
 E-mail Alert
E-mail Alert RSS
RSS
-
Abstract:
Moderate resolution imaging spectroradiometer (MODIS) imaging has various applications in the field of ground monitoring, cloud classification and meteorological research. However, the limitations of the sensors and external disturbance make the resolution of image still limited in a certain level. The goal of this paper is to use a single image super-resolution (SISR) method to predict a high-resolution (HR) MODIS image from a single low-resolution (LR) input. Recently, although the method based on sparse representation has tackled the ill-posed problem effectively, two fatal issues have been ignored. First, many methods ignore the relationships among patches, resulting in some unfaithful output. Second, the high computational complexity of sparse coding using l1 norm is needed in reconstruction stage. In this work, we discover the semantic relationships among LR patches and the corresponding HR patches and group the documents with similar semantic into topics by probabilistic Latent Semantic Analysis (pLSA). Then, we can learn dual dictionaries for each topic in the low-resolution (LR) patch space and high-resolution (HR) patch space and also pre-compute corresponding regression matrices for dictionary pairs. Finally, for the test image, we infer locally which topic it corresponds to and adaptive to select the regression matrix to reconstruct HR image by semantic relationships. Our method discovered the relationships among patches and pre-computed the regression matrices for topics. Therefore, our method can greatly reduce the artifacts and get some speed-up in the reconstruction phase. Experiment manifests that our method performs MODIS image super-resolution effectively, results in higher PSNR, reconstructs faster, and gets better visual quality than some current state-of-art methods.

-
Key words:
- MODIS /
- super-resolution /
- sparse representation /
- sparse coding /
- regression matrix
-

Spatial resolution is an important property of remote sensing image. As an important branch of remote sensing, the moderate resolution imaging spectroradiometer (MODIS), mounted on Terra and Aqua satellites, is an important instrument for observing global biological and physical processes in the Earth observation system (EOS) program. Itis widely used in the fields of ground detection, cloud classification and climate research because it contains rich information. However, due to sensor limitations and external interference, MODIS image resolution is still limited to a certain level. Therefore, using super-resolution technology to improve resolution of the MODIS image has a great practicalsignificance.
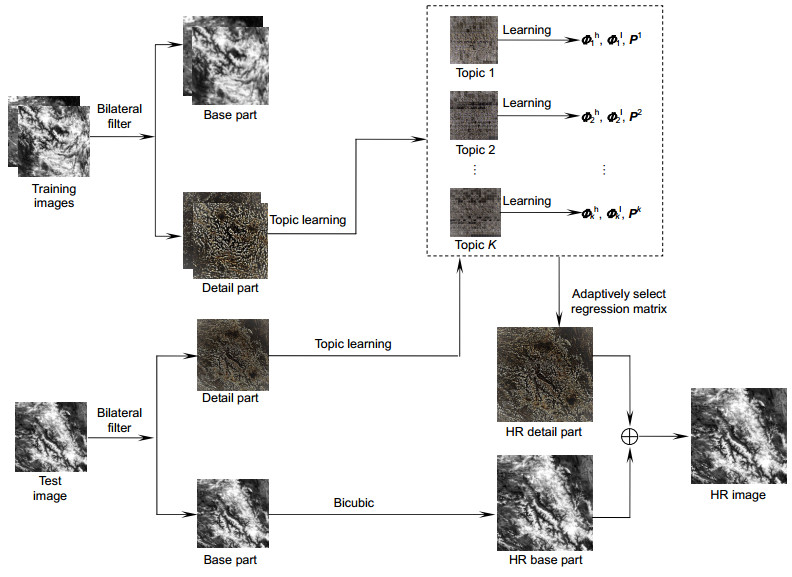
Recently, although the method based on sparse representation has tackled the ill-posed problem effectively, two fatalissues have been ignored. First, many methods ignore the relationships among patches, which will result in some unfaithful output. Second, the high computational complexity of sparse coding using l1 norm is needed in reconstructionstage. We proposed a single image super-resolution (SISR) method to predict a high-resolution (HR) MODIS imagefrom a single low-resolution (LR) input. As is known to us, infinitely many HR patches will result in the same LR patchwhen blurred and down-sampled. This is an extremely ill-pose problem. Therefore, we group the LR patches with thesimilar semantic and the corresponding HR patches into topics in the training stage and find the HR patch with the mostsimilar semantic from all possible HR patches for a given LR patches in the reconstruct stage by pLSA.
In the training stage, we discover the semantic relationships among LR patches and the corresponding HR patches andgroup the documents with the similar semantic into topics. Then, we can learn dual dictionaries for each topic in thelow-resolution (LR) patch space and high-resolution (HR) patch space and also pre-compute corresponding regressionmatrices for dictionary pairs. In the reconstruction stage, for the test image we infer locally which topic it corresponds toand adaptive to select the regression matrix to reconstruct HR image by semantic relationships. With above processing,we can get the optimal reconstruction for the HR image.
Our method discovered the relationships among patches and pre-computed the regression matrices for topics. Therefore, our method can greatly reduce the artifacts and get some speed-up in the reconstruction phase. Experiment manifests that our method performs MODIS image super-resolution effectively, results in higher PSNR, reconstructs faster,and gets better visual quality than some current state-of-art methods.
-

-

Figure 2. Collection of documents under different topics. (a) Topic 8. (b) Topic 9. (c) Topic 10.

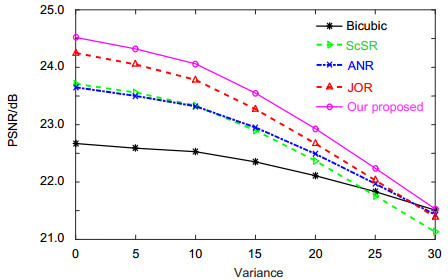
Figure 3. Visual comparison with different SR results on channel 1 image by different methods (S=3). (a) Bicubic method. (b) ScSR method. (c) ANR method. (d) JOR method. (e) Our method. (f) Original image.
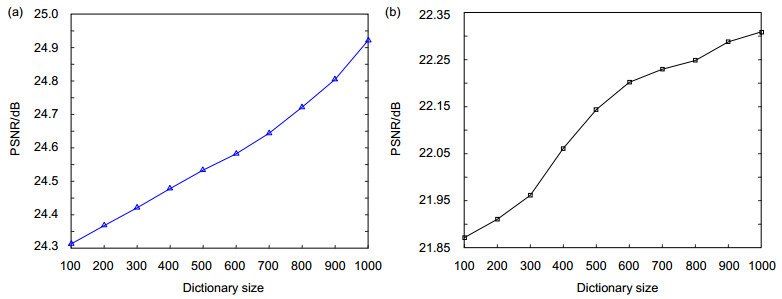
Figure 5. PSNR (dB) with different dictionary sizes on channel 1 image. (a) S=2. (b) S=3.
Table 1. PSNR(dB) and SSIM of the reconstruct images by different methods.
Factor Image Bicubic ScSR ANR JOR Our method ×2 Channel 1 22.67/0.9665 23.71/0.9739 23.65/0.9727 24.25/0.9767 24.53/0.9785 Channel 2 23.33/0.9696 24.44/0.9767 24.37/0.9775 25.27/0.9813 25.40/0.9815 Channel 3 25.42/0.9369 26.08/0.9465 26.23/0.9732 26.79/0.9787 26.92/0.9792 Channel 4 25.21/0.9433 25.89/0.9522 25.99/0.9740 26.45/0.9746 26.73/0.9751 Channel 7 23.25/0.9680 24.28/0.9750 24.37/0.9775 24.87/0.9795 25.02/0.9803 ×3 Channel 1 21.06/0.9579 21.78/0.9630 21.79/0.9632 22.01/0.9653 22.14/0.9656 Channel 2 21.64/0.9617 22.42/0.9669 22.42/0.9670 22.96/0.9681 23.03/0.9688 Channel 3 24.22/0.9592 24.73/0.9632 24.72/0.9625 24.93/0.9657 25.16/0.9662 Channel 4 23.97/0.9598 24.50/0.9636 24.50/0.9636 24.86/0.9649 25.01/0.9654 Channel 7 21.62/0.9602 22.37/0.9656 22.39/0.9659 22.60/0.9693 22.76/0.9680  下载: 导出CSV
下载: 导出CSV
Table 2. Consumed time(s) of different methods.
Factor Method Channel 1 Channel 2 Channel 3 Channel 4 Channel 7 Average ×2 ScSR 548.87 528.34 536.42 553.60 568.73 547.192 ANR 3.53 3.26 3.31 3.69 3.51 3.460 JOR 50.12 47.33 48.45 48.34 52.62 49.372 Our method 58.11 55.82 58.25 53.89 60.64 57.342 ×3 ScSR 537.21 583.82 598.54 612.77 623.28 591.124 ANR 2.99 2.14 2.89 3.08 3.27 2.874 JOR 28.34 29.53 30.12 32.21 36.73 31.386 Our method 41.93 49.01 46.25 45.25 48.54 46.196
下载: 导出CSV
-
[1] Farsiu S, Robinson M D, Elad M, et al. Fast and robust multiframe super resolution[J]. IEEE Transactions on Image Processing, 2004, 13(10): 1327–1344. doi: 10.1109/TIP.2004.834669
[2] Lu Yao, Inamura M. Spatial resolution improvement of remote sensing images by fusion of subpixel-shifted multi-observation images[J]. International Journal of Remote Sensing, 2003, 24(23): 4647–4660. doi: 10.1080/01431160310001595064
[3] Aumann H H, Chahine M T, Gautier C, et al. AIRS/AMSU/HSB on the Aqua mission: design, science objectives, data products, and processing systems[J]. IEEE Transactions on Geoscience and Remote Sensing, 2003, 41(2): 253–264. doi: 10.1109/TGRS.2002.808356
[4] Chan T F, Ng M K, Yau A C, et al. Superresolution image reconstruction using fast inpainting algorithms[J]. Applied and Computational Harmonic Analysis, 2007, 23(1): 3–24. doi: 10.1016/j.acha.2006.09.005
[5] Keys R. Cubic convolution interpolation for digital image processing[J]. IEEE Transactions on Acoustics, Speech and Signal Processing, 2003, 29(6): 1153–1160. http://cn.bing.com/academic/profile?id=9f0cfbe5a86e2628e56bc547edc0891d&encoded=0&v=paper_preview&mkt=zh-cn
[6] Yang Shuyuan, Wang Min, Chen Yiguang, et al. Single-image super-resolution reconstruction via learned geometric dictionaries and clustered sparse coding[J]. IEEE Transactions on Image Processing, 2012, 21(9): 4016–4028. doi: 10.1109/TIP.2012.2201491
[7] Yang Jianchao, Wright J, Huang T, et al. Image super-resolution as sparse representation of raw image patches[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Anchorage AK, USA, 2008: 1–8.
[8] Yang Jianchao, Wright J, Huang T S, et al. Image super-resolution via sparse representation[J]. IEEE Transactions on Image Processing, 2010, 19(11): 2861–2873. doi: 10.1109/TIP.2010.2050625
[9] Zhou Ying, Fu Randi, Yan Wen, et al. A method of infrared nephogram super-resolution based on structural group sparse representation[J]. Opto-Electronic Engineering, 2016, 43(12): 126–132. http://www.oee.ac.cn/EN/abstract/abstract1855.shtml
[10] Chang Hong, Yeung D Y, Xiong Yimin M. Super-resolution through neighbor embedding[C]//Proceedings of the 2004 IEEE Computer Society Computer Vision and Pattern Recognition, Washington DC, USA, 2004: 275–282.
[11] Roweis S T, Saul L K. Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290(5500): 2323–2326. doi: 10.1126/science.290.5500.2323
[12] Donoho D L. Compressed sensing[J]. IEEE Transactions on Information Theory, 2012, 52(4): 1289–1306. http://cn.bing.com/academic/profile?id=2f57a68c1f486cd656875caabf799215&encoded=0&v=paper_preview&mkt=zh-cn
[13] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations[C]//Proceedings of 7th International Conference on Curves and Surfaces, Avignon, France, 2010: 711–730.
[14] Aharon M, Elad M, Bruckstein A. rmK-SVD: an algorithm for designing overcomplete dictionaries for sparse representation [J]. IEEE Transactions on Signal Processing, 2006, 54(11): 4311–4322. doi: 10.1109/TSP.2006.881199
[15] Timofte R, De V, Gool L V. Anchored neighborhood regression for fast example-based super-resolution[C]//Proceedings of IEEE International Conference on Computer Vision, Sydney NSW, Australia, 2013: 1920–1927.
[16] Hofmann T. Probabilistic latent semantic analysis[C]// Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, Stockholm, Sweden, 1999: 289–296.
[17] Zhao Yao, Chen Qian, Sui Xiubao, et al. A novel infrared image super-resolution method based on sparse representation[J]. Infrared Physics & Technology, 2015, 71: 506–513. https://www.sciencedirect.com/science/article/pii/S1350449515001541
[18] Purkait P, Chanda B. Image upscaling using multiple dictionaries of natural image patches[C]//Proceedings of Asian Conference on Computer Vision, Daejeon, Korea, 2012: 284–295.
[19] Rubinstein R, Zibulevsky M, Elad M. Efficient Implementation of the K-SVD Algorithm Using Batch Orthogonal Matching Pursuit[R]. Technion-Computer Science Department, Technical Report CS, 2008.
[20] Timofte R, van Gool L. Adaptive and Weighted Collaborative Representations for image classification[J]. Pattern Recognition Letters, 2014, 43: 127–135. doi: 10.1016/j.patrec.2013.08.010
[21] Dai D, Timofte R, Van Gool L. Jointly optimized regressors for image super-resolution[J]. Computer Graphics Forum, 2015, 34(2): 95–104. doi: 10.1111/cgf.2015.34.issue-2
-
 点击扫一扫
点击扫一扫
图(5)
表(2)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


