
 E-mail Alert
E-mail Alert RSS
RSS
LF-UMTI: unsupervised multi-exposure light field image fusion based on multi-scale spatial-angular interaction
-
摘要:
光场成像可同时捕获真实场景中光线的强度和方向信息。但受限于成像传感器的势阱容量,现光场相机单曝光捕获的光场图像难以完整记录真实场景中所有的细节信息。为了解决上述问题,本文提出了一种基于多尺度空角交互的无监督多曝光光场成像方法。该方法采用多尺度空角交互策略,以有效提取光场空角特征,同时利用通道维上建模策略以降低计算量来适应光场高维结构。其次,构建了由可逆神经网络导向的光场重建模块,以避免融合伪影并恢复更多细节信息。最后,设计了一种角度一致性损失,其考虑了边界子孔径图像和中心子孔径图像之间的视差变化,以保证融合结果的视差结构。为评估所提方法的性能,建立了一个面向真实场景的多曝光光场基准数据集。实验结果表明,所提方法可在保证角度一致性的前提下重建出具备高对比度和丰富细节的光场图像。与现有方法相比,所提方法在客观质量和主观视觉两方面均取得更好的结果。
Abstract:Light field imaging can simultaneously capture the intensity and direction information of light in a real-world scene. However, due to the limited capacity of imaging sensors, light field images captured with a single exposure struggle to fully record all the details in the real scene. To address the aforementioned issue, an unsupervised multi-exposure light field imaging method based on multi-scale spatial-angular interactions is proposed in this paper. A multi-scale spatial-angular interaction strategy is adopted to effectively extract spatial-angular features of the light field. Additionally, a channel-wise modeling strategy is employed to reduce computational complexity and adapt to the high-dimensional structure of the light field. Furthermore, a light field reconstruction module guided by reversible neural networks is constructed to avoid fusion artifacts and recover more detailed information. Lastly, an angle consistency loss is designed, considering the disparity variations between boundary sub-aperture images and the central sub-aperture image, to ensure the disparity structure of the fusion result. To evaluate the performance of the proposed method, a benchmark dataset for multi-exposure light field imaging is created, targeting real-world scenes. Experimental results demonstrate that the proposed method can reconstruct light field images with high contrast and rich details while ensuring angular consistency. Compared with the existing methods, the proposed method achieves superior results in both objective quality and subjective visual perception.
-
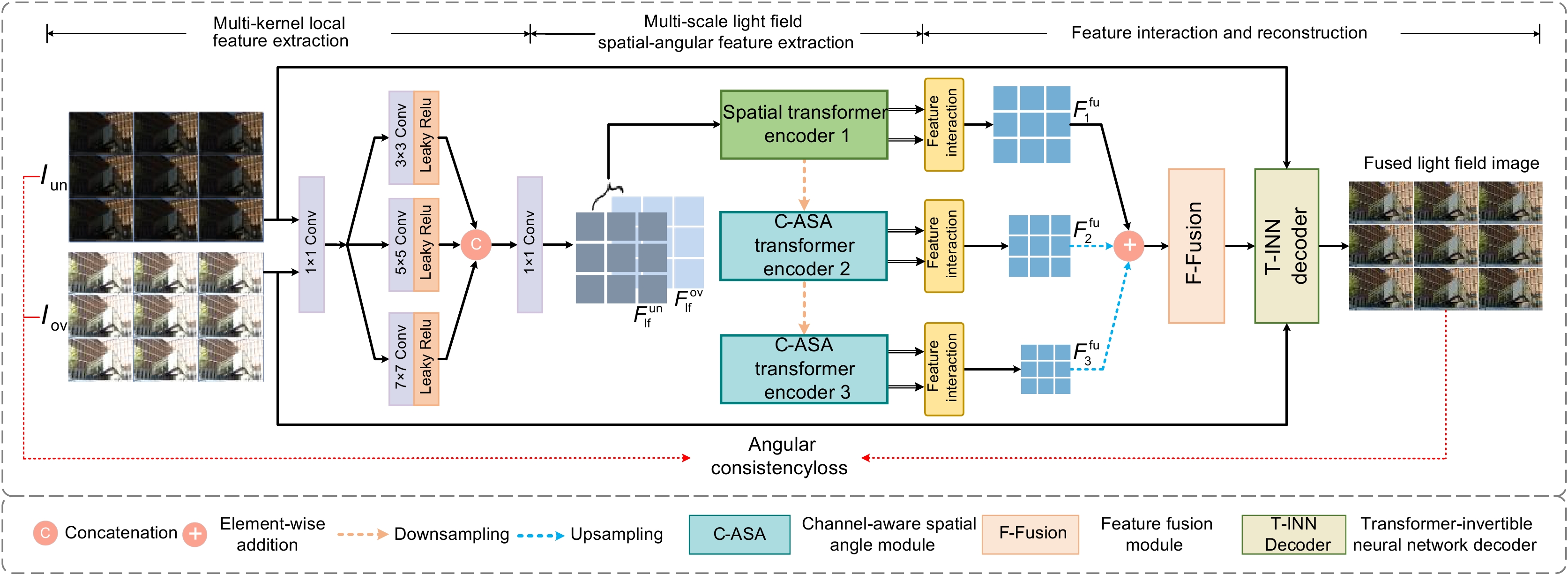
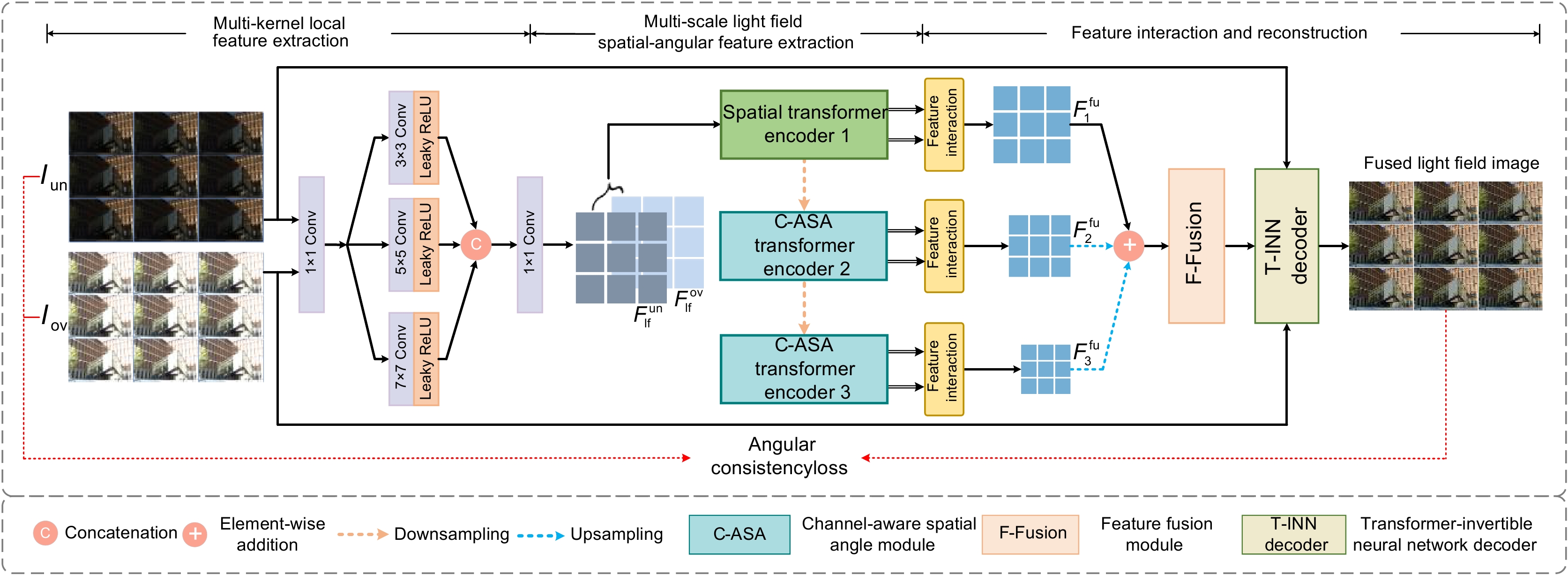
Overview: Light field imaging has unique advantages in many applications such as refocusing and depth estimation, since it can simultaneously capture spatial and angular information of light rays. However, due to the limited dynamic range of the camera, the light field images may suffer from over-exposure and under-exposure issues, bringing challenges to capturing all the details of the real scene and posing difficulties for subsequent light field applications. In recent years, deep learning has shown powerful nonlinear fitting capabilities and has achieved good results in multi-exposure fusion for conventional images. However, the high-dimensional characteristics of light field images make it necessary to consider not only the issues of traditional images suffered from, but also the angular consistency of the fused light field images during multi-exposure fusion. In this paper, an unsupervised multi-exposure light field imaging method (LF-UMTI) based on multi-scale spatial-angular interaction is proposed. Firstly, a multi-scale spatial-angular interaction strategy is employed to extract spatial-angular features and explore complementary information of source light field images at different scales. A channel-dimensional modeling strategy is also employed to reduce computational complexity and adapt to the high-dimensional structure of light fields. Secondly, a light field reconstruction module guided by reversible neural networks is constructed to avoid fusion artifacts and recover more detailed information. Lastly, an angular consistency loss is designed, which takes into account the disparity variations between boundary sub-aperture images and central sub-aperture images to ensure the disparity structure of the fusion result. To evaluate the performance of the proposed method, a benchmark dataset of multi-exposure light field images of the real scenes is established. Through subjective and objective quality evaluations of the fused light field images as well as ablation experiments conducted on the proposed dataset, the effectiveness of the proposed method is demonstrated in reconstructing high-contrast and detail-rich light field images while preserving angular consistency. Considering future research tasks and analyzing the limitations of the network, simplifying the model and improving the operational speed will be key directions for future research tasks.
-

-
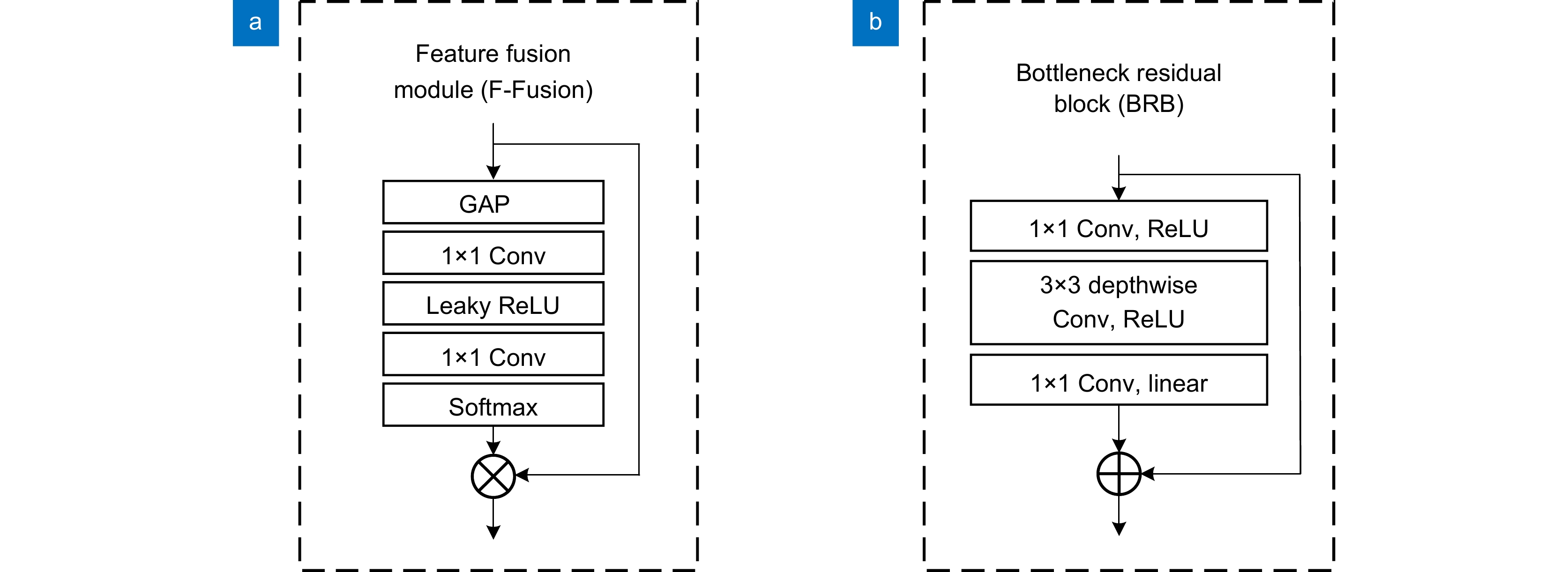
图 4 (a)特征融合模块;(b)瓶颈残差模块
Figure 4. (a) Feature fusion module; (b) Bottleneck residual module

图 6 本文建立的基准数据集中的部分场景示例
Figure 6. Some scene examples in the benchmark dataset established in this work

图 7 不同方法在所建立的基准数据集上的主观对比结果
Figure 7. Subjective comparison results of different methods on the established benchmark dataset

图 8 从不同方法的多曝光光场融合结果中估计出深度图的主观对比结果
Figure 8. Subjective comparison of depth maps estimated from the fused light field images obtained with different fusion methods

图 9 本文主要网络结构消融实验的主观对比结果
Figure 9. Subjective comparison results of the main network structure ablation experiments

图 10 角度一致性损失消融实验的主观对比结果
Figure 10. Subjective comparison results of angle consistency loss ablation experiments
表 1 50个测试场景上不同方法的客观指标对比
Table 1. Comparison of objective indicators among different methods on 50 testing scenarios
Method SD↑ MEFSSIM↑ Qcv↓ SF↑ Qabf↑ Qnice↑ NMI↑ AG↑ Rank↓ DISFT_EF[8] 58.2897(5) 0.9610(3) 679.7548(8) 23.5287(2) 0.7489(3) 0.8118(10) 0.6411(8) 5.4570(7) 46 GFF[7] 60.2416(3) 0.9624(2) 592.7575(10) 25.8524(1) 0.7648(1) 0.8154(7) 0.6074(9) 5.7301(3) 36 MEFAW[9] 54.2736(6) 0.9639(1) 625.0993(9) 22.2241(3) 0.7507(2) 0.8163(6) 0.5215(10) 5.5581(4) 41 PAS_MEF[10] 48.7852(10) 0.8887(9) 517.8809(7) 16.2884(7) 0.5452(6) 0.8146(8) 0.6610(7) 5.5482(5) 59 DeepFuse[20] 53.3335(7) 0.9040(6) 321.1736(4) 16.3365(6) 0.5408(7) 0.8202(3) 0.8482(3) 5.4888(6) 42 PMGI[27] 51.0411(9) 0.8933(8) 361.4652(6) 16.2283(8) 0.5209(8) 0.8194(4) 0.8285(4) 5.4126(8) 55 U2Fusion[26] 52.7949(8) 0.8973(7) 316.6257(3) 15.5335(10) 0.5061(9) 0.8183(5) 0.7999(5) 5.3375(10) 57 TransMEF[21] 60.6602(2) 0.9328(5) 281.9047(2) 18.1766(5) 0.6264(5) 0.8210(1) 0.8758(1) 6.0909(2) 23 FFMEF[22] 58.9095(4) 0.8595(10) 334.6085(5) 16.0121(9) 0.4360(10) 0.8135(9) 0.7276(6) 5.4097(9) 62 Proposed 67.5961(1) 0.9491(4) 238.4925(1) 20.5533(4) 0.6870(4) 0.8205(2) 0.8510(2) 6.7186(1) 19  下载: 导出CSV
下载: 导出CSV
表 2 本文主要网络结构消融实验的客观指标对比结果
Table 2. Comparative results of objective indicators of the main network structure ablation experiments in this article
Method SD↑ MEFSSIM↑ Qcv↓ SF↑ Qabf↑ Qnice↑ NMI↑ AG↑ w/o C-ASA 74.6707 0.8747 313.7698 16.8144 0.4682 0.8143 0.6906 5.7951 w/o T-INN 40.1623 0.7105 948.2726 16.4418 0.3252 0.8095 0.4769 6.1205 w/o MK 66.819 0.8999 252.7716 19.3284 0.5027 0.8142 0.6666 6.3629 Proposed 67.5961 0.9491 238.4925 20.5533 0.687 0.8205 0.851 6.7186
下载: 导出CSV
表 3 不同方法的运行时间及参数量比较结果
Table 3. Comparison results of running time and parameter quantities of different methods
下载: 导出CSV
-
[1] Cui Z L, Sheng H, Yang D, et al. Light field depth estimation for non-lambertian objects via adaptive cross operator[J]. IEEE Trans Circuits Syst Video Technol, 2024, 34(2): 1199−1211. doi: 10.1109/TCSVT.2023.3292884
[2] 马帅, 王宁, 朱里程, 等. 基于边框加权角相关的光场深度估计算法[J]. 光电工程, 2021, 48(12): 210405. doi: 10.12086/oee.2021.210405
Ma S, Wang N, Zhu L C, et al. Light field depth estimation using weighted side window angular coherence[J]. Opto-Electron Eng, 2021, 48(12): 210405. doi: 10.12086/oee.2021.210405
[3] 吴迪, 张旭东, 范之国, 等. 基于光场内联遮挡处理的噪声场景深度获取[J]. 光电工程, 2021, 48(7): 200422. doi: 10.12086/oee.2021.200422
Wu D, Zhang X D, Fan Z G, et al. Depth acquisition of noisy scene based on inline occlusion handling of light field[J]. Opto-Electron Eng, 2021, 48(7): 200422. doi: 10.12086/oee.2021.200422
[4] Cong R X, Yang D, Chen R S, et al. Combining implicit-explicit view correlation for light field semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 9172–9181. https://doi.org/10.1109/CVPR52729.2023.00885.
[5] Han L, Zhong D W, Li L, et al. Learning residual color for novel view synthesis[J]. IEEE Trans Image Process, 2022, 31: 2257−2267. doi: 10.1109/TIP.2022.3154242
[6] Xu F, Liu J H, Song Y M, et al. Multi-exposure image fusion techniques: a comprehensive review[J]. Remote Sens, 2022, 14(3): 771. doi: 10.3390/rs14030771
[7] Li S T, Kang X D, Hu J W. Image fusion with guided filtering[J]. IEEE Trans Image Process, 2013, 22(7): 2864−2875. doi: 10.1109/TIP.2013.2244222
[8] Liu Y, Wang Z F. Dense SIFT for ghost-free multi-exposure fusion[J]. J Visual Commun Image Represent, 2015, 31: 208−224. doi: 10.1016/j.jvcir.2015.06.021
[9] Lee S, Park J S, Cho N I. A multi-exposure image fusion based on the adaptive weights reflecting the relative pixel intensity and global gradient[C]//Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), 2018: 1737–1741. https://doi.org/10.1109/ICIP.2018.8451153.
[10] Ulucan O, Ulucan D, Turkan M. Ghosting-free multi-exposure image fusion for static and dynamic scenes[J]. Signal Process, 2023, 202: 108774. doi: 10.1016/j.sigpro.2022.108774
[11] Gul M S K, Wolf T, Bätz M, et al. A high-resolution high dynamic range light-field dataset with an application to view synthesis and tone-mapping[C]//2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 2020: 1–6. https://doi.org/10.1109/ICMEW46912.2020.9105964.
[12] Li C, Zhang X. High dynamic range and all-focus image from light field[C]//Proceedings of the 7th IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), 2015: 7–12. https://doi.org/10.1109/ICCIS.2015.7274539.
[13] Le Pendu M, Guillemot C, Smolic A. High dynamic range light fields via weighted low rank approximation[C]//Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), 2018: 1728–1732. https://doi.org/10.1109/ICIP.2018.8451584.
[14] Yin J L, Chen B H, Peng Y T. Two exposure fusion using prior-aware generative adversarial network[J]. IEEE Trans Multimedia, 2021, 24: 2841−2851. doi: 10.1109/TMM.2021.3089324
[15] Xu H, Ma J Y, Zhang X P. MEF-GAN: multi-exposure image fusion via generative adversarial networks[J]. IEEE Trans Image Process, 2020, 29: 7203−7216. doi: 10.1109/TIP.2020.2999855
[16] Liu J Y, Wu G Y, Luan J S, et al. HoLoCo: holistic and local contrastive learning network for multi-exposure image fusion[J]. Inf Fusion, 2023, 95: 237−249. doi: 10.1016/j.inffus.2023.02.027
[17] Liu J Y, Shang J J, Liu R S, et al. Attention-guided global-local adversarial learning for detail-preserving multi-exposure image fusion[J]. IEEE Trans Circuits Syst Video Technol, 2022, 32(8): 5026−5040. doi: 10.1109/TCSVT.2022.3144455
[18] Chen Y Y, Jiang G Y, Yu M, et al. Learning to simultaneously enhance field of view and dynamic range for light field imaging[J]. Inf Fusion, 2023, 91: 215−229. doi: 10.1016/j.inffus.2022.10.021
[19] Ram Prabhakar K, Sai Srikar V, Venkatesh Babu R. DeepFuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 4724–4732. https://doi.org/10.1109/ICCV.2017.505.
[20] Ma K D, Duanmu Z F, Zhu H W, et al. Deep guided learning for fast multi-exposure image fusion[J]. IEEE Trans Image Process, 2020, 29: 2808−2819. doi: 10.1109/TIP.2019.2952716
[21] Qu L H, Liu S L, Wang M N, et al. TransMEF: a transformer-based multi-exposure image fusion framework using self-supervised multi-task learning[C]//Proceedings of the 36th AAAI Conference on Artificial Intelligence, 2022: 2126–2134. https://doi.org/10.1609/AAAI.v36i2.20109.
[22] Zheng K W, Huang J, Yu H, et al. Efficient multi-exposure image fusion via filter-dominated fusion and gradient-driven unsupervised learning[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2023: 2804–2813. https://doi.org/10.1109/CVPRW59228.2023.00281.
[23] Xu H, Haochen L, Ma JY. Unsupervised multi-exposure image fusion breaking exposure limits via contrastive learning[C]//Proceedings of 37th AAAI Conference on Artificial Intelligence, 2023: 3010–3017. https://doi.org/10.1609/AAAI.v37i3.25404.
[24] Zhang H, Ma J Y. IID-MEF: a multi-exposure fusion network based on intrinsic image decomposition[J]. Inf Fusion, 2023, 95: 326−340. doi: 10.1016/j.inffus.2023.02.031
[25] Xu H, Ma J Y, Le Z L, et al. FusionDN: a unified densely connected network for image fusion[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, 2020: 12484–12491. https://doi.org/10.1609/AAAI.v34i07.6936.
[26] Xu H, Ma J Y, Jiang J J, et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Trans Pattern Anal Mach Intell, 2022, 44(1): 502−518. doi: 10.1109/TPAMI.2020.3012548
[27] Zhang H, Xu H, Xiao Y, et al. Rethinking the image fusion: a fast unified image fusion network based on proportional maintenance of gradient and intensity[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, 2020: 12797–12804. https://doi.org/10.1609/AAAI.v34i07.6975.
[28] Zhou M, Huang J, Fang Y C, et al. Pan-sharpening with customized transformer and invertible neural network[C]//Proceedings of the 36th AAAI Conference on Artificial Intelligence, 2022: 3553–3561. https://doi.org/10.1609/aaai.v36i3.20267.
[29] Ma K D, Zeng K, Wang Z. Perceptual quality assessment for multi-exposure image fusion[J]. IEEE Trans Image Process, 2015, 24(11): 3345−3356. doi: 10.1109/TIP.2015.2442920
[30] Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans Image Process, 2004, 13(4): 600−612. doi: 10.1109/TIP.2003.819861
[31] Hossny M, Nahavandi S, Creighton D. Comments on ‘Information measure for performance of image fusion’[J]. Electron Lett, 2008, 44(18): 1066−1067. doi: 10.1049/el:20081754
[32] Wang Q, Shen Y, Jin J. Performance evaluation of image fusion techniques[M]//Stathaki T. Image Fusion: Algorithms and Applications. Amsterdam: Academic Press, 2008: 469–492. https://doi.org/10.1016/B978-0-12-372529-5.00017-2.
[33] Cui G M, Feng H J, Xu Z H, et al. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition[J]. Opt Commun, 2015, 341: 199−209. doi: 10.1016/j.optcom.2014.12.032
[34] Xydeas C S, Petrovic V. Objective image fusion performance measure[J]. Electronics letters, 2000, 36(4): 308−309. doi: 10.1049/el:20000267
[35] Rao Y J. In-fibre Bragg grating sensors[J]. Meas Sci Technol, 1997, 8(4): 355−375. doi: 10.1088/0957-0233/8/4/002
[36] Eskicioglu A M, Fisher P S. Image quality measures and their performance[J]. IEEE Trans Commun, 1995, 43 (12): 2959–2965. https://doi.org/10.1109/26.477498.
[37] Chen H, Varshney P K. A human perception inspired quality metric for image fusion based on regional information[J]. Inf Fusion, 2007, 8(2): 193−207. doi: 10.1016/j.inffus.2005.10.001
-
 点击扫一扫
点击扫一扫
图(11)
表(3)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


