
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
在车辆识别和车辆年检时,正确识别车架上金属刻印的车辆识别代号(VIN)是非常重要的环节。针对VIN序列,本文提出了一种基于神经网络的旋转VIN图片识别方法,它由VIN检测和VIN识别两部分组成。首先,在EAST算法基础上利用轻量级神经网络提取特征,并结合文本分割实现快速、准确的VIN检测;其次,将VIN识别任务作为一个序列分类问题,提出了一种新的识别VIN方法,即通过位置相关的序列分类器,预测出最终的车辆识别代号。为了验证本文的识别方法,引入了一个VIN数据集,其中包含用于检测的原始旋转VIN图像和用于识别的水平VIN图像。实验结果表明,本文方法能有效地识别车架VIN图片,同时达到了实时性。
 Abstract:
Abstract:It is far essential to properly recognize the vehicle identification number (VIN) engraved on the car frame for vehicle surveillance and identification. In this paper, we propose an algorithm for recognizing rotational VIN images based on neural network which incorporates two components: VIN detection and VIN recognition. Firstly, with lightweight neural network and text segmentation based on EAST, we attain efficient and excellent VIN detection performance. Secondly, the VIN recognition is regarded as a sequence classification problem. By means of connecting sequential classifiers, we predict VIN characters directly and precisely. For validating our algorithm, we collect a VIN dataset, which contains raw rotational VIN images and horizontal VIN images. Experimental results show that the algorithm we proposed achieves good performance on VIN detection and VIN recognition in real time.
-
Key words:
- vehicle identification number /
- neural network /
- text segmentation /
- machine vision
-

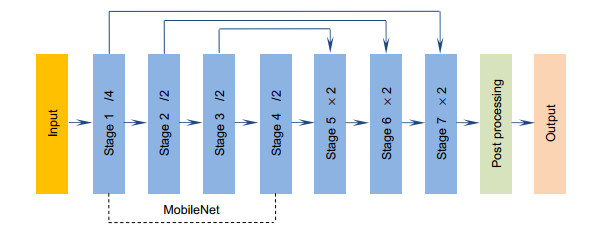
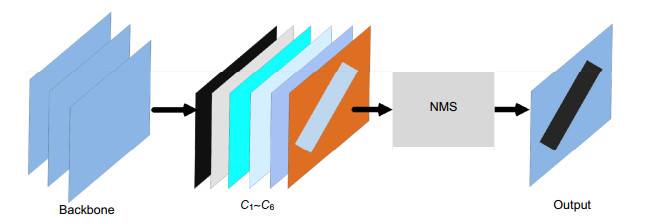
Overview: It is far essential to properly recognize the vehicle identification number (VIN) engraved on the car frame for car surveillance and vehicle identification. Vehicle identification number is unique globally, which is assigned by car manufacturers to a car for identifying it. The vehicle identification number is usually engraved on the metallic car frame which is uneasy to tamper with, so it is of great significance for vehicle annual surveillance and vehicle identification. Although many important achievements have been made in text recognition, especially the wide application of OCR in document recognition in images, the complex background, arbitrary angle and fuzzy font of the engraved text in the images have made it difficult to identify the vehicle identification number automatically. In vehicle identification and annual car inspection, a large number of VIN pictures need to be manually reviewed every day, which is very inefficient. With the application of deep learning, we can make use of deep learning to accelerate this process, improve the efficiency of auditing greatly, and realize automated auditing. We introduce an algorithm for recognizing vehicle identification number in images based on neural network, which incorporates two components: VIN detection and VIN recognition. Firstly, in the VIN detection part, the lightweight Network is used as feature extraction network in order to accelerate the inference speed and reduce the network cost. Combined with FCN and FPN, the network is able to adapt to any size of input images and focus on the distribution difference between foreground text pixels and background pixels. In order to improve the performance on rotational VIN, the images are rotated at any angle lossless in the training stage to augment datasets. Secondly, in the VIN recognition stage, we take VIN recognition task as a sequence classification problem, using VGGNet as the feature extraction network, and the final vehicle identification number sequence is predicted through the position-related sequential classifier without character segmentation to simplify the recognition processing. Also, the text direction in images may be reversed in dataset, and in order to solve the situation, picture is rotated at 180 degrees randomly in network training. Finally, we introduce a VIN dataset, which contains raw rotational VIN images and horizontal VIN images for validating our algorithm, and all of our experiments are conducted on the dataset. Experimental results show that the algorithm we proposed can detect and recognize the VIN text in images efficiently in real time.
-

-

图 1 复杂背景以及任意角度方向的车辆识别代号图片
Figure 1. Samples of vehicle VIN images in complex background and with arbitrary orientation
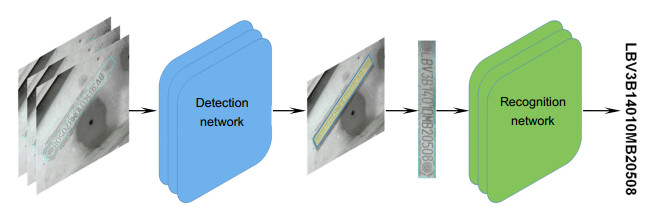
图 2 基于神经网络的VIN识别框架
Figure 2. The overall architecture of our proposed VIN recognition algorithm
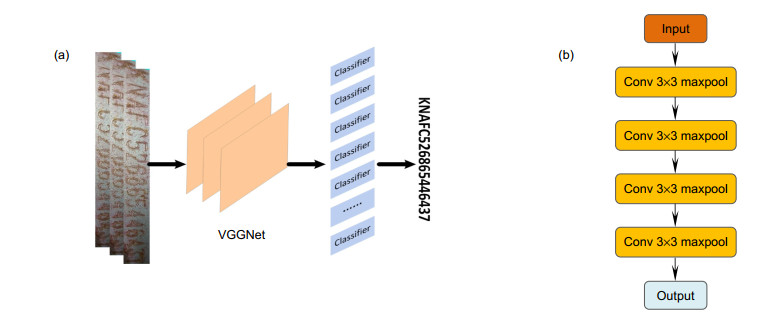
图 5 VIN识别算法网络。(a) 网络整体框架;(b) VGGNet内部结构
Figure 5. Illustration of VIN recognition network. (a) Overall framework; (b) VGGNet network

图 6 任意方向旋转图片和文本框标签
Figure 6. Rotating VIN images and labels at any angle to augment dataset

图 8 实际复杂环境下VIN图片识别效果
Figure 8. Samples of detection and recognition results of our algorithm on complicated VIN images

图 9 实际复杂环境下检测和识别效果不好的图片
Figure 9. Samples of failed detection and recognition on complicated VIN images
表 1 在VIN数据集上不同方法的检测效果
Table 1. Detection performance comparison of different algorithms on VIN dataset
 下载: 导出CSV
下载: 导出CSV
表 2 在VIN数据集上不同方法的识别效果
Table 2. Recognition performance comparison of two algorithms on VIN dataset
下载: 导出CSV
表 3 在不同尺寸输入图片大小上的识别效果
Table 3. Recognition performance comparison of different input size
Input size FPS(frame/s) F/% A/% 200×20+aug 134 47.53 89.66 200×20 134 41.21 85.73 320×32+aug 122 61.47 93.28 320×32 122 55.15 91.90 400×40+aug 94 66.29 95.12 400×40 94 58.70 91.42 500×50+aug 88 64.73 95.71 500×50 88 58.11 92.37
下载: 导出CSV
-
[1] Smith R. An overview of the Tesseract OCR engine[C]// Proceedings of the 9th International Conference on Document Analysis and Recognition (ICDAR 2007), 2007: 629–633.
[2] Mori S, Suen C Y, Yamamoto K. Historical review of OCR research and development[J]. Proc IEEE, 1992, 80(7): 1029–1058. doi: 10.1109/5.156468
[3] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[Z]. arXiv: 1409.1556, 2014.
[4] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 770–778.
[5] 唐有宝, 卜巍, 邬向前. 多层次MSER自然场景文本检测[J]. 浙江大学学报(工学版), 2016, 50(6): 1134–1140. http://www.cnki.com.cn/article/cjfdtotal-zdzc201606017.htm
Tang Y B, Bu W, Wu X Q. Natural scene text detection based on multi-level MSER[J]. J Zhejiang Univ (Eng Sci), 2016, 50(6): 1134–1140. http://www.cnki.com.cn/article/cjfdtotal-zdzc201606017.htm
[6] 蒋弘毅, 朱丽平, 欧樟鹏. 基于MSER和Tesseract的自然场景图像文字识别[J]. 电脑知识与技术, 2017, 13(33): 213–216. http://www.cnki.com.cn/Article/CJFDTotal-DNZS201733095.htm
Jiang H Y, Zhu L P, Ou Z P. Text recognition of natural scene image based on MSER and Tesseract[J]. Comput Knowl Technol, 2017, 13(33): 213–216. http://www.cnki.com.cn/Article/CJFDTotal-DNZS201733095.htm
[7] 张开玉, 邵康一, 卢迪. MSER快速自然场景倾斜文本定位算法[J]. 哈尔滨理工大学学报, 2019, 24(2): 81–88. http://www.cnki.com.cn/Article/CJFDTotal-HLGX201902013.htm
Zhang K Y, Shao K Y, Lu D. MSER fast skewed scene-text location algorithm[J]. J Harbin Univ Sci Technol, 2019, 24(2): 81–88. http://www.cnki.com.cn/Article/CJFDTotal-HLGX201902013.htm
[8] 张国和, 黄凯, 张斌, 等. 最大稳定极值区域与笔画宽度变换的自然场景文本提取方法[J]. 西安交通大学学报, 2017, 51(1): 135–140. http://www.cnki.com.cn/Article/CJFDTotal-XAJT201701021.htm
Zhang G H, Huang K, Zhang B, et al. A natural scene text extraction method based on the maximum stable extremal region and stroke width transform[J]. J Xi'an Jiaotong Univ, 2017, 51(1): 135–140. http://www.cnki.com.cn/Article/CJFDTotal-XAJT201701021.htm
[9] 南阳, 白瑞林, 李新. 卷积神经网络在喷码字符识别中的应用[J]. 光电工程, 2015, 42(4): 38–43. doi: 10.3969/j.issn.1003-501X.2015.04.007
Nan Y, Bai R L, Li X. Application of convolutional neural network in printed code characters recognition[J]. Opto-Electron Eng, 2015, 42(4): 38–43. doi: 10.3969/j.issn.1003-501X.2015.04.007
[10] Wang K, Belongie S. Word spotting in the wild[C]//Proceedings of the 11th European Conference on Computer Vision, 2010, 6311: 591–604.
[11] Wang K, Babenko B, Belongie S. End-to-end scene text recognition[C]//Proceedings of 2011 International Conference on Computer Vision, 2011: 1457–1464.
[12] Tian Z, Huang W L, He T, et al. Detecting text in natural image with connectionist text proposal network[C]//Proceedings of the 14th European Conference on Computer Vision, 2016, 9912: 56–72.
[13] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91–99.
[14] Liao M H, Shi B G, Bai X, et al. TextBoxes: a fast text detector with a single deep neural network[Z]. arXiv: 1611.06779, 2016.
[15] Liu W, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 21–37.
[16] Tian Z, Huang W L, He T, et al. Detecting text in natural image with connectionist text proposal network[C]//Proceedings of the 14th European Conference on Computer Vision, 2016, 9912: 56–72.
[17] Liao M H, Shi B G, Bai X. TextBoxes++: a single-shot oriented scene text detector[J]. IEEE Trans Image Process, 2018, 27(8): 3676–3690. doi: 10.1109/TIP.2018.2825107
[18] Ma J Q, Shao W Y, Ye H, et al. Arbitrary-oriented scene text detection via rotation proposals[J]. IEEE Trans Multimed, 2018, 20(11): 3111–3122. doi: 10.1109/TMM.2018.2818020
[19] Zhou X Y, Yao C, Wen H, et al. EAST: an efficient and accurate scene text detector[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 2642–2651.
[20] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015: 3431–3440.
[21] Deng D, Liu H, Li X, et al. PixelLink: detecting scene text via instance segmentation[Z]. arXiv: 1801.01315, 2018.
[22] Shi B G, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. I IEEE Trans Pattern Anal Mach Intell, 2017, 39(11): 2298–2304. doi: 10.1109/TPAMI.2016.2646371
[23] Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks[C]//Proceedings of the 23rd International Conference on Machine Learning, 2006: 369–376.
[24] Lee C Y, Osindero S. Recursive recurrent nets with attention modeling for OCR in the wild[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 2231–2239.
[25] Sandler M, Howard A, Zhu M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 4510–4520.
[26] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 936–944.
[27] Milletari F, Navab N, Ahmadi S A. V-Net: fully convolutional neural networks for volumetric medical image segmentation[C]// Proceedings of the 4th International Conference on 3D Vision (3DV), 2016: 565–571.
[28] Li X, Wang W H, Hou W B, et al. Shape robust text detection with progressive scale expansion network[Z]. arXiv: 1806.02559, 2018.
[29] Liu X B, Liang D, Yan S, et al. FOTS: fast oriented text spotting with a unified network[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 5676–5685.
[30] Thakare S, Kamble A, Thengne V, et al. Document Segmentation and Language Translation Using Tesseract-OCR[C]//2018 IEEE 13th International Conference on Industrial and Information Systems (ICⅡS). IEEE, 2018.
[31] Shi B G, Yang M K, Wang X G, et al. ASTER: an attentional scene text recognizer with flexible rectification[J]. IEEE Trans Pattern Anal Mach Intell, 2019, 41(9): 2035–2048. https://pubmed.ncbi.nlm.nih.gov/29994467/
-

 点击扫一扫
点击扫一扫
图(9)
表(3)
计量
- 文章访问数: 5983
- PDF下载数: 2133
- 施引文献: 0


