
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要
卷积神经网络在单帧图像超分辨率重建任务中取得了巨大成功,但是其重建模型多是基于单链结构,层间联系较弱且不能充分利用网络提取的分层特征。针对这些问题,本文设计了一种多路径递归的网络结构(MRCN)。通过使用多路径结构来加强层之间的联系,实现特征的有效利用并且提取丰富的高频成分,同时使用递归结构降低训练难度。此外,通过引入特征融合的操作使得在重建的过程中可以充分利用各层提取的特征,并且自适应的选择有效特征。在常用的基准测试集上进行了大量实验表明,MRCN比现有的方法在重建效果上具有明显提升。

Abstract
Convolutional neural network (CNN) has recently achieved a great success for single image super-resolution (SISR). However, most deep CNN-based super-resolution models use chained stacking to build the network, which results in the fact that the relationship between layers is weak and does not make full use of hierarchical features. In this paper, a multi-path recursive convolutional network (MRCN) is designed to address these problems in SISR. By using multi-path structure to strengthen the relationship between layers, our network can effectively utilize features and extract rich high-frequency components. At the same time, we also use recursive structure to alleviate training difficulty. In addition, by introducing the operation of feature fusion into the model, our network can make full use of the features extracted from each layer in the reconstruction process and select the effective features adaptively. Extensive experiments on benchmarks datasets have shown that MRCN has a significant performance improvement against existing methods.
-
Key words:
- convolutional neural network /
- super-resolution /
- hierarchical features /
- multi-path /
- feature fusion
-
Overview

Overview: Single image super-resolution is widely used in security monitoring, satellite remote sensing imagery, and medical image processing. It aims at restoring a high-resolution image from corresponding degraded low resolution LR-image. Recently, Dong et al. first discovered that convolutional neural networks can accomplish super-resolution by end-to-end manner, opening the door for deep learning in the field of super-resolution. And a series of new network model were proposed. Although these models have achieved good performance, the existing problems cannot be ignored. First, with the increase of network depth, many models fail to take into account the effect of hierarchical features on super-resolution, and the extracted features of each layer can only be learned once, which cannot be fully utilized. Second, the many models use pre-processing methods to get the target size, which not only increases the computational complexity, but also destroys the information carried by the original image. In response to this problem, ESPCN based on subpixel convolution and FSRCNN based on deconvolution are proposed. However, their structure is too simple to complete the exact mapping. Third, most methods use the mean square error (MSE) to optimize the model, resulting in overly smooth images.
To solve these problems, we propose a multipath recursive network (MRCN). We use multi-path structure to extract features and improve the ability of non-linear mapping, which accelerates the transfer of feature and gradient in the network. Then we use recursive methods to reduce network parameters. Finally, all the features were merged to complete super-resolution. Compared with other models, our network mainly has the following differences. First, different from the traditional single-chain structure, our network adopts a multi-path structure, which enables the extracted features of each layer to be learned multiple times, improving feature richness, and the reconstructed image contains more high-frequency information. Second, most models use the last layer of the network to complete reconstruction, while our network uses all the features extracted from the network to complete reconstruction together. At the same time, we use the nature of SENet to select the effective features of these features adaptively and suppress the useless features. Third, we use the Charbonnier loss function to alleviate the problem that the reconstructed images are too smooth due to MSE, and the performance of the network can be improved. A large number of experiments on the benchmark set show that our method is superior to the existing methods in reconstruction performance.
-

-
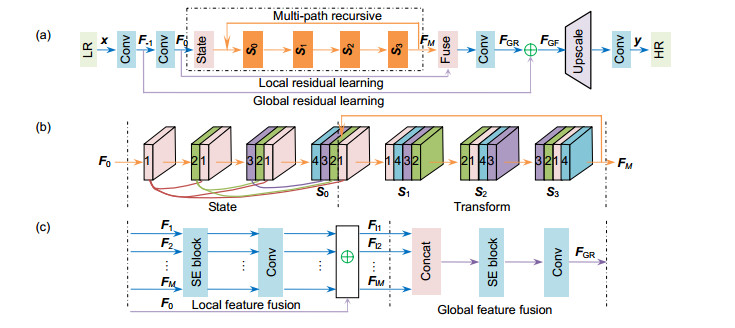
图 1 网络结构。(a)本文的基本网络结构;(b)多路径递归过程,其利用状态转移来模拟,“State”表示生成组成状态的部分,“Transform”表示递归中状态转移,对应(a)中橙色部分;(c)特征融合,对应(a)中的Fuse
Figure 1. Basic architectures. (a) The architecture of our proposed multi-path recursive convolutional network; (b) The multi-path recursive structure. State transitions are used here to simulate this process, where "State" represents the generation of different states and "Transform" represents state transitions in recursion; (c) Feature fusion, corresponding to the "fuse" in (a).
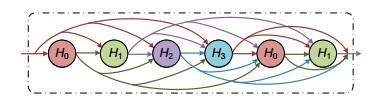
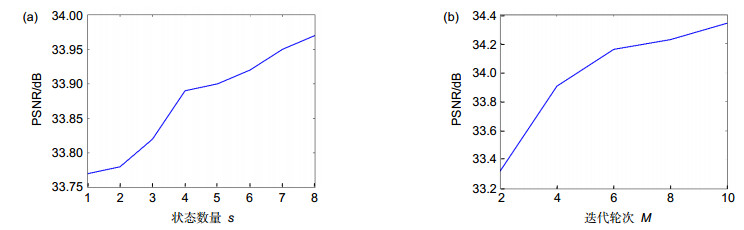
图 4 多路径递归结构对网络性能的影响。(a)状态数量对重建效果的影响;(b)递归轮数对重建效果的影响
Figure 4. The effect of multi-path on network performance. (a) The effect of the number of states on SR; (b) The effect of the number of recursive-rounds on SR
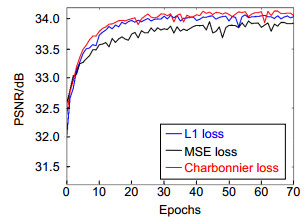
图 5 损失函数的选择对网络性能的影响
Figure 5. The impact of the choice of loss function on network performance

图 7 Urban数据集中的“ img096”图片3×重建
Figure 7. "img096" from Urban with an upscaling factor of 3×

图 8 Set14数据集中的“ ppt3”图片3×重建
Figure 8. "ppt3" from Urban with an upscaling factor of 3×
表 1 数据集Set5、Set14、BSD100以及Urban100在比例因子为2×、3×和4×下的平均PSNR/SSIM
Table 1. Average PSNR/SSIMs for scale factors of 2×, 3× and 4× on datasets Set5, Set14, BSD100 and Urban100
Scale Method Set5 Set14 BSD100 Urban100 PSNR/SSIM PSNR/SSIM PSNR/SSIM PSNR/SSIM 2× Bicubic 33.66 /0.9299 30.24/0.8688 29.56/0.8431 26.88/0.8403 A+[8] 36.54/0.9544 32.28/0.9056 31.21/0.8863 29.20/0.8938 SRCNN[9-10] 36.66/0.9542 32.42/0.9063 31.36/0.8879 29.50/0.8946 VDSR[12] 37.53/0.9587 33.03/0.9124 31.90/0.8960 30.76/0.9140 DRCN[13] 37.63/0.9588 33.04/0.9118 31.85/0.8942 30.75/0.9133 DRRN[17] 37.74/0.9591 33.23/0.9136 32.05/0.8973 31.23/0.9188 MemNet[19] 37.78/0.9597 33.28/0.9142 32.08/0.8978 31.31/0.9195 MRCN(ours) 37.89/0.9602 33.37/0.9163 32.12/0.8985 31.36/0.9231 3× Bicubic 30.39/0.8628 27.55/0.7742 27.21/0.7385 24.46/0.7349 A+[8] 32.58/0.9088 29.13/0.8188 28.29/0.7835 26.03/0.7973 SRCNN[9-10] 32.75/0.9090 29.28/0.8209 28.41/0.7863 26.24/0.7989 VDSR[12] 33.66/0.9213 29.77/0.8314 28.82/0.7976 27.14/0.8279 DRCN[13] 33.82/0.9226 29.76/0.8311 28.80/0.7963 27.15/0.8276 DRRN[17] 34.03/0.9244 29.96/0.8349 28.95/0.8004 27.53/0.8378 MemNet[19] 34.09/0.9248 30.00/0.8350 28.96/0.8001 27.56/0.8376 MRCN(ours) 34.24/0.9267 30.16/0.8413 29.06/0.8022 27.60/0.8391 4× Bicubic 28.24/0.8104 26.00/0.7027 25.96/0.6675 23.14/0.6577 A+[8] 30.28/0.8603 27.32/0.7491 26.82/0.7087 24.32/0.7183 SRCNN[9-10] 30.48/0.8628 27.49/0.7503 26.90/0.7101 24.52/0.7221 VDSR[12] 31.35/0.8838 28.01/0.7674 27.29/0.7251 25.18/0.7524 DRCN[13] 31.53/0.8854 28.02/0.7670 27.23/0.7233 25.14/0.7510 DRRN[17] 31.68/0.8888 28.21/0.7721 27.38/0.7284 25.44/0.7638 MemNet[19] 31.74/0.8893 28.26/0.7723 27.40/0.7281 25.50/0.7630 MRCN(ours) 31.83/0.8904 38.31/0.7732 27.44/0.7301 25.52/0.7641  下载: 导出CSV
下载: 导出CSV
-
参考文献
[1] Li X, Orchard M T. New edge-directed interpolation[J]. IEEE Transactions on Image Processing, 2001, 10(10): 1521-1527. doi: 10.1109/83.951537
[2] Zhang L, Wu X L. An edge-guided image interpolation algorithm via directional filtering and data fusion[J]. IEEE Transactions on Image Processing, 2006, 15(8): 2226-2238. doi: 10.1109/TIP.2006.877407
[3] Dai S Y, Han M, Xu W, et al. SoftCuts: a soft edge smoothness prior for color image super-resolution[J]. IEEE Transactions on Image Processing, 2009, 18(5): 969-981. doi: 10.1109/TIP.2009.2012908
[4] Sun J, Xu Z B, Shum H Y. Image super-resolution using gradient profile prior[C]//Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition, 2008: 1-8.
[5] 吴从中, 胡长胜, 张明君, 等.有监督多类字典学习的单幅图像超分辨率重建[J].光电工程, 2016, 43(11): 69-75. doi: 10.3969/j.issn.1003-501X.2016.11.011
Wu C Z, Hu C S, Zhang M J, et al. Single image super-resolution reconstruction via supervised multi-dictionary learning[J]. Opto-Electronic Engineering, 2016, 43(11): 69-75. doi: 10.3969/j.issn.1003-501X.2016.11.011
[6] 汪荣贵, 汪庆辉, 杨娟, 等.融合特征分类和独立字典训练的超分辨率重建[J].光电工程, 2018, 45(1): 170542. doi: 10.12086/oee.2018.170542
Wang R G, Wang Q H, Yang J, et al. Image super-resolution reconstruction by fusing feature classification and independent dictionary training[J]. Opto-Electronic Engineering, 2018, 45(1): 170542. doi: 10.12086/oee.2018.170542
[7] Timofte R, De Smet V, Van Gool L. Anchored neighborhood regression for fast example-based super-resolution[C]// Proceedings of 2013 IEEE International Conference on Computer Vision, 2013: 1920-1927.
[8] Timofte R, De Smet V, Van Gool L. A+: adjusted anchored neighborhood regression for fast super-resolution[M]//Cremers D, Reid I, Saito H, et al. Computer Vision--ACCV 2014. Cham: Springer, 2014: 111-126.
[9] Dong C, Loy C C, He K M, et al. Learning a deep convolutional network for image super-resolution[C]//Proceedings of the 13th European Conference on Computer Vision, 2014: 184-199.
[10] Dong C, Loy C C, He K M, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295-307. doi: 10.1109/TPAMI.2015.2439281
[11] Yang J C, Wright J, Huang T S, et al. Image super-resolution via sparse representation[J]. IEEE Transactions on Image Processing, 2010, 19(11): 2861-2873. doi: 10.1109/TIP.2010.2050625
[12] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1646-1654.
[13] Kim J, Lee J K, Lee K M. Deeply-recursive convolutional network for image super-resolution[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1637-1645.
[14] Zhang K, Zuo W M, Gu S H, et al. Learning deep CNN Denoiser prior for image restoration[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2808-2817.
[15] Shi W Z, Jiang F, Zhao D B. Single image super-resolution with dilated convolution based multi-scale information learning inception module[C]//Proceedings of 2017 IEEE International Conference on Image Processing, 2017: 977-981.
[16] Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 105-114.
[17] Tai Y, Yang J, Liu X M. Image super-resolution via deep recursive residual network[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2790-2798.
[18] Mao X J, Shen C H, Yang Y B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016: 2810-2818.
[19] Tai Y, Yang J, Liu X M, et al. MemNet: a persistent memory network for image restoration[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 4549-4557.
[20] Dong C, Loy C C, Tang X O. Accelerating the super-resolution convolutional neural network[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 391-407.
[21] Shi W Z, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1874-1883.
[22] Lai W S, Huang J B, Ahuja N, et al. Deep Laplacian pyramid networks for fast and accurate super-resolution[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5835-5843.
[23] Huang G, Liu Z, van der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2261-2269.
[24] Chen Y P, Li J A, Xiao H X, et al. Dual path networks[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 4470-4478.
[25] Hu J, Shen L, Albanie S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, doi: 10.1109/TPAMI.2019.2913372.
[26] Timofte R, Agustsson E, van Gool L, et al. NTIRE 2017 challenge on single image super-resolution: methods and results[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017: 1110-1121.
[27] Bevilacqua M, Roumy A, Guillemot C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C]//Proceedings of the British Machine Vision Conference, 2012: 135.1-135.10.
[28] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations[C]//Proceedings of the 7th International Conference on Curves and Surfaces, 2010: 711-730.
[29] Huang J B, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 5197-5206.
[30] Martin D, Fowlkes C, Tal D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proceedings of the 8th IEEE International Conference on Computer Vision, 2001: 416-423.
[31] He K M, Zhang X Y, Ren S Q, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, 2015: 1026-1034.
[32] Zhao H, Gallo O, Frosio I, et al. Loss functions for neural networks for image processing[OL]. arXiv: 1511.08861[cs.CV], 2015.
[33] Bruhn A, Weickert J, Schnörr C. Lucas/Kanade meets Horn/Schunck: combining local and global optic flow methods[J]. International Journal of Computer Vision, 2005, 61(3): 211-231. doi: 10.1023/b:visi.0000045324.43199.43
-
访问统计

 点击扫一扫
点击扫一扫
图(8)
表(1)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


