
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
针对现有的基于卷积神经网络的车辆目标检测算法不能有效地适应目标尺度变化、自身形变以及复杂背景等问题,提出了一种融合多尺度上下文卷积特征的车辆目标检测算法。首先采用特征金字塔网络获取多个尺度下的特征图,并在每个尺度的特征图中通过区域建议网络定位出候选目标区域,然后引入候选目标区域的上下文信息,与提取的目标多尺度特征进行融合,最后通过多任务学习联合预测出车辆目标位置和类型。实验结果表明,与多种主流检测算法相比,本算法具有更强的鲁棒性和准确性。
 Abstract:
Abstract:Aiming at the problems of the existing vehicle object detection algorithm based on convolutional neural network that cannot effectively adapt to the changes of object scale, self-deformation and complex background, a new vehicle detection algorithm based on multi-scale context convolution features is proposed. The algorithm firstly used feature pyramid network to obtain feature maps at multiple scales, and candidate target regions are located by region proposal network in feature maps at each scale, and then introduced the context information of the candidate object regions, fused the context information with the multi-scale object features. Finally the multi-task learning is used to predict the position and type of vehicle object. Experimental results show that compared with many detection algorithms, the proposed algorithm has stronger robustness and accuracy.
-

Overview: Aiming at the problems of the existing vehicle object detection algorithm based on convolutional neural network that cannot effectively adapt to the changes of object scale, self-deformation and complex background, a new vehicle detection algorithm based on multi-scale context convolution features is proposed. In real scenes, the scale of the object is often changeable, and it is difficult to distinguish all objects based on single scale image features. In order to obtain multi-scale feature representation of images, hierarchical features are extracted by convolutional neural network, and then FPN (feature pyramid network) is established. FPN is composed of convolutional layers. The feature maps of different scales are outputted from different convolutional layers. The information of FPN is propagated in three directions: bottom-up, top-down and transverse. In the bottom-up and top-down paths, the feature map of the former contains less semantic information, but it is more accurate for object location, while the latter has more semantic information. However, after several downsampling, most spatial information of the object is lost. Through transverse connection, feature complementarity and multi-scale fusion can be realized. The object candidate regions are generated by RPN network, and the corresponding object regions are located in each level of feature pyramid. Then, the object multi-scale features are extracted. Since the object usually does not exist independently, the background has more or less influence on the object. The structural relationship between the object and the background produces context information. Context information is introduced into the algorithm and fused into the multi-scale feature representation of the object to further enhance the discriminant ability of the object features. The contextual features are extracted around the candidate targets in the multi-scale feature map, and then, like the object features, are pooled by ROI and sent to the full-connectivity layer, respectively. The two sets of fixed-length feature vectors are connected to obtain the multi-scale features fused with the contextual information. The whole convolutional neural network can be trained end-to-end. In order to realize vehicle detection and type recognition simultaneously, multi-task loss function is defined to learn network parameters. In order to verify the validity of the proposed algorithm, the performance of several current mainstream algorithms is compared, including YOLOV2, YOLOV3, SSD, R-FCN. Through training and testing on PASCAL VOC data set and self-made engineering vehicle data set, it is shown that the proposed algorithm is superior to the existing object detection algorithm in precision and recall rate, and has good robustness to the influence factors of vehicle scale, shape change and complex background.
-

-

图 1 本文车辆目标检测算法的卷积神经网络模型流程图
Figure 1. Flow chart of convolutional neural network model of vehicle object detection algorithm
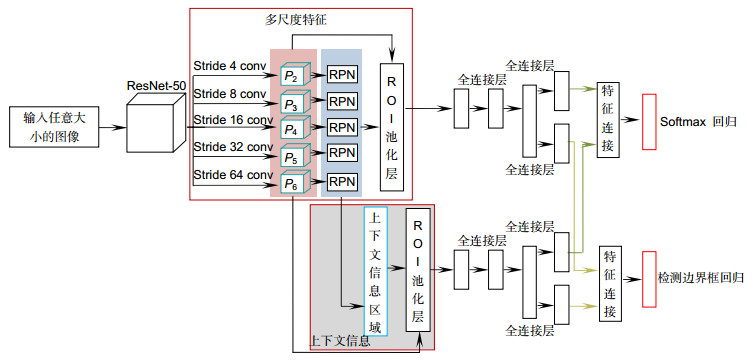
图 2 本文车辆目标检测算法的卷积神经网络模型结构图
Figure 2. Structure diagram of convolutional neural network model of vehicle object detection algorithm

图 5 五种算法在场景一的检测效果对比图。(a) YOLOV2; (b) YOLOV3; (c) SSD; (d) R-FCN; (e)本文算法
Figure 5. Comparison of the detection effects of five algorithms in the first scene. (a) YOLOV2; (b) YOLOV3; (c) SSD; (d) R-FCN; (e) Ours

图 6 五种算法在场景二的检测效果对比图。(a) YOLOV2; (b) YOLOV3; (c) SSD; (d) R-FCN; (e)本文算法
Figure 6. Comparison of the detection effects of five algorithms in the second scene. (a) YOLOV2; (b) YOLOV3; (c) SSD; (d) R-FCN; (e) Ours

图 7 不同算法在工程车数据集上的PR曲线
Figure 7. PR curves of different algorithms on the engineering vehicle dataset. (a) Crane; (b) Digger
表 1 不同算法在VOC数据集下的检测性能
Table 1. Detection performance of different algorithms under VOC data sets
Algorithm Bus Car mAP/% MacroF1/% AP/% F1/% AP/% F1/% YOLOV2 79.8 83.3 76.5 84.2 78.1 83.8 YOLOV3 87.6 86.9 87.7 87.2 87.6 87.0 SSD 79.4 86.4 76.1 84.8 77.7 85.6 R-FCN 85.9 86.8 86.1 87.0 86.0 86.9 Ours 87.4 87.0 89.4 87.6 88.4 87.3  下载: 导出CSV
下载: 导出CSV
表 2 不同算法在SC数据集上的检测性能
Table 2. Detection performance of different algorithms on SC data sets
Algorithm Crane Digger mAP/% MacroF1/% AP/% F1/% AP/% F1/% YOLOV2 89.3 91.1 91.2 92.3 90.2 91.7 YOLOV3 91.1 92.4 91.8 93.2 91.4 92.8 SSD 82.7 84.6 86.6 85.6 84.7 85.1 R-FCN 88.0 84.8 89.7 87.3 88.8 86.0 Ours 91.0 92.6 92.7 93.4 91.9 93
下载: 导出CSV
-
[1] Felzenszwalb P, McAllester D, Ramanan D. A discriminatively trained, multiscale, deformable part model[C]//Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition, 2008: 24-26.
10.1109/CVPR.2008.4587597 [2] Felzenszwalb P F, Girshick R B, McAllester D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645. doi: 10.1109/TPAMI.2009.167
[3] Manana M, Tu C L, Owolawi P A. A survey on vehicle detection based on convolution neural networks[C]//Proceedings of the 3rd IEEE International Conference on Computer and Communications, 2017: 1751-1755.
10.1109/CompComm.2017.8322840 [4] 曹诗雨, 刘跃虎, 李辛昭.基于Fast R-CNN的车辆目标检测[J].中国图象图形学报, 2017, 22(5): 671-677. doi: 10.11834/jig.160600
Cao S Y, Liu Y H, Li X Z. Vehicle detection method based on fast R-CNN[J]. Journal of Image and Graphics, 2017, 22(5): 671-677. doi: 10.11834/jig.160600
[5] 谷雨, 徐英.基于随机卷积特征和集成超限学习机的快速SAR目标识别[J].光电工程, 2018, 45(1): 170432. doi: 10.3788/gzxb20114002.0289
Gu Y, Xu Y. Fast SAR target recognition based on random convolution features and ensemble extreme learning machines[J]. Opto-Electronic Engineering, 2018, 45(1): 170432. doi: 10.3788/gzxb20114002.0289
[6] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91-99.
10.1109/TPAMI.2016.2577031 [7] Lin T Y, Dollar P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936-944.
10.1109/CVPR.2017.106 [8] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
10.1109/CVPR.2016.91 [9] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6517-6525.
10.1109/CVPR.2017.690 [10] Redmon J, Farhadi A. YOLOv3: an incremental improvement[EB/OL]. arXiv: 1804.02767[cs.CV].
https://www.researchgate.net/publication/324387691_YOLOv3_An_Incremental_Improvement [11] Cai Z W, Fan Q F, Feris R S, et al. A unified multi-scale deep convolutional neural network for fast object detection[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 354-370.
10.1007/978-3-319-46493-0_22 [12] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 21-37.
10.1007/978-3-319-46448-0_2 [13] He K M, Zhang X Y, Ren S Q, et al. Deep Residual Learning for Image Recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
10.1109/CVPR.2016.90 [14] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems, 2012: 1097-1105.
10.1145/3065386 [15] Jia Y Q, Shelhamer E, Donahue J, et al. Caffe: convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM international conference on Multimedia, 2014: 675-678.
10.1145/2647868.2654889 [16] Dai J F, Li Y, He K M, et al. R-FCN: object detection via region-based fully convolutional networks[EB/OL]. arXiv: 1605.06409.
-

 点击扫一扫
点击扫一扫
图(7)
表(2)
计量
- 文章访问数:
- PDF下载数:
- 施引文献: 0


