
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
针对视网膜显微手术中的复杂干扰情况,本文利用深度学习的方法提出一种手术器械检测算法。首先,构建并手动标注了RET1数据集,并以YOLO框架为基础,针对部分图像退化,提出利用SGConv和RGSCSP特征提取模块增强模型对图像细节特征的提取能力。针对IoU损失函数收敛速度慢以及边界框回归不准确的问题,提出DeltaIoU边界框损失函数。最后,运用动态头部和解耦头部的集成对特征融合的目标进行检测。实验结果表明,提出的方法在RET1数据集上mAP50-95达到72.4%,相较原有算法提升了3.8%,并能在复杂手术场景中对器械有效检测,为后续手术显微镜自动跟踪以及智能化手术导航提供有效帮助。
Abstract
To address the challenges posed by complex interference in retinal microsurgery, this study presents a deep learning-based algorithm for surgical instrument detection. The RET1 dataset was first constructed and meticulously annotated to provide a reliable basis for training and evaluation. Building upon the YOLO framework, this study introduces the SGConv and RGSCSP feature extraction modules, specifically designed to enhance the model's capability to capture fine-grained image details, especially in scenarios involving degraded image quality. Furthermore, to address the issues of slow convergence in IoU loss and inaccuracies in bounding box regression, the DeltaIoU bounding box loss function was proposed to improve both detection precision and training efficiency. Additionally, the integration of dynamic and decoupled heads optimizes feature fusion, further enhancing the detection performance. Experimental results demonstrate that the proposed method achieves 72.4% mAP50-95 on the RET1 dataset, marking a 3.8% improvement over existing algorithms. The method also exhibits robust performance in detecting surgical instruments under various complex surgical scenarios, underscoring its potential to support automatic tracking in surgical microscopes and intelligent surgical navigation systems.
-
Key words:
- retinal microsurgery /
- object detection /
- YOLO /
- surgical microscope /
- loss function
-
Overview
Overview: The integration of computer vision into ophthalmic surgical procedures, particularly in digital navigation microscopes, has opened new avenues for real-time instrument tracking. Accurate localization of surgical instruments during retinal surgery presents unique challenges, such as reflections, motion artifacts, and obstructions, which impede precise detection. To address these challenges, this study introduces RM-YOLO, a specialized deep learning-based detection algorithm tailored for retinal microsurgery. The model is designed to ensure accurate instrument localization in real-time, offering substantial advancements over existing approaches.
Given the scarcity of annotated data specific to retinal microsurgery, the RET1 dataset was constructed, derived from high-resolution surgical videos and manually annotated for three primary instruments: vitrectomy cutter, light pipe, and peeling forceps. This dataset encompasses various surgical conditions, including occlusions, low-light environments, and reflections, ensuring robust model training and evaluation.
The proposed algorithm leverages a customized YOLO framework and incorporates novel modules to enhance performance. The SGConv and RGSCSP modules were specifically designed to improve feature extraction capabilities, addressing the limitations of conventional convolutional layers by employing channel shuffling and re-parameterization techniques to maximize feature diversity and minimize parameter count. Additionally, a dynamic head architecture was implemented to integrate multi-scale, spatial, and task-specific attention mechanisms, enhancing the model's ability to capture complex features across varying scales. For bounding box regression, DeltaIoU loss was introduced as a refined metric that improves convergence speed and accuracy, particularly in ambiguous annotation scenarios.
Extensive experiments on the RET1 dataset demonstrate that RM-YOLO achieves an mAP50-95 of 72.4%, outperforming existing models in precision and recall with only 7.4 million parameters and 20.7 GFLOPs. Comparative analysis with traditional and modern detection models, including Faster R-CNN, YOLO series, and RT-DETR, reveals that RM-YOLO not only achieves superior accuracy but also addresses the high rate of missed detections common in retinal microsurgery applications.
The ablation studies underscore the contributions of each module, with dynamic head and RSGCSP modules providing significant boosts in model performance by enhancing the robustness of feature representation. DeltaIoU loss further complements these improvements by ensuring precise bounding box regression in challenging visual conditions.
-
1. 引 言
数字眼科手术显微镜因其优异的数字化能力、操作的便利性以及可提升手术成功率的优势,在眼科手术中得到了广泛应用[1]。在临床实践中,手术显微镜提供的视野往往有限,如何辅助医生移动显微镜的视野成为了一项难题[2]。手动跟踪手术器械不仅会干扰手术过程,还会延长手术时间。为了使显微镜自动地跟踪手术器械,必须准确识别显微镜下器械的位置。因此,针对手术器械的精准检测成为一项关键任务。然而在视网膜手术中,手术环境尤为复杂,这对检测精度提出了高要求[3]。显微镜的对焦不准造成的模糊、背景突然变暗、严重的图像失真、光源的变化、器械反光、阴影、器械与病变之间的遮挡等问题,均对视网膜显微手术中的器械检测方法构成重大挑战[4-5]。
基于视觉的手术器械检测方法因其易于实现逐渐成为研究热点[6]。Allan等[7]分析利用各种颜色空间来区分手术器械与组织、器官的颜色差异。Alsheakhali等[8]通过结合RGB颜色空间与Lab颜色空间,从图像的整体RGB空间中提取手术器械的边缘信息,随后在Lab颜色空间中精确定位关键点。颜色特征提取的方法比较简单,但在手术场景中,金属器械的反光特性使检测结果易受光照条件影响。Sznitman等[9]使用贝叶斯滤波器训练主动测试模型,计算边界内的像素强度来确定器械所指的方向。这种方法的稳定性不及基于梯度的方法,并且可能将生理组织误识别为手术器械。
近年来,基于深度卷积神经网络(DCNN)的目标检测在多个医学影像任务中表现出卓越的性能[10]。Girshick等[11]于2015年提出了Fast R-CNN。随后,微软研究团队推出了经典的两阶段目标检测算法Faster R-CNN[12]。2016年,Redmon等[13]提出了YOLO (you only look once)算法,这是最早的单阶段目标检测算法之一。YOLO将目标检测视为回归问题,直接处理整张图像,预测边界框的坐标、框内目标的类别及置信度。目前,许多研究已将深度学习的概念应用于手术器械检测。Sarikaya等[14]引入了Faster R-CNN网络,用于识别和跟踪微创手术器械,即使器械被遮挡仍能实现有效的检测。Zhang等[15]提出了一种基于Faster R-CNN的锚框生成网络用于检测腹腔镜下的手术器械,该方法结合了两阶段网络的高精度和单阶段网络的高效性。Pan等[16]提出DBH-YOLO (dual-branched head YOLO),一种基于双分支检测头的手术器械检测方法,结合OIoU损失和改进的SoftNMS策略,在复杂背景下实现了高效的定位和分类。Zhao等[17]提出了一种基于时空上下文和深度学习的手术器械实时跟踪算法,该算法利用空间变换网络和卷积神经网络实现手术工具的定位,并通过时空上下文学习算法进行高效的帧间跟踪。当前的研究多聚焦于腹腔镜下的手术器械检测,对视网膜手术器械检测的关注相对不足。
尽管上述检测算法取得了显著性进展,但在视网膜手术的器械检测中仍存在很大局限性。在复杂的眼底手术图像中,存在各种影响成像效果或突发的情况,对模型鲁棒性和稳定性的考验极大,已有的算法难以在极端情况下完成精确检测,目标识别的分类精度和目标定位的回归精度仍然没有得到有效改善。针对这些问题,本文对复杂视网膜显微手术中的器械检测做出了多项研究,主要工作内容如下:1)构建并手动标注了RET1数据集,该数据集基于反复筛选的手术视频,涵盖了关键的视网膜手术场景及典型手术器械,为验证后续算法提供了坚实基础。2)基于YOLOv8框架设计了一种手术器械检测算法RM (retinal microsurgery)-YOLO。提出SGConv (shuffle GhostConv)和重参数化的RSGCSP (Rep SGConv CSP),改进了原有的卷积层和特征提取层,通过重参数化有效地在推理过程中减少参数量,同时保持较高的检测精度。3)将动态注意力机制的概念无缝集成到双分支的检测头中,增强模型对不同尺度、位置器械特征的捕获与表达能力,显著提高了检测的召回率。4)设计并引入DeltaIoU损失函数作为边界框回归损失函数,替代了传统的CIoU损失,加速模型收敛。
2. 原 理
2.1 数据集
鉴于目前尚无针对视网膜显微手术器械检测的公开数据集,且现有的相关数据集主要针对腹腔镜手术等领域,特别是腹腔镜胆囊切除术,这些都难以满足视网膜手术场景的需求。本研究基于实际手术视频,自行构建并精细标注了一个全新的数据集RET1,用以支持算法的开发和验证。本文使用的数据集源于由爱尔康(中国)提供的四段手术视频。视频涵盖了四种眼底手术类型:玻璃体切除术、黄斑裂孔修复术、视网膜前膜剥离术以及视网膜脱离修复术,涵盖关键且具有挑战性的手术场景。数据集中的手术器械主要分为三类:玻璃体切割器、内界膜剥离镊和光导管,如图1所示。
 图 1. RET1数据集中的三种主要手术器械。(a)玻璃体切割器;(b)内界膜剥离镊;(c)光导管Figure 1. Three main surgical instruments in RET1 dataset. (a) Vitrectomy cutter; (b) Internal limiting membrane peeling forceps; (c) Light pipe
图 1. RET1数据集中的三种主要手术器械。(a)玻璃体切割器;(b)内界膜剥离镊;(c)光导管Figure 1. Three main surgical instruments in RET1 dataset. (a) Vitrectomy cutter; (b) Internal limiting membrane peeling forceps; (c) Light pipe为提升算法的泛化性,本研究针对数据集进行了多种数据增强方法。为充分模拟视网膜手术中的极端情况,对数据集中的图片进行数据增强,其中包括显微镜失焦、过度曝光、高照明亮度、不同光源照明以及色调饱和度失调5种情况的模拟,以进一步减少过拟合的影响和提升算法的鲁棒性。在训练阶段还使用MixUp和马赛克数据增强等通用数据增强方式,以最大化提升数据集的多样性。
数据集最终经过精细挑选为3255张高质量图片,并手动划分为1953张训练集图片、651张验证集图片和651张测试集图片。其中测试集图片包含多种视网膜显微手术中的复杂环境,如模糊、低光、失真、反光、伪影、阴影和遮挡等,以验证算法的有效性。数据划分完成后使用Labelme软件进行手动标注。
2.2 模型网络架构
为了有效应对视网膜手术中器械检测带来的挑战,在网络模型的设计中进行针对性的调整是必要的。这些调整旨在增强语义特征和边界特征的提取能力,从而在分类和定位任务中显著提升模型的整体性能。本文基于YOLOv8框架提出用于视网膜显微手术器械检测的RM-YOLO算法网络,网络架构如图2所示。该算法将以 RSGCSP特征提取模块为基础的RSGCSPDarknet作为网络的骨干部分,用于深度提取输入图像特征;以SGConv卷积层为基础的SGNeck作为网络的特征融合部分,并保留了路径聚合网络的策略。头部使用解耦头和动态头的集成,将分类任务和回归任务分开处理并使用自注意力机制完成各个维度的感知,以下将详细介绍网络中每个部分的改进。
2.2.1 检测头改进
在视网膜手术中,不同尺度的手术器械目标常同时出现在图像中,而现有目标检测的检测头往往缺乏对尺度差异的有效感知;其次,器械的形状、位置和方向因视角不同而变化多样,现有方法在空间特性学习上表现有限;目标检测任务本身具有多样化,如边界框回归和目标分类,而现有的检测头难以灵活适配不同任务需求。为解决这些问题,基于拥有自注意力机制的动态头部[18],本部分将原检测头改进为更高效、精准的检测头。如式(1)~(2)所示,在特征融合部分生成多尺度的图像特征金字塔后,将输入的特征图映射为一个三维张量F,并建立了一个完整的注意力机制W(F),该注意力机制被分解为尺度感知、空间感知和任务感知三种维度的注意力。如图3所示,通过级联这些自注意力机制,不断的增强表达,最终形成一个统一的动态头部结构,其中L表示尺度维度,S表示空间维度,C表示通道维度,πL、πS、πC分别表示这三个维度上的注意力。
 图 3. 检测头中三种注意力机制的级联Figure 3. Cascading of three attention mechanisms in the detection head
图 3. 检测头中三种注意力机制的级联Figure 3. Cascading of three attention mechanisms in the detection headF∈RL×S×C, (1) W(F)=πC(πS(πL(F)⋅F)⋅F)⋅F. (2) 此外,本部分将分类任务和定位回归任务分开处理,各自构建分支,以便于模型对不同的任务需求进行更有效的特征提取。这种设计可减少不同任务间的干扰,使分类和定位更加准确。提出的检测头结合了动态头和解耦头的结构,以充分利用两种设计的优势,该结构通过在每一层提取并聚合多层次的特征,有效增强了模型对不同场景和目标尺度的适应能力,从而能在不同手术背景和多尺度器械检测任务中表现出更高的检测精度,图4展示了提出的头部集成框架,其中k为卷积核大小,s为步长,p为填充,ncls为类别数量。
2.2.2 卷积层改进
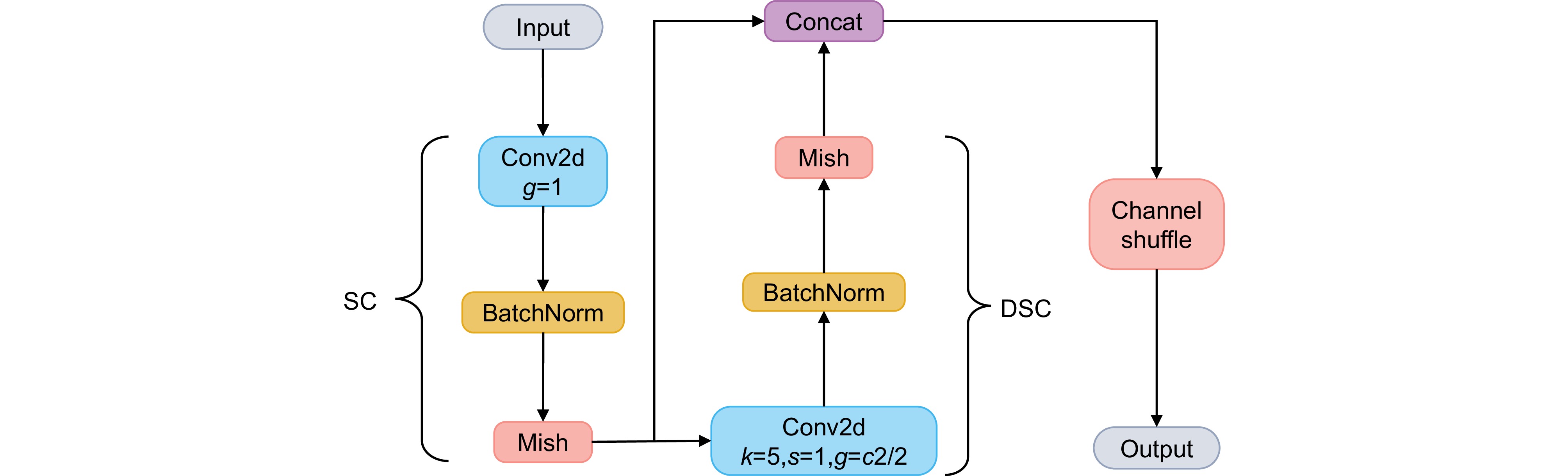
在目标检测任务中,卷积神经网络的表现高度依赖于卷积模块的特征提取能力。然而,类似普通卷积的传统卷积模块在逐步提取高层语义特征的过程中容易丢失空间信息,而GhostConv[19]等轻量化卷积虽然在一定程度上提高了计算效率,但在捕捉复杂场景下的全局信息和空间细节方面仍存在不足。在手术器械检测中,手术器械的形状、边缘特征(空间特征)以及通道间交互关系(通道特征)也非常重要,器械反光对检测性能的影响较大。为应对上述挑战,本文基于slim-neck结构[20]将卷积模块SGConv替换原有的普通卷积。该卷积在借鉴华为提出的GhostConv的基础上,针对其不足进行了优化与改进,具体结构如图5所示,其中g为卷积的分组数。该卷积层以标准卷积SC (standard convolution)为开端,接着经过一层深度可分离卷积DSC (depthwise separable convolution)。深度可分离卷积分为两步:逐通道卷积和逐点卷积,逐通道卷积指每个输入通道单独与一个卷积核进行卷积操作,不涉及通道间的信息交换,逐点卷积则用于跨通道的线性组合。与普通卷积相比,深度可分离卷积的计算量显著减少,特别是在输入和输出通道数较多时,优势更加明显。之后将两种卷积的输出进行结合,再通过通道混洗重新排列后输入特征图的通道,增强不同通道之间的信息融合效率。这样既能维持普通卷积对于通道维度的把握,也能减少空间信息的丢失。由于深度可分离卷积的存在,显著降低了SGConv的计算复杂度,提高了运行效率,通过通道之间的信息交互和深度捕捉器械的细节特征,在不同边缘特征器械的检测中表现出一定的优势。
2.2.3 特征提取模块改进
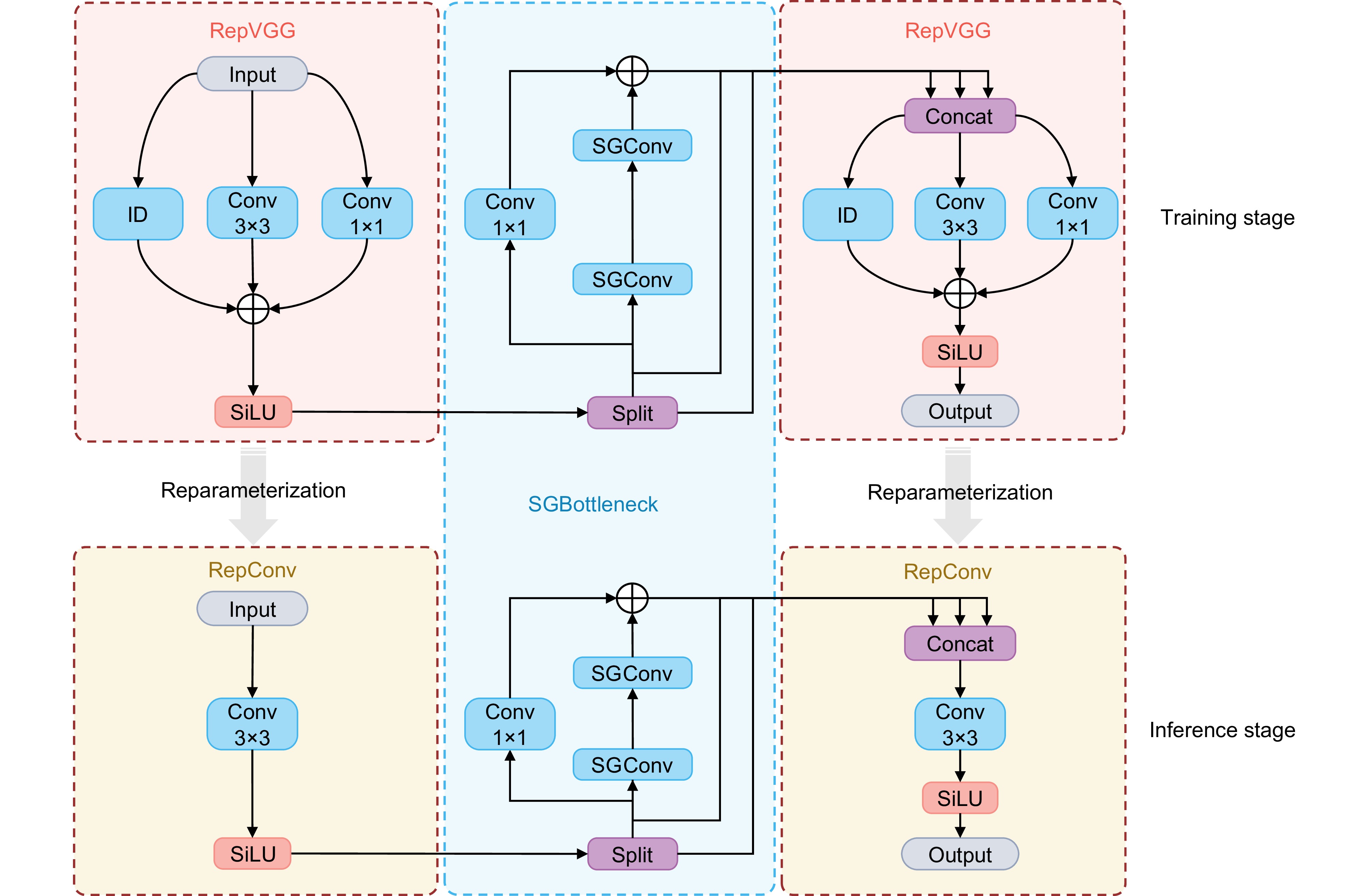
在进行视网膜显微手术中的器械检测时,模型需要在干扰场景下保持高精度的特征提取能力,同时还要满足实时推理的需求。而在YOLO系列算法中,C2f模块作为高效的特征提取模块,融合了ELAN(efficient layer aggregation network)的设计思想,为了进一步的轻量化,增加了更多跳层连接和额外的Split操作,但是仍存在大量计算冗余,导致参数利用效率低下,使得模型能力受限,仍有大量提升准确性的空间。针对上述问题,为增强模型在干扰环境下对手术器械的特征提取能力,本部分提出基于重参数化的RSGCSP特征提取模块,在网络轻量化和捕获全局信息能力上实现了双重保证,模块结构如图6所示。它的核心思想基于RepVGG[21],使用结构重参数化(structural re-parameterization)技术,在训练时构建具有多分支的复杂网络结构,多分支结构可以更好地捕捉特征,以优化表达能力和性能,而在推理时将多分支结构等价转换为简单的VGG样式(即纯3×3卷积核堆叠)的网络,提高推理速度和效率,简化了网络结构,减少了计算开销,具体的转化过程如图7所示。模块中设计的SGbottleneck由两个级联的SGConv和一个残差的1×1卷积组成,残差连接是为了使网络能够在保留初始特征信息的同时,增强更深层次的特征学习,同时可以有效缓解梯度消失和梯度爆炸。RepVGG的输出被分为三个部分,输入到SGbottleneck中合并后传入另一个RepVGG。该特征提取模块利用了上文提出的SGConv卷积层,显著增强模型的全局语义特征捕捉能力,并在推理时降低计算成本,在视网膜手术的干扰场景下实现高效且精准的检测。
2.3 损失函数
在目标检测任务中,边界框损失函数的设计直接影响边界框回归的精度与优化效率。原本的CIoU损失函数本质上是结合中心点和长宽比等信息来优化目标框,而在手术器械的检测中,对检测框中心点和长宽比的精确度量意义不大,而检测框边缘位置的度量信息才能准确反映预测框的回归精度。在数据标注过程中,往往是通过框的左上角和右下角坐标来控制手术器械标注的准确性。CIoU损失还对标注误差以及边界框的轻微变化较为敏感,在类似视网膜手术这种标注不完美的场景下,CIoU损失无法有效缓解标注误差带来的影响。
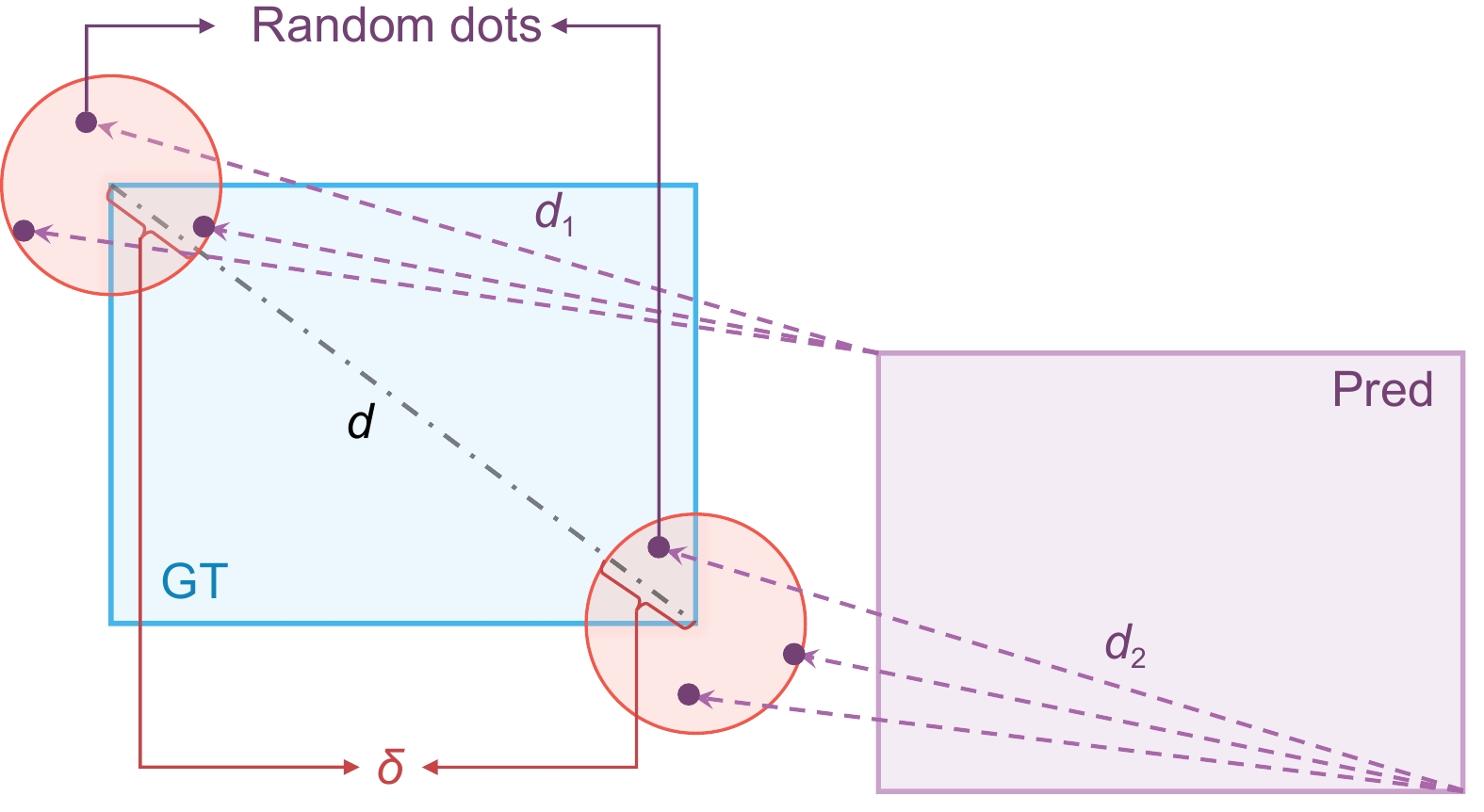
为此,本文基于MPDIoU的概念[22]提出边界框损失函数DeltaIoU Loss,利用目标框的顶点进行几何关系度量,改进了边界框优化策略。如图8所示,蓝色框表示真实框;紫色框表示预测框;d是目标框外接圆的半径,即对角线长度;红色区域表示以目标框左上角和右下角为中心;δ是圆的半径;d1是从目标框左上角为圆心的圆内随机点到预测框左上角坐标的距离;d2是从目标框右下角为圆心的圆内随机点到预测框右下角坐标的距离。在计算时,如果d1或d2的值小于δ,则d1或d2的值设为0,这样设计是为了让模型更加关注中等难度的样本,更容易从中提取有效特征,避免过度关注简单或困难样本,在一定的范围内对IoU的值敏感。DeltaIoU的计算还考虑了输入图像的宽度和高度,且δ与d成比例,比例因子为α。DeltaIoU的计算公式、其与比例因子的关系及DeltaIoU损失函数的计算分别见式(3)~(5),其中w表示输入图像的宽度。
DeltaIoU=IoU−d21w2+h2−d22w2+h2, (3) δ=dα, (4) LDeltaIoU=1−DeltaIoU. (5) DeltaIoU利用随机生成的顶点距离替代传统IoU的中心点度量,不仅降低了对标注误差的敏感性,还提升了中等难度样本的优化效果。此外,DeltaIoU考虑了目标框与图像尺寸的比例关系,使其在多尺度器械的检测任务中表现优异。在模糊和背景干扰的复杂场景下,DeltaIoU的设计使模型能够更快收敛,并有效提升最终的检测精度。
3. 实验结果
3.1 评估指标
为了评估算法在视网膜显微手术中器械检测的性能,采用的评估指标包括精确率(precision, P)、召回率(recall, R),在50%~95% IoU范围内的平均精度(mAP50-95)。主要的评价标准如式(6)~(9)所示:
P=TPTP+FP, (6) R=TPTP+FN, (7) AP=∑n(Rn−Rn−1)Pn, (8) mAP50-95=1N∑Ni=1(110∑9j=0APi,0.5+0.05j), (9) 式中:TP为真正例的数量;FP为假正例的数量;FN为假负例的数量;Pn和Rn分别为第n个阈值下的精度和召回率;N为总类别数。为了展示提出算法的高效性,判断模型在实际应用中是否满足实时检测的需求,还考虑了参数量(parameters)、浮点计算数(GFLOPs)以及每秒处理的图片数量(FPS)三种指标。
3.2 详细实验配置
实验的具体设置如下表1所示,训练完成后保存最佳权重进行后续验证。
表 1. 实验环境配置Table 1. Experimental environment configurationConfiguration Configuration parameters Operating system Windows 11 GPU Nvidia Geforce RTX 4070 Super Programming language Python 3.11 Framework Pytorch 2.1 GPU computing framework Cuda 12.1 GPU acceleration library Cudnn 8.0 Learning rate 0.001 Momentum 0.9 Weight rate decay 0.0005 Batch size 32 Epochs 300 | Show Table DownLoad:
CSV
DownLoad:
CSV
3.3 损失函数实验
在损失函数计算的过程中,参数α的取值不同会产生不同的结果。本部分基于提出算法进行大量实验,将α的取值从1到60依次进行遍历,实验结果如图9(a)所示。针对RET1数据集,当DeltaIoU损失函数的α取值为26时,其mAP达到峰值。由于不同数据集的内容不尽相同,其标注精度也有所偏差,因此实现最高精度的α值也会有所差异。
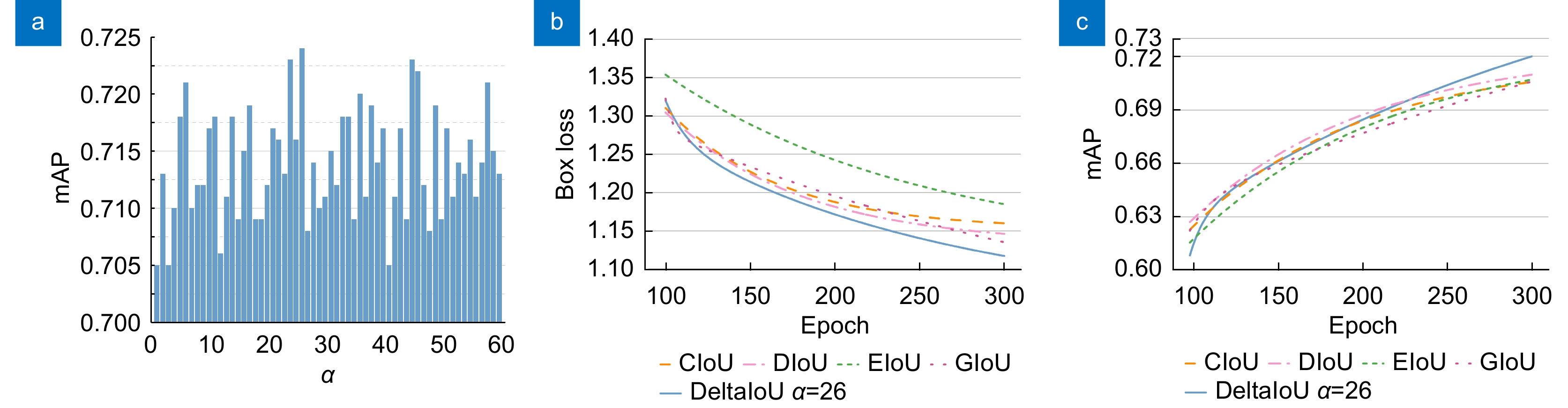 图 9. 损失函数实验结果。(a)不同α对应的mAP;(b)不同IoU对应的边界框回归损失;(c)不同IoU对应的mAPFigure 9. Results of the loss function experiments. (a) mAP at different values of α; (b) Bounding box regression loss corresponding to different IoUs; (c) mAP corresponding to different IoUs
图 9. 损失函数实验结果。(a)不同α对应的mAP;(b)不同IoU对应的边界框回归损失;(c)不同IoU对应的mAPFigure 9. Results of the loss function experiments. (a) mAP at different values of α; (b) Bounding box regression loss corresponding to different IoUs; (c) mAP corresponding to different IoUs为了验证提出的DeltaIoU边界框损失函数的有效性,在此基础上依次将边界框回归损失替换为四种常用的IoU损失函数(CIoU loss、DIoU loss、EIoU loss和GIoU loss)并进行充分的对比实验。首先比较了在不同边界框损失函数下的Box loss下降趋势。如图9(b)所示,与其他IoU损失函数相比,DeltaIoU展现了更快的收敛速度、更低的下降趋势以及更准确的回归结果。此外,还比较了不同边界框回归损失函数下的平均精度,结果如图9(c)所示。结果表明,前期DeltaIoU展现的平均精度相比其他损失函数略低,但能够让模型在训练后期达到更高的mAP值。这些实验进一步证明了本文提出的边界框损失函数能优化模型训练收敛速度和平均精度。DeltaIoU在本研究数据集上展现了良好的适配性和效果,有效解决了其他边界框损失函数在某些情况下无法区分目标的问题和数据集标注误差偏大的问题。
3.4 消融实验
为验证提出的各项改进对模型性能的具体影响,本研究在RET1数据集上开展了广泛的消融实验。主要的改进点分为三类:Dynamic head、RSGCSP和DeltaIoU,其中将提出的SGConv卷积层与RSGCSP模块相绑定,因此未单独列出,基线网络模型A为YOLOv8n,实验过程中保持其他参数不变。在实验中,当不使用DeltaIoU损失函数时,默认的IoU损失为CIoU损失,所有包含DeltaIoU的实验中,参数α的值都设为26。详细的实验结果见表2。
表 2. 消融实验结果Table 2. Ablation experiments resultsModel Dynamic head RSGCSP(SGConv) DeltaIoU loss P R mAP50-95 FPS A 0.960 0.925 0.686 206 B √ 0.966 0.923 0.706 128 C √ 0.977 0.929 0.691 210 D √ 0.970 0.928 0.680 216 E √ √ 0.960 0.931 0.702 136 F √ √ 0.980 0.926 0.707 198 G √ √ 0.985 0.930 0.711 115 H √ √ √ 0.975 0.941 0.724 143 | Show TableDownLoad:
CSV
结果表明,单独动态检测头的加入使平均精度相对原来提高2%,说明动态头与解耦头的集成显著增强了模型的检测表征能力,但损失了部分检测速度。RSGCSP特征提取模块增强了模型对不同手术器械的区分能力,主要表现在精确率上(有较大提升)。当动态头和RSGCSP结合使用时,精确率达到98.5%,相对基线提高2.5%。实验模型D、E、F表明DeltaIoU损失函数降低了边界框回归误差,当单独使用DeltaIoU损失函数时,对mAP的提升效果不显著;而将其与其他两个模块结合后,改进效果更为明显,在召回率上相对基线提升较多。这是由于在训练过程中发生了梯度爆炸,训练不稳定,而动态头和RSGCSP的加入缓解了这一问题。最终,提出的三项改进点使mAP较原始基线提高了3.8%,同时达到最高召回率94.1%,避免了大量的漏检。
3.5 对比实验
为突出所提算法的独特性和优势,与现有主流的目标检测算法进行了对比实验,包括两阶段检测算法Faster R-CNN、单阶段YOLO系列算法以及基于Transformer架构的 RT-DETR[23]等。实验均基于 RET1 数据集开展,所有算法的基础实验配置与表1保持一致。此外,还评估了参数量、GFLOPs和FPS等关键性能指标,以全面衡量模型的整体性能和效率,具体实验结果如表3所示。
表 3. 对比实验结果Table 3. Comparison experiments resultsModel P R mAP50-95 Parameters/M GFLOPs FPS Faster R-CNN 0.961 0.919 0.652 / / 85 YOLOv3s[24] 0.981 0.931 0.687 15.32 43.8 147 YOLOv5s 0.965 0.927 0.683 9.11 23.8 194 YOLOv6s[25] 0.960 0.914 0.681 16.3 44.0 192 RT-DETR 0.964 0.895 0.623 10.56 23.9 131 YOLOv9m[26] 0.952 0.927 0.685 20.02 76.5 89 YOLOv10s[27] 0.947 0.876 0.684 8.04 24.5 182 DBH-YOLO 0.975 0.918 0.643 20.86 47.9 128 RM-YOLO(ours) 0.975 0.941 0.724 7.4 20.7 143 | Show TableDownLoad:
CSV
在视网膜手术的复杂场景中,尤其是病灶和器械遮挡问题,阻碍了模型对目标的有效检测,实验结果也表明,所有算法的召回率均显著低于精确率,说明器械的漏检问题较为严重,而误检相对较少。因此,提高召回率并减少漏检成为本研究的主要关注点。所提方法在精确率和召回率之间实现了最佳平衡,召回率达到了所有算法中的最高值(94.1%),有效缓解了模型漏检。在各类流行的目标检测算法中,所提算法在召回率和平均精度方面均优于其他算法,在保证高精度的同时,模型依旧保持了较低的参数量和浮点计算数,分别为7.4和20.7,得益于RSGCSP特征提取模块的重参数化应用,将推理时的计算开销降到最低。在检测实时性方面,提出算法每秒处理的图片数量在所有模型中位居前列,接近于主流的轻量化模型,能够满足实际的临床应用。
3.6 器械单独检测实验
针对RET1数据集中的三类主要手术器械,采用提出的方法进行了单独检测实验,实验结果如图10所示。玻璃体切割器和光导管在某些条件下具有高度视觉相似性,在训练阶段模型难以充分学习到两种不同特征,导致模型容易将一种器械误分类为另一种,从而降低了精确率,错检率变高,在图10中表现为这两种器械的精确率、召回率和平均精度均低于内界膜剥离镊。在视网膜显微手术中,光导管作为照明设备,不直接参与手术操作,通常位于显微图像的边缘。由于前置镜头的存在,边缘的清晰度较低且畸变程度较大,成像质量远低于中央区域,从而影响了光导管的成像。如图10所示,这种图像退化导致模型对光导管的召回率有所降低,并且数据集中光导管的实例数量相对较少,限制了模型对该器械类别独特特征的充分学习,影响了检测的准确性。
4. 分析讨论
当下主流的目标检测方法与所提方法的主要区别在于网络架构的集成和损失函数的计算方式。在深度学习的实际应用中,能否有效检测困难样本是评估模型性能的关键。本文提出的基于深度学习的器械检测方法的核心优势在于,在复杂干扰因素的存在下依然能够协助外科医生轻松识别和定位手术器械。
图11展示了单个手术器械在干扰因素下的检测结果。其中,图11(a)对比了其他主流算法与本文算法在处理器械严重反光情况下对内界膜剥离镊的检测表现。结果表明,内界膜剥离镊的强烈反光使YOLOv5s错误地检测出额外的器械,而YOLOv10s的边界框定位不准确,且置信度仅为0.28。图11(b)展示了显微镜眼底成像发生严重畸变时,不同算法对玻璃体切割器的检测结果。基线模型在此场景下出现漏检,而RT-DETR则额外检测出一种器械,凸显了干扰因素对算法性能的影响。
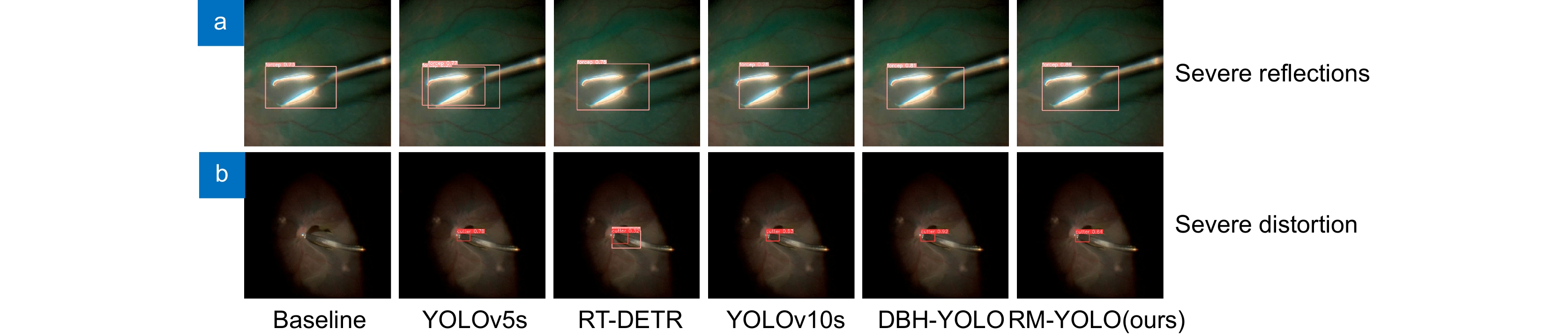 图 11. 复杂情况下不同算法对单个手术器械的检测结果。(a)器械严重反光;(b)显微镜成像严重畸变Figure 11. Detection results of different algorithms for a single surgical instrument in complex scenarios. (a) Severe instrument reflection; (b) Severe distortion in microscope imaging
图 11. 复杂情况下不同算法对单个手术器械的检测结果。(a)器械严重反光;(b)显微镜成像严重畸变Figure 11. Detection results of different algorithms for a single surgical instrument in complex scenarios. (a) Severe instrument reflection; (b) Severe distortion in microscope imaging图12进一步列举了在其他三种复杂干扰场景下,多种器械同时存在时不同算法的检测对比结果。在图12(a)中,由于光导管与玻璃体切割器之间的高度相似性及环境光亮度不足,基线模型出现误检,YOLOv5s对玻璃体切割器产生漏检,甚至在某些情况下人眼也难以有效区分两者。在图12(b)中,手术显微镜对焦不当导致靠近显微镜的内界膜剥离镊成像模糊。在此场景下,虽然基线模型和RT-DETR能够检测出内界膜剥离镊,但其置信度较低,仅为0.38和0.57,YOLOv10s则出现了漏检现象。在图12(c)中,在两种器械相互遮挡的场景下,玻璃体切割器几乎完全被内界膜剥离镊掩盖。此种干扰导致YOLOv5s未能检测到两种器械,而其余三种算法在此场景下只能检测到上方的内界膜剥离镊,未能对下方的玻璃体切割器有效检测,表现出较高的漏检率。
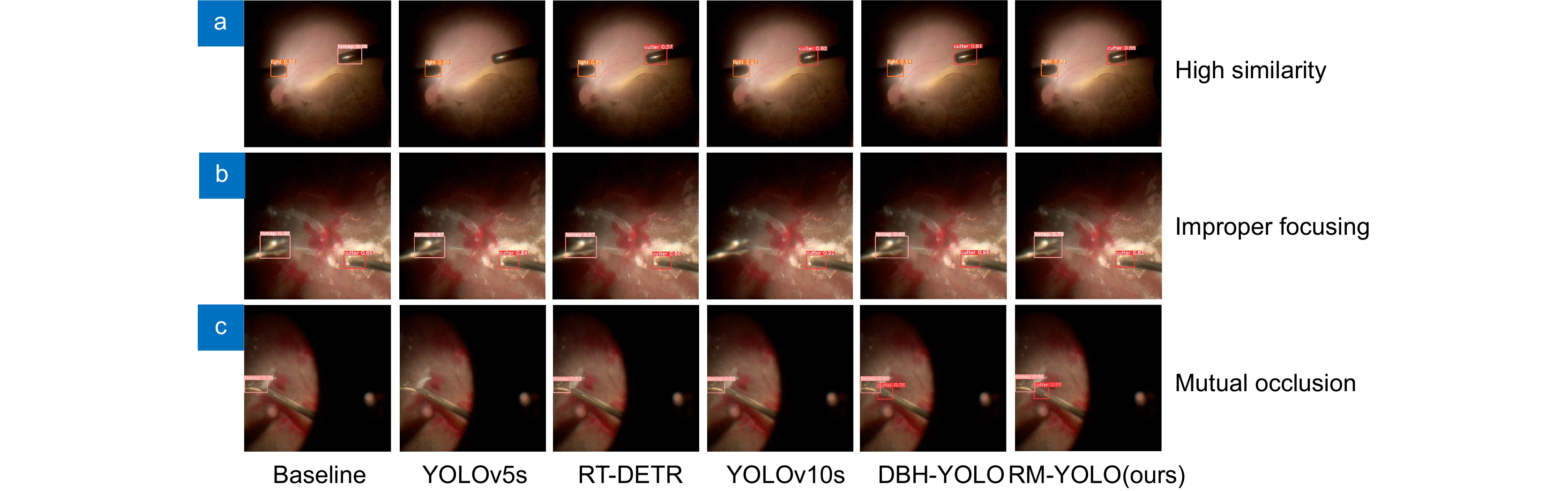 图 12. 复杂情况下不同算法对多个手术器械的检测结果。(a)器械相似度过高;(b)显微镜失焦;(c)器械之间相互遮挡Figure 12. Detection results of different algorithms for multiple surgical instruments in complex scenarios. (a) High instrument similarity; (b) Microscope out of focus; (c) Occlusion between instruments
图 12. 复杂情况下不同算法对多个手术器械的检测结果。(a)器械相似度过高;(b)显微镜失焦;(c)器械之间相互遮挡Figure 12. Detection results of different algorithms for multiple surgical instruments in complex scenarios. (a) High instrument similarity; (b) Microscope out of focus; (c) Occlusion between instruments相比之下,所提算法在5种场景中均展现出高效且精准的检测性能。在每一种复杂干扰场景下,此算法能够准确识别器械的名称和位置,无漏检或误检情况发生,且所有检测的置信度均超过0.6,充分体现了模型对各类器械特征的全面学习能力。此外,边界框回归的精度显著高于其他算法,完全满足精确手术跟踪的需求,所提算法在面对人眼难以区分器械的场景时,依然能够准确且有效地识别和区分。以上结果表明,该算法在广泛的临床实践和医疗应用中具有一定的潜力,尤其在具有挑战性的视网膜显微手术场景下,能够比其他目标检测算法更可靠、更精准地检测手术器械。
所提的算法在玻璃体切除手术中进一步验证了其可靠性。在此类手术中通常采用蓝光、绿光和黄光等不同颜色的光源对眼底进行照明。光照条件的变化不仅增加了手术环境的复杂性,也对检测算法的适应性提出了更高要求。如图13所示,所提算法通过丰富的数据增强策略和创新的特征提取方法,能够在不同光照条件下精准检测手术器械的名称和位置。得益于RSGCSP模块的设计,通过充分挖掘和利用不同特征图之间的信息,增强了模型的特征提取和融合能力,使得网络能够全局捕捉特征,从而显著提升了模型的鲁棒性。
5. 结 论
本文提出了一种基于深度学习的在视网膜显微手术中的器械检测方法,通过构建、筛选、增强和标注RET1数据集解决视网膜显微手术数据集不足的问题。针对复杂环境下视网膜手术的困难样本检测,一般算法频繁出现漏检和误检,本文引入动态头与解耦头的有效集成,提出SGConv卷积层和RSGCSP重参数化模块替换原有模块,提高模型的检测精度的同时维持较低的参数量。针对边界框回归不准确和收敛速度慢等问题,提出用于边界框回归的DeltaIoU损失函数。大量消融实验和对比实验表明,所提方法在RET1数据集上达到了72.4%的mAP50-95,尤其是在召回率上达到了94.1%的较高值,在性能上优于现有算法,有效解决了一般算法中常见的漏检问题。本研究适用于视网膜手术操作中出现的多样性与不可预测性,不仅能够准确检测视网膜显微手术中的手术器械尖端,还为后续手术显微镜的自动跟踪和智能眼科手术导航机器人提供了有力支持。
在后续的工作中,研究将致力于应对某些突发情况,如视网膜撕裂或术中出血等,这些突发情况都有可能影响检测结果。另外,基于此算法将开发更为智能的手术导航功能,结合手术机器人实现更为精准的手术表现。
-
图 1 RET1数据集中的三种主要手术器械。(a)玻璃体切割器;(b)内界膜剥离镊;(c)光导管
Figure 1. Three main surgical instruments in RET1 dataset. (a) Vitrectomy cutter; (b) Internal limiting membrane peeling forceps; (c) Light pipe
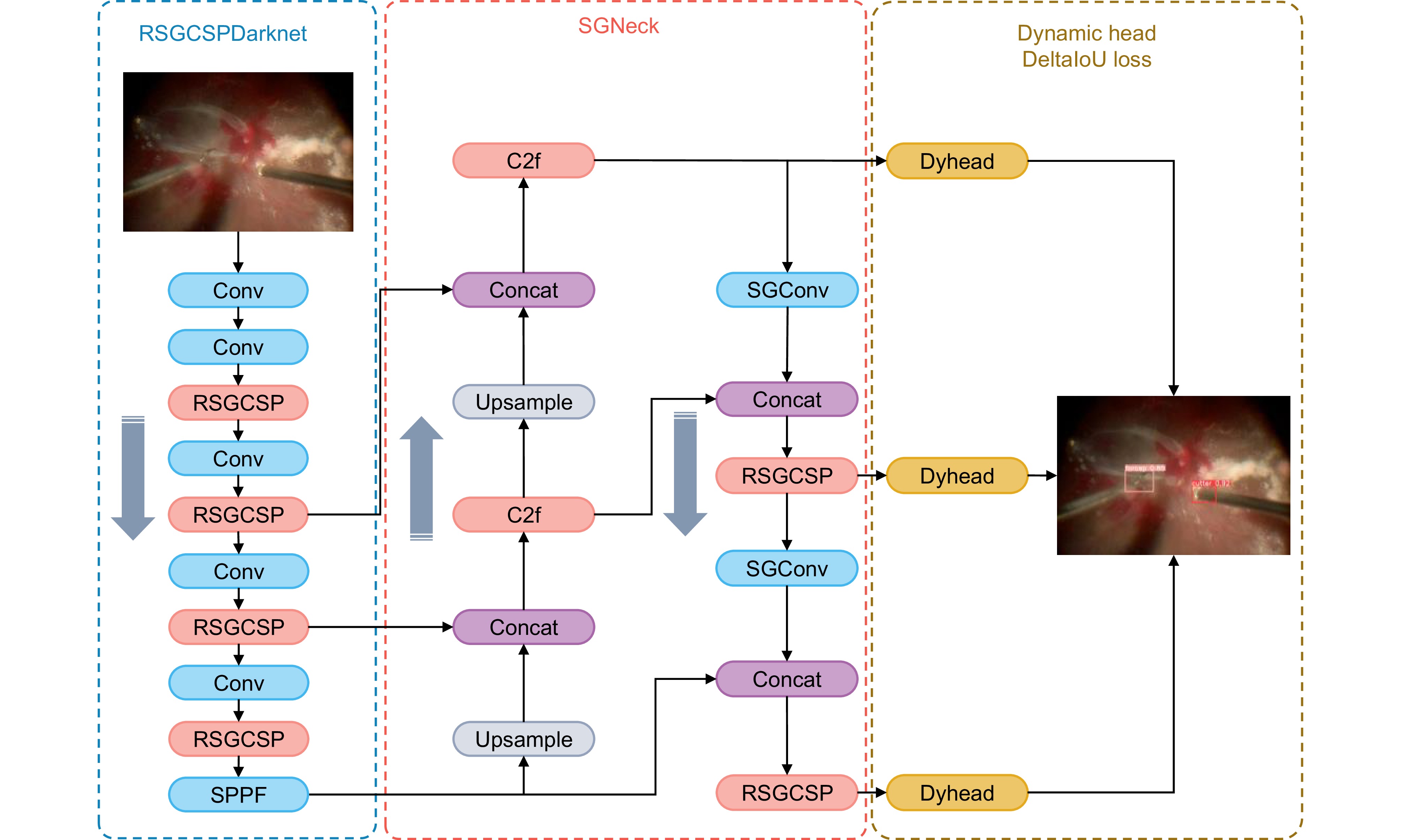
图 2 提出的RM-YOLO网络模型整体架构
Figure 2. Overall network architecture of the proposed RM-YOLO model
图 3 检测头中三种注意力机制的级联
Figure 3. Cascading of three attention mechanisms in the detection head
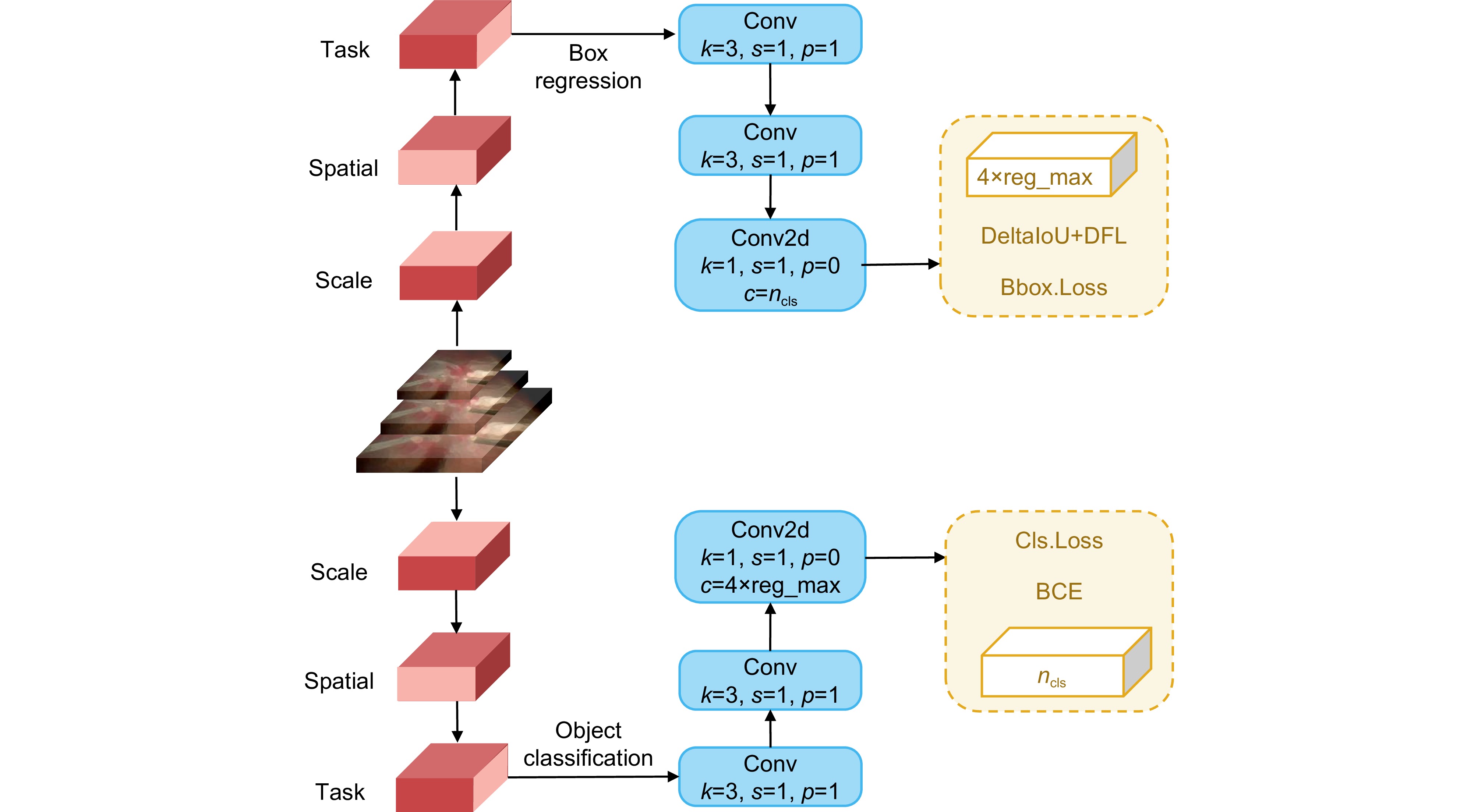
图 4 提出的动态头部与解耦头部集成结构图
Figure 4. Integrated structure of the proposed dynamic head and decoupled head
图 9 损失函数实验结果。(a)不同α对应的mAP;(b)不同IoU对应的边界框回归损失;(c)不同IoU对应的mAP
Figure 9. Results of the loss function experiments. (a) mAP at different values of α; (b) Bounding box regression loss corresponding to different IoUs; (c) mAP corresponding to different IoUs
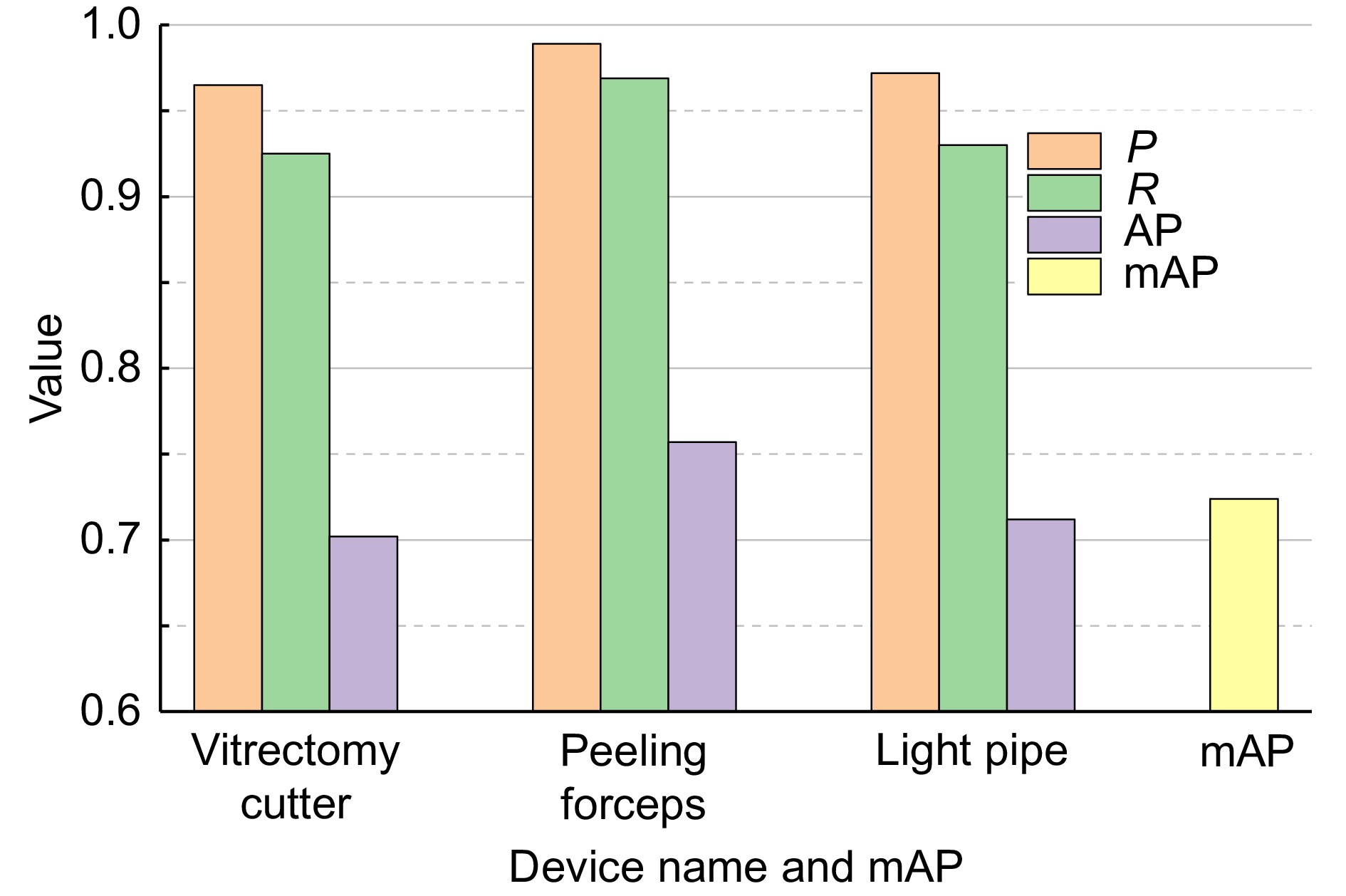
图 10 实验结果中三种主要手术器械的指标
Figure 10. The results of three main types of surgical instruments in the experiment
图 11 复杂情况下不同算法对单个手术器械的检测结果。(a)器械严重反光;(b)显微镜成像严重畸变
Figure 11. Detection results of different algorithms for a single surgical instrument in complex scenarios. (a) Severe instrument reflection; (b) Severe distortion in microscope imaging
图 12 复杂情况下不同算法对多个手术器械的检测结果。(a)器械相似度过高;(b)显微镜失焦;(c)器械之间相互遮挡
Figure 12. Detection results of different algorithms for multiple surgical instruments in complex scenarios. (a) High instrument similarity; (b) Microscope out of focus; (c) Occlusion between instruments
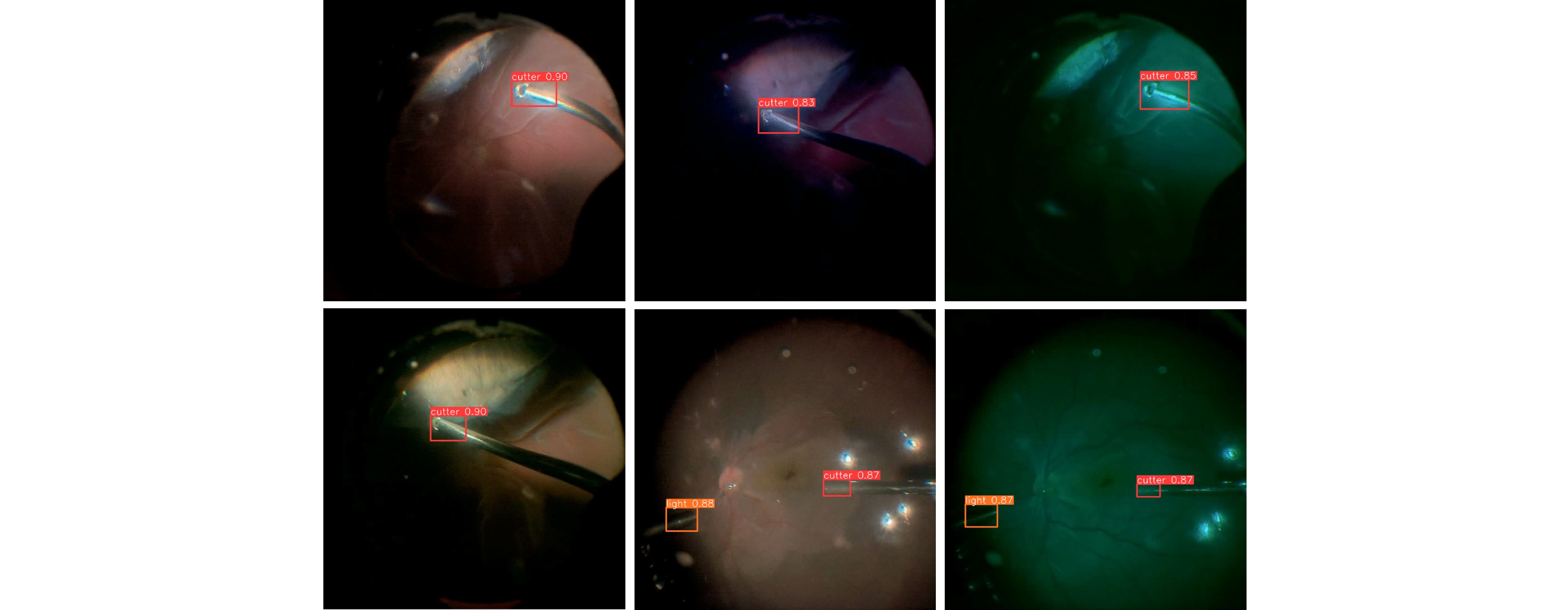
图 13 提出算法在玻璃体切除术中不同光照条件下对手术器械的检测
Figure 13. Detection of surgical instruments during vitrectomy under different lighting conditions by the proposed algorithm
表 1 实验环境配置
Table 1. Experimental environment configuration
Configuration Configuration parameters Operating system Windows 11 GPU Nvidia Geforce RTX 4070 Super Programming language Python 3.11 Framework Pytorch 2.1 GPU computing framework Cuda 12.1 GPU acceleration library Cudnn 8.0 Learning rate 0.001 Momentum 0.9 Weight rate decay 0.0005 Batch size 32 Epochs 300
下载: 导出CSV
表 2 消融实验结果
Table 2. Ablation experiments results
Model Dynamic head RSGCSP(SGConv) DeltaIoU loss P R mAP50-95 FPS A 0.960 0.925 0.686 206 B √ 0.966 0.923 0.706 128 C √ 0.977 0.929 0.691 210 D √ 0.970 0.928 0.680 216 E √ √ 0.960 0.931 0.702 136 F √ √ 0.980 0.926 0.707 198 G √ √ 0.985 0.930 0.711 115 H √ √ √ 0.975 0.941 0.724 143
下载: 导出CSV
表 3 对比实验结果
Table 3. Comparison experiments results
Model P R mAP50-95 Parameters/M GFLOPs FPS Faster R-CNN 0.961 0.919 0.652 / / 85 YOLOv3s[24] 0.981 0.931 0.687 15.32 43.8 147 YOLOv5s 0.965 0.927 0.683 9.11 23.8 194 YOLOv6s[25] 0.960 0.914 0.681 16.3 44.0 192 RT-DETR 0.964 0.895 0.623 10.56 23.9 131 YOLOv9m[26] 0.952 0.927 0.685 20.02 76.5 89 YOLOv10s[27] 0.947 0.876 0.684 8.04 24.5 182 DBH-YOLO 0.975 0.918 0.643 20.86 47.9 128 RM-YOLO(ours) 0.975 0.941 0.724 7.4 20.7 143
下载: 导出CSV
-
参考文献
[1] Ma L, Fei B W. Comprehensive review of surgical microscopes: technology development and medical applications[J]. J Biomed Opt, 2021, 26(1): 010901. doi: 10.1117/1.JBO.26.1.010901
[2] Ehlers J P, Dupps W J, Kaiser P K, et al. The prospective intraoperative and perioperative ophthalmic ImagiNg with optical CoherEncE TomogRaphy (PIONEER) study: 2-year results[J]. Am J Ophthalmol, 2014, 158(5): 999−1007. e1 doi: 10.1016/j.ajo.2014.07.034
[3] Ravasio C S, Pissas T, Bloch E, et al. Learned optical flow for intra-operative tracking of the retinal fundus[J]. Int J Comput Assist Radiol Surg, 2020, 15(5): 827−836. doi: 10.1007/s11548-020-02160-9
[4] 李云耀, 樊金宇, 蒋天亮, 等. 光学相干层析技术在眼科手术导航方面的研究进展[J]. 光电工程, 2023, 50(1): 220027. doi: 10.12086/oee.2023.220027
Li Y Y, Fan J Y, Jiang T L, et al. Review of the development of optical coherence tomography imaging navigation technology in ophthalmic surgery[J]. Opto-Electron Eng, 2023, 50(1): 220027. doi: 10.12086/oee.2023.220027
[5] 杨建文, 黄江杰, 何益, 等. 线聚焦谱域光学相干层析成像的分段色散补偿像质优化方法[J]. 光电工程, 2024, 51(6): 240042. doi: 10.12086/oee.2024.240042
Yang J W, Huang J J, He Y, et al. Image quality optimization of line-focused spectral domain optical coherence tomography with subsection dispersion compensation[J]. Opto-Electron Eng, 2024, 51(6): 240042. doi: 10.12086/oee.2024.240042
[6] Bouget D, Allan M, Stoyanov D, et al. Vision-based and marker-less surgical tool detection and tracking: a review of the literature[J]. Med Image Anal, 2017, 35: 633−654. doi: 10.1016/j.media.2016.09.003
[7] Allan M, Ourselin S, Thompson S, et al. Toward detection and localization of instruments in minimally invasive surgery[J]. IEEE Trans Biomed Eng, 2013, 60(4): 1050−1058. doi: 10.1109/TBME.2012.2229278
[8] Alsheakhali M, Yigitsoy M, Eslami A, et al. Real time medical instrument detection and tracking in microsurgery[C]//Proceedings of the Algorithmen-Systeme-Anwendungen on Bildverarbeitung für die Medizin, Lübeck, 2015: 185–190. https://doi.org/10.1007/978-3-662-46224-9_33.
[9] Sznitman R, Richa R, Taylor R H, et al. Unified detection and tracking of instruments during retinal microsurgery[J]. IEEE Trans Pattern Anal Mach Intell, 2013, 35(5): 1263−1273. doi: 10.1109/TPAMI.2012.209
[10] Sun Y W, Pan B, Fu Y L. Lightweight deep neural network for articulated joint detection of surgical instrument in minimally invasive surgical robot[J]. J Digit Imaging, 2022, 35(4): 923−937. doi: 10.1007/s10278-022-00616-9
[11] Girshick R. Fast R-CNN[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, 2015: 1440–1448. https://doi.org/10.1109/ICCV.2015.169.
[12] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031
[13] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, 2016. https://doi.org/10.1109/CVPR.2016.91.
[14] Sarikaya D, Corso J J, Guru K A. Detection and localization of robotic tools in robot-assisted surgery videos using deep neural networks for region proposal and detection[J]. IEEE Trans Med Imaging, 2017, 36(7): 1542−1549. doi: 10.1109/TMI.2017.2665671
[15] Zhang B B, Wang S S, Dong L Y, et al. Surgical tools detection based on modulated anchoring network in laparoscopic videos[J]. IEEE Access, 2020, 8: 23748−23758. doi: 10.1109/ACCESS.2020.2969885
[16] Pan X Y, Bi M R, Wang H, et al. DBH-YOLO: a surgical instrument detection method based on feature separation in laparoscopic surgery[J]. Int J Comput Assist Radiol Surg, 2024, 19(11): 2215−2225. doi: 10.1007/s11548-024-03115-0
[17] Zhao Z J, Chen Z R, Voros S, et al. Real-time tracking of surgical instruments based on spatio-temporal context and deep learning[J]. Comput Assist Surg, 2019, 24(S1): 20−29. doi: 10.1080/24699322.2018.1560097
[18] Dai X Y, Chen Y P, Xiao B, et al. Dynamic head: unifying object detection heads with attentions[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, 2021: 7373–7382. https://doi.org/10.1109/CVPR46437.2021.00729.
[19] Han K, Wang Y H, Tian Q, et al. GhostNet: more features from cheap operations[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 1580–1589. https://doi.org/10.1109/CVPR42600.2020.00165.
[20] Li H L, Li J, Wei H B, et al. Slim-neck by GSConv: a lightweight-design for real-time detector architectures[J]. J Real Time Image Process, 2024, 21(3): 62. doi: 10.1007/s11554-024-01436-6
[21] Ding X H, Zhang X Y, Ma N N, et al. RepVGG: making VGG-style ConvNets great again[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, 2021: 13733–13742. https://doi.org/10.1109/CVPR46437.2021.01352.
[22] Ma S L, Xu Y. MPDIoU: a loss for efficient and accurate bounding box regression[Z]. arXiv: 2307.07662, 2023. https://doi.org/10.48550/arXiv.2307.07662.
[23] Zhao Y, Lv W Y, Xu S L, et al. DETRs beat YOLOs on real-time object detection[C]//Proceedings of 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2024: 16965–16974. https://doi.org/10.1109/CVPR52733.2024.01605.
[24] Redmon J, Farhadi A. YOLOv3: an incremental improvement[Z]. arXiv: 1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767.
[25] Li C Y, Li L L, Jiang H L, et al. YOLOv6: a single-stage object detection framework for industrial applications[Z]. arXiv: 2209.02976, 2022. https://doi.org/10.48550/arXiv.2209.02976.
[26] Wang C Y, Yeh I H, Liao H Y M. YOLOv9: learning what you want to learn using programmable gradient information[C]//Proceedings of the 18th European Conference on Computer Vision, Milan, 2025. https://doi.org/10.1007/978-3-031-72751-1_1.
[27] Wang A, Chen H, Liu L H, et al. YOLOv10: real-time end-to-end object detection[Z]. arXiv: 2405.14458, 2024. https://doi.org/10.48550/arXiv.2405.14458.
-
访问统计



 点击扫一扫
点击扫一扫
图(14)
表(3)
计量
- 文章访问数:
- PDF下载数:



