
 E-mail Alert
E-mail Alert RSS
RSS
Hypergraph computed efficient transmission multi-scale feature small target detection algorithm
-
摘要
无人机航拍图像具有背景复杂、目标小且密集的特点。在无人机航拍图像检测中,存在小目标检测精度低和模型参数量大的问题。因此,提出基于超图计算的多尺度特征高效传递小目标检测算法。首先,设计高效传递多尺度特征金字塔网络作为颈部网络,在中间层融合多层特征,并将其向相邻各层直接传递,有效缓解传递路径冗长导致的信息丢失问题。另外,特征融合环节借助超图对高阶特征进行建模,从而增强模型的非线性表达能力。其次,设计轻量化动态任务引导检测头,借助共享机制在参数量较少的情况下,有效解决传统解耦头中分类与定位任务空间不一致导致检测目标不准确的问题。最后,基于层自适应幅度的剪枝轻量化模型,进一步减小模型体积。实验结果表明,此算法在VisDrone2019数据集上表现出比其他架构更优越的性能,精度mAP0.5和参数量分别达到了42.4%和4.8 M,与基准YOLOv8相比参数量降低了54.7%,该模型实现检测性能与资源耗费之间的良好平衡。
Abstract
UAV aerial images have the characteristics of complex background, small and dense targets. Aiming at the problems of low precision and a large number of model parameters in UAV aerial image detection, an efficient multi-scale feature transfer small target detection algorithm based on hypergraph computation is proposed. Firstly, a multi-scale feature pyramid network is designed as a neck network to effectively reduce the problem of information loss caused by lengthy transmission paths by fusing multi-layer features in the middle layer and transmitting them directly to adjacent layers. In addition, the feature fusion process uses hypergraphs to model higher-order features, improving the nonlinear representation ability of the model. Secondly, a lightweight dynamic task-guided detection head is designed to effectively solve the problem of inaccurate detection targets caused by inconsistent classification and positioning task space in the traditional decoupling head with a small number of parameters through sharing mechanism. Finally, the pruning lightweight model based on layer adaptive amplitude is used to further reduce the model volume. The experimental results show that this algorithm has better performance than other architectures on VisDrone2019 dataset, with the accuracy mAP0.5 and parameter number reaching 42.4% and 4.8 M, respectively. Compared with the benchmark YOLOv8, the parameter number is reduced by 54.7%. The model achieves a good balance between detection performance and resource consumption.
-
Key words:
- small target detection /
- hypergraph /
- decoupling head /
- light weight
-
Overview
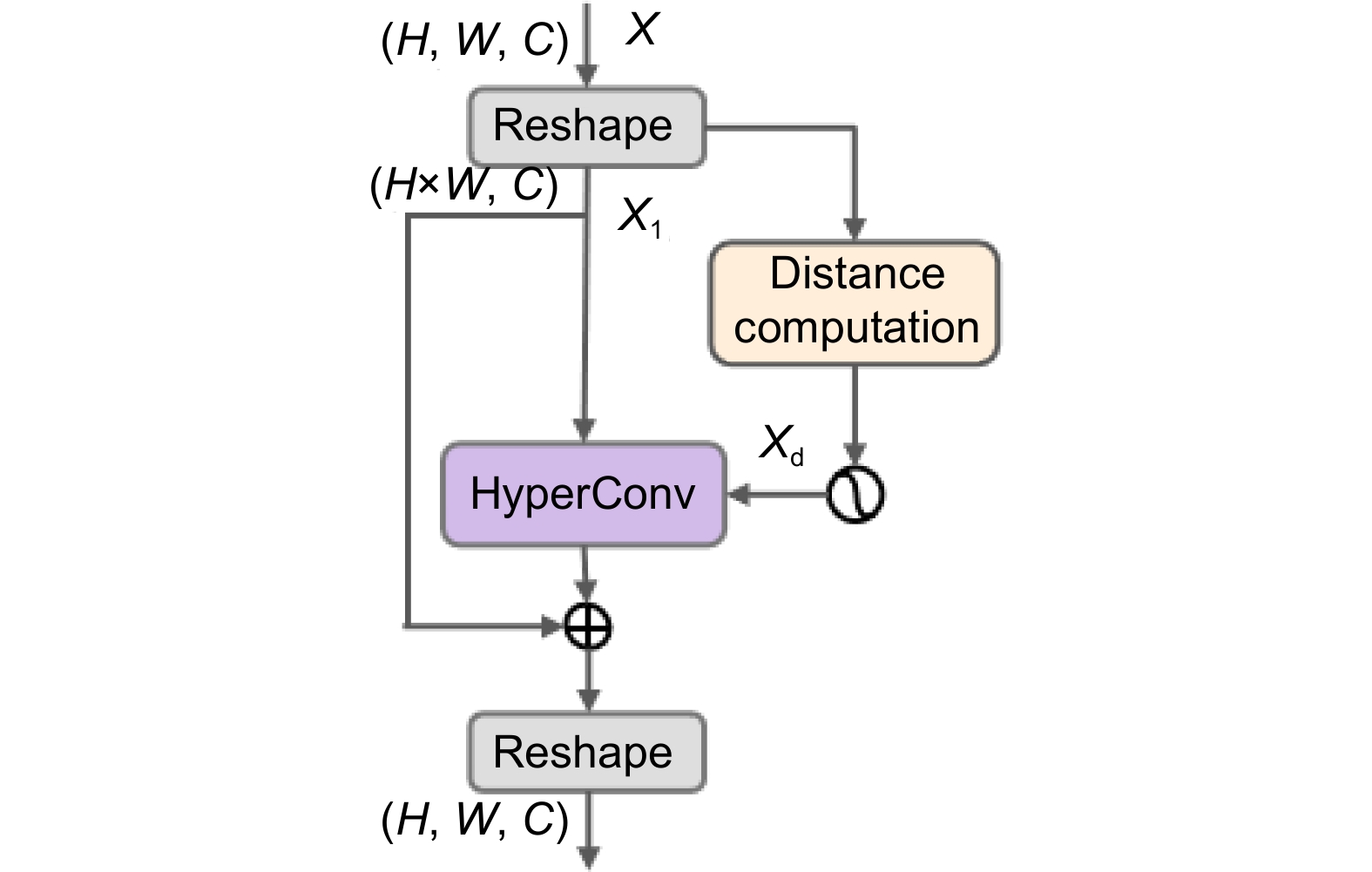
Overview: Aiming at the characteristics of UAV aerial images such as complex background, small target size and dense distribution due to high-angle shooting, as well as the common problems of insufficient accuracy and parameter redundancy in existing detection models, this paper proposes an efficient multi-scale feature transfer small target detection algorithm based on hypergraph computation. By systematically improving network architecture, feature fusion mechanism and model compression strategy, the algorithm achieves an effective balance between detection performance and computational efficiency. In terms of network architecture design, this study innovatively constructs a multi-scale feature pyramid network as a neck structure. Different from the traditional feature pyramid layer-by-layer transmission, this network transmits the features of the middle layer directly to the adjacent layers through the cross-layer feature aggregation mechanism, which significantly shortens the feature transmission path. Specifically, by integrating shallow high-resolution features and deep semantic features, the spatial information loss caused by long-distance transmission is effectively alleviated, so that the location information and texture features of small targets can be completely preserved. In the feature fusion stage, hypergraph is introduced to break through the limitation of binary relation of traditional graph neural networks. By connecting multiple feature nodes with hyperedge and establishing a high-order feature interaction model, the nonlinear correlation between the object and the complex background in UAV images can be accurately described. This hypergraph structure can not only capture the geometric correlation between objects but also model the potential relationship between the interference factors such as illumination change and occlusion and the object features. Secondly, a lightweight dynamic task-guided detection head is designed to effectively solve the problem of inaccurate detection targets caused by inconsistent classification and positioning task space in the traditional decoupling head with a small number of parameters by sharing mechanism. Finally, a layer adaptive pruning amplitude strategy is used to break through the limitation of the traditional global pruning threshold. By analyzing the weight distribution characteristics of each convolution layer, the calculation model of the pruning coefficient based on layer sensitivity is established. Experimental results show that the proposed algorithm performs better than other architectures on VisDrone2019 dataset, with an accuracy of 42.4% and many parameters of 4.8 M. Compared to the benchmark YOLOv8, the number of parameters has been reduced by 54.7%. This model achieves a good balance between detection performance and resource consumption.
-

-
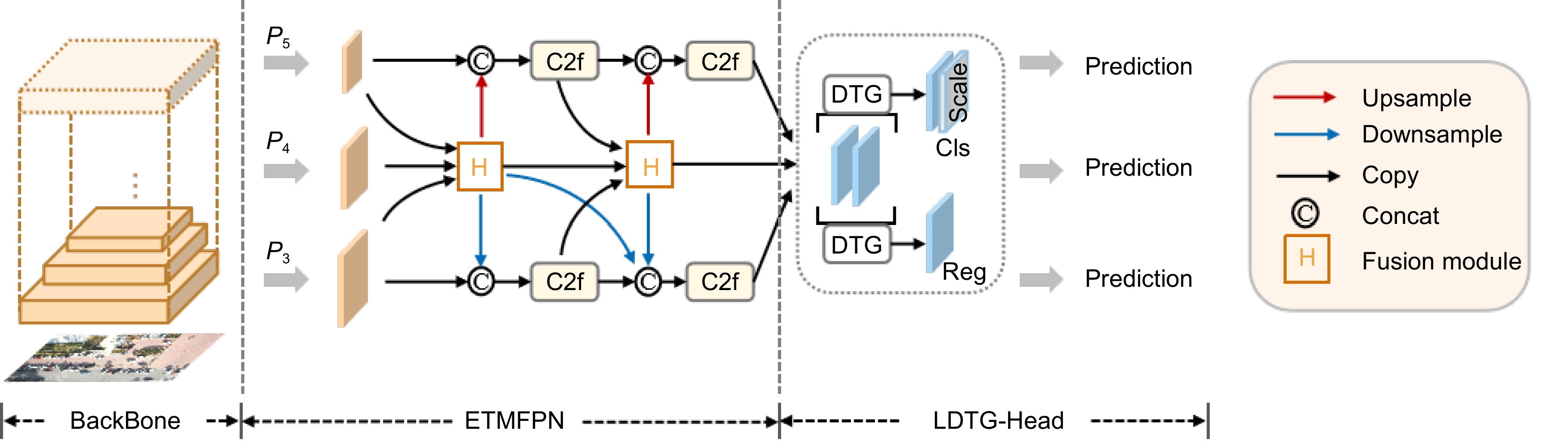
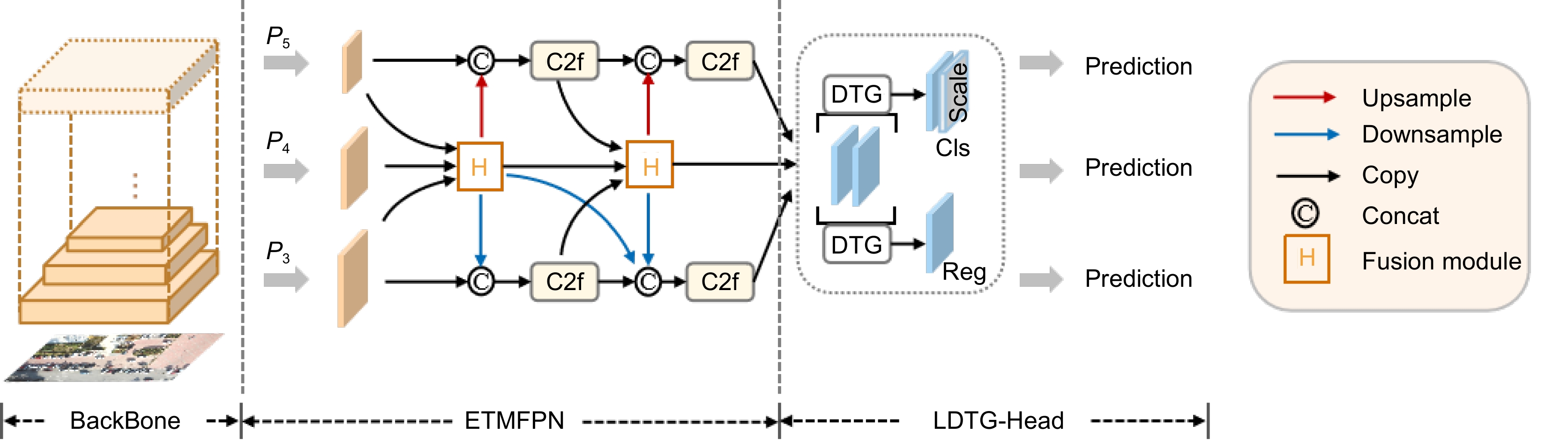
图 1 基于超图计算的高效传递多尺度特征小目标检测算法
Figure 1. Efficient transfer multi-scale feature small target detection algorithm based on hypergraph computing
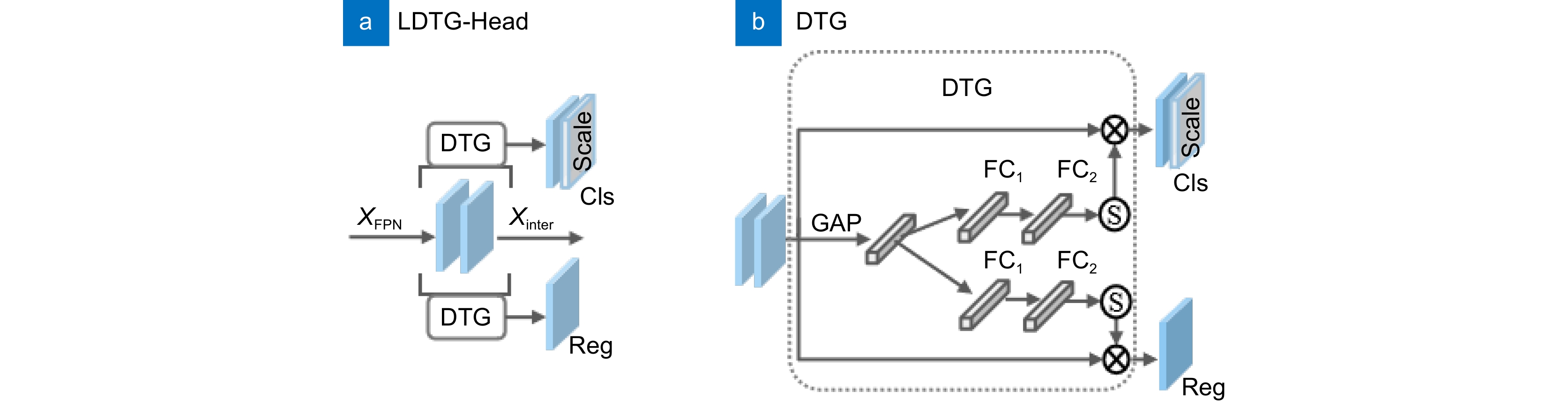
图 5 LDTG-Head和DTG模块结构示意图。(a) LDTG-Head;(b) DTG模块
Figure 5. Structure diagram of LDTG-Head and DTG module. (a) LDTG-Head; (b) DTG module

图 6 普通卷积与分组卷积对比。(a)普通卷积;(b)分组卷积
Figure 6. Comparison between ordinary convolution and group convolution. (a) Ordinary convolution; (b) Group convolution
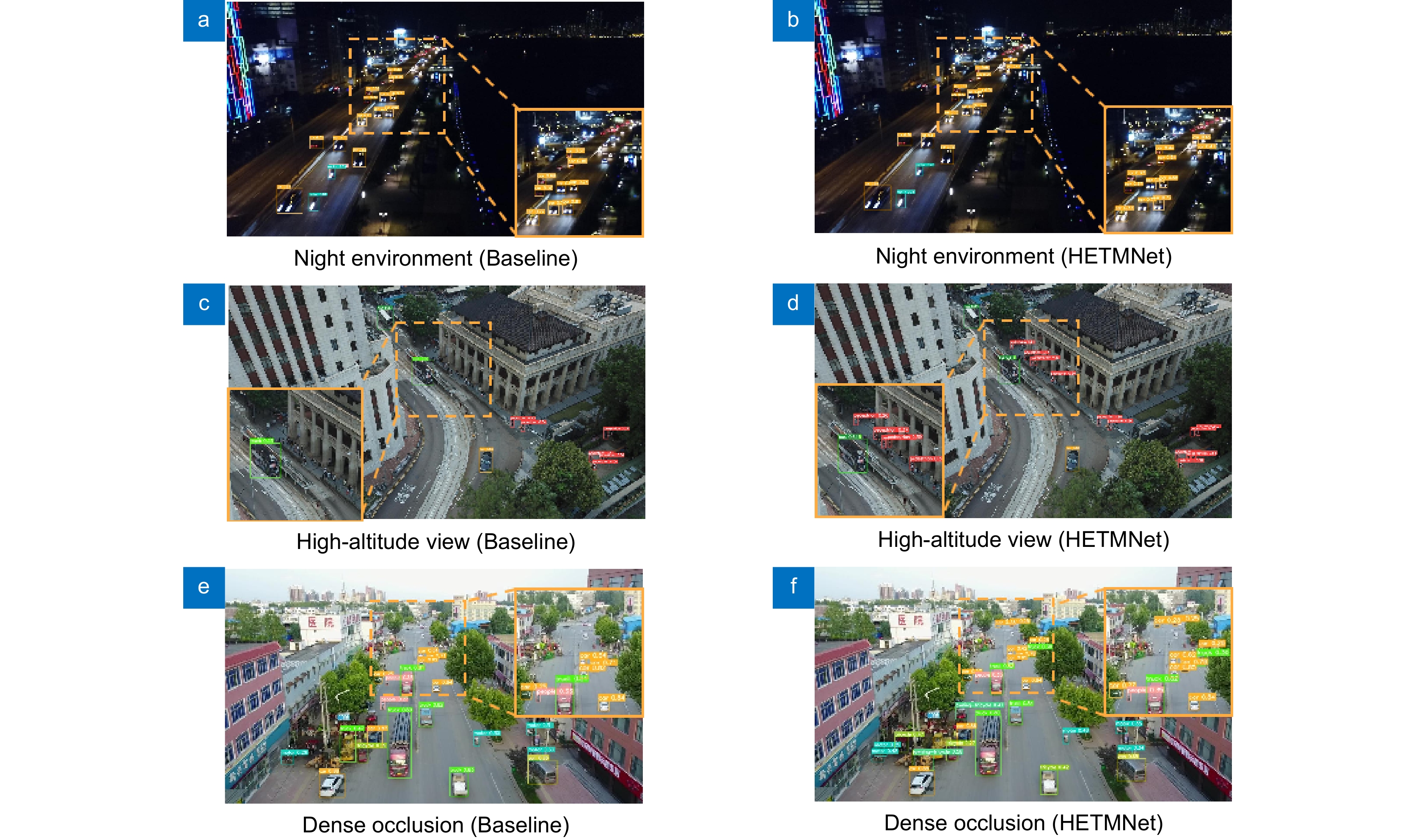
图 8 VisDrone 数据集上的复杂场景目标检测效果对比。(a)(b)夜间环境;(c)(d)高空视角;(e)(f)密集遮挡
Figure 8. Comparison of target detection effectiveness in complex scenes on VisDrone dataset. (a)(b) Night environment; (c)(d) High-altitude view; (e)(f) dense occlusion scenes
表 1 不同算法在 VisDrone 数据集上的平均精度和参数量对比结果
Table 1. Comparison results of AP and params of different algorithms on VisDrone dataset
Method AP/% $ {mAP}_{0.5} $/% Params/M Pedestrian People Bicycle Car Van Truck Tricycle Awning-Tricycle Bus Motor Faster R-CNN[33] 20.9 14.8 7.3 51.0 29.7 19.5 14.0 8.8 30.5 21.2 21.8 — Cascade R-CNN 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 — YOLOv5 39.0 31.3 11.2 73.5 35.4 29.5 20.5 11.1 43.1 37.0 33.2 7.0 YOLOX[34] 34.8 24.5 16.9 72.4 34.4 40.5 23.1 17.8 53.1 36.0 35.3 54.2 YOLOv7[35] 37.9 34.6 9.4 76.1 36.3 29.8 20.1 10.6 43.2 41.8 34.0 6.0 YOLOv8 40.3 30.1 12.5 77.7 45.8 36.0 27.0 14.9 54.5 42.7 38.2 10.6 YOLOv9[36] 42.4 33.4 14.2 79.5 45.8 39.4 29.5 16.9 57.5 44.5 40.3 6.8 YOLOv10[37] 43.4 34.7 14.5 80.5 46.5 37.3 28.0 15.8 55.2 45.7 40.2 6.9 Mamba-YOLO[38] 41.0 31.7 11.5 79.3 44.2 33.2 26.1 13.8 56.0 43.0 38.0 5.7 BDAD-YOLO[39] 37.8 30.0 10.5 77.0 42.4 32.5 24.8 13.6 53.0 39.6 36.1 3.2 HETMNet(ours) 45.2 35.8 14.2 81.6 49.7 41.1 30.7 18.0 60.5 51.1 42.4 4.8  下载: 导出CSV
下载: 导出CSV
表 2 HETMNet在VisDrone数据集上的消融实验结果
Table 2. Results of HETMNet's ablation experiment on the VisDrone dataset
Model ETMFPN LDTG-Head LAMP $ {{m}{A}{P}}_{0.5} $/% $ {{m}{A}{P}}_{0.5:0.95} $/% Params/M GFLOPs Size/MB Model 1 — — — 38.2 22.8 10.6 28.5 21.5 Model 2 √ — — 41.5 25.1 9.7 29.5 19.6 Model 3 — √ — 40.8 24.8 8.1 24.3 16.4 Model 4 √ √ — 42.0 25.7 9.2 28.6 18.8 Model 5 √ √ √ 42.4 26.0 4.8 20.4 9.9
下载: 导出CSV
表 3 ETMFPN消融实验结果
Table 3. ETMFPN ablation experiment results
Model $ {{m}{A}{P}}_{0.5} $/% $ {{m}{A}{P}}_{0.5:0.95} $/% Params/M +PAFPN 38.2 22.8 10.6 +GoldYOLO 40.5 24.4 13.0 +BiFPN 40.9 24.9 7.0 +ETMFPN 41.5 25.1 9.7
下载: 导出CSV
表 4 LAMP消融实验结果
Table 4. LAMP ablation experiment results
Speed_up $ {{m}{A}{P}}_{0.5} $/% Params/M — 42.0 9.2 1.25 42.6 5.6 1.35 42.4 5.0 1.40 42.4 4.8 1.45 42.3 4.6
下载: 导出CSV
-
参考文献
[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580–587. https://doi.org/10.1109/CVPR.2014.81.
[2] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 2980–2988. https://doi.org/10.1109/ICCV.2017.322.
[3] Cai Z W, Vasconcelos N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 6154–6162. https://doi.org/10.1109/CVPR.2018.00644.
[4] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779–788. https://doi.org/10.1109/CVPR.2016.91.
[5] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 21–37. https://doi.org/10.1007/978-3-319-46448-0_2.
[6] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 2999–3007. https://doi.org/10.1109/ICCV.2017.324.
[7] Ghiasi G, Lin T Y, Le Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 7029–7038. https://doi.org/10.1109/CVPR.2019.00720.
[8] Jiang Y Q, Tan Z Y, Wang J Y, et al. GiraffeDet: a heavy-neck paradigm for object detection[C]//Proceedings of the 10th International Conference on Learning Representations, 2022.
[9] Ma M, Pang H. SP-YOLOv8s: an improved YOLOv8s model for remote sensing image tiny object detection[J]. applied sciences, 2023, 13(14): 8161
[10] Wang K X, Liew J H, Zou Y T, et al. PANet: few-shot image semantic segmentation with prototype alignment[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 9196–9205. https://doi.org/10.1109/ICCV.2019.00929.
[11] Lin T Y, DollárP, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936–944. https://doi.org/10.1109/CVPR.2017.106.
[12] Tan M X, Pang R M, Le Q V. EfficientDet: scalable and efficient object detection[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10778–10787. https://doi.org/10.1109/CVPR42600.2020.01079.
[13] Liu S, Qi L, Qin H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8759–8768. https://doi.org/10.1109/CVPR.2018.00913.
[14] Yang G Y, Lei J, Zhu Z K, et al. AFPN: asymptotic feature pyramid network for object detection[C]//Proceedings of 2023 IEEE International Conference on Systems, Man, and Cybernetics, 2023: 2184–2189. https://doi.org/10.1109/SMC53992.2023.10394415.
[15] Xue Y J, Ju Z Y, Li Y M, et al. MAF-YOLO: multi-modal attention fusion based YOLO for pedestrian detection[J]. Infrared Phys Technol, 2021, 118: 103906. doi: 10.1016/j.infrared.2021.103906
[16] Xu X Z, Jiang Y Q, Chen W H, et al. DAMO-YOLO: a report on real-time object detection design[Z]. arXiv: 2211.15444, 2023. https://doi.org/10.48550/arXiv.2211.15444.
[17] Wang C C, He W, Nie Y, et al. Gold-YOLO: efficient object detector via gather-and-distribute mechanism[C]//Proceedings of the 37th International Conference on Neural Information Processing Systems, 2023: 2224.
[18] Gao Y, Zhang Z Z, Lin H J, et al. Hypergraph learning: methods and practices[J]. IEEE Trans Pattern Anal Mach Intell, 2020, 44(5): 2548−2566. doi: 10.1109/TPAMI.2020.3039374
[19] Gao Y, Feng Y F, Ji S Y, et al. HGNN+: general hypergraph neural networks[J]. IEEE Trans Pattern Anal Mach Intell, 2023, 45(3): 3181−3199. doi: 10.1109/TPAMI.2022.3182052
[20] Liu Y Y, Yu Z Y, Zong D L, et al. Attention to task-aligned object detection for end-edge-cloud video surveillance[J]. IEEE Internet Things J, 2024, 11(8): 13781−13792. doi: 10.1109/JIOT.2023.3340151
[21] Shen Q, Zhang L, Zhang Y X, et al. Distracted driving behavior detection algorithm based on lightweight StarDL-YOLO[J]. Electronics, 2024, 13(16): 3216. doi: 10.3390/electronics13163216
[22] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5MB model size[Z]. arXiv: 1602.07360, 2016. https://doi.org/10.48550/arXiv.1602.07360.
[23] Zhang X Y, Zhou X Y, Lin M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 6848–6856. https://doi.org/10.1109/CVPR.2018.00716.
[24] Howard A G, Zhu M L, Chen B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[Z]. arXiv: 1704.04861, 2017. https://doi.org/10.48550/arXiv.1704.04861.
[25] Tan M X, Le Q. EfficientNet: rethinking model scaling for convolutional neural networks[C]//Proceedings of the 36th International Conference on Machine Learning, 2019: 6105–6114.
[26] Han K, Wang Y H, Tian Q, et al. GhostNet: more features from cheap operations[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1577–1586. https://doi.org/10.1109/CVPR42600.2020.00165.
[27] 王舒梦, 徐慧英, 朱信忠, 等. 基于改进YOLOv8n航拍轻量化小目标检测算法: PECS-YOLO[J]. 计算机工程, 2024. doi: 10.19678/j.issn.1000-3428.0069353
Wang S M, Xu H Y, Zhu X Z, et al. Lightweight small object detection algorithm based on improved YOLOv8n aerial photography: PECS-YOLO[J]. Comput Eng, 2024. doi: 10.19678/j.issn.1000-3428.0069353
[28] 张佳承, 韦锦, 陈义时. 改进YOLOv8的实时轻量化鲁棒绿篱检测算法[J]. 计算机工程, 2024. doi: 10.19678/j.issn.1000-3428.0069524
Zhang J C, Wei J, Chen Y S. Improved YOLOv8 real-time lightweight robust hedge detection algorithm[J]. Comput Eng, 2024. doi: 10.19678/j.issn.1000-3428.0069524
[29] Gale T, Elsen E, Hooker S. The state of sparsity in deep neural networks[Z]. arxiv: 1902.09574, 2019. https://doi.org/10.48550/arXiv.1902.09574.
[30] Evci U, Gale T, Menick J, et al. Rigging the lottery: making all tickets winners[C]//Proceedings of the 37th International Conference on Machine Learning, 2020: 276.
[31] Lee J, Park S, Mo S, et al. Layer-adaptive sparsity for the magnitude-based pruning[C]//Proceedings of the 9th International Conference on Learning Representations, 2021.
[32] Feng Y F, Huang J G, Du S Y, et al. Hyper-YOLO: when visual object detection meets hypergraph computation[J]. IEEE Trans Pattern Anal Mach Intell, 2025, 47(4): 2388−2401. doi: 10.1109/TPAMI.2024.3524377
[33] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031
[34] Ge Z, Liu S T, Wang F, et al. YOLOX: exceeding YOLO series in 2021[Z]. arXiv: 2107.08430, 2021. https://doi.org/10.48550/arXiv.2107.08430.
[35] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721.
[36] Wang C Y, Yeh I H, Liao H Y M. YOLOv9: learning what you want to learn using programmable gradient information[C]//Proceedings of the 18th European Conference on Computer Vision, 2025: 1–21. https://doi.org/10.1007/978-3-031-72751-1_1.
[37] Wang A, Chen H, Liu L H, et al. YOLOv10: real-time end-to-end object detection[C]//Proceedings of the 38th Conference on Neural Information Processing Systems, 2024.
[38] Wang Z Y, Li C, Xu H Y, et al. Mamba YOLO: SSMs-based YOLO For object detection[Z]. arXiv: 2406.05835v1, 2024. https://doi.org/10.48550/arXiv.2406.05835.
[39] 孙佳宇, 徐民俊, 张俊鹏, 等. 优化改进YOLOv8无人机视角下目标检测算法[J]. 计算机工程与应用, 2025, 61(1): 109−120. doi: 10.3778/j.issn.1002-8331.2405-0030
Sun J Y, Xu M J, Zhang J P, et al. Optimized and improved YOLOv8 target detection algorithm from UAV perspective[J]. Comput Eng Appl, 2025, 61(1): 109−120. doi: 10.3778/j.issn.1002-8331.2405-0030
-
访问统计


 点击扫一扫
点击扫一扫
图(9)
表(4)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


