Leftarrow batch \; {{ b \; {\rm{of}} \; D} }$ ${\text{For } }l \in [L - S + 1,L]{\text{ do} }$ ${y^l} \Leftarrow H_{ {\rm{class} } }^l[H_{ {\rm{Conv} } }^l({F^l}(P(x,n)))]$ ${L_l} \Leftarrow {L_{{\rm{CE}}} }({y^l},y)$ Backpropagation ${L_l}$ End for ${y^{ {\rm{Concat} } } } = H_{ {\rm{class} } }^{ {\rm{Concat} } }\left\{ { {\rm{Concat} }[{V^{(L - S + 1)} }, \ldots ,{V^L}]} \right\}$ ${L_{ {\rm{Concat} } } } \Leftarrow {L_{{\rm{CE}}} }({y^{ {\rm{Concat} } } },y)$ Backpropagation ${L_{ {\rm{Concat} } } }$ End for End for  下载: 导出CSV
下载: 导出CSV
表 2 各个阶段PLCB切分大小的比较
Table 2. Comparison of PLCB split size at each stage
Stage1 Stage2 Stage3 Stage4 Accuracy/% 1 1 1 1 93.5 2 2 2 2 93.9 4 4 4 4 94.2 8 8 8 8 94.0 16 8 4 2 93.6 8 4 2 1 94.5 4 2 1 1 93.9
下载: 导出CSV
表 3 RCDB模块加入不同层后识别效果消融实验
Table 3. Ablation experiment of recognition effect after adding different layers to the RCDB module
ResNet50 Layer1 Layer2 Layer3 Layer4 Accuracy/% ✓ ✗ ✗ ✗ ✗ 91.5 ✓ ✓ ✗ ✗ ✗ 92.3 ✓ ✗ ✓ ✗ ✗ 92.9 ✓ ✗ ✗ ✓ ✗ 93.0 ✓ ✗ ✗ ✗ ✓ 92.6 ✓ ✓ ✓ ✓ ✓ 93.2
下载: 导出CSV
表 4 不同模块依次加入网络中的实验效果
Table 4. Different modules are added to the network
Baseline PLCB RCDB Accuracy/% ✓ ✗ ✗ 91.5 ✓ ✓ ✗ 94.8 ✓ ✗ ✓ 93.2 ✓ ✓ ✓ 95.7
下载: 导出CSV
表 5 不同网络车型识别准确率比较
Table 5. Comparison of recognition accuracy of different network models
Methods Backbone Stanford-cars/% Compcars/% VMRURS/% Speed/(f/s) Params/M FLOPs/G 基线[25] ResNet50 91.5 94.1 87.1 4.15 23.50 33.05 FBSD[31] ResNet50 94.4 96.8 92.3 1.73 46.82 53.11 LIO[32] ResNet50 94.5 96.8 94.2 3.60 24.57 33.06 DCL[33] ResNet50 94.5 96.7 94.7 3.46 24.91 33.06 Cross-X[34] ResNet50 94.6 97.0 94.6 3.88 25.56 38.86 CAL[17] ResNet50 95.5 98.0 96.4 3.72 33.73 33.08 WS-DAN[18] ResNet50 94.5 97.1 95.6 4.02 33.24 33.08 PMG[26] ResNet50 95.1 97.8 95.7 2.94 45.12 69.82 CN-CNN[35] ResNet50 94.9 97.6 94.9 1.92 42.31 47.65 Ours ResNet50 95.7 98.8 97.4 2.97 40.64 69.61
下载: 导出CSV
-
参考文献
[1] Bay H, Tuytelaars T, Van Gool L. SURF: speeded up robust features[C]//Proceedings of the 9th European Conference on Computer Vision, 2006: 404–417. https://doi.org/10.1007/11744023_32.
[2] Csurka G, Dance C R, Fan L X, et al. Visual categorization with bags of keypoints[C]//Workshop on Statistical Learning in Computer Vision, Prague, 2004.
[3] De Sousa Matos F M, De Souza R M C R. An image vehicle classification method based on edge and PCA applied to blocks[C]//International Conference on Systems, Man, and Cybernetics, 2012: 1688–1693. https://doi.org/10.1109/ICSMC.2012.6377980.
[4] Behley J, Steinhage V, Cremers A B. Laser-based segment classification using a mixture of bag-of-words[C]//2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2013: 4195–4200. https://doi.org/10.1109/IROS.2013.6696957.
[5] Liao L, Hu R M, Xiao J, et al. Exploiting effects of parts in fine-grained categorization of vehicles[C]//Proceedings of the 2015 IEEE International Conference on Image Processing, 2015: 745–749. https://doi.org/10.1109/ICIP.2015.7350898.
[6] Hsieh J W, Chen L C, Chen D Y. Symmetrical SURF and its applications to vehicle detection and vehicle make and model recognition[J]. IEEE Trans Intell Transp Syst, 2014, 15(1): 6−20. doi: 10.1109/TITS.2013.2294646
[7] 冯建周, 马祥聪. 基于迁移学习的细粒度实体分类方法的研究[J]. 自动化学报, 2020, 46(8): 1759−1766. doi: 10.16383/j.ass.c190041
Feng J Z, Ma X C. Fine-grained entity type classification based on transfer learning[J]. Acta Autom Sin, 2020, 46(8): 1759−1766. doi: 10.16383/j.ass.c190041
[8] 罗建豪, 吴建鑫. 基于深度卷积特征的细粒度图像分类研究综述[J]. 自动化学报, 2017, 43(8): 1306−1318. doi: 10.16383/j.aas.2017.c160425
Luo J H, Wu J X. A survey on fine-grained image categorization using deep convolutional features[J]. Acta Autom Sin, 2017, 43(8): 1306−1318. doi: 10.16383/j.aas.2017.c160425
[9] 汪荣贵, 姚旭晨, 杨娟, 等. 基于深度迁移学习的微型细粒度图像分类[J]. 光电工程, 2019, 46(6): 180416. doi: 10.12086/oee.2019.180416
Wang R G, Yao X C, Yang J, et al. Deep transfer learning for fine-grained categorization on micro datasets[J]. Opto-Electron Eng, 2019, 46(6): 180416. doi: 10.12086/oee.2019.180416
[10] Wei X S, Song Y Z, Aodha O M, et al. Fine-grained image analysis with deep learning: a survey[J]. IEEE Trans Pattern Anal Mach Intell, 2022, 44(12): 8927−8948. doi: 10.1109/TPAMI.2021.3126648
[11] Yang Z, Luo T G, Wang D, et al. Learning to navigate for fine-grained classification[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 438–454. https://doi.org/10.1007/978-3-030-01264-9_26.
[12] Fang J, Zhou Y, Yu Y, et al. Fine-grained vehicle model recognition using a coarse-to-fine convolutional neural network architecture[J]. IEEE Trans Intell Transp Systems, 2017, 18(7): 1782−1792. doi: 10.1109/TITS.2016.2620495
[13] Zhang X P, Xiong H K, Zhou W G, et al. Fused one-vs-all features with semantic alignments for fine-grained visual categorization[J]. IEEE Trans Image Process, 2016, 25(2): 878−892. doi: 10.1109/TIP.2015.2509425
[14] Xu H P, Qi G L, Li J J, et al. Fine-grained image classification by visual-semantic embedding[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence, 2018: 1043–1049. https://doi.org/10.5555/3304415.3304563.
[15] Zhang H, Xu T, Elhoseiny M, et al. SPDA-CNN: Unifying semantic part detection and abstraction for fine-grained recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1143–1152. https://doi.org/10.1109/CVPR.2016.129.
[16] Ding Y F, Ma Z Y, Wen S G, et al. AP-CNN: weakly supervised attention pyramid convolutional neural network for fine-grained visual classification[J]. IEEE Trans Image Process, 2021, 30: 2826−2836. doi: 10.1109/TIP.2021.3055617
[17] Rao Y M, Chen G Y, Lu J W, et al. Counterfactual attention learning for fine-grained visual categorization and re-identification[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021: 1005–1014. https://doi.org/10.1109/ICCV48922.2021.00106.
[18] Hu T, Qi H G, Huang Q M, et al. See better before looking closer: weakly supervised data augmentation network for fine-grained visual classification[Z]. arXiv: 1901.09891, 2019. https://doi.org/10.48550/arXiv.1901.09891.
[19] Lin T Y, RoyChowdhury A, Maji S. Bilinear CNN models for fine-grained visual recognition[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision, 2015: 1449–1457. https://doi.org/10.1109/ICCV.2015.170.
[20] Yu C J, Zhao X Y, Zheng Q, et al. Hierarchical bilinear pooling for fine-grained visual recognition[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 595–610. https://doi.org/10.1007/978-3-030-01270-0_35.
[21] Gao Y, Beijbom O, Zhang N, et al. Compact bilinear pooling[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 317–326. https://doi.org/10.1109/CVPR.2016.41.
[22] Kong S, Fowlkes C. Low-rank bilinear pooling for fine-grained classification[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 7025–7034. https://doi.org/10.1109/CVPR.2017.743.
[23] Sun M, Yuan Y C, Zhou F, et al. Multi-attention multi-class constraint for fine-grained image recognition[C]//15th European Conference on Computer Vision, 2018: 834–850. https://doi.org/10.1007/978-3-030-01270-0_49.
[24] Zheng X W, Ji R R, Sun X S, et al. Towards optimal fine grained retrieval via decorrelated centralized loss with normalize-scale layer[C]//Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, 2019: 1140. https://doi.org/10.1609/aaai.v33i01.33019291.
[25] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90.
[26] Du R Y, Cheng D L, Bhunia A K, et al. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches[C]//16th European Conference on Computer Vision, 2020: 153–168. https://doi.org/10.1007/978-3-030-58565-5_10.
[27] Choe J, Shim H. Attention-based dropout layer for weakly supervised object localization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 2214–2223. https://doi.org/10.1109/CVPR.2019.00232.
[28] Krause J, Stark J, Deng L, et al. 3D object representations for fine-grained categorization[C]//2013 IEEE International Conference on Computer Vision Workshops, 2013: 554–561. https://doi.org/10.1109/ICCVW.2013.77.
[29] Yang L J, Luo P, Loy C C, et al. A large-scale car dataset for fine-grained categorization and verification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3973–3981. https://doi.org/10.1109/CVPR.2015.7299023.
[30] Ali M, Tahir M A, Durrani M N. Vehicle images dataset for make and model recognition[J]. Data Brief, 2022, 42: 108107. doi: 10.1016/J.DIB.2022.108107
[31] Song J W, Yang R Y. Feature boosting, suppression, and diversification for fine-grained visual classification[C]//International Joint Conference on Neural Networks, 2021: 1–8. https://doi.org/10.1109/IJCNN52387.2021.9534004.
[32] Zhou M H, Bai Y L, Zhang W, et al. Look-into-object: self-supervised structure modeling for object recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 11771–11780. https://doi.org/10.1109/CVPR42600.2020.01179.
[33] Chen Y, Bai Y L, Zhang W, et al. Destruction and construction learning for fine-grained image recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 5152–5161. https://doi.org/10.1109/CVPR.2019.00530.
[34] Luo W, Yang X T, Mo X J, et al. Cross-x learning for fine-grained visual categorization[C]//IEEE/CVF International Conference on Computer Vision, 2019: 8241–8250. https://doi.org/10.1109/ICCV.2019.00833.
[35] Guo C Y, Xie J Y, Liang K M, et al. Cross-layer navigation convolutional neural network for fine-grained visual classification[C]//ACM Multimedia Asia, 2021: 49. https://doi.org/10.1145/3469877.3490579.
-
访问统计


 点击扫一扫
点击扫一扫
图(10)
表(5)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


