
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
针对无人机航拍图像前景目标尺度差异大、样本空间分布不均衡、背景冗余占比高所导致的漏检和误检问题,本文提出一种自适应前景聚焦无人机航拍图像目标检测算法。首先,构建全景特征细化分类层,通过重参数空间像素方差法及混洗操作,增强算法聚焦能力,提高前景样本特征的表示质量。其次,采用分离-学习-融合策略设计自适应双维特征采样单元,加强对前景焦点特征提取能力和背景细节信息保留能力,改善误检情况,加快推理速度。然后,结合多分支结构和广播自注意力机制构造多路径信息整合模块,解决下采样引起的歧义映射问题,优化特征的交互与整合,提高算法对多尺度目标的识别、定位能力,降低模型计算量。最终,引入自适应前景聚焦检测头,运用动态聚焦机制,增强前景目标检测精度,抑制背景干扰。在公开数据集VisDrone2019和VisDrone2021上进行相关实验,实验结果表明,该方法mAP@0.5数值达到了45.1%和43.1%,较基线模型分别提升6.6%和5.7%,且优于其他对比算法,表明该算法显著提升了检测精度,具备良好的普适性与实时性。
Abstract:To address the issues of missed and false detections caused by significant scale differences of foreground targets, uneven sample spatial distribution, and high background redundancy in UAV aerial images, an adaptive foreground-focused UAV aerial image target detection algorithm is proposed. A panoramic feature refinement classification layer is constructed to enhance the algorithm's focusing capability and improve the representation quality of foreground sample features through the re-parameterization spatial pixel variance method and shuffling operation. An adaptive dual-dimensional feature sampling unit is designed using a separate-learn-merge strategy to strengthen the algorithm's ability to extract foreground focus features and retain background detail information, thereby improving false detection situations and accelerating inference speed. A multi-path information integration module is constructed by combining a multi-branch structure and a broadcast self-attention mechanism to solve the ambiguity mapping problem caused by downsampling, optimize feature interaction and integration, enhance the algorithm's ability to recognize and locate multi-scale targets, and reduce model computational load. An adaptive foreground-focused detection head is introduced, which employs a dynamic focusing mechanism to enhance foreground target detection accuracy and suppress background interference. Experiments on the public datasets VisDrone2019 and VisDrone2021 show that the proposed method achieves mAP@0.5 values of 45.1% and 43.1%, respectively, improving by 6.6% and 5.7% compared to the baseline model, and outperforming other comparison algorithms. These results demonstrate that the proposed algorithm significantly improves detection accuracy and possesses good generalizability and real-time performance.
-
Overview: To address the issues of missed and false detections due to significant scale variations of foreground targets, uneven sample distribution, and high background redundancy in UAV aerial images, we propose an adaptive foreground-focused object detection algorithm based on the YOLOv8s model. This algorithm incorporates several novel components designed to enhance detection accuracy and efficiency. First, a panoramic feature refinement classification (PFRC) layer is introduced. This layer enhances the algorithm's focus capability and improves the representation quality of foreground samples through re-parameterized spatial pixel variance and shuffle operations. The PFRC layer effectively refines the spatial pixel distribution, highlighting important features while reducing noise. This ensures that the foreground representation is prominent and clear, thereby improving the algorithm's ability to detect objects accurately. Second, we incorporate an adaptive two-dimensional feature sampling (ATFS) unit. This unit employs a separate-learn-merge strategy, which strengthens the extraction of foreground features and retains essential background details. By dynamically adjusting the sampling grid to various scales and orientations, the ATFS unit enhances fine-grained detail extraction. This not only reduces false detections but also accelerates inference, making the algorithm more efficient. Third, a multi-path full-text information integration (MPFT) module is introduced. This module utilizes a multi-branch structure and a broadcast self-attention (BSA) mechanism to address the ambiguity mapping issues caused by downsampling. The MPFT module optimizes feature interaction and integration, enhancing the algorithm's ability to recognize and locate targets accurately. By processing different feature types simultaneously, the multi-branch structure and BSA mechanism reduce the computational load while maintaining high detection accuracy. Finally, we propose an adaptive foreground focus detection head (AFF_Detect). This detection head employs a dynamic focusing mechanism that adjusts based on input characteristics. The AFF_Detect head improves the detection accuracy of foreground targets and suppresses background interference. This dynamic adjustment ensures that the algorithm performs well across various scenarios, enhancing its robustness and generalization capabilities. Experimental results on the VisDrone2019 and VisDrone2021 datasets demonstrate the effectiveness of our proposed algorithm. The mAP@0.5 values achieved are 45.1% and 43.1%, respectively, representing improvements of 6.6% and 5.7% over the baseline model. These results indicate that our algorithm outperforms other state-of-the-art methods, showcasing significant enhancements in detection accuracy, robustness, generalization, and real-time performance. In conclusion, our adaptive foreground-focused object detection algorithm introduces innovative components that address the challenges of UAV aerial image analysis. The integration of the PFRC layer, ATFS unit, MPFT module, and AFF_Detect head results in a comprehensive solution that enhances the representation of foreground features, reduces false detections, and optimizes computational efficiency. These advancements make our algorithm a valuable contribution to UAV-based object detection, offering a significant improvement in performance and reliability.
-

-

图 2 全景特征分类层 (PFRC)结构
Figure 2. Panoramic feature classification layer (PFRC) structure
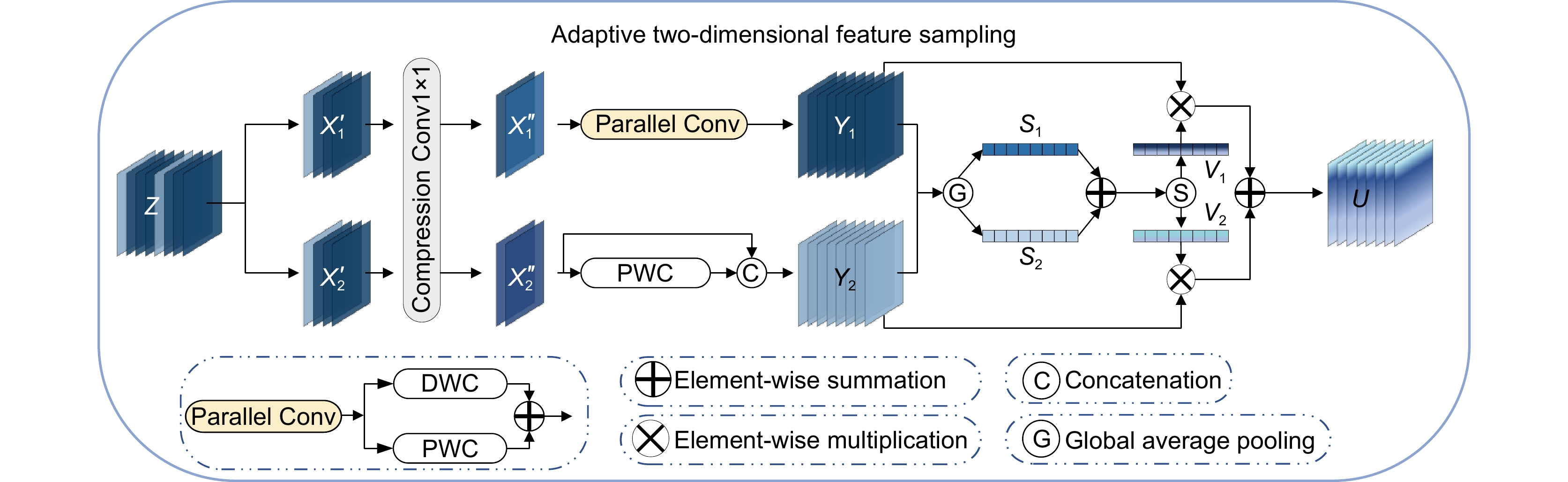
图 3 自适应双维特征采样 (ATFS)结构
Figure 3. Adaptive two-dimensional feature sampling (ATFS) structure
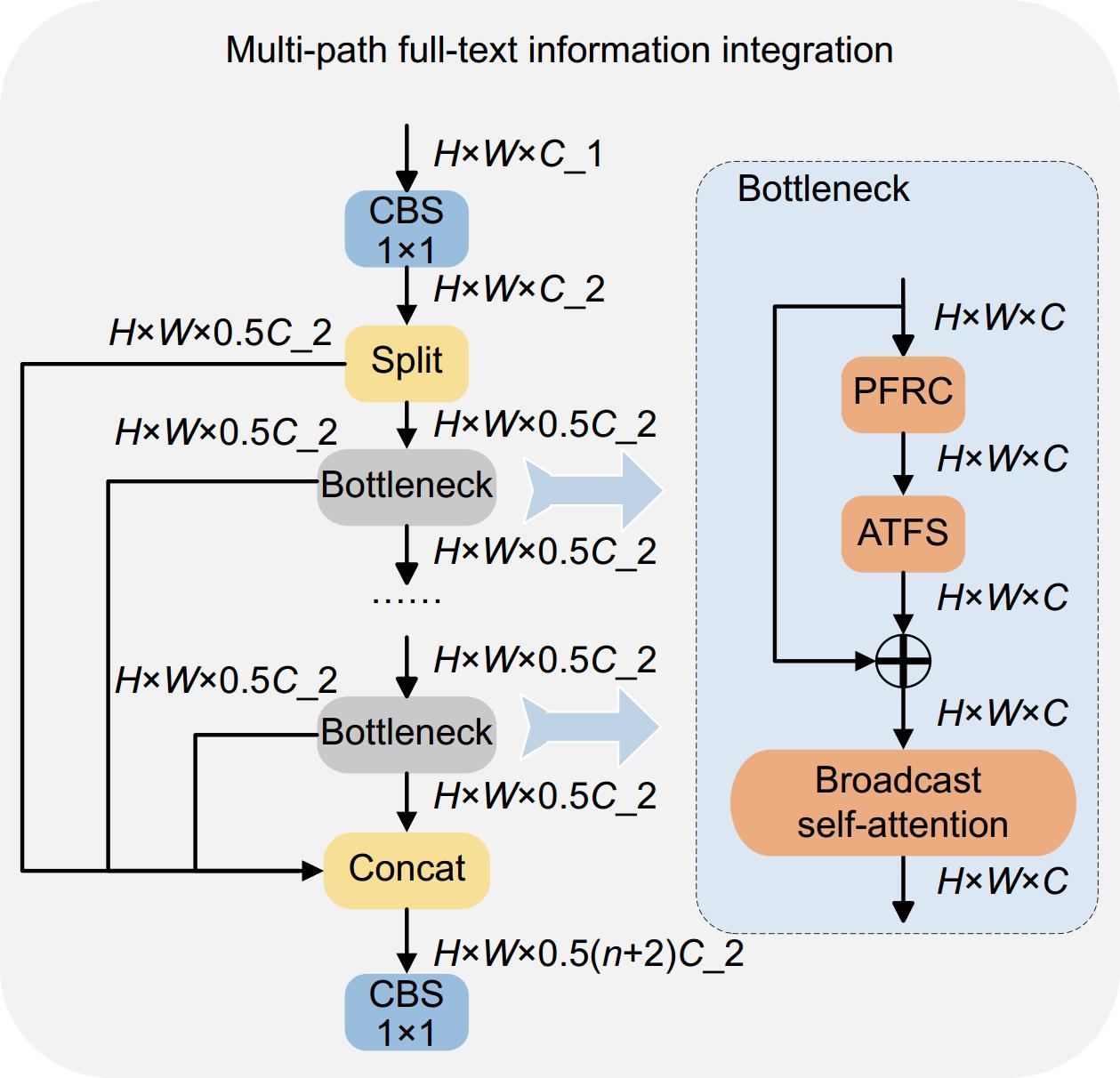
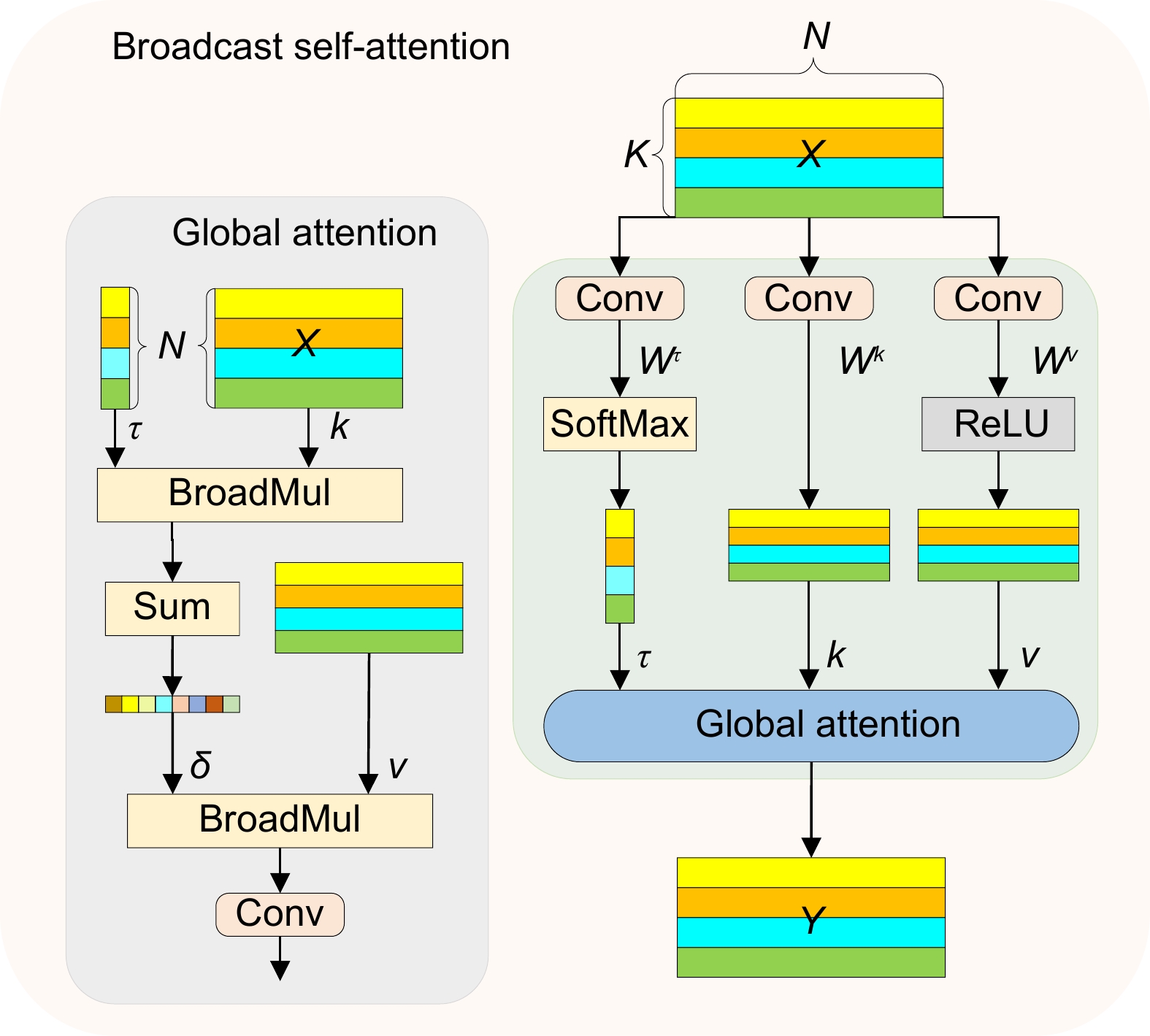
图 4 多路径全文信息整合 (MPFT)结构
Figure 4. Structure of multi-path full-text information integration (MPFT)
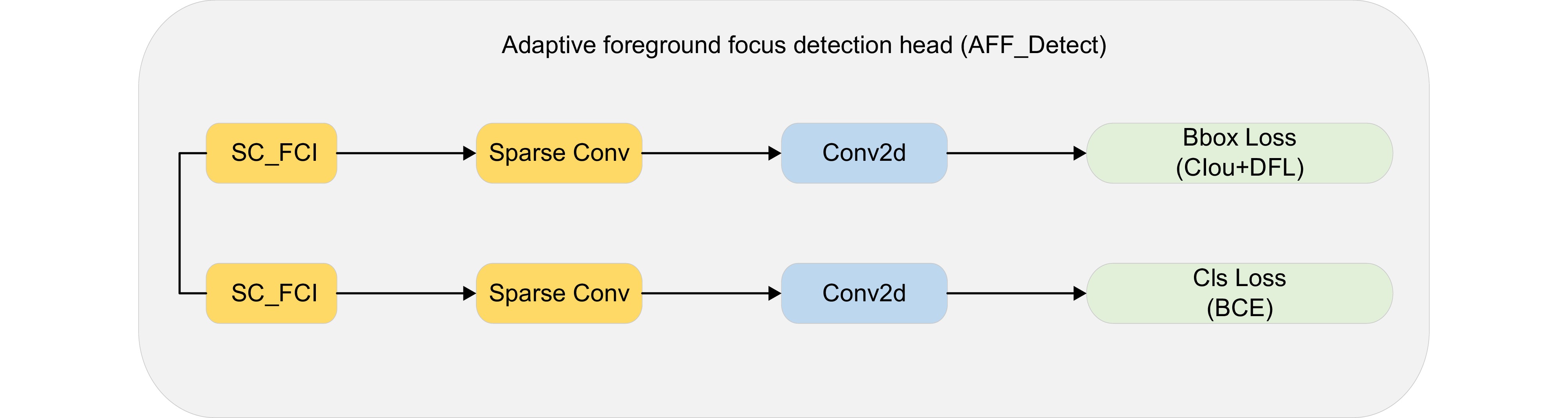
图 7 自适应前景聚焦检测头 (AFF_Detect)结构
Figure 7. Adaptive foreground focus detect head (AFF_Detect) structure
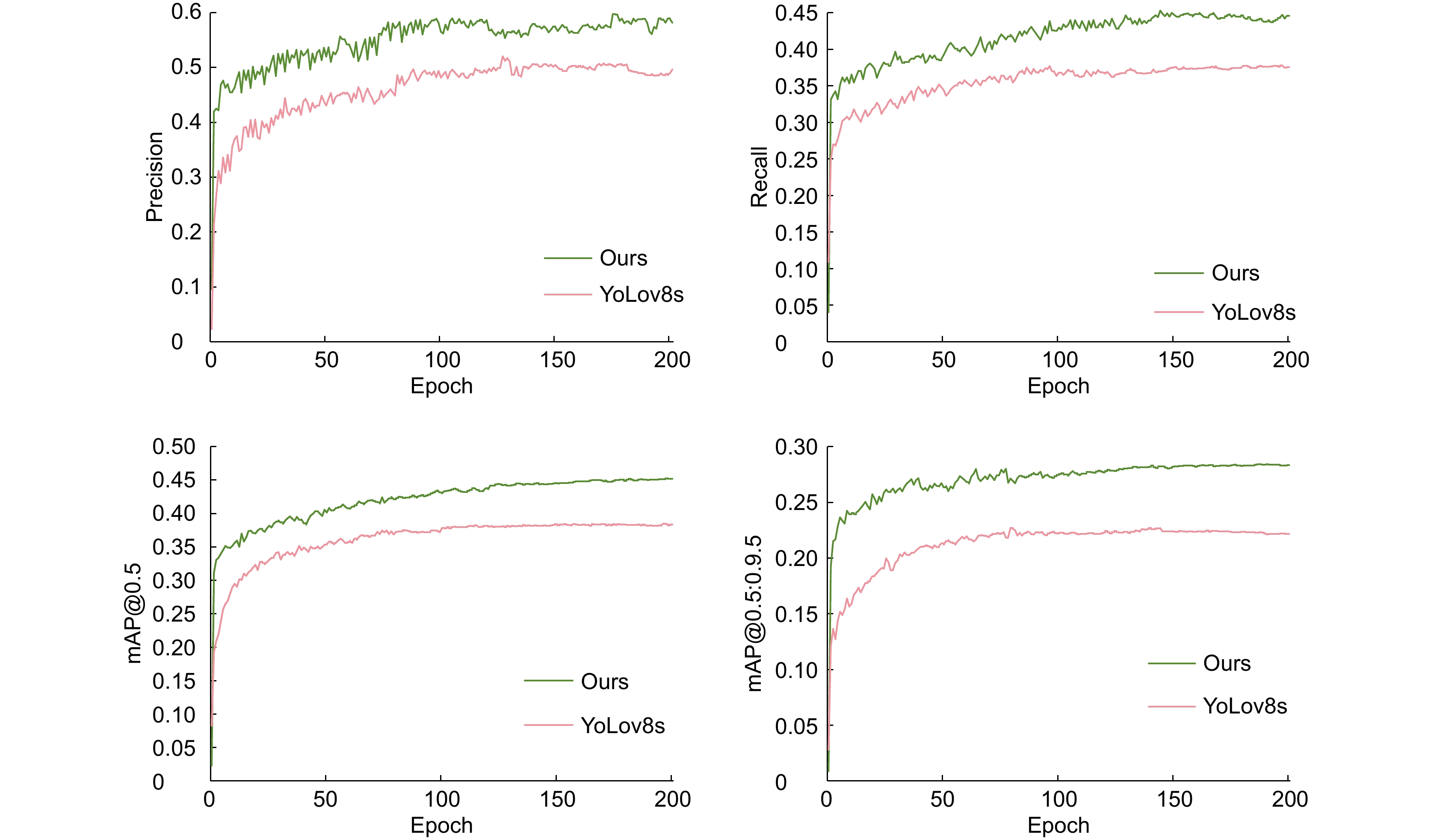
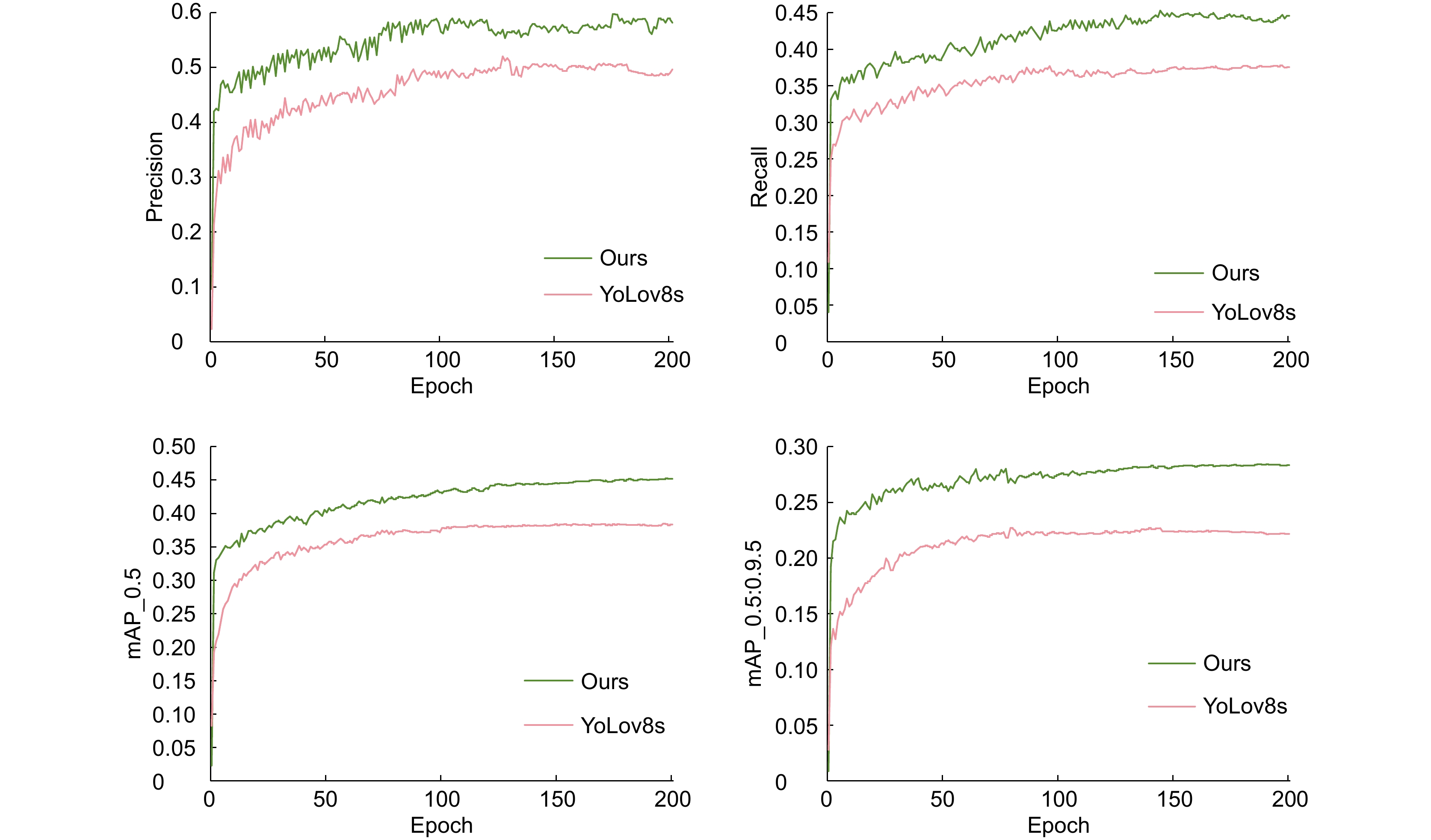
图 8 YOLOv8s与改进模型评价指标对比
Figure 8. Comparison of evaluation indicators between the YOLOv8s and improved mode

图 9 对比试验可视化结果。 (a) RetinaNet; (b) YOLOv5s; (c) Faster-RCNN; (d) TPH-YOLOv5; (e) YOLOv7-tiny; (f) YOLOv8s; (g) YOLOv10s; (h) Improved YOLOv5; (i) Deformmable-DETR; (j) Ours
Figure 9. Comparison test visualisation results. (a) RetinaNet; (b) YOLOv5s;(c) Faster-RCNN; (d) TPH-YOLOv5; (e) YOLOv7-tiny; (f) YOLOv8s;(g) YOLOv10s; (h) Improved YOLOv5; (i) Deformmable-DETR; (j) Ours
表 1 所提算法在VisDrone2019数据集的消融实验
Table 1. Ablation experiments of the proposed algorithm in the VisDrone2019 dataset
Number YOLOv8s PFRC ATFS MPFT AFFDH Precision/% Recall/% mAP@0.5/% GFLOPs 1 √ × × × × 49.7 37.5 38.5 28.8 2 √ √ × × × 52.7 41.7 40.9 34.3 3 √ × √ × × 53.4 42.8 41.8 27.1 4 √ × × √ × 54.5 41.5 42.7 25.5 5 √ × × × √ 52.4 41.4 39.8 26.8 6 √ √ √ × × 54.0 43.4 43.2 32.0 7 √ √ √ √ × 55.8 44.2 44.3 29.2 8 √ √ √ √ √ 58.1 44.6 45.1 28.9  下载: 导出CSV
下载: 导出CSV
表 2 消融实验各类别精度对比结果/%
Table 2. Comparison results of the accuracy of ablation experiments by category/%
Number Pedestrian People Bicycle Car Van Truck Tricycle Awning-tricycle Bus Motor mAP@0.5 1 37.2 27.6 14.7 77.4 42.9 39.0 23.8 21.5 56.1 39.4 38.5 2 38.2 22.3 18.9 81.0 44.1 41.2 18.7 25.5 58.1 35.6 40.9 3 39.0 31.0 18.4 80.9 44.9 42.9 24.6 19.9 60.3 39.7 41.8 4 41.8 33.2 17.6 83.8 45.4 40.6 25.8 26.1 61.5 45.6 42.7 5 33.3 22.1 16.3 73.4 39.4 41.0 21.1 22.9 57.4 40.9 39.8 6 44.8 34.7 18.9 84.7 46.6 50.7 26.8 25.4 58.3 49.1 43.2 7 52.8 42.0 20.1 83.3 46.7 43.8 28.0 26.7 60.8 52.7 44.3 8 53.9 41.3 24.1 87.8 50.5 45.3 31.6 28.9 62.6 55.2 45.1
下载: 导出CSV
表 3 VisDrone2019数据集对比实验结果
Table 3. Results of comparison experiments on VisDrone2019 dataset
Model Precision/% Recall/% mAP@0.5/% mAP@0.5:0.95/% GFLOPs FPS YOLOv5s 48.7 35.0 34.4 18.5 15.7 120 RetinaNet 35.5 21.9 20.3 12.5 92.9 26 TPH-YOLOv5 49.4 37.0 36.9 19.1 14.6 125 YOLOv7-tiny 50.1 41.2 37.6 22.6 12.9 113 Deformmable-DETR 52.4 45.0 44.2 25.7 179.3 69 YOLOv8s 49.7 37.5 38.5 22.1 28.8 129 YOLOv10s 55.4 40.7 41.1 23.8 21.6 133 Improved YOLOv5 57.7 43.0 43.9 24.9 34.3 99 Faster-RCNN 48.0 35.1 35.0 21.8 42.5 23 Ours 58.1 44.6 45.1 28.3 28.9 145
下载: 导出CSV
表 4 VisDrone2021数据集对比实验结果
Table 4. Results of comparison experiments on VisDrone2021 dataset
Model Precision/% Recall/% mAP@0.5/% mAP@0.5:0.95/% GFLOPs FPS YOLOv5s 46.6 33.1 31.9 16.1 15.7 115 RetinaNet 31.5 18.9 15.3 10.5 92.9 21 TPH-YOLOv5 45.4 34.0 33.6 16.3 14.6 119 YOLOv7-tiny 48.8 39.2 34.6 19.9 12.9 105 Deformmable-DETR 51.5 42.1 42.0 22.4 179.3 62 YOLOv8s 47.7 37.5 37.4 19.8 28.8 120 YOLOv10s 50.7 38.1 40.5 21.2 21.6 127 Improved YOLOv5s 52.2 40.7 42.1 22.6 34.3 88 Faster-RCNN 46.1 33.6 32.3 18.8 42.5 20 Ours 53.1 42.6 43.1 24.3 28.9 138
下载: 导出CSV
-
[1] 陈旭, 彭冬亮, 谷雨. 基于改进YOLOv5s的无人机图像实时目标检测[J]. 光电工程, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
Chen X, Peng D L, Gu Y. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electron Eng, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
[2] Xiong X R, He M T, Li T Y, et al. Adaptive feature fusion and improved attention mechanism-based small object detection for UAV target tracking[J]. IEEE Internet Things J, 2024, 11(12): 21239−21249. doi: 10.1109/JIOT.2024.3367415
[3] 马梁, 苟于涛, 雷涛, 等. 基于多尺度特征融合的遥感图像小目标检测[J]. 光电工程, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363
Ma L, Guo Y T, Lei T, et al. Small object detection based on multi-scale feature fusion using remote sensing images[J]. Opto-Electron Eng, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363
[4] Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), 2005: 886–893. https://doi.org/10.1109/CVPR.2005.177.
[5] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031
[6] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779–788. https://doi.org/10.1109/CVPR.2016.91.
[7] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6517–6525. https://doi.org/10.1109/CVPR.2017.690.
[8] Redmon J, Farhadi A. YOLOv3: an incremental improvement[Z]. arXiv: 1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767.
[9] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: optimal speed and accuracy of object detection[Z]. arXiv: 2004.10934, 2020. https://doi.org/10.48550/arXiv.2004.10934.
[10] Ge Z, Liu S T, Wang F, et al. YOLOX: exceeding YOLO series in 2021[Z]. arXiv: 2107.08430, 2021. https://doi.org/10.48550/arXiv.2107.08430.
[11] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//14th European Conference on Computer Vision, 2016: 21–37. https://doi.org/10.1007/978-3-319-46448-0_2.
[12] Zhang Z, Yi H H, Zheng J. Focusing on small objects detector in aerial images[J]. Acta Electron Sin, 2023, 51(4): 944−955. doi: 10.12263/DZXB.20220313
[13] Li S C, Yang X D, Lin X X, et al. Real-time vehicle detection from UAV aerial images based on improved YOLOv5[J]. Sensors, 2023, 23(12): 5634. doi: 10.3390/s23125634
[14] Li K, Wang Y N, Hu Z M. Improved YOLOv7 for small object detection algorithm based on attention and dynamic convolution[J]. Appl Sci, 2023, 13(16): 9316. doi: 10.3390/app13169316
[15] Wang G, Chen Y F, An P, et al. UAV-YOLOv8: a small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios[J]. Sensors, 2023, 23(16): 7190. doi: 10.3390/s23167190
[16] Zhu M L, Kong E. Multi-scale fusion uncrewed aerial vehicle detection based on RT-DETR[J]. Electronics, 2024, 13(8): 1489. doi: 10.3390/electronics13081489
[17] Shao Y F, Yang Z X, Li Z H, et al. Aero-YOLO: an efficient vehicle and pedestrian detection algorithm based on unmanned aerial imagery[J]. Electronics, 2024, 13(7): 1190. doi: 10.3390/electronics13071190
[18] Zhan W, Sun C F, Wang M C, et al. An improved Yolov5 real-time detection method for small objects captured by UAV[J]. Soft Comput, 2022, 26(1): 361−373. doi: 10.1007/s00500-021-06407-8
[19] 陈朋磊, 王江涛, 张志伟, 等. 基于特征聚合与多元协同特征交互的航拍图像小目标检测[J]. 电子测量与仪器学报, 2023, 37(10): 183−192. doi: 10.13382/j.jemi.B2306431
Chen P L, Wang J T, Zhang Z W, et al. Small object detection in aerial images based on feature aggregation and multiple cooperative features interaction[J]. J Electron Meas Instrum, 2023, 37(10): 183−192. doi: 10.13382/j.jemi.B2306431
[20] Sui J C, Chen D K, Zheng X, et al. A new algorithm for small target detection from the perspective of unmanned aerial vehicles[J]. IEEE Access, 2024, 12: 29690−29697. doi: 10.1109/ACCESS.2024.3365584
[21] Li X, Wang W H, Hu X L, et al. Selective kernel networks[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 510–519. https://doi.org/10.1109/CVPR.2019.00060.
[22] Zhao X B, Liu K Q, Gao K, et al. Hyperspectral time-series target detection based on spectral perception and spatial-temporal tensor decomposition[J]. IEEE Trans Geosci Remote Sens, 2023, 61: 5520812. doi: 10.1109/TGRS.2023.3307071
[23] Wu Y X, He K M. Group normalization[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 3–19. https://doi.org/10.1007/978-3-030-01261-8_1.
[24] Yin X Y, Goudriaan J A N, Lantinga E A, et al. A flexible sigmoid function of determinate growth[J]. Ann Bot, 2003, 91(3): 361−371. doi: 10.1093/aob/mcg029
[25] Tanaka M. Weighted sigmoid gate unit for an activation function of deep neural network[J]. Pattern Recognit Lett, 2020, 135: 354−359. doi: 10.1016/j.patrec.2020.05.017
[26] Guo Y H, Li Y D, Wang L Q, et al. Depthwise convolution is all you need for learning multiple visual domains[C]//Proceedings of the 33rd AAAI Conference on Artificial Intelligence, 2019: 8368–8375. https://doi.org/10.1609/aaai.v33i01.33018368.
[27] Howard A G, Zhu M L, Chen B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[Z]. arXiv: 1704.04861, 2017. https://doi.org/10.48550/arXiv.1704.04861.
[28] Zhang P F, Lo E, Lu B T. High performance depthwise and pointwise convolutions on mobile devices[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, 2020: 6795–6802. https://doi.org/10.1609/aaai.v34i04.6159.
[29] Lin M, Chen Q, Yan S C. Network in network[C]//2nd International Conference on Learning Representations, 2013.
[30] Yan S, Shao H D, Wang J, et al. LiConvFormer: a lightweight fault diagnosis framework using separable multiscale convolution and broadcast self-attention[J]. Expert Syst Appl, 2024, 237: 121338. doi: 10.1016/j.eswa.2023.121338
[31] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 6000–6010.
[32] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale[C]//9th International Conference on Learning Representations, 2021.
[33] Wu H, Wen C L, Shi S S, et al. Virtual sparse convolution for multimodal 3D object detection[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 21653–21662. https://doi.org/10.1109/CVPR52729.2023.02074.
[34] Feng M K, Yu H C, Dang X Y, et al. Category-aware dynamic label assignment with high-quality oriented proposal[Z]. arXiv: 2407.03205, 2024. https://doi.org/10.48550/arXiv.2407.03205.
[35] Verelst T, Tuytelaars T. Dynamic convolutions: exploiting spatial sparsity for faster inference[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 2317–2326. https://doi.org/10.1109/CVPR42600.2020.00239.
[36] Du D W, Zhu P F, Wen L Y, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshops, 2019: 213–226. https://doi.org/10.1109/ICCVW.2019.00030.
[37] Cao Y R, He Z J, Wang L J, et al. VisDrone-DET2021: the vision meets drone object detection challenge results[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 2847–2854. https://doi.org/10.1109/ICCVW54120.2021.00319.
[38] Wang Y Y, Wang C, Zhang H, et al. Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery[J]. Remote Sens, 2019, 11(5): 531. doi: 10.3390/rs11050531
[39] Zhu X K, Lyu S C, Wang X, et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 2778–2788. https://doi.org/10.1109/ICCVW54120.2021.00312.
[40] Liu C, Hong Z Y, Yu W H, et al. An efficient helmet wearing detection method based on YOLOv7-tiny[C]//Proceedings of the 6th International Conference on Machine Learning and Machine Intelligence, 2023: 92–99. https://doi.org/10.1145/3635638.3635652.
[41] Zhu X Z, Su W J, Lu L W, et al. Deformable DETR: deformable transformers for end-to-end object detection[C]//9th International Conference on Learning Representations, 2021.
[42] Wang A, Chen H, Liu L H, et al. YOLOv10: real-time end-to-end object detection[Z]. arXiv: 2405.14458, 2024. https://doi.org/10.48550/arXiv.2405.14458.
[43] Li S X, Liu C, Tang K W, et al. Improved YOLOv5s algorithm for small target detection in UAV aerial photography[J]. IEEE Access, 2024, 12: 9784−9791. doi: 10.1109/ACCESS.2024.3353308
-
 点击扫一扫
点击扫一扫

图(10)
表(4)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


