
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
针对无人机图像背景复杂、分辨率高、目标尺度差异大等特点,提出了一种实时目标检测算法YOLOv5sm+。首先,分析了网络宽度和深度对无人机图像检测性能的影响,通过引入可增大感受野的残差空洞卷积模块来提高空间特征的利用率,基于YOLOv5s设计了一种改进的浅层网络YOLOv5sm,以提高无人机图像的检测精度。然后,设计了一种特征融合模块SCAM,通过局部特征自监督的方式提高细节信息利用率,通过多尺度特征有效融合提高了中大目标的分类精度。最后,设计了目标位置回归与分类解耦的检测头结构,进一步提高了分类精度。采用VisDrone无人机航拍数据集实验结果表明,提出的YOLOv5sm+模型对验证集测试时交并比为0.5时的平均精度均值(mAP50)达到了60.6%,相比于YOLOv5s模型mAP50提高了4.8%,超过YOLOv5m模型的精度,同时推理速度也有提升。通过在DIOR遥感数据集上的迁移实验也验证了改进模型的有效性。提出的改进模型具有虚警率低、重叠目标识别率高的特点,适合于无人机图像的目标检测任务。
Abstract
As unmanned aerial vehicle (UAV) image has the characteristics of complex background, high resolution, and large scale differences between targets, a real-time detection algorithm named as YOLOv5sm+ is proposed in this paper. First, the influence of network width and depth on UAV image detection performance was analyzed, and an improved shallow network based on YOLOv5s, which is named as YOLOv5sm, was proposed to improve the detection accuracy of major targets in UAV image through improving the utilization of spatial features extracted by residual dilated convolution module that could increase the receptive field. Then, a feature fusion module SCAM was designed, which could improve the utilization of detailed information by local feature self-supervision and could improve classification accuracy of medium and large targets through effective feature fusion. Finally, a detection head structure consisting with decoupled regression and classification head was proposed to further improve the classification accuracy. The experimental results on VisDrone dataset show that when intersection over union equals 0.5 mean average precision (mAP50) of the proposed YOLOv5sm+ model reaches 60.6%. Compared with YOLOv5s model, mAP50 of YOLOv5sm+ has increased 4.1%. In addition, YOLOv5sm+ has higher detection speed. The migration experiment on the DIOR remote sensing dataset also verified the effectiveness of the proposed model. The improved model has the characteristics of low false alarm rate and high recognition rate under overlapping conditions, and is suitable for the object detection task of UAV images.
-
Key words:
- UAV image /
- real-time object detection /
- YOLOv5sm+
-
Overview
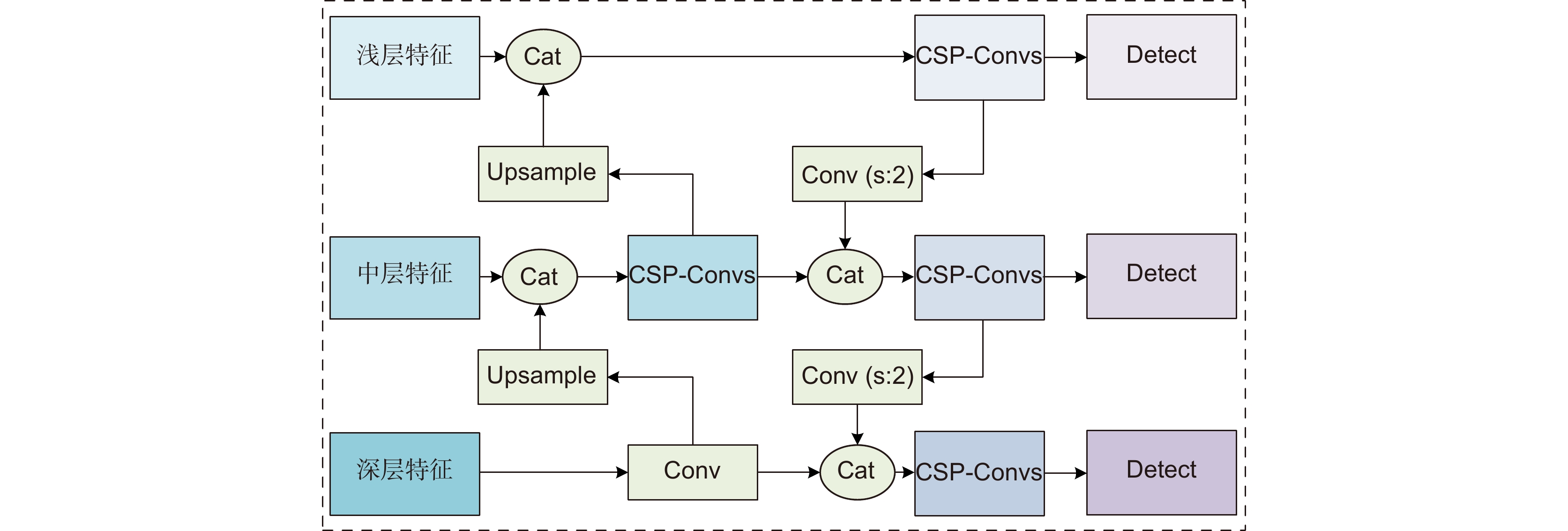
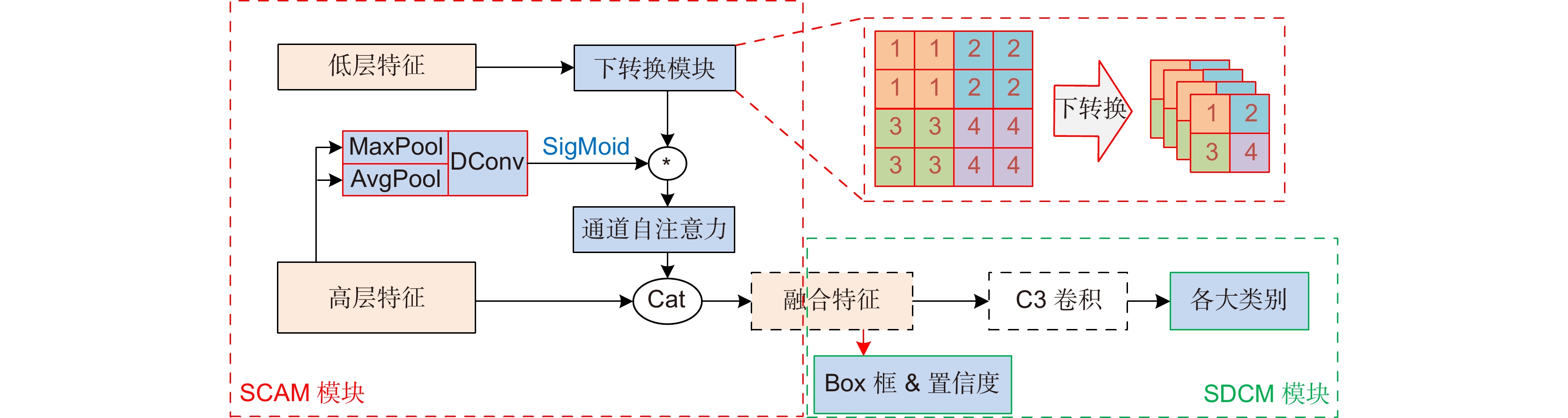
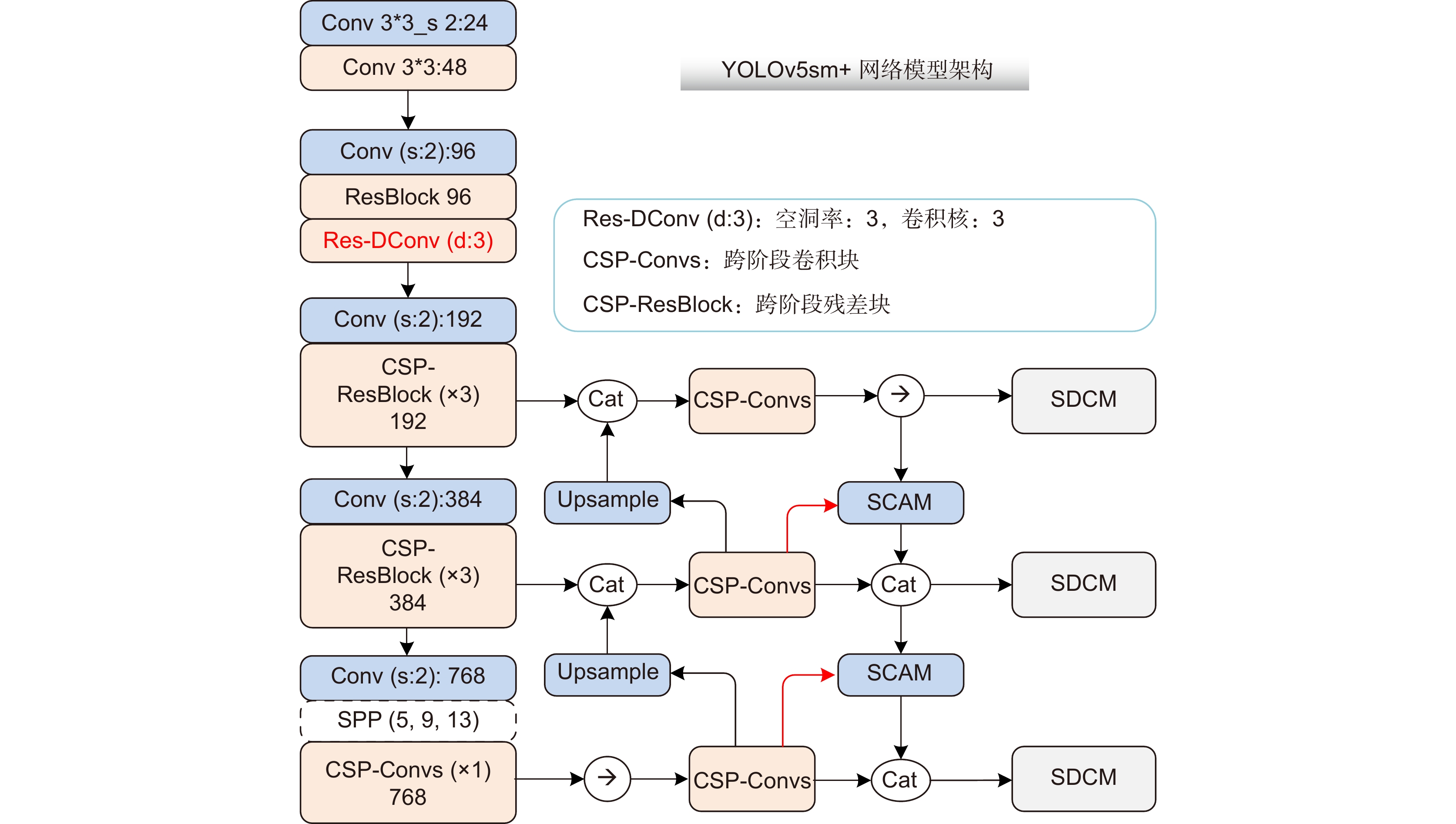
Overview: The real-time object detection under unmanned aerial vehicle (UAV) scenario has a wide range of military and civilian applications, including traffic monitoring, power line detection, etc. As UAV image has the characteristics of complex background, high resolution, and large scale differences between targets, how to meet the requirements of both detection accuracy and real-time performance is one of key problems to be solved. Thus, a balanced real-time detection algorithm based on YOLOv5s, which is named as YOLOv5sm+ is proposed in this paper. First, the influence of network width and depth on UAV image detection performance was analyzed. The experimental results on VisDrone datasets show that, due to the less internal feature mapping, the detection performance improves with model depth rather than model width. Moreover, with the depth of the model grows, semantic information can improve detection accuracy under generic object detection scenarios. An improved shallow network based on YOLOv5s, which is named as YOLOv5sm, was proposed to improve the detection accuracy of major targets in UAV image through improving the utilization of spatial features extracted by residual dilated convolution module that could increase the receptive field. Then, a cross-stage attention feature fusion module (SCAM) was designed, which could improve the utilization of detailed information by local feature self-supervision and could improve classification accuracy of medium and large targets through effective feature fusion. Finally, a detection head structure consisting with decoupled regression and classification head was proposed to further improve the classification accuracy. The first stage completes the regression task, and the second stage uses the cross-stage convolution module to assist in the classification task. The contradiction between regression and classification was alleviated, and the accuracy of the fine-grained classification was improved. Under the synergistic of the balanced light-weight feature extraction network (YOLOv5sm), the cross-stage attention feature fusion module (SCAM) and the improved detection head, the algorithm named YOLOv5sm+ was proposed. The experimental results on VisDrone dataset show that when intersection over union equals 0.5 mean average precision (mAP50) of the proposed YOLOv5sm+ model reaches 60.6%. Compared with YOLOv5s model, mAP50 of YOLOv5sm+ has increased 4.1%. In addition, YOLOv5sm+ has higher detection speed. The migration experiment on the DIOR remote sensing dataset also verified the effectiveness of the proposed model. The improved model has the characteristics of low false alarm rate and high recognition rate under overlapping conditions, and is suitable for the object detection task of UAV images.
-

-

图 3 (a) Res-DConv模块;(b) 感受野映射
Figure 3. (a) Res-DConv module; (b) Receptive field mapping
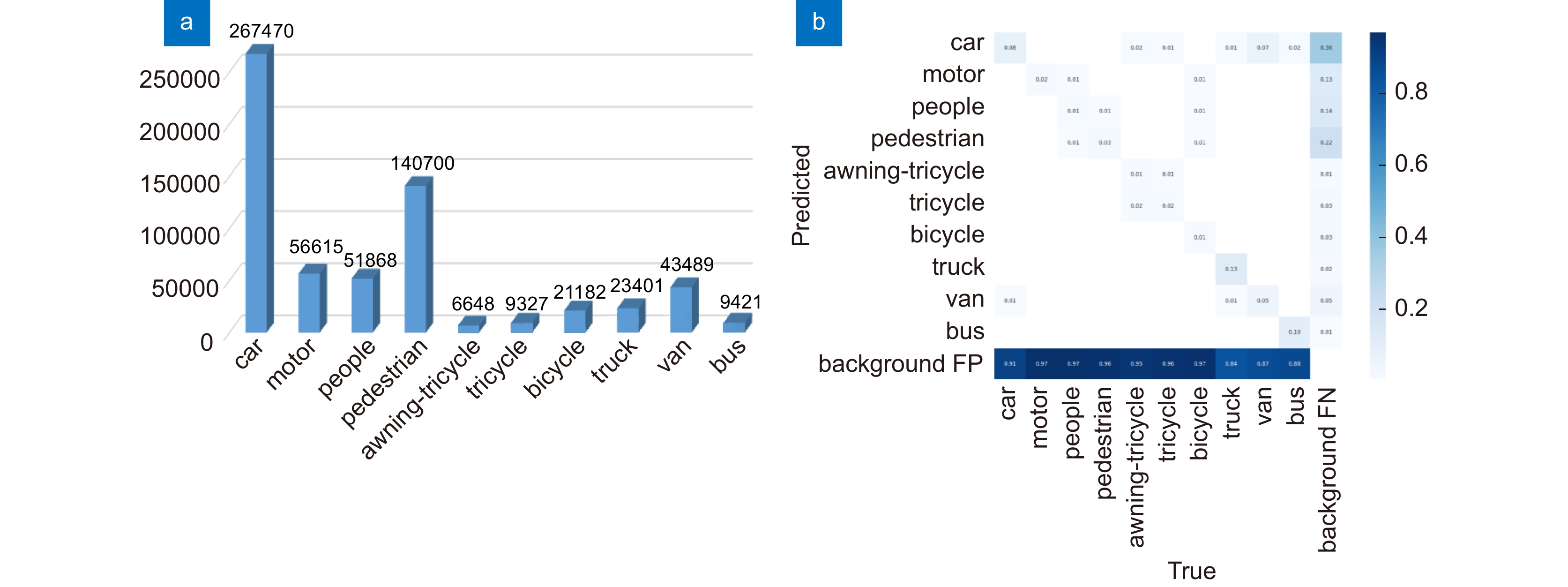
图 6 (a) VisDrone数据集类别实例总计;(b) YOLOv5m算法下的类混淆矩阵
Figure 6. (a) Total number of category instances on the VisDrone dataset; (b) Classes confusion matrix of YOLOv5m algorithm

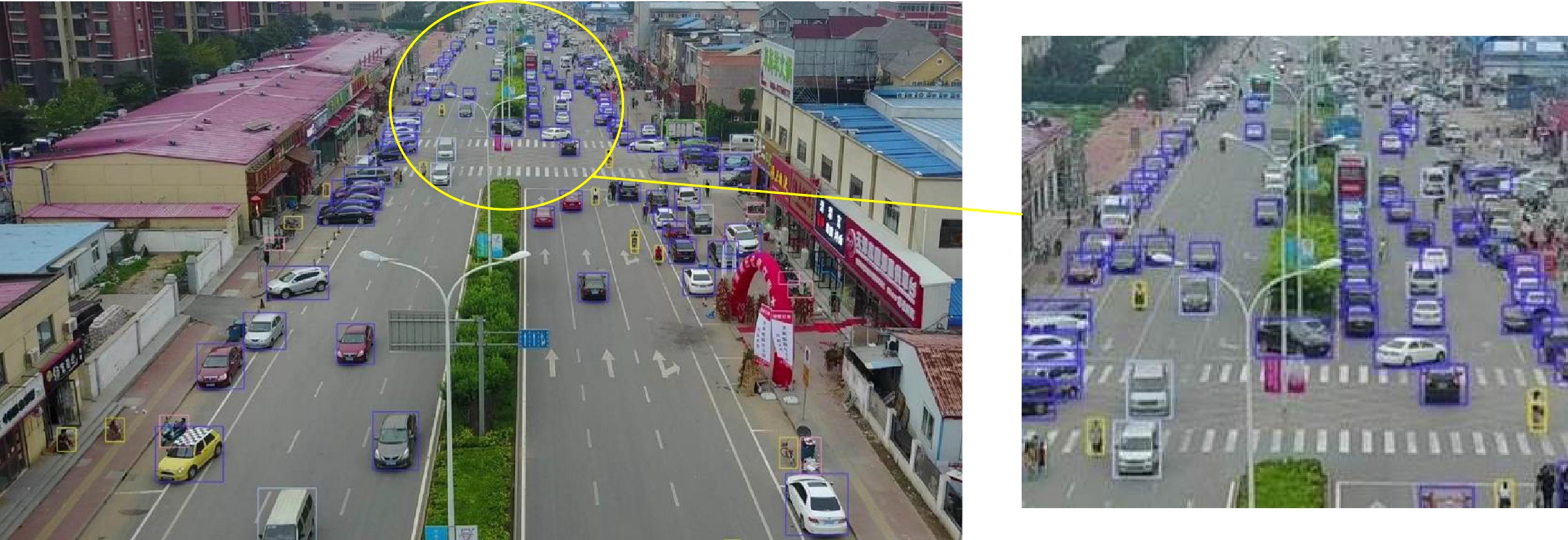
图 7 不同算法在VisDrone无人机场景下的检测实例。
Figure 7. The detection examples of different algorithms in the VisDrone UAV scene.

图 8 三种算法在密集车辆场景的检测结果对比图。
Figure 8. Comparison of the detection effects of three algorithms in dense vehicle scenes.

图 9 改进算法在DIOR数据集的检测对比。
Figure 9. Detection comparison of improved algorithm in DIOR dataset.
表 1 感受野分析表
Table 1. Receptive field analysis table
YOLOv5s 感受野 通道 YOLOv5sm 感受野 通道 Focus 6 32 Conv 3*3 (stride:2) 3 24 Conv3*3 (dilation:2) 15 48 下采样 10 64 Conv3*3 (stride:2) 19 96 Res-Block 27 96 C3_x1 18 64 Res-Dconv 51 96 下采样 26 128 Conv 3*3 (stride:2) 59 192 C3_x3 74 128 C3_x3 107 192 下采样 90 256 Conv3*3 (stride:2) 123 384 C3_x3 186 256 C3_x3 219 384 下采样 218 512 Conv3*3 (stride:2) 251 768 Spp 218~634 512 Spp 251~667 768 C3_x1 282~698 512 C3_x1 315~731 768  下载: 导出CSV
下载: 导出CSV
表 2 呼应感受野、下采样的锚点预设置
Table 2. Pre-setting anchors in response to the receptive field and down-sampling
下采样因子 3 4 5 最大感受野/pixel 111 255 731 先验框范围 8*8~37*37 32*32~85*85 96*96~365*365
下载: 导出CSV
表 3 不同类型目标数量统计
Table 3. Statistics of different types of objects
目标种类 Small (0×0~32×32) Mid (32×32~96×96) Large (96×96~) 数量 44.44 18.63 1.704
下载: 导出CSV
表 4 深度、宽度模型性能对比实验结果
Table 4. Performance comparison experiment results of depth and width models
深度 宽度 mAP50 mAP BFLOPs 0.33 0.5 0.502 0.288 16.5 0.33 0.75 0.540 0.319 36.3 1.33 0.5 0.525 0.311 35.4
下载: 导出CSV
表 5 Res-Dconv模块验证实验结果
Table 5. Verification experiment results on Res-Dconv module
Baseline Res-Dconv mAP50 mAP BFLOPs √ 0.502 0.288 16.5 √ √ 0.516 0.299 19.8
下载: 导出CSV
表 6 本文算法模块在VisDrone数据集上的消融实验结果
Table 6. The ablation experiment results of our algorithm modules on the VisDrone dataset
Baseline SM SCAM SDCM mAP mAP50 BFLOPs Infer AP-small AP-medium AP-large YOLOv5s 0.319 0.548 16.5 4.8 0.220 0.437 0.495 √ 0.358 0.589 30.1 8.3 0.280 0.476 0.495 √ √ 0.324 0.555 14.7 3.8 0.225 0.446 0.511 √ √ 0.333 0.555 19.5 4.9 0.250 0.448 0.482 √ √ 0.356 0.593 38.0 9.0 0.278 0.475 0.512 √ √ √ 0.360 0.596 30.8 7.7 0.281 0.479 0.505 注:加粗字体为该列最优值。
下载: 导出CSV
表 7 不同算法在VisDrone数据集上的检测性能
Table 7. Detection performance of different algorithms on VisDrone dataset
算法 mAP50 mAP mAP75 AP-small AP-mid AP-large BFLOPs Infer/ms YOLOv3 0.609 0.389 0.417 0.297 0.496 0.545 154.9 27.8 Scaled-YOLOv4 0.620 0.400 0.428 0.305 0.514 0.626 119.4 27.1 ClusDet[1] 0.562 0.324 0.316 - - - - - HRDNet[1] 0.620 0.3551 0.351 - - - - - YOLOv5s 0.548 0.319 0.317 0.220 0.437 0.495 16.5 4.8 YOLOv5m 0.595 0.365 0.372 0.285 0.482 0.525 50.4 9.8 YOLOX-s 0.535 0.314 0.317 0.225 0.415 0.485 41.65 5.1 MobileNetv3 0.554 0.329 0.329 0.245 0.443 0.495 23.8 8.0 MobileViT 0.555 0.333 0.337 0.249 0.442 0.418 - 13.7 YOLOv5sm+ 0.596 0.360 0.369 0.281 0.479 0.505 30.8 7.7 YOLOv5sm+* 0.606 0.367 0.378 0.295 0.478 0.439 - - 注:+为添加改进模块的模型, *为多尺度测试结果,包含引用文献实验结果。
下载: 导出CSV
-
参考文献
[1] Wu X, Li W, Hong D F, et al. Deep learning for UAV-based object detection and tracking: a survey[EB/OL]. arXiv: 2110.12638. https://arxiv.org/abs/2110.12638.
[2] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580–587. doi: 10.1109/CVPR.2014.81.
[3] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779–788. doi: 10.1109/CVPR.2016.91.
[4] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 21–37. doi: 10.1007/978-3-319-46448-0_2.
[5] Du D W, Zhu P F, Wen L Y, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshop, 2019: 213–226. doi: 10.1109/ICCVW.2019.00030.
[6] Du D W, Qi Y K, Yu H Y, et al. The unmanned aerial vehicle benchmark: object detection and tracking[C]//Proceedings of the15th European Conference on Computer Vision, 2018: 375–391. doi: 10.1007/978-3-030-01249-6_23.
[7] Cai Z W, Vasconcelos N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 6154–6162.
[8] Yang F, Fan H, Chu P, et al. Clustered object detection in aerial images[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 8310–8319. doi: 10.1109/ICCV.2019.00840.
[9] Singh B, Najibi M, Davis L S. SNIPER: efficient multi-scale training[C]//Proceedings of Annual Conference on Neural Information Processing Systems 2018, 2018: 9333–9343.
[10] Wei Z W, Duan C Z, Song X H, et al. AMRNet: chips augmentation in aerial images object detection[EB/OL]. arXiv: 2009.07168. https://arxiv.org/abs/2009.07168.
[11] Duan K W, Bai S, Xie L X, et al. CenterNet: Keypoint triplets for object detection[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 6568–6577. doi: 10.1109/ICCV.2019.00667.
[12] Howard A G, Zhu M L, Chen B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. arXiv: 1704.04861. https://arxiv.org/abs/1704.04861.
[13] Wang R J, Li X, Ao S, et al. Pelee: a real-time object detection system on mobile devices[C]//Proceedings of the 6th International Conference on Learning Representations, 2018.
[14] Tan M X, Pang R M, Le Q V. EfficientDet: scalable and efficient object detection[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10778–10787.
[15] Han K, Wang Y H, Tian Q, et al. Ghostnet: more features from cheap operations[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1580–1589. doi: 10.1109/CVPR42600.2020.00165.
[16] Li K, Wan G, Cheng G, et al. Object detection in optical remote sensing images: a survey and a new benchmark[J]. ISPRS J Photogr Remote Sens, 2020, 159: 296−307. doi: 10.1016/j.isprsjprs.2019.11.023
[17] Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 1571–1580. doi: 10.1109/CVPRW50498.2020.00203.
[18] He K M, Zhang X Y, Ren S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans Pattern Anal Mach Intell, 2015, 37(9): 1904−1916. doi: 10.1109/TPAMI.2015.2389824.
[19] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936–944.
[20] Liu S, Qi L, Qin H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8759–8768. doi: 10.1109/CVPR.2018.00913.
[21] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. arXiv: 2004.10934. https://arxiv.org/abs/2004.10934.
[22] Zhang N, Donahue J, Girshick R, et al. Part-based R-CNNs for fine-grained category detection[C]//Proceedings of the 13th European Conference on Computer Vision, 2014: 834–849. doi: 10.1007/978-3-319-10590-1_54.
[23] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 3–19. doi: 10.1007/978-3-030-01234-2_1.
[24] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 2999–3007. doi: 10.1109/ICCV.2017.324.
[25] Wu Y, Chen Y P, Yuan L, et al. Rethinking classification and localization for object detection[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10183–10192. doi: 10.1109/CVPR42600.2020.01020.
[26] Chen X L, Fang H, Lin T Y, et al. Microsoft coco captions: data collection and evaluation server[EB/OL]. arXiv: 1504.00325. https://arxiv.org/abs/1504.00325.
[27] Wang C Y, Bochkovskiy A, Liao H Y M. Scaled-YOLOv4: scaling cross stage partial network[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13024–13033. doi: 10.1109/CVPR46437.2021.01283.
[28] Farhadi A, Redmon J. Yolov3: an incremental improvement[C]//Proceedings of Computer Vision and Pattern Recognition, 2018: 1804–2767.
[29] Howard A, Sandler M, Chen B, et al. Searching for MobileNetV3[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 1314–1324. doi: 10.1109/ICCV.2019.00140.
[30] Mehta S, Rastegari M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer[EB/OL]. arXiv: 2110.02178. https://arxiv.org/abs/2110.02178.
[31] Ge Z, Liu S T, Wang F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. arXiv: 2107.08430. https://arxiv.org/abs/2107.08430.
[32] 姚艳清, 程塨, 谢星星, 等. 多分辨率特征融合的光学遥感图像目标检测[J]. 遥感学报, 2021, 25(5): 1124−1137. doi: 10.11834/jrs.20210505.
Yao Y Q, Cheng G, Xie X X, et al. Optical remote sensing image object detection based on multi-resolution feature fusion[J]. J Remote Sens, 2021, 25(5): 1124−1137. doi: 10.11834/jrs.20210505.
[33] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031
[34] Liu Y, Li H F, Hu C, et al. CATNet: context AggregaTion network for instance segmentation in remote sensing images[EB/OL]. arXiv: 2111.11057. https://arxiv.org/abs/2111.11057.
-
访问统计
 点击扫一扫
点击扫一扫

图(10)
表(8)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


