
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
大部分注意力机制虽然能增强图像特征,但没有考虑局部特征的关联性影响特征整体的问题。针对以上问题,本文提出局部注意力引导下的全局池化残差分类网络(MSLENet)。MSLENet的基线网络为ResNet34,首先改变首层结构,保留图像重要信息;其次提出多分割局部增强注意力机制(MSLE)模块,MSLE模块将图像整体分割成多个小图像,增强每个小图像的局部特征,通过特征组交互的方式将局部重要特征引导到全局特征中;最后提出池化残差(PR)模块来处理ResNet残差结构丢失信息的问题,提高各层之间的信息利用率。实验结果表明,MSLENet通过增强局部特征的关联性,在多个数据集上均有良好的效果,有效地提高了网络的表达能力。
Abstract:Most attention mechanisms, while enhancing image features, do not consider the impact of local feature interaction on overall feature representation. To address this issue, this paper proposes a global pooling residual classification network guided by local attention (MSLENet). The baseline network for MSLENet was ResNet34. First, the initial layer structure was modified to retain important image information. Second, a multiple segmentation local enhancement attention mechanism (MSLE) module was introduced. The MSLE module first segmented the image into multiple small images, then enhanced the local features of each small image, and finally integrated these important local features into the global features through feature group interaction. Lastly, a pooling residual (PR) module was proposed to address the information loss problem in the ResNet residual structure and improve the information utilization between layers. The experimental results show that by enhancing the interaction of local features, MSLENet achieves good performance on multiple datasets and effectively improves the expressive ability of the network.
-
Key words:
- image classification /
- attention mechanism /
- residual structure /
- local features /
- global features /
- interaction
-
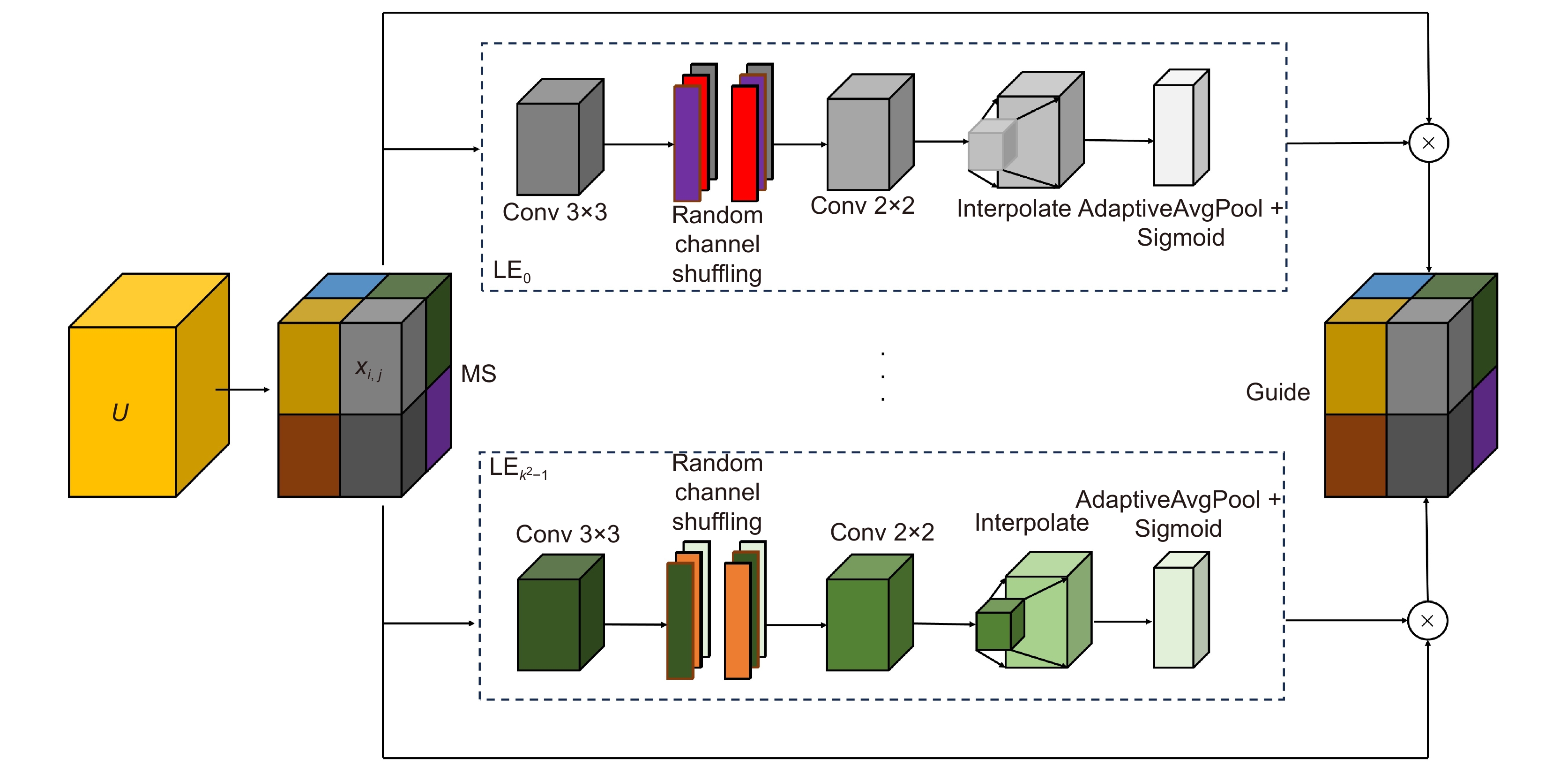
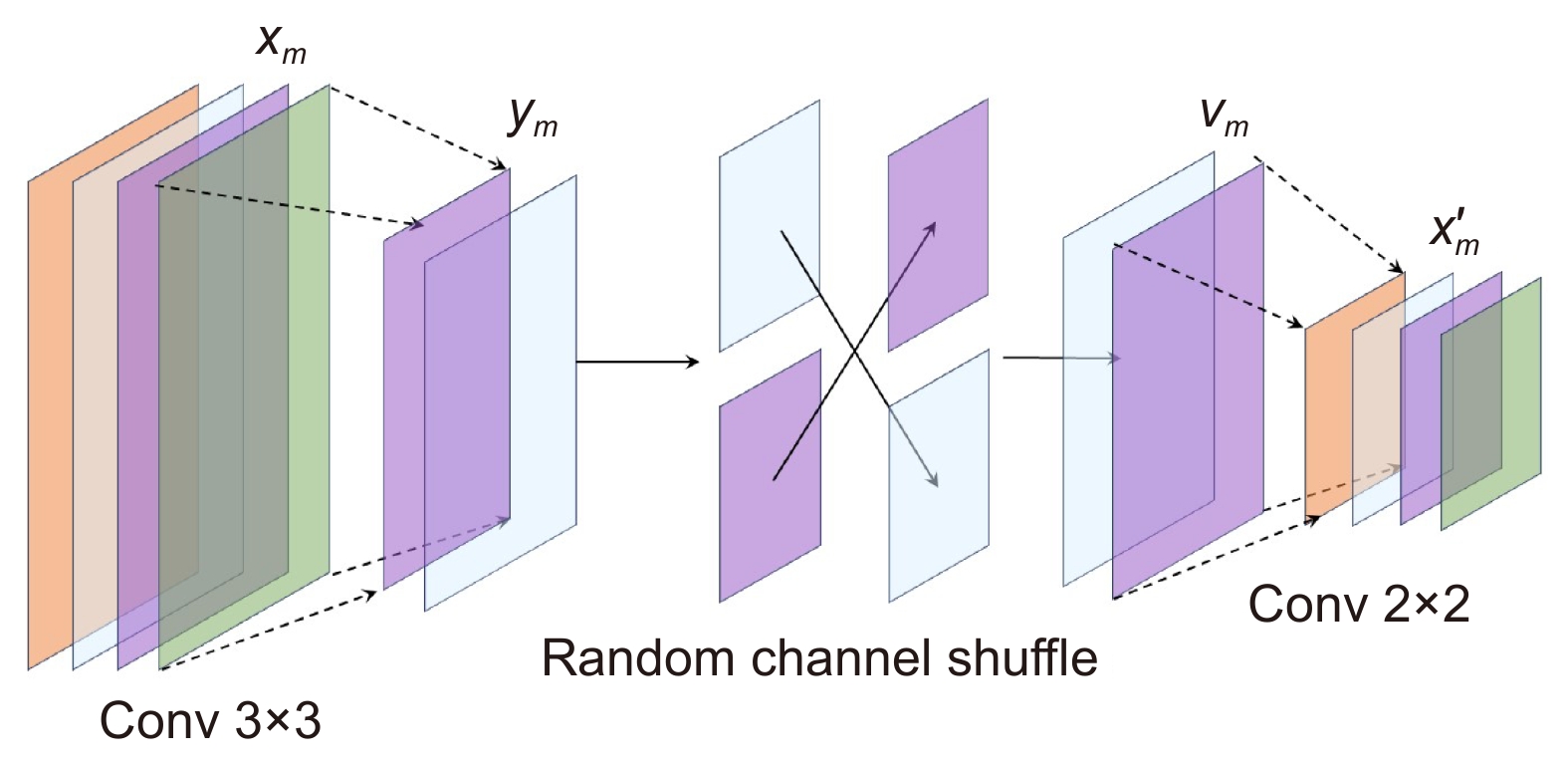
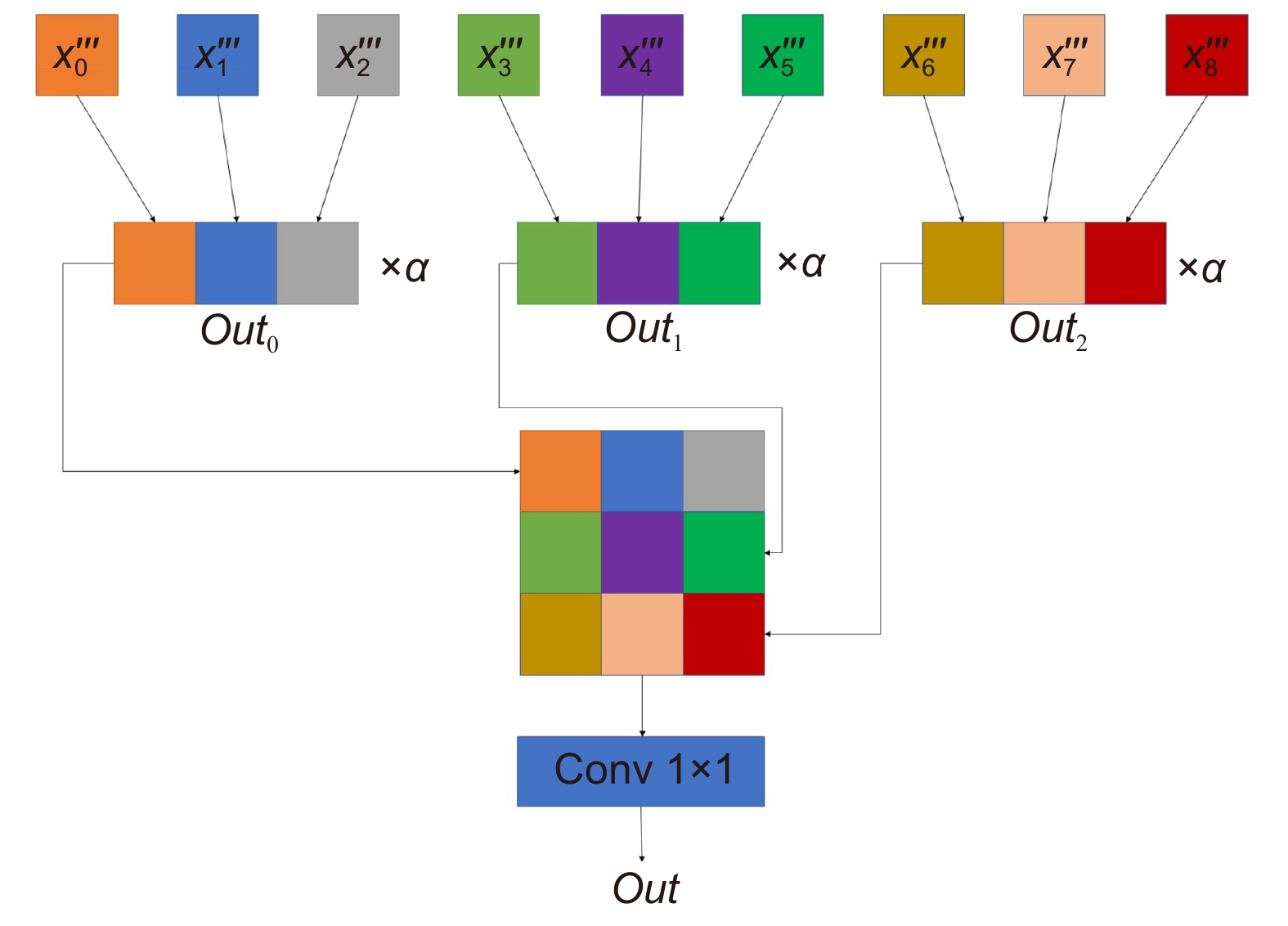
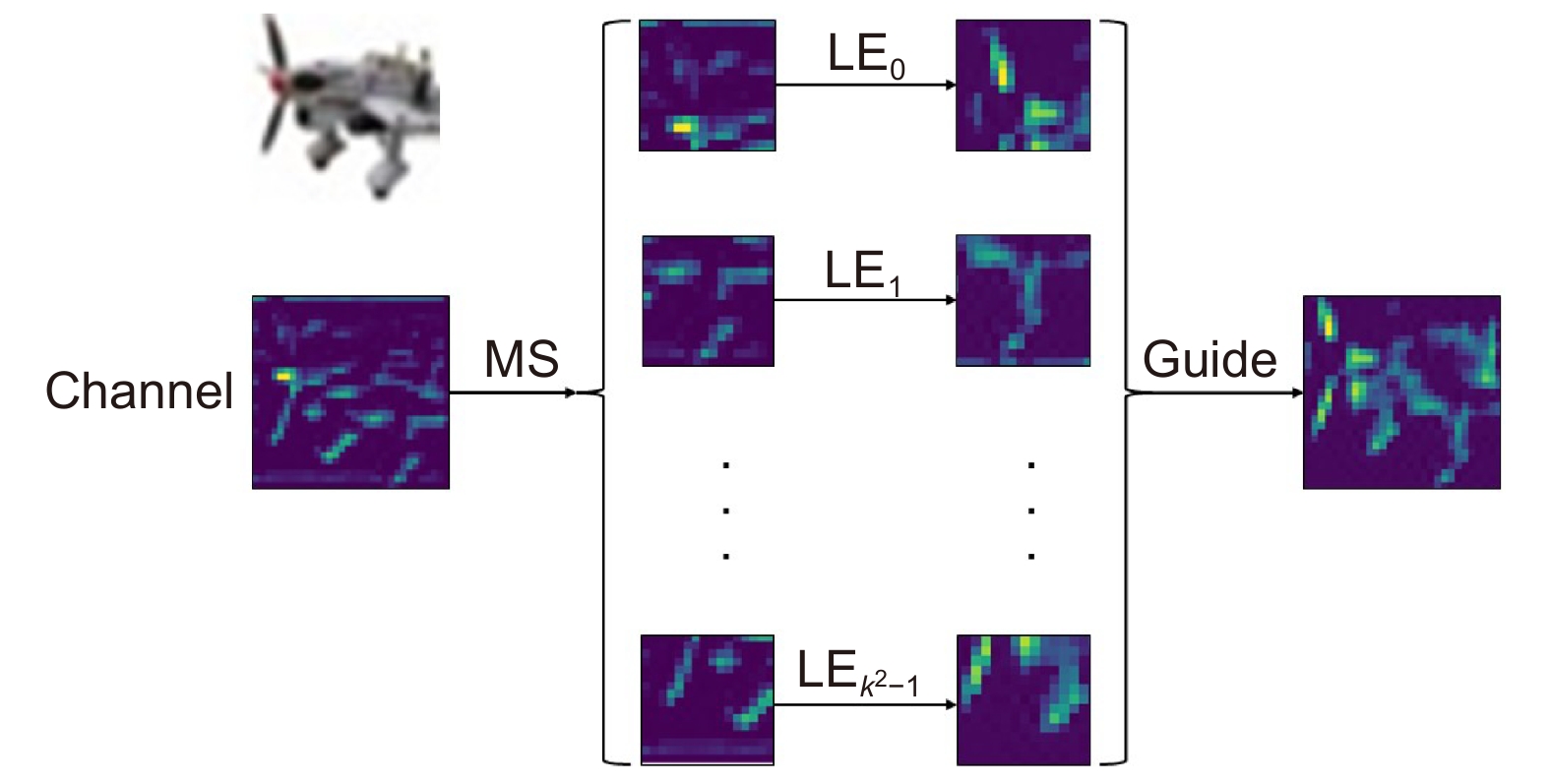
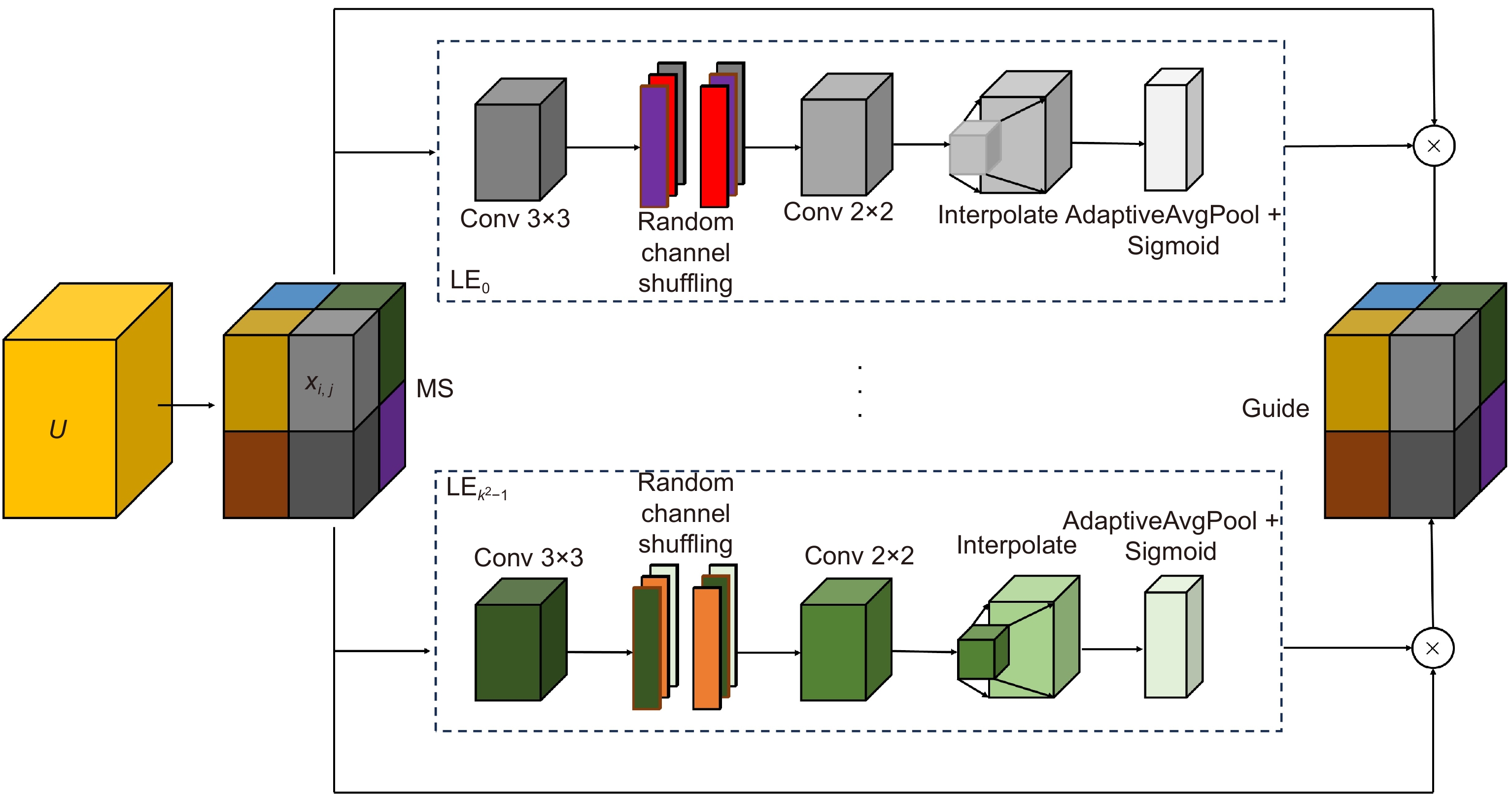
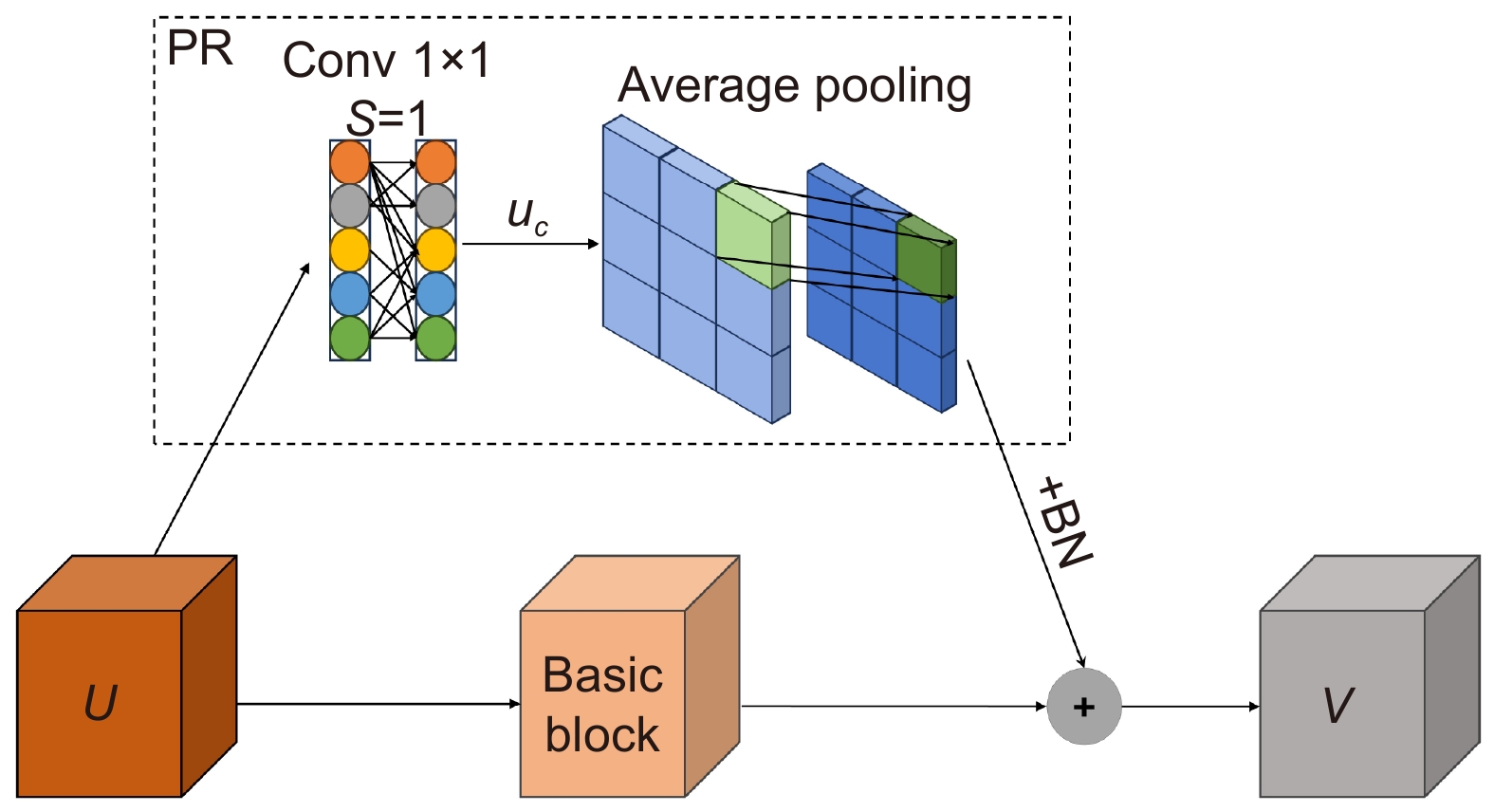
Overview: In image classification tasks, it has been demonstrated through various experiments that attention mechanisms can significantly enhance a model’s generalization ability. However, most attention mechanisms only focus on enhancing the importance of local or global features, without considering that the interrelationships between local features can also affect the overall image features. To address this issue and improve the model’s generalization ability, this paper proposes a global pooling residual classification network guided by local attention (MSLENet). MSLENet uses ResNet34 as its baseline network. It first modifies the initial convolution structure by replacing the convolution method and removing the pooling layer, allowing the network to retain the basic information of the image and enhance the utilization of detailed information. Secondly, this paper introduces a multiple segmentation local enhancement attention mechanism (MSLE) module, which enhances the information relationship between local and global features and amplifies local key information. The MSLE module consists of three sequential components: the multiple segmentation (MS) module, the local enhancement (LE) module, and the guide module. The MS module uniformly segments the image to fully utilize local information. The LE module enhances the local features of each segmented image and amplifies the local important information of the enhanced segments, thereby improving the interaction among local features and increasing the utilization of local key information. The guide module directs important local features into global features through the interaction between feature layers and different feature groups, thus enhancing the global important features and the network’s expressiveness. Finally, to address the issue of information loss in the residual structure of ResNet, the pooling residual (PR) module is proposed. The PR module modifies the residual structure of ResNet34 by replacing the convolution method in the residual structure with pooling operations, thereby improving the information utilization between layers and reducing the network’s overfitting. Experimental results show that MSLENet achieves accuracy rates of 96.93%, 82.51%, 97.22%, 72.82%, 97.39%, 89.70%, and 95.44% on the CIFAR-10, CIFAR-100, SVHN, STL-10, GTSRB, Imagenette, and NWPU-RESISC45 datasets, respectively. Compared to other networks or modules, MSLENet demonstrates improved performance, proving that the interaction between local and global features, the comprehensive utilization of both local and global information, and the guidance of important local features to global features effectively enhance the network’s accuracy.
-

-
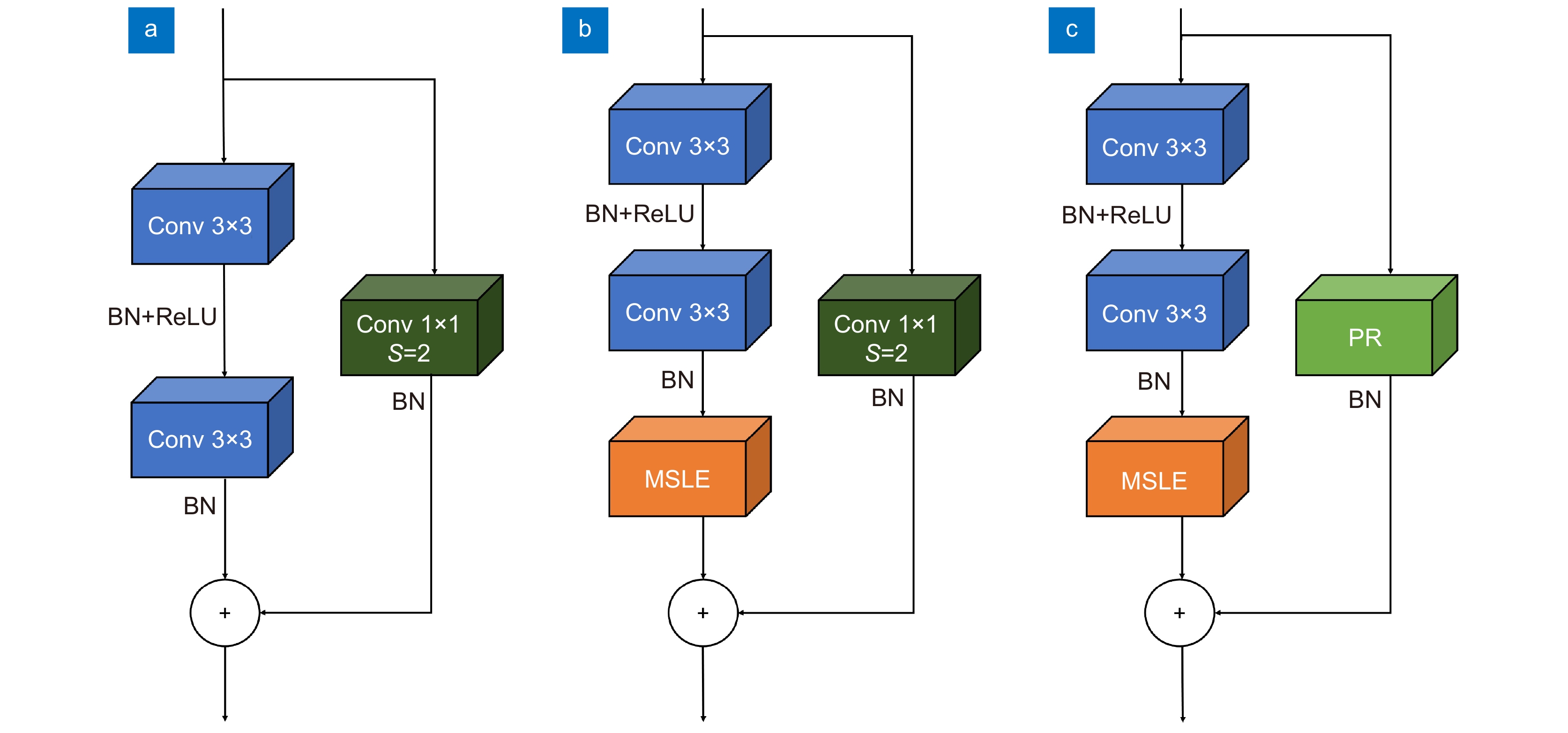
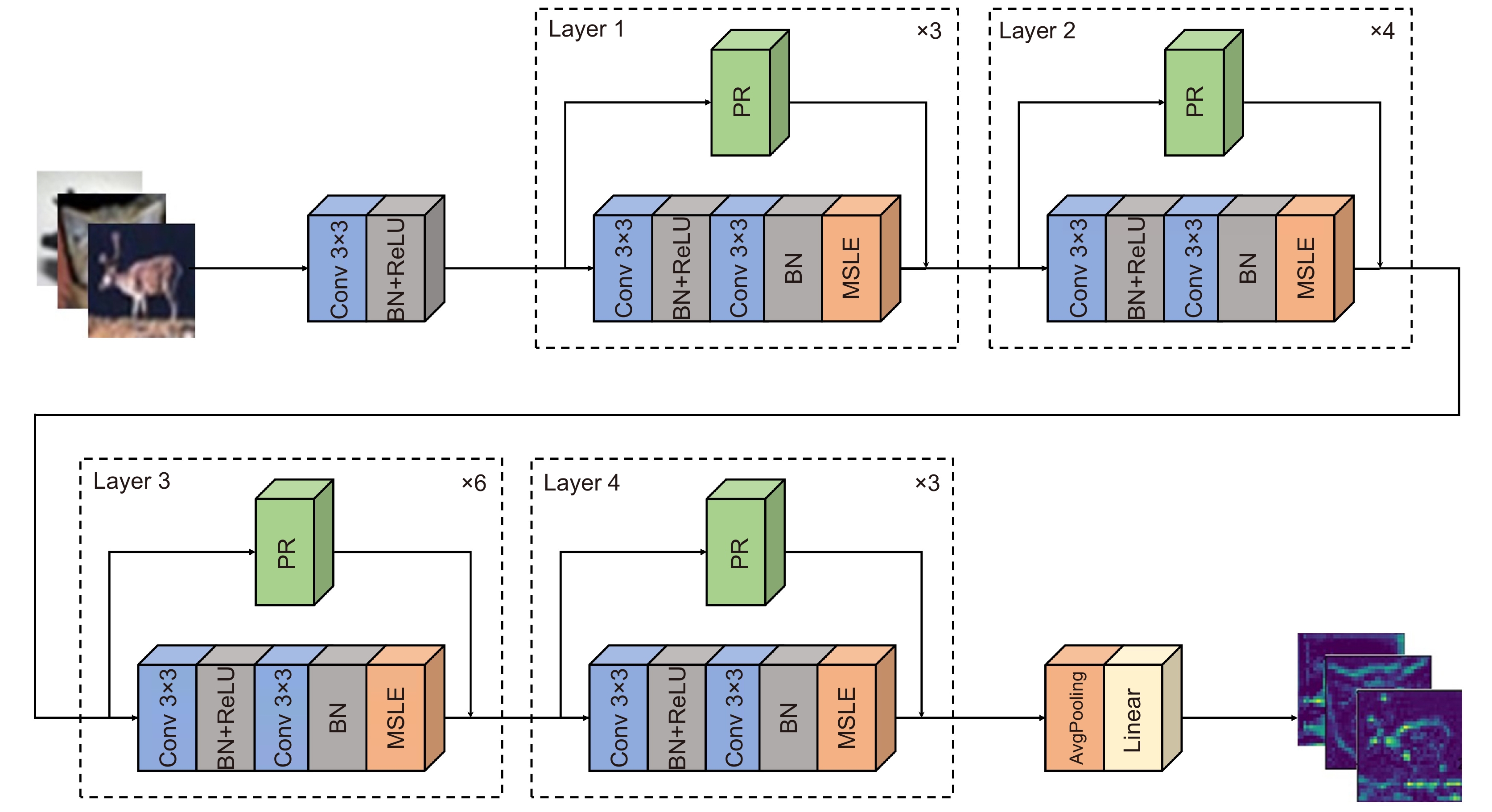
图 8 三种模块结构。 (a)常规残差块; (b)融合MSLE残差块; (c)融合MSLE和PR残差块
Figure 8. Three module structures. (a) Block; (b) M-block; (c) MP-block
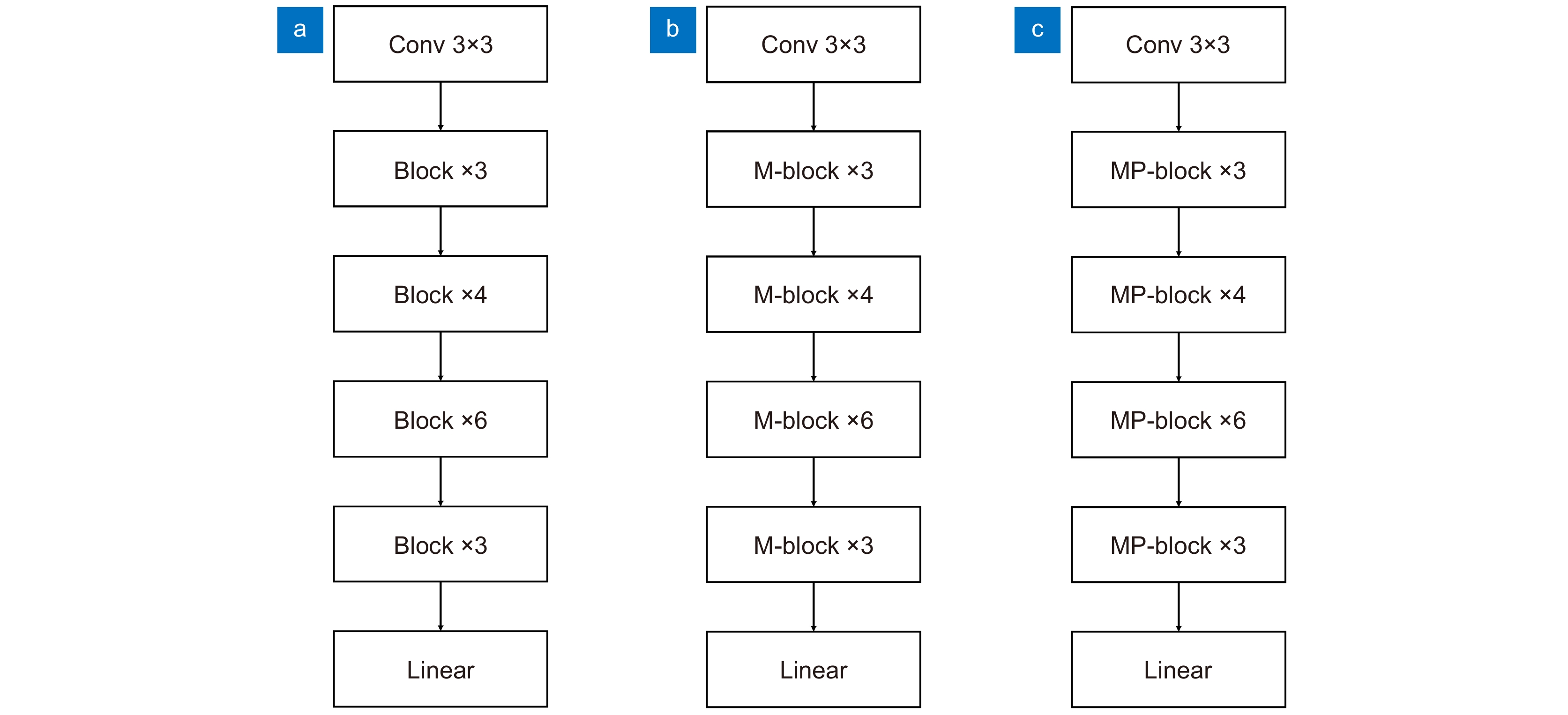
图 10 三种网络结构图。(a)改变首层的ResNet;(b)融合MSLE的MSLENet;(c)融合MSLE和PR的MSLENet
Figure 10. Structure diagrams of three types of network. (a) ResNet34-c; (b) M-MSLENet; (c) MP-MSLENet
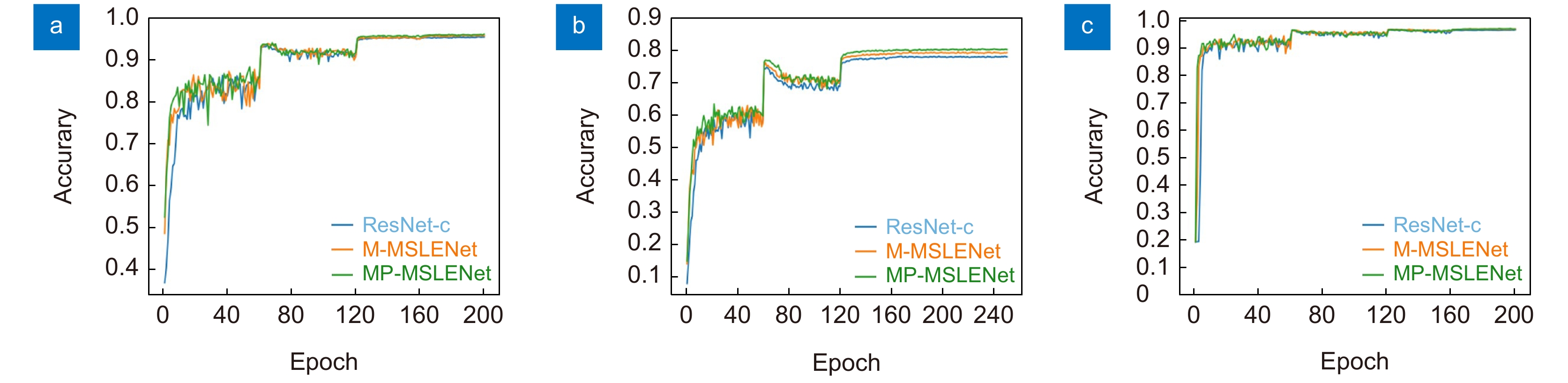
图 11 三种数据集下三种网网络的迭代准确率。(a) CIFAR-10;(b) CIFAR-100;(c) SVHN
Figure 11. Three type of network iteration accuracies under three datasets.(a) CIFAR-10; (b) CIFAR-100; (c) SVHN
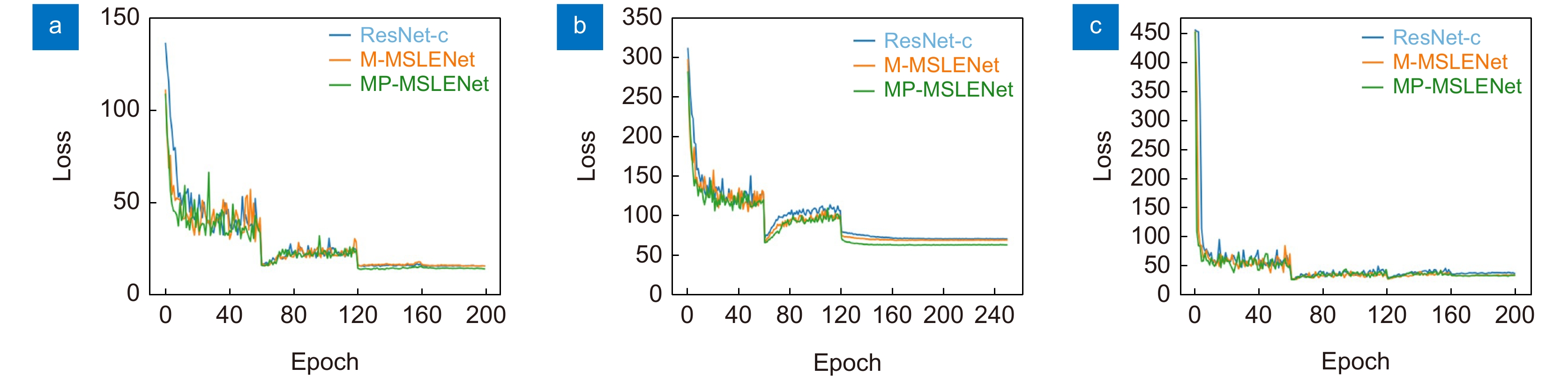
图 12 三种数据集下三种网络的迭代损失。(a) CIFAR-10;(b) CIFAR-100;(c) SVHN
Figure 12. Three type of network iteration loss under three datasets. (a) CIFAR-10; (b) CIFAR-100; (c) SVHN
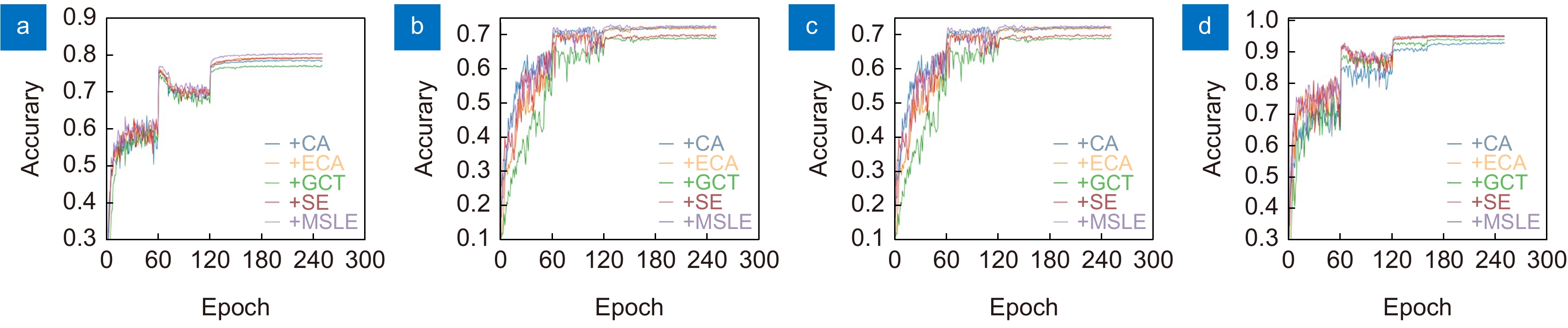
图 13 五种模块不同迭代次数下的准确率。(a) CIFAR-1100;(b) STL-10; (c) Imagenette;(d) NWPU-RESISC45
Figure 13. Accuracy of five modules at different iterations. (a) CIFAR-100;(b) STL-10; (c) Imagenette; (d) NWPU-RESISC45

图 14 不同模块下的通道可视化图像。 (a) CA; (b) ECA; (c) GCT; (d) SE; (e) M-APC
Figure 14. Channel visualizations under different modules. (a) CA; (b) ECA; (c) GCT; (d) SE; (e) M-APC
表 1 数据集
Table 1. Dataset
名称 图像尺寸 分类数 训练集数量 测试集数量 CIFAR-10 32×32 10 50000 10000 CIFAR-100 32×32 100 50000 10000 SVHN 32×32 10 73257 26032 GTSRB 32×32 43 39209 12630 STL-10 96×96 10 5000 8000 Imagenette 320×320 10 7000 3000 NWPU-RESISC45 256×256 45 27000 4500  下载: 导出CSV
下载: 导出CSV
表 2 三种网络在三种数据集下的准确率
Table 2. Accuracy of three networks under three datasets
网络 CIFAR-10/% CIFAR-100/% SVHN/% ResNet-c 95.38 78.02 96.63 M-MSLENet 95.78 79.33 96.89 MP-MSLENet 96.02 80.42 96.94%
下载: 导出CSV
表 3 四种网络的参数对比
Table 3. Comparison of parameters for four modules
网络 准确率/% F1-score Xentropy MSLENet18 79.14 0.7916 0.012 MSLENet34 80.42 0.8065 0.008 MSLENet50 78.66 0.7883 0.010 MSLENet101 79.65 0.7965 0.008
下载: 导出CSV
表 4 五种模块在CIFAR-100的参数对比
Table 4. Comparison of parameters for five modules on CIFAR-100
网络 准确率/% F1-score Xentropy +CA 78.55 0.7881 0.010 +ECA 79.33 0.7949 0.011 +GCT 77.08 0.7810 0.012 +SE 79.25 0.7932 0.010 +MSLE 80.37 0.8054 0.009
下载: 导出CSV
表 5 五种模块在STL-10的参数对比
Table 5. Comparison of parameters for five modules on STL-10
网络 准确率/% F1-score Xentropy +CA 72.25 0.7228 0.005 +ECA 72.40 0.7241 0.006 +GCT 69.26 0.6931 0.008 +SE 70.32 0.7040 0.007 +MSLE 72.78 0.7282 0.003
下载: 导出CSV
表 6 五种模块在Imagenette的参数对比
Table 6. Comparison of parameters for five modules on Imagenette
网络 准确率/% F1-score Xentropy +CA 89.14 0.8924 0.003 +ECA 88.87 0.8903 0.004 +GCT 87.34 0.8745 0.002 +SE 89.07 0.8907 0.003 +MSLE 89.70 0.8991 0.002
下载: 导出CSV
表 7 五种模块在NWPU-RESISC45的参数对比
Table 7. Comparison of parameters for five modules on NWPU-RESISC45
网络 准确率/% F1-score Xentropy +CA 93.00 0.9302 0.012 +ECA 95.33 0.9533 0.003 +GCT 94.20 0.9421 0.007 +SE 95.13 0.9513 0.003 +MSLE 95.40 0.9540 0.004
下载: 导出CSV
表 8 训练过程中超参数的设定值
Table 8. Setting values of hyperparameters during training process
超参数 设定值 Input size 32×32 RandomCrop 4 RandomHorizontalFlip 0.5 RandomErasing 0.2 epochs 300 优化器 SGD lr 0.1 lr decay 0.2 batch size 128 Momentum 0.9 Weight decay 5e-4 Mixup 0.2 EMA 0.9 Label Smoothing 0.1 k [4,2,0,0] l 16
下载: 导出CSV
表 9 各网络在三种数据集下的分类准确率
Table 9. Classification accuracy of each network under three datasets
网络 CIFAR-10/% CIFAR-100/% SVHN/% VGG-16 91.79 67.84 - SENet 95.22 73.22 87.06 DenseNet-121 94.55 77.01 95.83 CAPR-DenseNet 94.24 78.84 94.95 MobileNetV2 93.37 68.08 - ShuffleNet 89.40 70.06 - ResNet34 87.89 69.41 91.51 Multi-ResNet 94.65 78.68 - EfficientNet 94.01 75.96 93.32 SSE-GAN 85.14 - 92.92 Couplformer 93.54 73.92 94.26 ResNet50+SPAM - 80.53 - FAVOR+ 91.42 72.56 93.21 ResNet-CE 94.27 76.15 - MMA-CCT-7/3×2 94.74 77.5 94.26 CaiT 94.91 79.89 -- Swin-T 94.46 78.07 -- MSLENet 96.93 82.28 97.22
下载: 导出CSV
表 10 各个网络的计算量和参数量
Table 10. FLOPs and params of various networks
网络 Params/M FLOPs/G Wide-ResNet 37.16 5.96 ConvNext 27.80 1.45 EfficientNet 52.98 1.49 Swim-T 86.78 4.25 Multi-ResNet 51.23 3.13 MSLENet 22.35 1.20
下载: 导出CSV
表 11 各个网络实验结果
Table 11. Experimental results of various networks
网络 CIFAR-10/% CIFAR-100/% GTSRB/% NWPU-RESISC45/% Net_2_2_0_0 96.81 79.65 97.26 95.17 Net_4_2_0_0 96.93 82.28 97.39 95.40 Net_4_2_2_0 96.80 82.23 97.13 95.44 Net_8_4_2_0 96.90 82.51 97.27 95.15
下载: 导出CSV
-
[1] Robbins H, Monro S. A stochastic approximation method[J]. Ann Math Statist, 1951, 22(3): 400−407. doi: 10.1214/aoms/1177729586
[2] Yang H, Li J. Label contrastive learning for image classification[J]. Soft Comput, 2023, 27(18): 13477−13486. doi: 10.1007/s00500-022-07808-z
[3] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proc IEEE, 1998, 86(11): 2278−2324. doi: 10.1109/5.726791
[4] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Commun ACM, 2017, 60(6): 84−90. doi: 10.1145/3065386
[5] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]//Proceedings of the 3rd International Conference on Learning Representations, San Diego, 2015.
[6] Szegedy C, Liu W, Jia Y Q, et al. Going deeper with convolutions[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, 2015: 1–9. https://doi.org/10.1109/CVPR.2015.7298594.
[7] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90.
[8] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, 2017: 2261–2269. https://doi.org/10.1109/CVPR.2017.243.
[9] Abdi M, Nahavandi S. Multi-residual networks: improving the speed and accuracy of residual networks[Z]. arXiv: 1609.05672, 2017. https://arxiv.org/abs/1609.05672.
[10] Howar A G, Zhu M L, Chen B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[Z]. arXiv: 1704.04861, 2017. https://arxiv.org/abs/1704.04861.
[11] Zhang X Y, Zhou X Y, Lin M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 6848–6856. https://doi.org/10.1109/CVPR.2018.00716.
[12] Jaderberg M, Simonyan K, Zisserman A, et al. Spatial transformer networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, 2015: 2017–2025.
[13] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[14] Yang Z X, Zhu L C, Wu Y, et al. Gated channel transformation for visual recognition[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 11794–11801. https://doi.org/10.1109/CVPR42600.2020.01181.
[15] 张峰, 黄仕鑫, 花强, 等. 基于Depth-wise卷积和视觉Transformer的图像分类模型[J]. 计算机科学, 2024, 51(2): 196−204. doi: 10.11896/jsjkx.221100234
Zhang F, Huang S X, Hua Q, et al. Novel image classification model based on depth-wise convolution neural network and visual transformer[J]. Comput Sci, 2024, 51(2): 196−204. doi: 10.11896/jsjkx.221100234
[16] Hou Q B, Zhou D Q, Feng J S. Coordinate attention for efficient mobile network design[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, 2021: 13708–13717. https://doi.org/10.1109/CVPR46437.2021.01350.
[17] Wang Q L, Wu B G, Zhu P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155.
[18] Zhong Z, Zheng L, Kang G L, et al. Random erasing data augmentation[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, 2020. https://doi.org/10.1609/aaai.v34i07.7000.
[19] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, 2016: 2818–2826. https://doi.org/10.1109/CVPR.2016.308.
[20] Zhang H Y, Cissé M, Dauphin Y N, et al. mixup: beyond empirical risk minimization[C]//Proceedings of the 6th International Conference on Learning Representations, Vancouver, 2018.
[21] Polyak B T. Some methods of speeding up the convergence of iteration methods[J]. USSR Comput Math Math Phys, 1964, 4(5): 1−17. doi: 10.1016/0041-5553(64)90137-5
[22] Zhang K, Guo Y R, Wang X S, et al. Channel-wise and feature-points reweights densenet for image classification[C]// Proceedings of 2019 IEEE International Conference on Image Processing, Taipei, China, 2019: 410–414. https://doi.org/10.1109/ICIP.2019.8802982.
[23] Tan M X, Le Q V. EfficientNet: rethinking model scaling for convolutional neural networks[C]//Proceedings of the 36th International Conference on Machine Learning, Long Beach, 2019: 6105–6114.
[24] 付晓, 沈远彤, 李宏伟, 等. 基于半监督编码生成对抗网络的图像分类模型[J]. 自动化学报, 2020, 46(3): 531−539. doi: 10.16383/j.aas.c180212
Fu X, Shen Y T, Li H W, et al. A semi-supervised encoder generative adversarial networks model for image classification[J]. Acta Autom Sin, 2020, 46(3): 531−539. doi: 10.16383/j.aas.c180212
[25] Choromanski K M, Likhosherstov V, Dohan D, et al. Rethinking attention with performers[C]//Proceedings of the 9th International Conference on Learning Representations, 2021.
[26] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, 2011: 315–323.
[27] 王方, 乔瑞萍. 用于图像分类的深度卷积神经网络中的空间分割注意力模块[J]. 西安交通大学学报, 2023, 57(9): 185−192. doi: 10.7652/xjtuxb202309019
Wang F, Qiao R P. SPAM: spatially partitioned attention module in deep convolutional neural networks for image classification[J]. J Xi'an Jiaotong Univ, 2023, 57(9): 185−192. doi: 10.7652/xjtuxb202309019
[28] 杨萌林, 张文生. 分类激活图增强的图像分类算法[J]. 计算机科学与探索, 2020, 14(1): 149−158. doi: 10.3778/j.issn.1673-9418.1902025
Yang M L, Zhang W S. Image classification algorithm based on classification activation map enhancement[J]. J Front Comput Sci Technol, 2020, 14(1): 149−158. doi: 10.3778/j.issn.1673-9418.1902025
[29] Konstantinidis D, Papastratis I, Dimitropoulos K, et al. Multi-manifold attention for vision transformers[J]. IEEE Access, 2023, 11: 123433−123444. doi: 10.1109/ACCESS.2023.3329952
[30] Touvron H, Cord M, Sablayrolles A, et al. Going deeper with image transformers[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, Montreal, 2021: 32–42. https://doi.org/10.1109/ICCV48922.2021.00010.
[31] Liu Z, Lin Y T, Cao Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, Montreal, 2021: 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986.
[32] Woo S, Debnath S, Hu R H, et al. ConvNeXt V2: co-designing and scaling ConvNets with masked autoencoders[C]// Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, 2023: 16133–1614. https://doi.org/10.1109/CVPR52729.2023.01548.
-

 点击扫一扫
点击扫一扫
图(15)
表(11)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


