
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
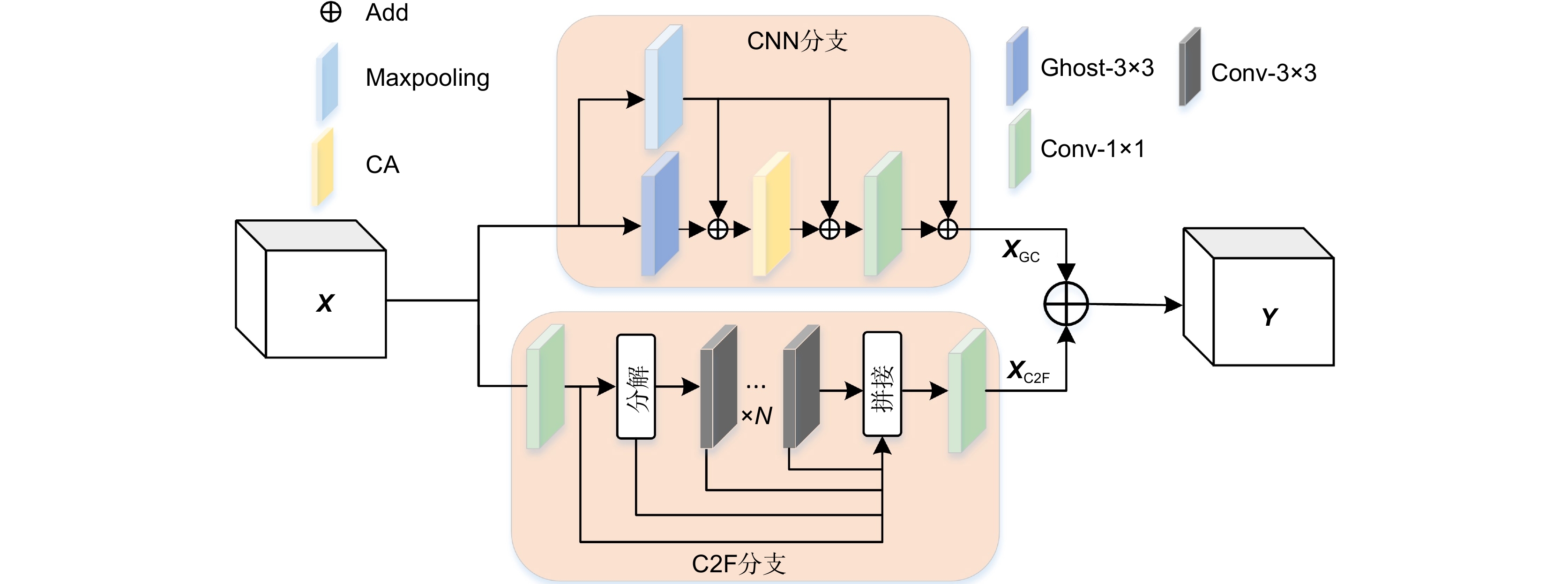
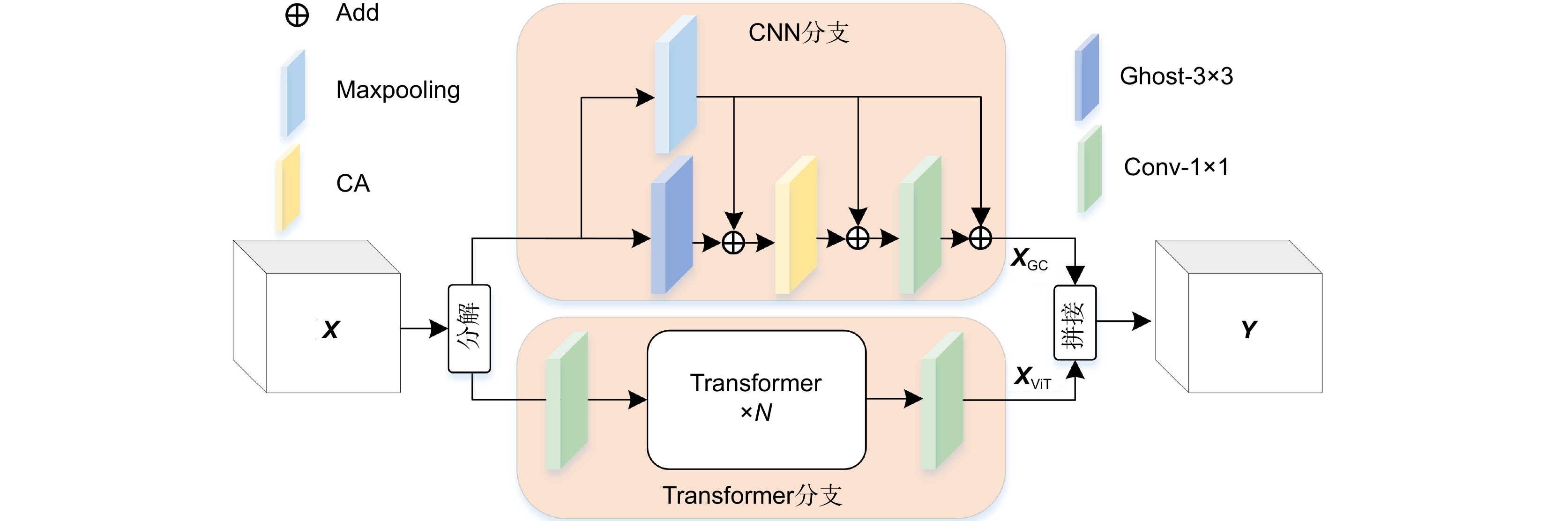
太阳能电池片表面缺陷具有类内差异大、类间差异小和背景特征复杂等特点,因此,要实现高精度的太阳能电池片表面缺陷自动检测是一项富有挑战性的任务。针对此问题,该文提出融合局部和全局特征的卷积视觉Transformer网络(CViT-Net),首先采用Ghost聚焦(G-C2F)模块提取电池片缺陷局部特征;然后引进坐标注意力强调缺陷特征并抑制背景特征;最后构建Ghost视觉(G-ViT)模块融合电池片缺陷局部特征和全局特征。同时,针对不同检测精度和模型参数量,分别提供了CViT-Net-S和 CViT-Net-L两种网络结构。实验结果表明,与经典MobileVit、MobileNetV3和GhostNet轻量级网络相比,CViT-Net-S对电池片分类准确率分别提升了1.4%、2.3%和1.3%,对电池片检测mAP50分别提升了2.7%、0.3%和0.8%;与ResNet50、RegNet网络相比,CViT-Net-L分类准确率分别提升了0.72%和0.7%,检测mAP50分别提升了3.9%、1.3%;与先进YOLOv6、YOLOv7和YOLOv8检测网络相比,作为骨干网络的CViT-Net-S、 CViT-Net-L结构在mAP和mAP50指标上仍保持良好检测效果。结果证明本文算法在太阳能电池片表面缺陷检测领域具有应用价值。
Abstract
The surface defects of solar cells exhibit significant intra-class differences, minor inter-class differences, and complex background features, making high-precision identification of surface defects a challenging task. This paper proposes a Convolutional -Vision Transformer Network (CViT-Net) that combines local and global features to address this issue. First, a Ghost-Convolution two-fusion (G-C2F) module is used to extract local features of the solar cell panel defects. Then, a coordinate attention mechanism is introduced to emphasize defect features and suppress background features. Finally, a Ghost-Vision Transformer (G-ViT) module is constructed to fuse local and global features of the solar cell panel defects. Meanwhile, CViT-Net-S and CViT-Net-L network structures are provided for low-resource and high-resource environments. Experimental results show that compared to classic lightweight networks such as MobileVit, MobileNetV3, and GhostNet, CViT-Net-S improves the classification accuracy of solar cell panels by 1.4%, 2.3%, and 1.3%, respectively, and improves the mAP50 for defect detection by 2.7%, 0.3%, and 0.8% respectively. Compared to ResNet50 and RegNet, CViT-Net-L enhances the classification accuracy by 0.72% and 0.7%, respectively, and improves the mAP50 for defect detection by 3.9% and 1.3%, respectively. Compared to advanced YOLOV6, YOLOV7, and YOLOV8 detection networks, CViT-Net-S and CViT-Net-L structures, as backbone networks, still maintain good detection performance in terms of mAP and mAP50 metrics, demonstrating the application value of the proposed algorithm in the field of solar cell panel surface defect detection.
-
Key words:
- deep learning /
- feature fusion /
- solar cells /
- defect classification /
- defect detection
-
Overview
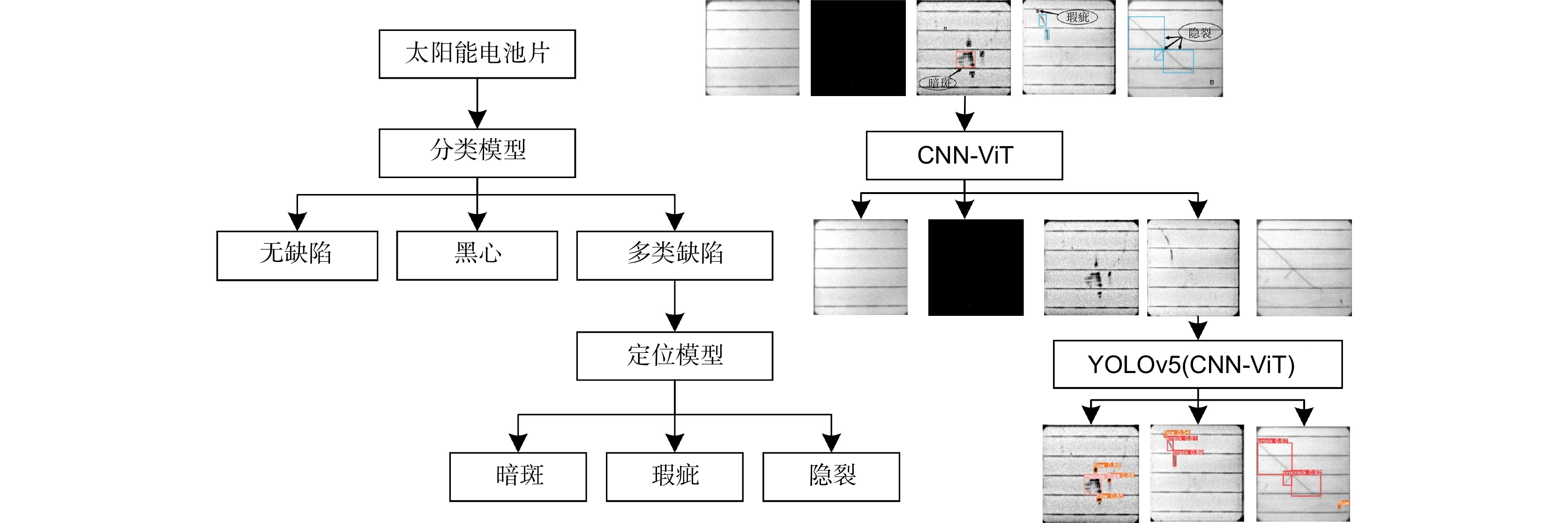
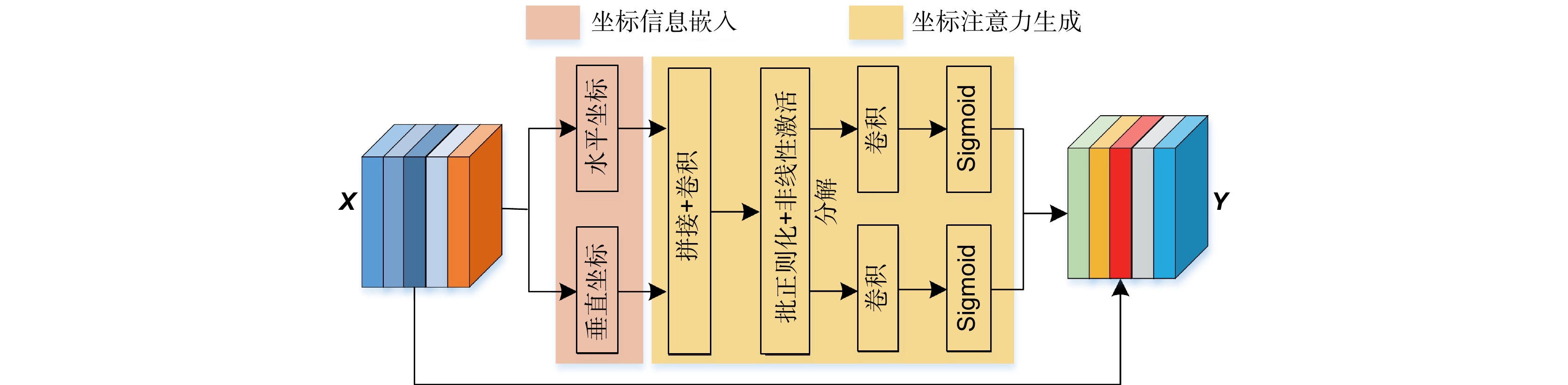
Overview: The methods employed for identifying surface defects on solar cell panels encompass traditional machine learning and deep learning. Traditional machine learning methods have advantages in defect recognition and well-established algorithms for detecting surface defects on solar cell panels. However, these methods encounter challenges, including extensive parameter tuning, issues with model robustness, suboptimal generalization performance, and reliance on engineers' subjective experience for defect discrimination in solar cell defect detection. Moreover, they need help adapting to prolonged manual labor. In contrast, deep learning methods face challenges from the high similarity of defect features on solar cell panels and the complexity of background features. Issues such as insufficient extraction of fine-grained defect features and feature loss during network deepening may arise, resulting in decreased detection accuracy. The surface defects on solar cell panels show significant intra-class and minimal inter-class differences, combined with a complex background. Therefore, achieving high-precision automatic detection of surface defects on solar cell panels becomes challenging. We utilize advanced techniques in deep learning and computer vision to address this issue. We propose a method named Convolutional-Vision Transformer Networks (CViT-Net), specifically designed to efficiently integrate local and global features for accurate defect detection in solar cell panels. The model initially utilizes a Ghost Focus (G-C2F) module to extract local features related to defects in solar cell panels. Subsequently, a coordinate attention mechanism is introduced to emphasize defect features and attenuate background features. Finally, we construct a Ghost Vision (G-ViT) module to integrate local and global features of defects in solar cell panels. To address various demands for detection accuracy and model parameterization, we introduce the CViT-Net-S structure with a parameter count of 5.6 M and the CViT-Net-L structure with a parameter count of 21.9 M, serving diverse practical applications in low-resource and high-resource environments, respectively. Experimental results illustrate the remarkable performance of our model in classifying and detecting defects in solar cell panels. Compared to lightweight models like MobileVit, MobileNetV3, and GhostNet, our CViT-Net-S model achieves accuracy improvements of 1.4%, 2.3%, and 1.3%, respectively, for defect classification in solar cell panels and mAP50 enhancements of 2.7%, 0.3%, and 0.8%, respectively, in defect detection. Compared to RecNet50 and RegNet, the CNN-ViT-L model demonstrates classification accuracy enhancements of 0.72% and 0.7% and mAP50 improvements of 3.9% and 1.3%, respectively. When compared to advanced object detection models like YOLOv6, YOLOv7, and YOLOv8, CViT-Net-S and CViT-Net-L, serving as backbone networks, continue to demonstrate robust detection performance in terms of mAP and mAP50 metrics. These results underscore the algorithm's significant practical value in the surface defect detection field of solar cell panels. In future work, we plan to extend the CViT-Net model for application in defect classification detection for other physical entities to meet diverse defect recognition needs.
-

-
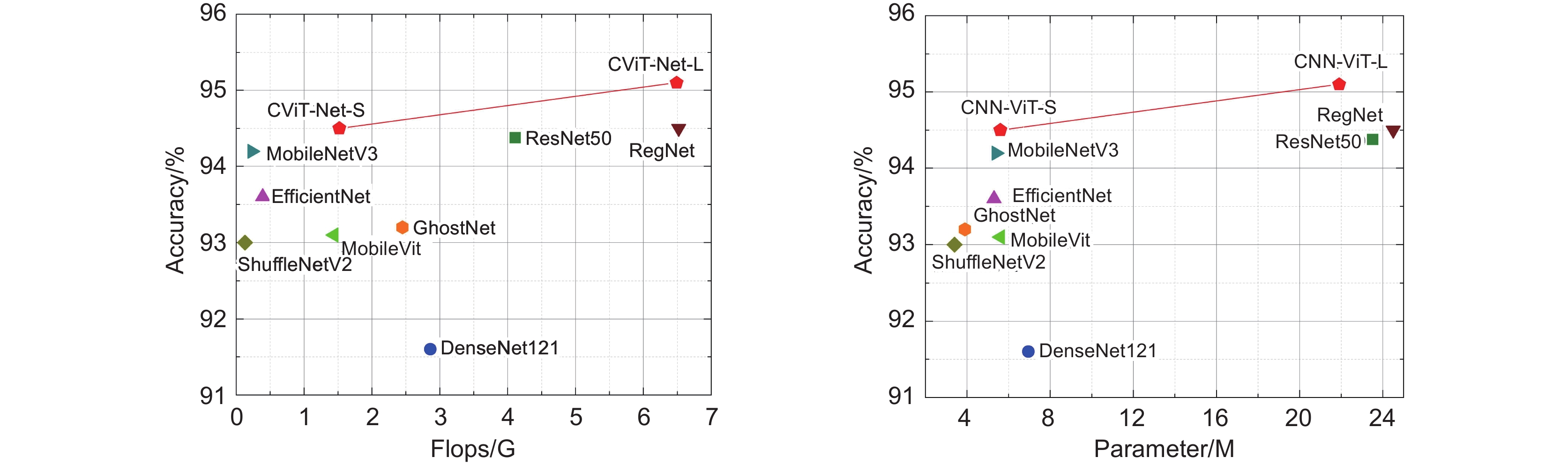
图 7 模型准确率相较计算量和参数量对比图
Figure 7. Comparison chart of model accuracy compared to calculation amount and parameter amount
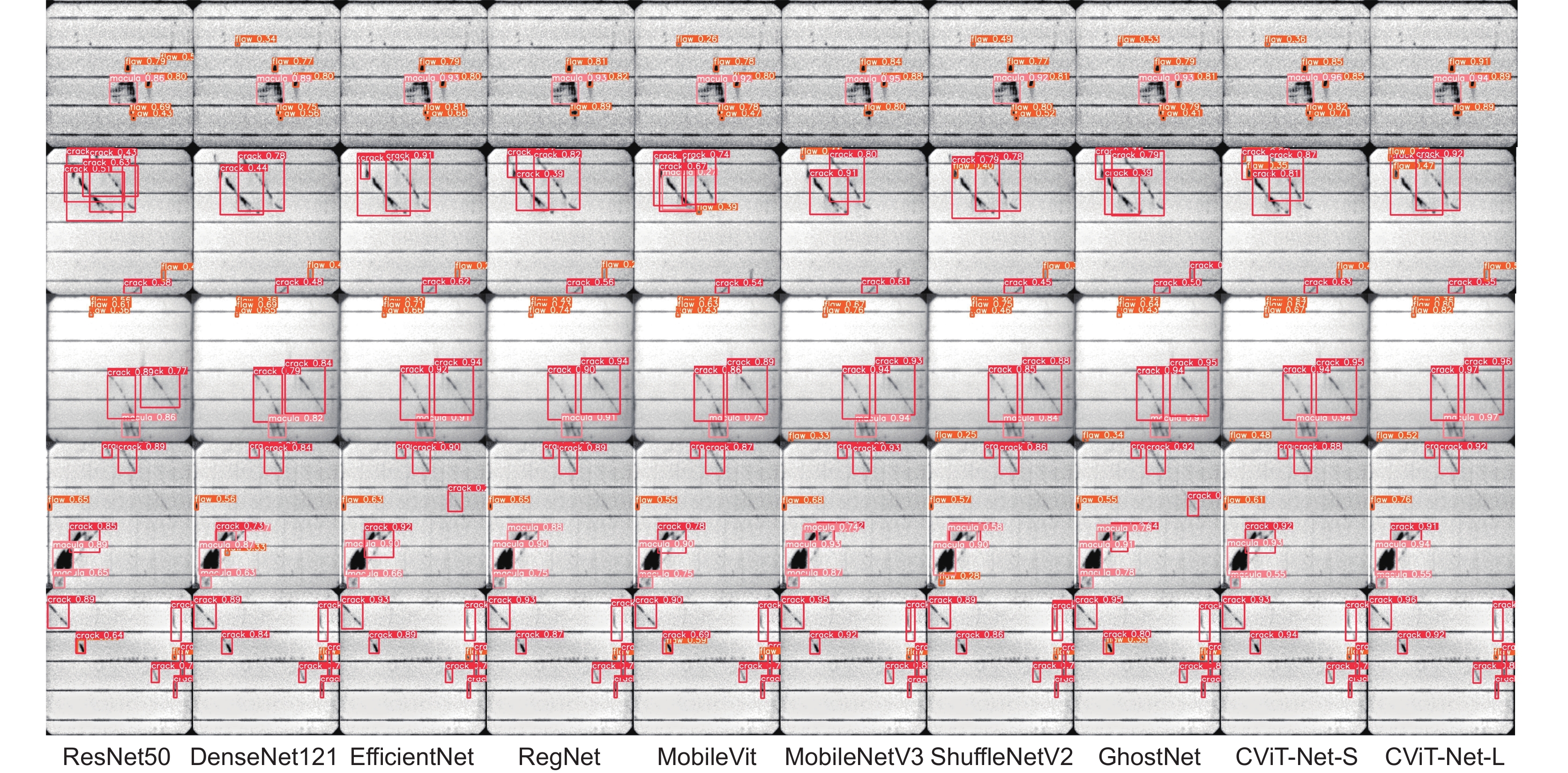
图 8 YOLOv5检测框架下的可视化定位结果
Figure 8. Visual positioning results under YOLOv5 detection framework
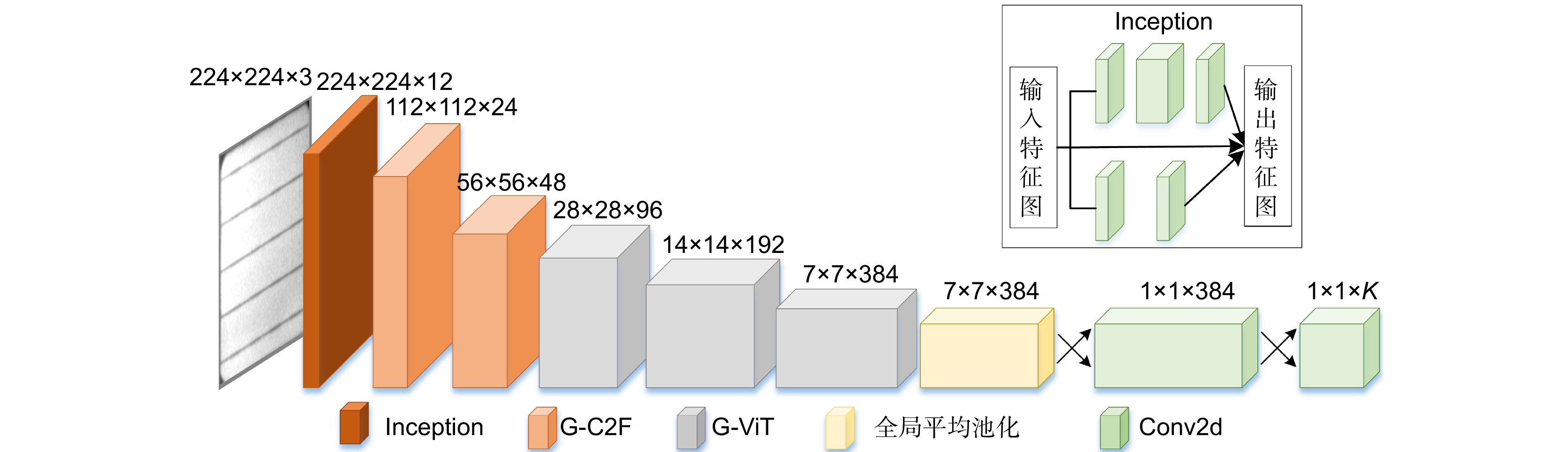
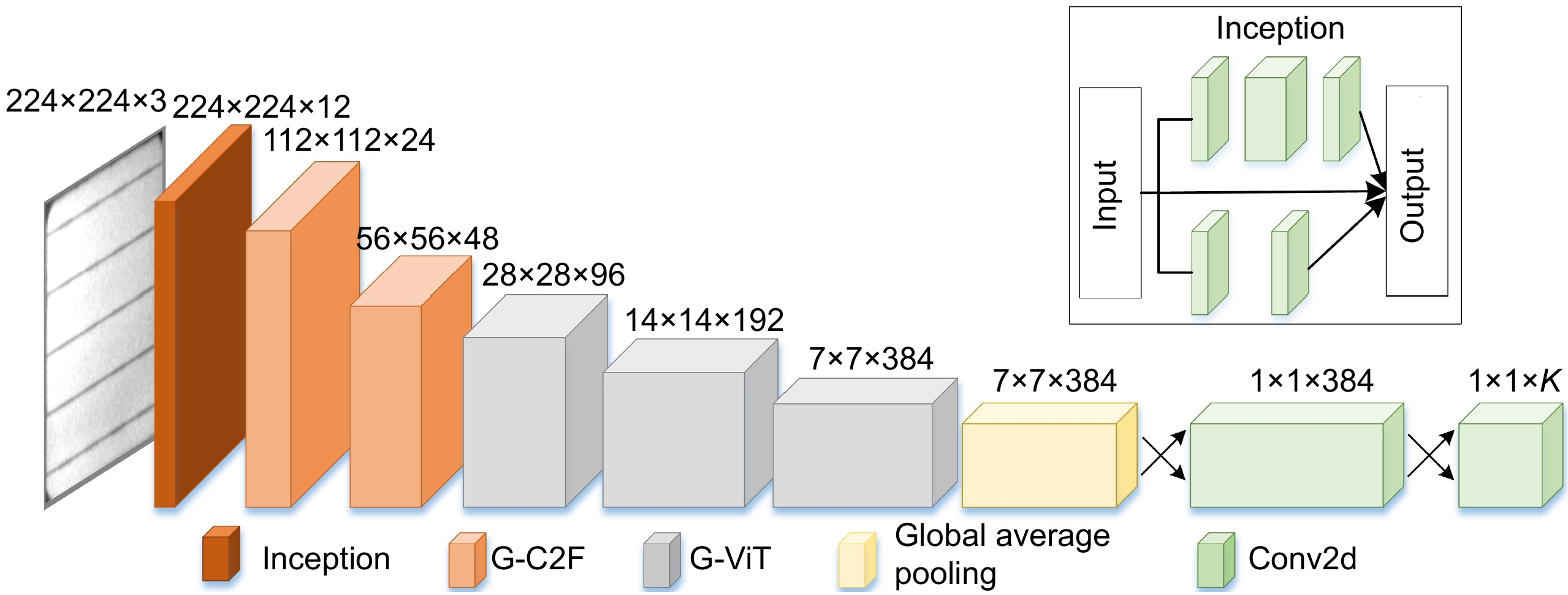
表 1 CViT-Net模型参数表
Table 1. CViT-Net model parameter table
输入分辨率 模块 输出分辨率 CViT-Net-S CViT-Net-L 输出通道数 重复 输出通道数 重复 224 × 224 Inception 224 × 224 12 1 24 1 224 × 224 G-C2F 112 × 112 24 1 48 2 112 × 112 G-C2F 56 × 56 48 2 96 2 56 × 56 G-ViT 28 × 28 96 2 192 2 28 × 28 G-ViT 14 × 14 192 4 384 4 14 × 14 G-ViT 7 × 7 384 2 768 2 7 × 7 池化 1× 1 384 1 768 1 1 × 1 Conv2d 1 × 1 384 1 768 1 1 × 1 Conv2d 1 × 1 K 1 K 1 Parameter 5.6 M 21.9 M FLOPs 1.52 G 6.49 G  下载: 导出CSV
下载: 导出CSV
表 2 分类实验和检测实验不同参数值
Table 2. Classify and detect experimentally different parameter values
名称 分类实验 检测实验 输入图像分辨率 224 × 224 640 × 640 训练轮数 (epoch) 100 300 批量尺寸 (Batch size) 40 8
下载: 导出CSV
表 3 先进卷积神经网络算法对比
Table 3. Comparison of advanced convolutional neural network algorithms
模型 测试分辨率 Precision/% Recall/% Accuracy/% Parameter/M FLOPs/G ResNet50 224×224 93.07 95.06 94.38 23.5 4.11 DenseNet121 224×224 90.03 93.78 91.60 6.9 2.86 EfficientNet-B0 224×224 92.33 94.11 93.60 5.3 0.39 RegNet 224×224 93.25 95.17 94.40 24.5 6.52 MobileVit 224×224 91.48 95.28 93.10 5.6 1.44 MobileNetV3 224×224 92.78 93.78 92.20 5.4 0.23 ShuffleNetV2 224×224 91.42 94.78 93.00 3.4 0.13 GhostNet 224×224 91.56 95.46 93.20 3.9 2.45 CViT-Net-S 224×224 93.00 95.94 94.50 5.6 1.52 CViT-Net-L 224×224 93.70 96.28 95.10 21.9 6.49
下载: 导出CSV
表 4 注意力机制性能比较
Table 4. Attention mechanism performance comparison
模型 Precision/% Recall/% Accuracy/% Parameter/M FLOPs/G CViT-Net 79.86 80.25 86.78 4.59 4.2 CViT-Net+SE 80.74 80.58 87.68 5.60 1.53 CViT-Net+CBAM 87.0 87.6 92.24 5.63 1.54 CViT-Net+EMA 87.9 86.4 93.20 5.64 1.72 CViT-Net+CA 93.00 95.94 94.50 5.64 1.52
下载: 导出CSV
表 5 CViT-Net-S网络消融实验
Table 5. CViT-Net-S network ablation experiment
模型 G-C2F G-ViT CA Parameter/M FLOPs/G Accuracy/% Baseline - - - 14.8 4.2 86.78 CViT-Net-S √ - - 8.9 1.35 92.15 CViT-Net-S √ √ - 12.6 1.51 92.31 CViT-Net-S √ √ √ 5.6 1.52 94.50
下载: 导出CSV
表 6 不同目标检测算法实验对比
Table 6. Experimental comparison of different target detection algorithms
模型 mAP/% mAP50/% 隐裂 暗斑 瑕疵 Two stage: Faster R-CNN( ResNet50) 86.1 85.4 76.8 82.8 Cascade:R-CNN( ResNet50) 89.3 86.8 79.9 85 Sparse R-CNN( ResNet50) 74.5 75.4 64.1 71.3 FoveaBox( ResNet50) 88.3 85.2 61.8 78.5 One stage: RetinaNet( ResNet50) 78.7 84.2 63.3 75.4 VFNet( ResNet50) 53.2 56.2 49.7 53 YOLOv5S 86.2 89.6 86.7 89.4 YOLOv6S 87.4 89.4 86.5 87.8 YOLOv7 80.8 86.7 81.2 82.9 YOLOv8S 86.9 88.1 86.0 87.0 YOLOX-S 88.1 88.8 87.2 88 PPYOLOE-S 87.7 89.9 84.5 87.4 YOLOv5(CViT-Net-S) 89.4 93.5 87.4 90.1 YOLOv5(CViT-Net-L) 89.5 93.6 87.5 90.2
下载: 导出CSV
表 7 YOLOv5检测框架下的骨干网络对比实验
Table 7. YOLOv5 backbone network comparison experiment
检测框架 骨干网络 Precision/% Recall/% mAP/% mAP50/% YOLOv5 ResNet50 83.9 85.1 48.4 86.3 YOLOv5 DenseNet121 83.2 83.9 49.0 88.1 YOLOv5 EfficientNet 87.0 84.9 52.1 89.3 YOLOv5 RegNet 86.3 85.5 52.8 88.9 YOLOv5 MobileVit 82.9 82.0 49.9 87.4 YOLOv5 MobileNetV3 89.5 86.5 58.3 89.8 YOLOv5 ShuffleNetV2 83.7 80.4 48.6 86.8 YOLOv5 GhostNet 85.6 86.3 52.8 89.3 YOLOv5 CViT-Net-S 87.2 87.1 56.2 90.1 YOLOv5 CViT-Net-L 90.1 87.3 61.1 90.2
下载: 导出CSV
-
参考文献
[1] 余星, 严俊森, 吴志鹏, 等. 激光微纳制造太阳能海水淡化材料研究进展[J]. 光电工程, 2022, 49(1): 210313. doi: 10.12086/oee.2022.210313
Yu X, Yan J S, Wu Z P, et al. Research progress of solar desalination materials produced by laser micro-nano fabrication[J]. Opto-Electron Eng, 2022, 49(1): 210313. doi: 10.12086/oee.2022.210313
[2] Herraiz Á H, Marugán A P, Márquez F P G. Photovoltaic plant condition monitoring using thermal images analysis by convolutional neural network-based structure[J]. Renew Energy, 2020, 153: 334−348. doi: 10.1016/j.renene.2020.01.148
[3] 曾德宇, 梁泽逍, 吴宗泽. 基于加权核范数和L2, 1范数的最优均值线性分类器[J]. 电子与信息学报, 2022, 44(5): 1602−1609. doi: 10.11999/JEIT211434
Zeng D Y, Liang Z X, Wu Z Z. Optimal mean linear classifier via weighted nuclear norm and L2, 1 norm[J]. J Electron Inf Technol, 2022, 44(5): 1602−1609. doi: 10.11999/JEIT211434
[4] Juan R O S, Kim J. Photovoltaic cell defect detection model based-on extracted electroluminescence images using SVM classifier[C]//2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 2020: 578–582. https://doi.org/10.1109/ICAIIC48513.2020.9065065.
[5] 王超, 蒋晓瑜, 柳效辉. 基于电致发光成像理论的硅太阳电池缺陷检测[J]. 光电子·激光, 2011, 22(9): 1332–1336.
Wang C, Jiang X Y, Liu X H. Defect detection in crystalline silicon solar cells based on electroluminescence imaging[J]. J Optoelectron·Laser‚ 2011, 22(9): 1332–1336.
[6] Firuzi K, Vakilian M, Phung B T, et al. Partial discharges pattern recognition of transformer defect model by LBP & HOG features[J]. IEEE Trans Power Delivery, 2019, 34(2): 542−550. doi: 10.1109/TPWRD.2018.2872820
[7] Juan R O S, Kim J. Photovoltaic cell defect detection model based-on extracted electroluminescence images using SVM classifier[C]//2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). IEEE, 2020: 578-582. https://doi.org/10.1109/ICAIIC48513.2020.9065065.
[8] 李原, 李燕君, 刘进超, 等. 基于改进Res-UNet网络的钢铁表面缺陷图像分割研究[J]. 电子与信息学报, 2022, 44(5): 1513−1520. doi: 10.11999/JEIT211350
Li Y, Li Y J, Liu J C, et al. Research on segmentation of steel surface defect images based on improved Res-UNet network[J]. J Electron Inf Technol, 2022, 44(5): 1513−1520. doi: 10.11999/JEIT211350
[9] Masita K, Hasan A, Shongwe T. 75MW AC PV module field anomaly detection using drone-based IR orthogonal images with Res-CNN3 detector[J]. IEEE Access, 2022, 10: 83711−83722. doi: 10.1109/ACCESS.2022.3194547
[10] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90.
[11] Du B L, He Y G, He Y Z, et al. Intelligent classification of silicon photovoltaic cell defects based on eddy current thermography and convolution neural network[J]. IEEE Trans Industr Inform, 2020, 16(10): 6242−6251. doi: 10.1109/TII.2019.2952261
[12] Chen H Y, Pang Y, Hu Q D, et al. Solar cell surface defect inspection based on multispectral convolutional neural network[J]. J Intell Manuf, 2020, 31(2): 453−468. doi: 10.1007/s10845-018-1458-z
[13] Su B Y, Chen H Y, Zhou Z. BAF-detector: an efficient CNN-based detector for photovoltaic cell defect detection[J]. IEEE Trans Ind Electron, 2022, 69(3): 3161−3171. doi: 10.1109/TIE.2021.3070507
[14] 陈海永, 赵鹏, 闫皓炜. 融合注意力的多尺度Faster RCNN的裂纹检测[J]. 光电工程, 2021, 48(1): 200112. doi: 10.12086/oee.2021.200112
Chen H Y, Zhao P, Yan H W. Crack detection based on multi-scale Faster RCNN with attention[J]. Opto-Electron Eng, 2021, 48(1): 200112. doi: 10.12086/oee.2021.200112
[15] Zhang M, Yin L J. Solar cell surface defect detection based on improved YOLO v5[J]. IEEE Access, 2022, 10: 80804−80815. doi: 10.1109/ACCESS.2022.3195901
[16] 陈旭, 彭冬亮, 谷雨. 基于改进YOLOv5s的无人机图像实时目标检测[J]. 光电工程, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
Chen X, Peng D L, Gu Y. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electron Eng, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372
[17] Howard A, Sandler M, Chen B, et al. Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 1314–1324. https://doi.org/10.1109/ICCV.2019.00140.
[18] Zhang X Y, Zhou X Y, Lin M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6848–6856. https://doi.org/10.1109/CVPR.2018.00716.
[19] Koonce B. EfficientNet[M]//Koonce B. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization. Berkeley: Apress, 2021: 109–123. https://doi.org/10.1007/978-1-4842-6168-2_10.
[20] Han K, Wang Y H, Tian Q, et al. GhostNet: more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 1577–1586. https://doi.org/10.1109/CVPR42600.2020.00165.
[21] Radosavovic I, Kosaraju R P, Girshick R, et al. Designing network design spaces[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 10425–10433. https://doi.org/10.1109/CVPR42600.2020.01044.
[22] Han K, Xiao A, Wu E H, et al. Transformer in transformer[C]//35th Conference on Neural Information Processing Systems, 2021: 15908–15919.
[23] Wu H P, Xiao B, Codella N, et al. CvT: introducing convolutions to vision transformers[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 22–31. https://doi.org/10.1109/ICCV48922.2021.00009.
[24] d’Ascoli S, Touvron H, Leavitt M L, et al. ConViT: improving vision transformers with soft convolutional inductive biases[J]. J Stat Mech Theory Exp, 2022, 2022(11): 114005. doi: 10.1088/1742-5468/ac9830
[25] Mehta S, Rastegari M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer[C]//Tenth International Conference on Learning Representations, 2022.
[26] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, 2023: 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721.
[27] Pawar N, Waghmare A, Pratap A, et al. Miniscule object detection in aerial images using YOLOR: a review[M]//Kumar S, Hiranwal S, Purohit S D, et al. Proceedings of International Conference on Communication and Computational Technologies: ICCCT 2022. Singapore: Springer, 2023: 697–708. https://doi.org/10.1007/978-981-19-3951-8_52.
[28] Norkobil Saydirasulovich S, Abdusalomov A, Jamil M K, et al. A YOLOv6-based improved fire detection approach for smart city environments[J]. Sensors, 2023, 23(6): 3161. doi: 10.3390/s23063161
[29] Talaat F M, Zaineldin H. An improved fire detection approach based on YOLO-v8 for smart cities[J]. Neural Comput Appl, 2023, 35(28): 20939−20954. doi: 10.1007/s00521-023-08809-1
[30] Zhang Y C, Zhang W B, Yu J Y, et al. Complete and accurate holly fruits counting using YOLOX object detection[J]. Comput Electron Agric, 2022, 198: 107062. doi: 10.1016/j.compag.2022.107062
[31] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 2261–2269. https://doi.org/10.1109/CVPR.2017.243.
[32] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 936–944. https://doi.org/10.1109/CVPR.2017.106.
[33] Liu S, Qi L, Qin H F, et al. Path aggregation network for instance segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8759–8768. https://doi.org/10.1109/CVPR.2018.00913.
[34] Hou Q B, Zhou D Q, Feng J S. Coordinate attention for efficient mobile network design[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 13708–13717. https://doi.org/10.1109/CVPR46437.2021.01350.
[35] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
[36] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, 2018: 3–19. https://doi.org/10.1007/978-3-030-01234-2_1.
[37] Ouyang D L, He S, Zhang G Z, et al. Efficient multi-scale attention module with cross-spatial learning[C]//ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, 2023: 1–5. https://doi.org/10.1109/ICASSP49357.2023.10096516.
[38] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 2818–2826. https://doi.org/10.1109/CVPR.2016.308.
[39] Wu C C, Hung Y C. A study on electroluminescent phenomenon for solar cells test[C]//2018 1st IEEE International Conference on Knowledge Innovation and Invention (ICKII), Jeju, Korea (South), 2018: 172–175. https://doi.org/10.1109/ICKII.2018.8569147.
-
访问统计

 点击扫一扫
点击扫一扫
图(9)
表(7)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


