
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
行人重识别是计算机视觉中一项具有挑战性和实际意义的重要任务,具有广泛的应用前景。背景干扰、任意变化的行人姿态和无法控制的摄像机角度等都会给行人重识别研究带来较大的阻碍。为提取更具有辨别力的行人特征,本文提出了基于多分区注意力的网络架构,该网络能同时从全局图像和不同局部图像中学习具有鲁棒性和辨别力的行人特征表示,能高效地提高行人重识别任务的识别能力。此外,在局部分支中设计了一种双重注意力网络,由空间注意力和通道注意力共同组成,优化提取局部特征。实验结果表明,该网络在Market-1501、DukeMTMC-reID和CUHK03数据集上的平均精度均值分别达到82.94%、72.17%、71.76%。

Abstract
Person re-identification is significant but a challenging task in the computer visual retrieval, which has a wide range of application prospects. Background clutters, arbitrary human pose, and uncontrollable camera angle will greatly hinder person re-identification research. In order to extract more discerning person features, a network architecture based on multi-division attention is proposed in this paper. The network can learn the robust and discriminative person feature representation from the global image and different local images simultaneously, which can effectively improve the recognition of person re-identification tasks. In addition, a novel dual local attention network is designed in the local branch, which is composed of spatial attention and channel attention and can optimize the extraction of local features. Experimental results show that the mean average precision of the network on the Market-1501, DukeMTMC-reID, and CUHK03 datasets reaches 82.94%, 72.17%, and 71.76%, respectively.
-
Key words:
- person re-identification /
- local features /
- dual attention network /
- deep neural networks
-
Overview

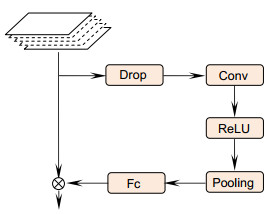
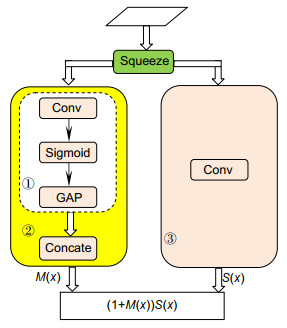
Overview:With the popularity of surveillance cameras in public areas, person re-identification has become more and more important, and has become a core technology in video content retrieval, video surveillance, and intelligent security. However, in actual application scenarios, due to factors such as camera shooting angle, complex lighting changes, and changing pedestrian poses, occlusions, clothes, and background clutter in person images. It makes even the same person target have significant differences in different cameras, which poses a great challenge for person re-identification research. Therefore, in this paper we propose a research method based on deep convolutional networks, which combines global and local person feature and attention mechanisms to solve the problem of person re-identification. First, unlike traditional methods, we use ResNet50 network to initially extract person image features with more discriminating ability. Then, according to the person inherent body structure, the image is divided into several bands in the horizontal direction, and it is input into the local branch of the built-in attention mechanism to extract the person local attention features. At the same time, the global image is input to the global branch to extract the person global features. Finally, the person global features and local attention features are fused to calculate the loss function. In the network, in order to better extract the person local features, we design two local branches to segment the person images into different numbers of local area images. With the increase of the number of blocks, the network will learn more detailed and discriminative local features in each different local area, and at the same time, it can filter irrelevant information in local images to a large extent by combining the attention mechanism. Our proposed attention mechanism can make the network focus on the areas that need to be identified. The output person attention features usually have a stronger response than the non-target areas. Therefore, the attention networks we design include spatial attention networks and channel attention networks, which complement each other to learn the optimal attention feature, thereby extracting more discriminative local features. Experimental results show that the method proposed in this paper can effectively improve the performance of person re-identification.
-

-
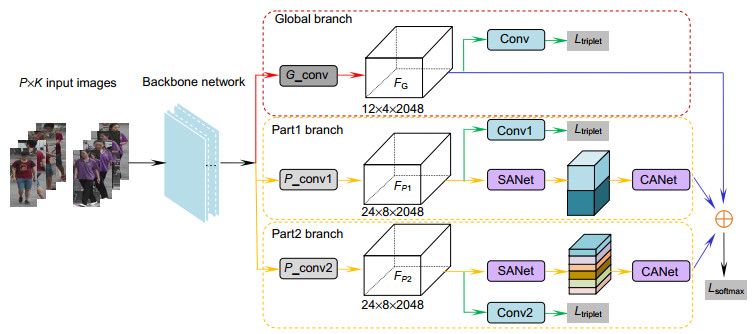
图 1 MDA模型框架的概述
Figure 1. Overview of our proposed MDA network for person re-identification
表 1 Backbone network结构
Table 1. Backbone network structure
Layer name Share Patch size Output size Input data - - 384×128, 3 Backbone Conv2d Yes 7×7, 64 192×64, 64 BN Yes 64 192×64, 64 Max pool Yes 3×3, 64 96×32, 64 Conv2_x Yes $\left[ {\begin{array}{*{20}{c}} {1 \times 1, 64}\\ {3 \times 3, 64}\\ {1 \times 1, 256} \end{array}} \right] \times 3 $ 96×32, 256 Conv3_x Yes $ \left[ {\begin{array}{*{20}{c}} {1 \times 1, 128}\\ {3 \times 3, 128}\\ {1 \times 1, 512} \end{array}} \right] \times 4$ 48×16, 512 Conv4_1 Yes $\left[ {\begin{array}{*{20}{c}} {1 \times 1, 256}\\ {3 \times 3, 256}\\ {1 \times 1, 1024} \end{array}} \right] $ 24×8, 1024 G_conv Conv5_x No $\left[ {\begin{array}{*{20}{c}} {1 \times 1, 512}\\ {3 \times 3, 512}\\ {1 \times 1, 2048} \end{array}} \right] \times 3 $ 12×4, 2048 P_conv i
(i∈[1, 2])Conv5_x No $ \left[ {\begin{array}{*{20}{c}} {1 \times 1, 512}\\ {3 \times 3, 512}\\ {1 \times 1, 2048} \end{array}} \right] \times 3$ 24×8, 2048  下载: 导出CSV
下载: 导出CSV
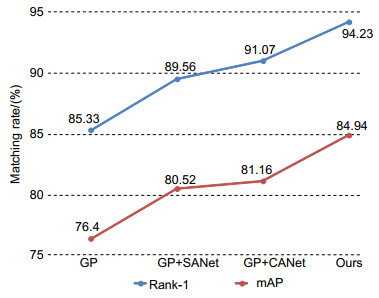
表 2 Market-1501数据集实验结果
Table 2. Comparison of results on Market-1501
Methods Rank-1/% mAP/% PCB+RPP[18] 93.80 81.60 Spindle[16] 76.90 64.67 PDC[22] 84.14 63.41 Part-Aligned[24] 81.00 63.40 AlignedReID[31] 91.80 79.30 APR[30] 87.04 66.89 HA-CNN[25] 91.20 75.70 Hydraplus-net[26] 91.80 - DuATM[32] 91.40 76.60 Ours 94.03 82.94 Ours(RK) 94.98 90.27 "RK" refers to implementing re-ranking[29] operation
下载: 导出CSV
-
参考文献
[1] 孙锐, 方蔚, 高隽.暗通道和测度学习的雾天行人再识别[J].光电工程, 2016, 43(12): 142–146. doi: 10.3969/j.issn.1003-501X.2016.12.022
Sun R, Fang W, Gao J, et al. Person Re-identification in foggy weather based on dark channel prior and metric learning[J]. Opto-Electronic Engineering, 2016, 43(12): 142–146. doi: 10.3969/j.issn.1003-501X.2016.12.022
[2] Su C, Zhang S L, Yang F, et al. Attributes driven tracklet-to-tracklet person re-identification using latent prototypes space mapping[J]. Pattern Recognition, 2017, 66: 4–15. doi: 10.1016/j.patcog.2017.01.006
[3] Matsukawa T, Okabe T, Suzuki E, et al. Hierarchical gaussian descriptor for person Re-identification[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016: 1363–1372.
[4] Zhao R, Ouyang W L, Wang X G. Person Re-identification by salience matching[C]//2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 2013: 2528–2535.
[5] Chen D P, Yuan Z J, Hua G, et al. Similarity learning on an explicit polynomial kernel feature map for person re-identification[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 2015: 1565–1573.
[6] Sun Y F, Zheng L, Deng W J, et al. SVDNet for pedestrian retrieval[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 3820–3828.
[7] Yang X, Wang M, Tao D C. Person Re-identification with metric learning using privileged information[J]. IEEE Transactions on Image Processing, 2018, 27(2): 791–805. https://arxiv.org/abs/1904.05005
[8] Zhang L, Xiang T, Gong S G. Learning a discriminative null space for person Re-identification[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016: 1239–1248.
[9] 刘辉, 彭力, 闻继伟.基于改进R-FCN的多遮挡行人实时检测算法[J].光电工程, 2019, 46(9): 180606. doi: 10.12086/oee.2019.180606
Liu H, Peng L, Wen J W. Multi-occluded pedestrian real-time detection algorithm based on preprocessing R-FCN[J]. Opto-Electronic Engineering, 2019, 46(9): 180606. doi: 10.12086/oee.2019.180606
[10] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing System, Red Hook, NY, United States, 2012, 25: 1097–1105.
[11] Li W, Zhao R, Xiao T, et al. DeepReID: deep filter pairing neural network for person Re-identification[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 2014: 152–159.
[12] Zheng L, Shen L Y, Tian L, et al. Scalable person Re-identification: a benchmark[C]//2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 2015: 1116–1124.
[13] Zheng Z D, Zheng L, Yang Y. Unlabeled samples generated by GAN improve the person Re-identification baseline in Vitro[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 3774–3782.
[14] Sudowe P, Spitzer H, Leibe B. Person attribute recognition with a jointly-trained holistic CNN model[C]//2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 2015: 329–337.
[15] 程德强, 唐世轩, 冯晨晨, 等.改进的HOG-CLBC的行人检测方法[J].光电工程, 2018, 45(8): 180111. doi: 10.12086/oee.2018.180111
Cheng D Q, Tang S X, Feng C C, et al. Extended HOG-CLBC for pedstrain detection[J]. Opto-Electronic Engineering, 2018, 45(8): 180111. doi: 10.12086/oee.2018.180111
[16] Zhao H Y, Tian M Q, Sun S Y, et al. Spindle net: person Re-identification with human body region guided feature decomposition and fusion[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017: 907–915.
[17] Wei L H, Zhang S L, Yao H T, et al. GLAD: global-local-alignment descriptor for pedestrian retrieval[C]//Proceedings of the 25th ACM International Conference on Multimedia, California, Mountain View, USA, 2017: 420–428.
[18] Sun Y F, Zheng L, Yang Y, et al. Beyond part models: person retrieval with refined part pooling[Z]. arXiv: 1711.09349[cs: CV], 2017.
https://www.researchgate.net/publication/321325809_Beyond_Part_Models_Person_Retrieval_with_Refined_Part_Pooling [19] Zheng Z D, Zheng L, Yang Y. Pedestrian alignment network for large-scale person Re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(10): 3037–3045. doi: 10.1109/TCSVT.2018.2873599
[20] Cheng D, Gong Y H, Zhou S P, et al. Person Re-identification by multi-channel parts-based CNN with improved triplet loss function[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016: 1335–1344.
[21] Zheng L, Huang Y J, Lu H C, et al. Pose-invariant embedding for deep person Re-identification[J]. IEEE Transactions on Image Processing, 2019, 28(9): 4500–4509. doi: 10.1109/TIP.2019.2910414
[22] Su C, Li J N, Zhang S L, et al. Pose-driven deep convolutional model for person Re-identification[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 3980–3989.
[23] Li D W, Chen X T, Zhang Z, et al. Learning deep context-aware features over body and latent parts for person Re-identification[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017: 7398–7407.
[24] Zhao L M, Li X, Zhuang Y T, et al. Deeply-learned part-aligned representations for person Re-identification[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 3239–3248.
[25] Li W, Zhu X T, Gong S G. Harmonious attention network for person Re-identification[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 2285–2294.
[26] Liu X H, Zhao H Y, Tian M Q, et al. HydraPlus-Net: attentive deep features for pedestrian analysis[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 350–359.
[27] Hermans A, Beyer L, Leibe B. In Defense of the triplet loss for person Re-Identification[Z]. arXiv: 1703.07737[cs: CV], 2017.
https://www.researchgate.net/publication/315514719_In_Defense_of_the_Triplet_Loss_for_Person_Re-Identification [28] Deng J, Dong W, Socher R, et al. ImageNet: a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 2009: 248–255.
[29] Zhong Z, Zheng L, Cao D L, et al. Re-ranking person Re-identification with k-reciprocal encoding[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017: 3652–3661.
[30] Lin Y T, Zheng L, Zheng Z D, et al. Improving person Re-identification by attribute and identity learning[Z]. arXiv: 1703.07220[cs: CV], 2017.
[31] Zhang X, Luo H, Fan X, et al. AlignedReID: surpassing human-level performance in person Re-identification[Z]. arXiv: 1711.08184[cs: CV], 2017.
https://arxiv.org/pdf/1711.08184 [32] Si J L, Zhang H G, Li C G, et al. Dual attention matching network for context-aware feature sequence based person Re-identification[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 5363–5372.
[33] Felzenszwalb P F, McAllester D A, Ramanan D. A discriminatively trained, multiscale, deformable part model[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 2008: 1–8.
-
访问统计


 点击扫一扫
点击扫一扫
图(6)
表(4)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


